基于改进型蚁群算法的P2P网络资源搜索的研究
2012-10-08蔡康
蔡 康
(华南理工大学电子与信息学院 广州 510640)
1 引言
蚁群在觅食过程中总可以找到一条从蚁巢到食物源的最短路径。受到这些现象的启发,意大利学者Dorigo M等人于1991年提出了一种新颖的启发式优化算法——蚁群算法。但是该算法并没有引起很多人的注意,直到1996年Dorigo M发表了一篇文章,更加详细地阐述了蚁群算法的基本原理和数学模型[1]。从此,蚁群算法吸引了广大研究者的注意,得到了很大的发展,目前已经广泛用于求解各种组合优化问题,如函数优化、系统辨识、机器人路径规划、数据挖掘、网络路由等,取得了很好的效果,尤其适用于网络路径优化。
Dorigo M针对TSP问题提出了3种不同的基本蚁群算法模型,分别称为蚁周系统(ant-cycle system)、蚁量系统(ant-quantity system)、蚁密系统 (ant-density system)。最大—最小蚂蚁系统(max-min ant system,MMAS)[2~5]是到目前为止解决TSP、QAP等问题最好的ACO算法。和其他寻优算法相比,它仍然属于最好的解决方案之一。利用蚁群算法良好的耦合能力,将蚁群算法和遗传算法结合起来,采用遗传算法生成信息素初始分布,利用蚁群算法求精确解,从而实现两种算法的优势互补[6,7]。
将蚁群算法的思想引入非结构化P2P网络的搜索算法中,模拟蚂蚁觅食行为查找用户需要的资源,利用蚂蚁的信息素轨迹指导搜索的前进方向。这种正反馈机制使得搜索可以尽快地找到目标,得到更好的搜索结果。在基于蚁群算法的P2P网络资源搜索算法中,查询消息分组可以看作蚂蚁,搜索的目标视为食物,存在搜索目标的节点就是食物源。算法流程如下。
·当源节点发出搜索请求时,就相当于派出蚂蚁到网络中寻找食物。
·当蚂蚁到达时,先看节点是否有需要的食物,如果有就返回一个命中消息分组(可看作派出一只找到食物的蚂蚁沿原路返回源节点,沿途释放信息素,即修改节点的信息素表)。
·若没有,则根据节点中的信息素浓度,选择离目标近的邻居继续爬行,直到TTL(存活时间)减为0。
[8]研究了在非结构化P2P网络资源发现算法中蚁群算法的应用,指出在非结构化P2P网络资源发现算法中,已有的一些算法基本采用泛洪搜索方法。泛洪搜索可以保证较高的搜索成功率,但同时也产生大量的网络查询信息,严重占用网络带宽,很容易造成网络拥塞。由于搜索没有任何指导,很多没用的节点(如资源缺乏、信誉度比较低、计算能力差或动态性比较大等)也可能被搜索到,但这样的搜索显然不会得到想要的结果。如果网络节点能够记录其邻居节点的相关信息,就可以有选择地进行搜索,避免搜索到无用节点,在提高搜索成功率的同时,也减少网络的负担。基于蚁群算法的P2P网络资源发现算法,正好可以满足上述要求。蚁群算法要求每个节点维护一张信息素表,通过信息素表中各邻居节点的信息素量等信息来决定搜索时走向哪些邻居节点。文中提出,基于蚁群算法的P2P网络资源发现算法主要分为两个阶段:探查阶段和泛洪阶段。
(1)探查阶段
