基于反馈机制的自愈算法
2012-11-06赵季红曲桦陈文东
赵季红 ,曲桦,陈文东
(1. 西安交通大学 电子与信息工程学院,陕西 西安 710049;
2. 西安邮电学院 通信与信息工程学院,陕西 西安 710061)
1 引言
随着通信网络宽带化进程的逐步深入,业务类型的日渐丰富,网络的生存性问题成为研究的热点。故障恢复是网络生存性研究的重要组成部分[1,2],而自愈作为一种智能化的故障恢复技术,其研究也成为了一种趋势。
自愈通常是指网络在发生故障的情况下,不需要人工干预,能很快地、自发地恢复受影响的业务[3]。这就要求网络设备具备更强的计算和存储能力。自愈的基本原理是在节点检测到故障之后,立即通知源节点重新选择一条路径,即在边缘节点之间建立另外一条能够满足业务传输需求的路径,将受影响的流量切换到这条备份路径上去,从而保证业务的连续传输。
自愈的研究现状主要集中于2个方面:故障检测和故障恢复。故障检测旨在感知并且定位网络故障[4]。当网络中检测到故障之后,故障恢复机制开始运作。故障恢复旨在将故障路径上的流量切换到另一条可承载这些流量的健康路径上,减少由于故障对业务传输所造成的影响。
目前故障检测主要有 RSVP软状态、RSVP HELLO、LSP PING/Traceroute[5]以及 BFD[6]等技术。这几种技术所花费的检测时间较长,意味着在故障发生到故障被检测期间,将有大量的数据丢失。故障恢复的研究主要集中于2种机制:保护交换和重路由。保护交换的前提是为可能的故障路径提前找到一条备份路径。当故障发生后,将流量切换到备份路径上保证业务的传输。这种机制的主要问题是备份路径会占用大量的网络资源,造成资源的利用率偏低[7]。重路由主要有2个思路,静态路由和在线路由。静态路由将网络在很长一段时间的平均流量作为网络的当前流量信息,在这个基础上计算路由。这种方法简单却精度较差。目前,静态路由主要有最宽最短路径(WSP)算法[8]、最大可预留带宽(MRB)算法[9]。在线路由则基于当前网络的状态信息,计算并选择最小可能出现拥塞的路径传输业务,网络状态信息更新的即时性和准确性很大程度上决定了算法的性能。目前,在线路由主要包括最小冲突路由算法(MIRA)[10]、动态在线路由算法(DORA)[11]、最小冲突优化算法(LIOA)[12]等。重路由对于新路径的建立依赖于故障信息、网络路由的策略、预定义设置以及网络当前的状态信息,利用这些信息的路由算法,其收敛时间得不到保证,导致故障恢复时间不能满足业务的QoS传输。
根据上述分析,自愈技术的研究仍有许多问题亟待解决。第一,自愈以故障检测为前提,对故障检测结果的依赖程度过高。首先,自愈算法的触发是在故障检测之后进行的,当网络发生故障后,只有该故障被感知并且被定位之后才能触发自愈算法,因此自愈算法需要等待故障检测所需的时间。其次,如果故障未被成功检测,那么自愈算法就不能被触发,从而导致故障恢复失败。第二,自愈进行重路由计算的时间过长,其收敛的时间很难符合业务传输质量的要求。而且基于QoS约束重路由计算需要随时掌握当前网络状态信息,这些信息的收集往往通过泛洪的方式,会造成一定的资源浪费。
针对上述问题,本文提出了一种基于反馈机制的自愈算法。该算法通过引入Q学习的反馈机制,可以感知网络当前的状态信息,也可以感知到路径发生故障或者拥塞的情况,这样大大降低了自愈对于故障检测的依赖程度,不必对故障进行精确地定位,只需要模糊的感知故障或拥塞,自愈就可以启动。另一方面,该算法可以通过业务的传输收集路径的信息(时延、带宽等),通过对这些信息的学习,可以获得学习“经验”并作为重路由选择的依据,避免了繁杂的重路由计算过程,降低了重路由所需的时间。同时,该算法引入了多 QoS参数约束评价函数的路由计算以及Boltzmann-Gibbs分布的路径选择策略,使算法具备了区分业务能力以及网络资源优化能力。
本文首先介绍了算法设计中的几个基本概念,然后详细介绍了算法应用于网络中的网络模型、算法的数学模型以及算法实现的具体流程和步骤。最后,用 MATLAB对该算法进行了仿真,并对算法的性能进行了讨论。
2 算法设计中的基本概念
2.1 反馈机制
本文的研究旨在通过引入机器学习理论改善目前传统自愈机制缺乏对于网络环境的学习能力的状况,提高自愈机制的智能性。机器学习理论中的学习策略很多,比如类比学习、归纳学习、支持向量机和强化学习等,其中强化学习源于心理学中的“试错法”,通过不断与环境交互来改善策略最终找到适合环境的最优策略,这种与环境交互的思想可以应用到网络中实现对网络环境的学习。
本文中提出的算法通过引入强化学习理论中的Q学习[13]反馈机制来感知网络当前状态的变化,一定程度上缓解了传统自愈机制对于故障检测技术依赖程度过高的问题。同时,利用反馈机制可以降低在线路由计算中由于泛洪流量对网络资源的浪费。反馈机制原理如图1所示。