当某个节点发出资源搜索请求时,首先发出探查信息分组给部分邻居节点,并赋予探查信息分组一个较小的存活期。探查信息主要用于估计所搜索的资源的普及性。当这个小区域搜索结束后,源节点就收到关于所搜索的资源的一些统计信息,通过分析这些统计信息,源节点可以预知,搜索信息传播给几个邻居,最后可以得到多少资源搜索结果。这些统计信息将被存储在“探查表”中。
(2)泛洪阶段
当“探查表”建立后,源节点需要对接下来的泛洪搜索进行两个值的初始化:一个是k,即多少百分比的邻居将会被传播该泛洪搜索信息;另一个是TTL,即该泛洪搜索信息的存活期。k的值是由“探查表”中的相关信息估计此次搜索的代价决定的。泛洪搜索是一个迭代的过程,源节点计算有多少节点需要更深入的搜索,并选择一个合适的TTL。在搜索到资源后,源节点与资源节点之间的所有节点的信息素表将会被依次更新,以标志该路径的代价。
参考文献[9]提出了一种基于资源相似度和信誉相似度的P2P网络节点选取方法。该方法使用蚁群优化算法,算法要求每个节点维护两张信息素表:资源相似度信息素表和信誉相似度信息素表。文中指出,在P2P网络中,由于人们兴趣相似的关系,很多节点拥有相似或相同的资源,如果将这些节点以一定的方式联系起来,组成一个逻辑上的资源社区,则当其他节点发起搜索请求时,根据资源特性可以很快地在社区中找到提供资源的节点。另外,还指出研究节点信誉度衡量的重要性。高信誉度的节点在给网络提供可靠资源的同时,也保证搜索资源的高效性,而低信誉度的节点则可能降低网络资源的搜索率,甚至给网络带来某些恶意破坏。并提出两种衡量节点信誉度的方法:直接信任和推荐。直接信任是指对与当前节点进行资源对换的邻居节点的信誉进行衡量;推荐是指根据与当前节点的邻居节点进行资源对换的其他节点的信誉来衡量。通过维护这两张表,可以提高网络资源的搜索率和成功率。
蚁群算法在P2P网络的应用还存在许多问题,如网络中的蚂蚁数量的控制、信息素的更新机制、网络动态变化的处理等,最为严重的问题是目前的各种研究仅仅具有理论上的价值,在实际网络应用中还不具有可行性和现实性。本文针对上述问题专门为蚁群算法设计一种新型的P2P文件共享构架,尝试将蚁群算法的理论与实际网络环境相结合。
Dorigo M提出蚁群算法以来,能见度一直作为蚁群算法最基本、不可或缺的两大要素之一(另一个是信息素),几乎被所有与蚁群算法相关的研究文章所采用。参考文献[10]认为去掉能见度更容易证明全局性,但缺乏分析和实验比较算法效率,且仅针对TSP问题。本文分析了在P2P网络中应用能见度带来的3个缺点,提出了去能见度蚁群算法。一系列的实验结果证明了本文的观点:能见度容易导致局部极值问题,在大型网络中去掉能见度更好。
2 蚁群算法在P2P网络中的实现问题
蚁群算法在P2P网络中的应用基本集中在路由和资源发现两个方面,资源发现包括搜索文件、有多余运算能力的节点等,归结到底是要在网络中找出符合条件的节点以及通往该节点的最优路径。蚁群算法在P2P网络的应用还存在许多问题,本节将其归纳为4点,并针对这个问题给出一个新型的P2P文件共享构架。
2.1 逻辑路径与物理路径的不一致性
在目前的P2P系统中,每个Peer既可以是一个用户,也可以是一个资源提供者,还可以是一个数据分组中转者(即中间节点),此时该Peer相当于一个路由器,这就是P2P路由的原理,如图1所示。然而当中间节点是一台普通的个人电脑 (在目前的系统中绝大多数Peer都是个人电脑)时,P2P路由存在严重的问题。