图1 基于Q学习的反馈机制
图1 中,当每个业务传输结束的时候,目的节点Egress会将该业务传输路径的状态信息反馈给源节点Ingress。Ingress通过这个反馈回来的状态信息感知该路径的承载能力。反馈回来的状态信息本质上是业务传输完成后学习到的“经验”。这样就可以避免每次重路由时重新计算新的路径,而是直接利用先前的“经验”自适应地选择合适的备份路径,从路由重计算到路由重查表,可以大大节省不必要的计算负担。
考虑到可以人为定义反映网络状态信息的评价函数,那么可以把其定义为一个数值。这样反馈流量占用的带宽和传输产生的时延可以忽略不记。因此,这种反馈机制较传统的泛洪广播网络状态信息的方式更加简单,而且能够有效减少网络中不必要的泛洪流量。
综上所述,通过反馈机制,Ingress节点依靠感知当前网络状态并且积累学习“经验”来选择路径,在很大程度上降低自愈机制对故障检测的依赖程度,同时提高了网络资源利用率。
2.2 业务分类
网络中的有些业务对实时性的要求较高,必须满足其实时传输,才能保证业务的服务质量(QoS);而有些业务对网络的吞吐量和分组丢失率的要求较高,只有足够大的吞吐量和足够低的分组丢失率才能保证业务的服务质量;还有一些业务对网络的要求不高,采用传统“尽力而为”服务即可,这类业务应该尽量少地占用网络资源。
为了合理地利用有限的网络资源,本文提出的算法的路由策略会依据不同业务类型选择适合其传输需求的最优路径。在本文中,将业务分成3种类型:EF业务、AF业务和BE业务。EF业务为加速转发业务,AF业务为确保转发业务,BE业务为尽力而为转发业务。3种业务对于QoS参数的要求参见表1。

表1 不同业务类型对QoS参数的要求
2.3 多QoS约束评价函数
一些自愈技术在寻找备份路径进行故障恢复的时候只考虑单一因素的约束,这样带来的问题是选择的路径不一定能够充分地满足业务传输的QoS需求,因为保证业务QoS传输需要考虑的参数很多,只满足其中一个不一定能达到传输的要求。因此,本文提出的算法引入多QoS参数的约束,这样反馈的评价函数所包含的网络状态信息会更加全面。
本文中,选取3种常用的QoS参数作为约束集合:吞吐量(TH)、端到端时延(delay)和分组丢失率(P)。这些参数都体现的是路径端到端的性能,综合考虑这些约束因素选择出来的路径就会融入这些约束信息,使路径的选择更加科学和可靠,更能满足业务的QoS传输需求。很明显,EF、AF业务的优先级和重要性要远远高于BE业务,因此希望 BE业务尽量少地占用网络中的节点和链路资源。使用U表示路径对网络节点和链路资源的利用率,U=Npath/ Nall,其中,Npath表示一条路径使用的节点数,Nall表示网络中节点个数总和。那么,约束集合C={TH, delay, P, U}。
评价函数为约束集合C的函数,即f(C)。评价函数的大小就体现了网络中路径的端到端的承载能力的好坏。其值越大,说明该路径当前的承载能力越强。
2.4 资源优化
静态路由算法通常会使业务集中于一条基于某种准则的“最优”路径。当网络中负载较大时,会产生路径拥塞,这就需要全局服务器对流量进行控制来解决这一问题。在本文中,源节点 Ingress可以得到评价函数提供的信息,因此可以感知到网络当前各条路径的负载情况,从而避免选择负载较大的路径进行业务的传输。但网络中的负载情况是随着时间变化而变化的,这就需要算法对网络状态信息的动态感知。本文中,源节点具有动态感知网络状态信息的能力,从而能够依据路径选择策略自适应地选择路径,使网络负载均衡,实现网络资源的优化。
3 基于反馈机制的自愈算法
基于反馈机制的自愈算法以强化学习中的 Q学习算法作为理论基础,应用于网络中以增强自愈机制的学习能力,提高自愈机制对于网络环境的感知力,实现网络的智能化控制。
3.1 数学模型
本文中反馈机制的实现是基于强化学习理论中的Q学习算法。Q学习就是要在系统动力学特性未知的情况下估计最优策略的Q值,详见文献[13]。在线Q学习方法的实现是按递归公式(3)进行的:在每个时间步 t,观察当前状态 St,选择和执行动作At,再观察后续状态 St+1并接受立即回报Rt,然后根据式(3)来调整Q值。
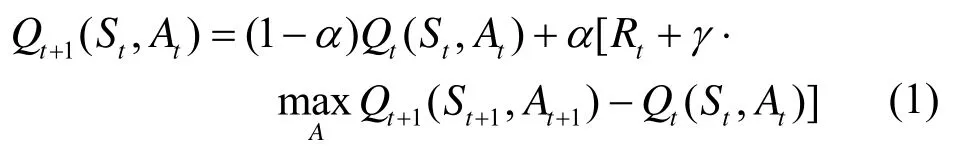
式(1)中,α为学习率,它控制着学习的速度,α越大则收敛越快。但是过大的α可能导致不收敛。Watkins证明了α在满足一定条件时,如果任一个二元组(St,At)能用方程(1)进行无穷多次迭代,则当 t趋于无穷时,Qt(St,At)以概率1收敛到关于最优策略的Q*(St,At)[13]。
根据多 QoS参数约束的需要,定义立即回报Reward为多 QoS约束的评价函数以满足业务的QoS需求。从上文可知,Reward是约束集C的函数。令 R={R1, R2, … , Rm}表示每个行动对应的Reward的集合。定义
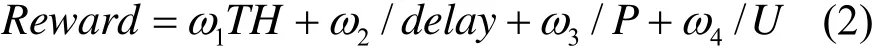
式(2)中ω1、ω2、ω3和ω4为权系数。调整权系数的大小可以体现出不同类型业务(EF业务、AF业务和BE业务)的需求。
Q学习算法中, Agent面临的一个问题是如果选择下一个动作,通常需要考虑2方面的因素。其一是Agent必须对状态动作空间做充分的探索从而能够找出最优或近最优的策略。另一方面是利用通过学习已获得的经验进行动作选择,从而使学习的成本降低。可以采用连续可微且近似贪婪的Boltzmann-Gibbs分布[14]作为动作选取策略,动作Ak被选取的概率为