图1中3个虚线的椭圆代表局域网,有3个网关(路由),虚线的箭头a、b代表P2P路由找到的一条Peer 1至Peer 3的路径,即 Peer 1→Peer 2→Peer 3,其中 Peer 2充当中间节点。这条P2P路径不是实际的路径,而只是一条逻辑意义上的路径,实际的物理路径是图1中的实线箭头,即 1→2→3→4→5→6,在这条物理路径中,路径 3和路径4构成了一个局部的回路(严格地说应该是闭迹),显然路径3和路径4完全是多余的,去掉这两条边,可以直接得到一条更好的路径:1→2→5→6,它比原来的路径短。

P2P的物理路径包含大量的局部回路,图1中只有一个中间节点,实际上中间节点会有多个,一般情况下,每一个中间节点就带来一个多余的局部回路,这将使得物理路径极大地加长,于是从Peer 1至Peer 2的时延也显著增加,对Peer 3而言,它下载需要的时间也相应显著地增加。当Peer 3从Peer 1下载资源时,所有的数据分组都会经过Peer 2,由此不但给Peer 2的电脑带来了巨大的负荷,而且占据了Peer 2的网络带宽,严重影响Peer 2的正常应用,在这种情况下,Peer 2的用户甚至可能会退出P2P系统。假设有多条P2P路径都经过Peer 2,则下载时多个数据流都经过Peer 2,即使该用户不退出,系统也无法正常下载。由此可以看出,基于蚁群算法的P2P路由难以在现实网络中实现。
2.2 资源搜索与优化相结合的问题
相对于2.1节所介绍的蚁群P2P路由问题,目前更多的理论研究集中于蚁群算法搜索P2P资源问题,一个有趣的现象是:目前绝大部分基于蚁群算法进行P2P资源搜索并不使用P2P路由,而是在找到资源之后,利用资源节点的IP地址,使用传统的路由方式建立下载路径[11]。一个显而易见的问题是:为什么在发现资源之后不使用原有的路径(即发现资源时所找到的路径)下载,而要重新搜索一条新的路径?
上述过程中进行了2次路径查找,这不但浪费时间,而且加重了网络的负担,似乎将资源搜索与路径优化结合起来更为合理,但是P2P的逻辑路径与物理路径的不一致性问题阻碍了这种结合。实际上很多学者已经发现了该问题,因此不得不把资源发现和资源下载分割成两个独立的部分,各自使用不同的路径。虽然这种分割处理的办法能够在实际网络中实现,并能够避免物理路径的局部回路(如图1所示),但是通过网络路由发现的下载路径既不是P2P路由路径(如图1虚箭头所示的P2P路径),也不一定是图1中所示的物理路径(通常是另一条物理路径)。这种差异造成的结果就是:通过蚁群算法找到的“优秀”资源实际上并不一定好,因为由蚁群算法所找到的“优秀”资源的逻辑路径优于其他逻辑路径,但是其物理路径并不一定优于其他路径。其本质就是:找到的路径和实际使用的路径不一致,找到的只是一条虚假的最优(或次优)路径。
2.3 节点失效与可靠性问题
在P2P系统中,尤其是非结构P2P网络中,每个Peer都有充分的自主权,可以自由地加入和退出系统。对于图1所示的系统,因为是普通用户的个人电脑充当中间节点,所以最容易发生的情况是一个中间节点退出,由此造成蚁群算法已经发现的一条或多条路径失效,只能重新搜索,尽管2.2节指出蚁群算法在动态变化网络的优化方面具有明显优势,但这只是相对传统路由算法而言,中间节点的频繁退出无疑会使得蚁群算法难以收敛。相对传统路由,蚁群算法的搜索路径时间肯定要长很多,时间越长,中间节点退出的可能性越大,因此在非结构P2P网络中使用蚁群路由算法必须要考虑中间节点退出的问题,但是这方面相关的研究不多,大部分都是在理想的静态条件下仿真。