式(3)中,Tt(>0)为温度参数,控制行为选取的随机程度。为了提高学习的速度,利用模拟退火技术在学习过程中按式(4)进行动态调整温度值,即在学习的初期选择较大的温度,以保证动作选取的随机性较大,增加搜索能力,然后在学习的过程中逐渐降低温度,保证以前的学习效果不被破坏[14]。
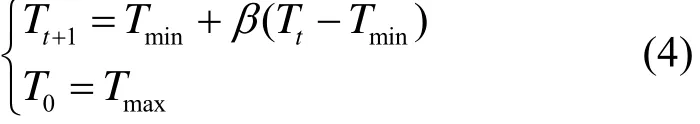
式(4)中, β 为退火因子,并且 0<β <1。
3.2 网络模型
本文提出的基于反馈机制的自愈算法可以应用在任何Mesh网络中。本文将以MPLS网络作为应用场景对算法的实现进行详细地研究。
将MPLS网络的拓扑抽象为G(V,E),V代表网络中的节点(路由器),E代表网络中的链路。令S={S1, S2,… , Sn}表示MPLS网络环境中的边缘节点的集合(边缘路由器LER或者自治域范围内的边缘标签交换路由器LSR),Si∈V。假设S1为业务传输源节点,那么选择S1作为Q学习Agent,潜在的目的节点集合S’={S2, … , Sn}即作为Q学习中的环境状态集,显然S’为有限集。源节点与目的节点之间所有可能的传输路径集合为 A={A1, A2, … ,Am},A即为Q学习Agent可以采取的行动集合,即是MPLS网络的标签交换路径(LSP)。Agent每采取一次行动,即每选择一条路径,都会产生一个与这次行动相对应的回报 Reward(式(2))反馈给源节点,然后根据式(1)更新此次业务传输之后对应路径的Qt(Si,Aj) 值,Si表示业务传输的目的节点;Aj表示业务到达Si的传输路径。网络模型如图2所示。

图2 Q学习在MPLS网络中的应用模型
Qt(Si,Aj)值大小决定了选择路径 Aj到目标节点 Si的“倾向”。将所有 Q值建立起来的矩阵Qt(Si,Aj)(i∈[1,n],j∈[1,m]) 定义为 Q 表格,表示业务的路由信息。S1节点中储存的Q表格如表2所示。
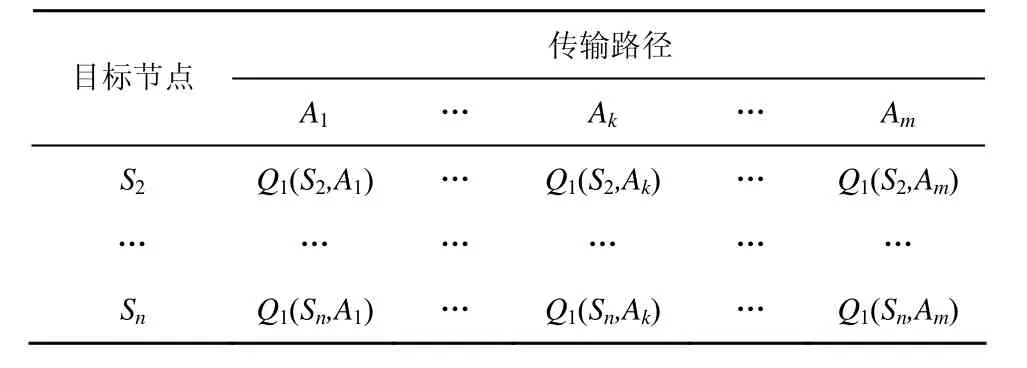
表2 Q表格
当业务传输结束并反馈Reward更新Q表格信息之后,就可以以式(3)作为路径选取策略来选择新业务的传输路径,更新后的 Q表格融入了反馈信息,因此具备网络状态的感知能力,同样也具备了故障的感知能力。
3.3 算法流程
算法的实现流程如图3所示。
具体实现步骤如下。
step1 当业务从源节点接入后,判断业务的类型。
step2 源节点根据业务的类型查询相应的路径优先级表格(EF业务Q表格、AF业务Q表格和BE业务Q表格)。
step3 依据基于Boltzmann-Gibbs分布的路径选择策略(式(3))得到业务的传输路径Ai。
step4 在业务传输过程中经过链路时,记录链路的吞吐量和时延信息。
step5 在业务到达目的节点后,将所得到的路径信息进行整合,计算出路径吞吐量、路径时延以及业务数据的分组丢失率,根据式(2)计算得到此次业务传输的Reward,并反馈给源节点。
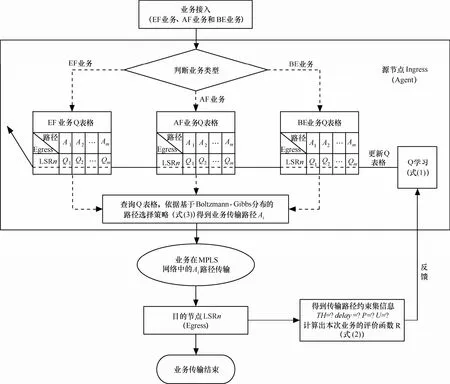
图3 算法的实现流程
step6 利用 Q 学习算法(式(1))得到更新后的Q值,从而对路径的优先级信息进行更新。新业务到来时便查询更新后的相应业务的Q表格,重复如上的步骤找到传输路径。
在本文中,业务的传输需要考虑2种情况,一种是业务传输成功的情况,一种是业务传输失败的情况。在第1种情况下,对算法收敛速度的要求不能过高,因为过快地收敛可能导致较大的扰动,学习的精确性不能得到很好地保证。在第2种情况下,业务传输失败很可能是由于链路或者节点出现故障造成的,对于这种情况,希望算法能对其进行较快地学习,因此希望收敛速度快。这2种情况可以通过使用不同的学习率α实现。算法可用下面的伪代码表示。
算法1 基于反馈机制的自愈算法
对于任意源节点Si∈S;
初始化 Qi(Sj,Ak),其中,Sj为目的节点,Ak为选择的路径,在所有 Ak中,取最少跳数路径的Qi(Sj,Ak)为1,其余值为0;
根据式(3)的随机分布选择路径,假设选择路径Am;
根据式(2),计算相应的Reward函数;
如果业务传输成功,依据下式更新Q表格:
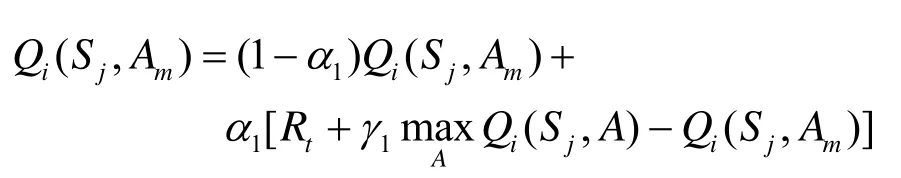
如果业务传输失败,依据下式更新Q表格:

4 仿真与性能分析
本节将对算法进行仿真并依据仿真结果分析算法各方面的性能。需要特别说明的是本文提出的算法改变了传统的自愈机制的以故障检测为前提的故障恢复模式,而是利用Q学习反馈机制的故障感知能力先于定位故障提前响应故障,因此缺少同类的自愈机制进行比较。在仿真中,将采用无反馈的静态自愈机制说明基于反馈的自愈机制对于网络环境的学习能力的改善。
4.1 网络参数设置
仿真中的网络拓扑如图 4所示。其中,LSR1为源节点,同时也是Q学习Agent。LSR15为目的节点,Reward将从这个节点反馈到LSR1以更新Q表格。
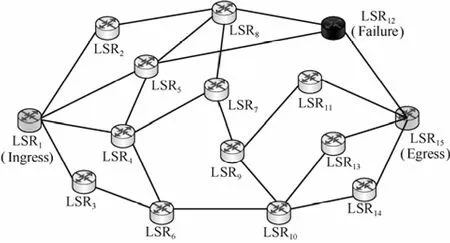
图4 网络拓扑(LSR12为故障场景中的故障节点)
LSR1和LSR15之间有22条可用传输路径,路径信息参见表 3。其中,对路径的约束参数包括路径吞吐量(Mbit/s)、路径时延(ms)和路径节点数。在仿真中,路径的分组丢失率与路径剩余带宽之间呈指数关系。