2.4 蚂蚁数量问题
目前的蚁群算法都只适合于小型网络,在大部分关于QoS路由的文章中,其仿真节点数不超过20个[12~15]。主要的问题在于蚂蚁数量。在一个节点较多的网络中,利用蚂蚁实现准确查找是一种小概率事件,除非花很长时间。因此关于QoS路由的文章使用的蚂蚁数量一般和节点数量相同,甚至使用比节点数更多的蚂蚁。一个具有n个节点的网络中,一个节点的一次查询就要n个蚂蚁,n个节点需要n2个蚂蚁。在一个100节点的网络中,高达10 000只蚂蚁的频繁访问,将使得所有节点瘫痪。然而,如果蚂蚁数量不多,准确查找又难以实现或者需要很长的时间。
3 适合蚁群算法的新型P2P文件共享构架
以上详细讨论了蚁群算法应用于非结构P2P存在的诸多问题,其主要原因在于大部分的蚁群算法仅限于纯粹的理论研究,实际上最初蚁群算法的原型是针对TSP问题而设计,与实际网络条件有较大的差异。本节将针对上述问题专门为蚁群算法设计一种新型的P2P文件共享构架,尝试将蚁群算法的理论与实际网络环境相结合。
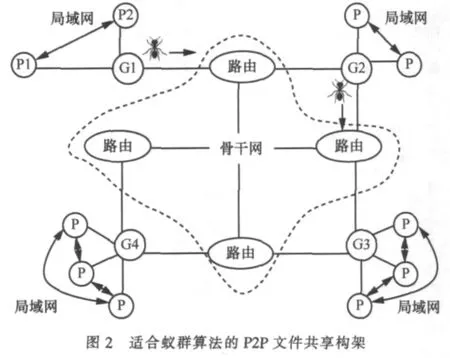
图2为系统的逻辑连接示意。G为网关节点(路由),P为普通节点(PC机)。虚线框内为骨干网。以上是硬件部分,该构架还包括蚁群协议部分。
3.1 信息素存储方式
信息素是蚁群算法的关键部分,从图论的角度来看,即各条边的权系数值。对于TSP问题,全部的程序都是在一台计算机上运行,因此所有的信息素都可以存储在本机上。但是对于网络路径优化问题,这个方法几乎无法实现。因为信息素和多个网关、路由、网络链路的实际参数有关,无法在本机(即源节点)上直接获得。一种想法是:蚂蚁经过路由和链路可以获得其参数,然后发信息分组回传源节点,由源节点在本机建立一个虚拟网络,但这种方法需要很大的通信量,且网络是动态变化的,蚂蚁回传的参数很快就失去时效。这种方法的本质是源路由法,每个Peer需要保存全网拓扑信息,要求很大的内存,更降低了该方法的实用性。
本文的方法是由各个路由器、网关存储信息素,每个路由或网关只存储与其相链接的边的信息素。显然,本文的蚁群算法是由路由器、网关来执行的,而不是P2P用户的个人电脑,从本质上看是多节点协同完成的分布式路由法。由于蚂蚁所经的路径就是物理路径,其信息素正是其物理路径的参数,由此就解决了逻辑路径与物理路径不一致的关键问题,从而使得基于蚁群算法的网络路由方法具有实际意义。因为信息素是不断挥发的,当经过一段时间某个蚂蚁的信息素挥发到一定值时,路由器就不必再存储该信息素,从而可以解决信息素过多占据内存的问题。
3.2 统一系统时钟
根据每次P2P任务中扮演的角色,可以将参加的全部Peer分为3类:源节点(蚂蚁的起点)、中间节点、目的节点(蚂蚁的终点)。由于信息素分布式存储于多个路由、网关中,为避免冲突,整个系统有一个统一的时钟频率,每个上半周期所有节点更新信息素,下半周期所有节点执行对蚂蚁的操作,包括接收、转移、发出、销毁。
3.3 蚂蚁搜索资源流程
系统搜索资源的原理如下。
·每个网关节点负责其局域网内节点的加入和退出,并建立一个域共享表保存其域内在线节点提供的所有共享文件的统一识别标志和关键词,相同文件只留1个识别标志。
·如果P1想查找某个感兴趣的内容,它把关键词发给网关G1,G1在其域共享表进行匹配,如果其域共享表有(假定P2有),把文件的统一识别标志和P2的地址返回P1,P2和P1用普通路由方式建立连接下载。
·如果G1在其域共享表没有找到P1需要的内容关键词,G1发蚂蚁到骨干网进行搜索,如果G1所在的域内有多节点同时查找域外同一资源,G1将其合并成一个任务。
·G1发出的某个蚂蚁A到达网关G2,G2将其域共享表与蚂蚁A所带关键词进行比较,如果G2域共享表内无该词,则转发别的网关;如果有,则将与该关键词对应的文件统一识别标志和G2域内路径赋予蚂蚁带回,于是总的路径为:P1至G1+G1至G2+G2至资源。
·多个蚂蚁搜索到资源之后返回,并在路径上布下信息素。
·由于蚂蚁是以随机漫游的方式进行搜索,其得到的路径大多数情况下不是满意解或次优解,更不是最优解,因此必须启动蚁群路径优化算法,确定最优资源和到最优资源的最优路径。
以上架构对蚁群算法有以下作用。
·减少蚂蚁数量,网关节点对域内请求进行了过滤和合并,大幅减少了骨干网上的蚂蚁数量。
·由于蚂蚁是在网关与网关之间搜索,缩短了蚂蚁的搜索路径,使得搜索难度呈指数降低(发现概率随着跳数的增加呈指数下降)。
·增大了蚁群算法搜索的网络规模。在普通网络中,蚂蚁以单机为搜索单位;在本构架中,蚂蚁在骨干网上以局域网(网关)为搜索单位,规模呈千百倍增长。
·将蚁群资源搜索和路径优化相结合,可以起到事半功倍的效果。
相比目前的超级节点系统,本构架有如下改进。
·超级节点系统中域的划分是一个难题,本架构以局域网划分域,物理拓扑结构和P2P逻辑结构相吻合,节点间通信开支小、流量小。
·网关服务器、路由器相比其他节点更可靠,以网关服务器为域中心,系统更稳定,并且能够避免虚假、过时的文件信息。
·路由器参与蚁群算法,使得物理路径与逻辑路径一致。
·能最大程度地实现流量本地化。目前P2P流量本地化采用IP地址判断,但由于运营商不同,IP地址与实际地址有较大差异,且不能准确到单个局域网。
·本文的蚁群算法能提供到资源节点的路径,无需骨干网路由查找。普通的超级节点系统只能提供资源节点的IP地址。
·穿透内网功能。因为直接获得资源的路径,所以不受内网虚拟IP地址的影响,可直接穿透,无需UPnP和打洞等复杂手段。
3.4 P2P网络拓扑仿真的改进
在研究蚁群算法应用于P2P网络的绝大部分文献中,从源节点至目的节点的距离一般都低于4跳,网络的节点数一般不超过20个[12~14],连小型局域网都算不上。然而,在实际的P2P网络中,一般情况下Peer的数量为数千甚至数万个,尤为重要的是这种“微型网络”是封闭式,即蚂蚁限制在这数十个点内走动,不会走到其他网络或者外网,如internet。在这种“微型网络”中,无论蚂蚁怎么随机游走,只需建立一个禁忌表,除非路径出现闭锁,绝大多数情况下都能找到目的地。因此蚂蚁的生存概率比实际网络环境高,所以基于这种网络的仿真结果对实际P2P并没有太多参考价值。当然这种“微型网络”的优点也是很明显的:其拓扑结构可以显示和打印在一个较小的版面上,读者一目了然,研究者能直接地研究该图,有利于进行公平的比较。事实上这种网络拓扑和TSP路径优化基本相同,但其与真实的网络环境相差甚远。