表3 仿真参数设置
表3中,静态路径选择指的是静态路由算法中3种业务可以选择的路径。EF业务选择的路径为1、2、4、5、12、20、21和 22;AF业务选择的路径为 1、3、7、10、11、17、20、21和 22;BE 业务可以选择所有路径。静态算法没有引入反馈机制,作为与本文提出算法的对比算法。
在仿真中,设置LSR12为可能发生故障的节点。从表3中可以看出,如果LSR12发生故障,受影响的路径有1、5、9、13、18和19。仿真中还加入了链路拥塞的情况,为了便于观察,设置路径22为可能发生拥塞的路径。因此,仿真中包括3种场景,分别为无故障场景、LSR12故障场景和路径22拥塞场景。
在仿真中,需要在网络负载大小变化条件下讨论算法性能,因此,对网络负载定义如下 10个等级,如表4所示。等级越高,表明网络负载越大。

表4 负载级别定义
4.2 性能分析
4.2.1 故障感知
本文中提出的算法通过业务传输之后评价函数的反馈机制感知网络当前的状态信息。因此,该算法具备故障感知的能力。令

φ 越小说明算法感知故障的能力越强;反之,算法感知故障的能力就越弱。仿真结果如图5所示。图5(b)反映了本文提出的算法对故障感知的性能,图5(a)反映了没有加入反馈机制的静态路由算法对故障感知的性能。从仿真结果可以看出,基于反馈机制的算法在故障感知性能上表现出了一定的优势。

图5 故障感知性能
4.2.2 故障恢复
在本文算法的自愈机制中,如果EF业务或者AF业务传输失败时,即选择了故障路径时,源节点会重新选择路径传输业务。如果重新选择的路径不能满足业务传输的QoS或者仍然选择了故障路径,则认为业务恢复失败,即没有找到合适的备份路径保证业务的传输;如果重新选择的路径可以满足业务的 QoS,并且不是故障路径,则认为业务恢复成功,即找到了一条合适的备份路径保证业务的传输。因此,业务恢复失败率可以表示为

仿真结果如图6所示。

图6 故障恢复性能
4.2.3 区分业务
图7从业务平均时延、路径平均剩余带宽和业务平均分组丢失率 3个方面说明了算法对于 EF、AF和BE业务的区分能力。
从图 7(a)中可以明显看出,EF业务的平均时延最小,AF业务次之,BE业务最大。这说明,算法对于EF业务,更倾向于选择时延小的路径保证业务的实时传输,而AF业务和BE业务的时延保证则相对较差。从图 7(b)中可以明显看出,AF业务选择路径的平均剩余带宽最大,EF业务次之,BE业务最小。算法对于AF业务,更倾向于选择吞吐量大的路径保证业务的传输,而对EF业务和BE业务,则这方面的保证相对较差。从图7(c)中可以明显看出,AF业务的平均分组丢失率最小,EF业务次之,BE业务最大。这说明,算法对于AF业务和EF业务,更倾向于选择分组丢失率小的路径保证业务的传输,而对BE业务的分组丢失率保证相对较差。

图7 区分业务性能
图7 的结果说明算法对EF、AF和BE 3种业务进行了区分服务,在有限的网络资源条件下,满足了EF业务和AF业务的传输需求。
4.2.4 网络资源优化
本文提出的算法通过反馈机制可以感知路径的剩余带宽,在源节点选择路径时,会根据剩余带宽情况动态进行路径的分配。因此,网络中流量会比较均衡。而静态路由算法由于没有引入反馈机制,缺少对路径剩余带宽的感知能力,因此在选路时,不会考虑到网络的负载情况,只根据静态路由表进行路由。因此,各路径的负载情况不一定会均衡,网络资源利用率偏低。将图8(a)和图8(b)进行比较,可以明显看出,基于反馈机制的自愈算法可以使网络中各路径的负载均衡化,具有网络资源优化的能力,在图中显示的效果是路径剩余带宽平面比较平滑,而静态路由算法中的路径剩余带宽平面就显得凹凸不平。

图8 资源优化性能
4.2.5 学习率α1、α2对算法性能的影响
在本文中,α1为业务传输成功时的学习率,α2为业务传输失败时的学习率。学习率越大,则算法收敛速度越快,但抖动也越大,而且如果学习率过大,还有可能导致算法不收敛。分别选取AF业务在故障路径17和拥塞路径22上的Q值变化曲线说明学习率对算法性能的影响,如图 9所示。

图9 学习率α1、α2对算法性能的影响
在仿真进行到1/4时,故障发生,路径17中断,所以此时影响算法收敛速度的学习率为α2;当仿真进行到3/4时,故障结束,路径17恢复,所以影响算法收敛速度的学习率变为α1。从图9(a)中可以看出,在故障发生时,当学习率较大时,收敛速度较快,但有一定的抖动。从图9(b)中可以看出,在拥塞发生的时候,较大的α1对应曲线的收敛速度较快,但抖动较大。
5 结束语
本文提出了一种基于反馈机制的自愈算法。利用Q学习的反馈机制,降低了传统自愈机制对故障检测的依赖程度,在一定程度上提高了算法对于故障感知的灵敏度,从而提高了故障恢复率。算法利用多QoS约束的评价函数,对于不同类型业务查询不同的Q表格从而使其具备区分业务的能力,同时,通过对网络状态信息的反馈以及基于Boltzmann-Gibbs分布的路径选择策略也在一定程度提高了网络资源的利用率,达到了网络资源优化的目的。
[1] IETF RFC 3469. Framework for Multi-Protocol Label Switching(MPLS)-based Recovery[S]. 2003.
[2] JORGE L, GOMES T. Survey of recovery schemes in MPLS networks[A]. 2006 International Conference on Dependability of Computer Systems[C]. Szklarska Poreba, Poland, 2006.
[3] YIJUN X, MASON L G. Restoration strategies and spare capacity requirements in self-healing ATM networks[J]. IEEE/ACM Transactions on Networking, 1999, 7(1): 98-110.
[4] CAVENDISH D, OHTA H, RAKOTORANTO H. Operation, administration, and maintenance in MPLS Networks[A]. IEEE Communications Magazine[C]. 2004. 91-99.
[5] IETF RFC 4379. Detecting Multi-protocol Label Switched (MPLS)Data Plane Failures[S]. 2006.
[6] IETF DRAFT. Bidirectional Fowarding Detection[S]. 2007.
[7] IETF RFC 3469. Framework for Multi-Protocol Label Switching(MPLS)-based Recovery[S]. 2003.
[8] GRERIN R, WILLIAMS D, ORDA A. QoS routing mechanisms and OSPF extensions[A]. 1997 Global Telecommunications Conference[C].Phoenix, 1997.
[9] KE Y, COPELAND G A. Scalability of routing advertisement for QoS routing in an IP network with guaranteed QoS[A]. 2000 Global Telecommunications Conference[C]. San Francisco, 2000.
[10] KODIALAM M, LAKSHMAN T. Minimum interference routing with applications to MPLS traffic engineering[A]. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies[C].Tel Aviv, 2000.
[11] SZETO W, BOUTABA R, IRAQI Y, Dynamic online routing algorithm for MPLS traffic engineering[A]. The 9th International Conference on Advanced Communication Technology[C]. Gangwon-Do,Korea, 2007.
[12] BAGULA B, BOTHA M, KRZESINSKI A. Online traffic engineering:the least interference optimization algorithm[A]. 2004 IEEE International Conference on Communications[C]. Paris, France, 2004.
[13] KAELBLING L P, LITTMAN M L, MOORE A W. Reinforcement learning: a survey[J]. Journal of Artificial Intelligence Research, 1996,4(1): 237-285.
[14] SUTTON R S, BARTO A G. Reinforcement Learning: An Introduction[M]. The MIT Press, Cambridge, MA, 1998.