在利用蚁群算法进行资源搜索的文章中[16~19],因为不进行路径优化,蚁群没有收敛过程,功能单一,算法简单,可以使用较多节点,有些文章在NS2环境中使用具有数百个节点的网络进行仿真,但是这种网络图不容易在常用的A4版面上显示和打印出来,尤其是对于路径优化,必须要在图中的每条链路标出时延。因此这种仿真无法使读者看到拓扑结构的细节。
综上所述,问题归结为:如何通过一个较小的拓扑结构来模拟一个大型的网络环境?似乎这两者相互矛盾。在解决这个问题之前,本文给出一个新的网络概念:开放式网络拓扑。在解释开放式网络拓扑之前,为了清楚地解释这个概念,先解释其反面——封闭式网络拓扑。
定义1(封闭式网络拓扑)如果一个用于仿真的网络结构图有确定的网络边界,数据分组只能在边界以内的节点之间传递,则称为封闭式网络拓扑。
定义2(开放式网络拓扑)如果一个用于仿真的网络结构图没有确定的网络边界,则称为开放式网络拓扑。
开放式网络拓扑如图3所示。
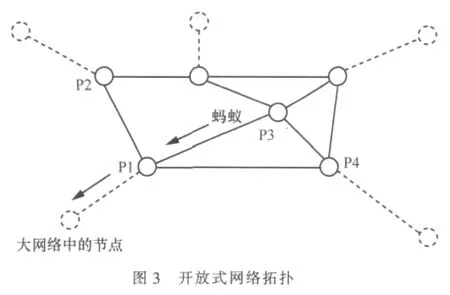
图3中的小圆圈表示一个节点,线段为链路,实线部分表示要研究的某个大型网络的一个局部,虚线部分表示实线部分连接到该大型网络的其余部分。当一个蚂蚁(数据分组)从P3节点到达P1节点时,如果是在封闭式的拓扑结构(忽略图中的虚线部分,余下的实线部分就是一个封闭式的拓扑结构)中,该蚂蚁只能去P2或P4节点;如果在新的开放式的拓扑结构中,该蚂蚁可以去虚线节点—图中所示为大网络中的节点,蚂蚁到达任何一个虚线节点即表示已经走到一个很大的网络中或者其他局域网,考虑到蚂蚁的生存周期有限,通常很难有机会再返回实线部分,因此仅需考虑实线部分 (源节点和目的节点都在实线部分),可以认为蚂蚁一到达虚线节点就意味着蚂蚁死亡。
从以上过程可以看出,通过这个较小的开放式拓扑结构可以模拟蚂蚁在一个大型网络中的行为,这种模拟环境相对于封闭式拓扑更接近实际环境。目前几乎所有的网络仿真实验都采用了封闭式的拓扑结构,包括著名的NS2软件。本文将采用开放式拓扑结构进行算法仿真实验,显然在开放式拓扑结构中蚂蚁更难找到目的节点。
4 改进型蚁群算法——去能见度的蚁群算法
4.1 能见度在P2P网络中的副作用
在蚁群算法中,蚂蚁根据概率转移公式选择下一条路径:
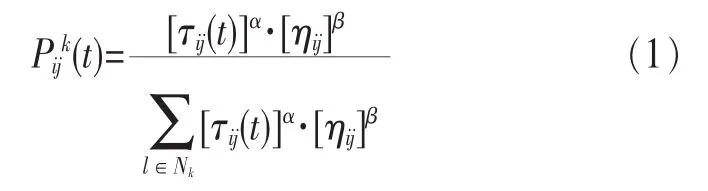
在研究网络QoS问题的绝大部分文章中,都应用了小型的封闭式网络,和TSP问题一样,蚂蚁选任何一条边几乎都能走到目的地,其失败的概率极小。因此当蚂蚁到达某个节点时,在与该点相关联的所有链路中,选择一条更短的链路具有概率上的启发意义。然而,如果在一个开放式的网络中,蚂蚁的失败概率很大,蚂蚁选的一条边无法保证它能走到目的地,无论其长度如何,也即在这种情况下边的长短和成功率无任何关联,必须先成功到达目的地之后才能考虑长度问题。另一方面,如果蚂蚁成功到达目的地,它可以用路径总长度来建立启发信息,无需用每条边的长度作为启发信息。更进一步,如果用每条边的长度作为启发信息,即所谓能见度,会有以下3个副作用。
(1)容易导致局部极小解
下面分两种情况进行说明。
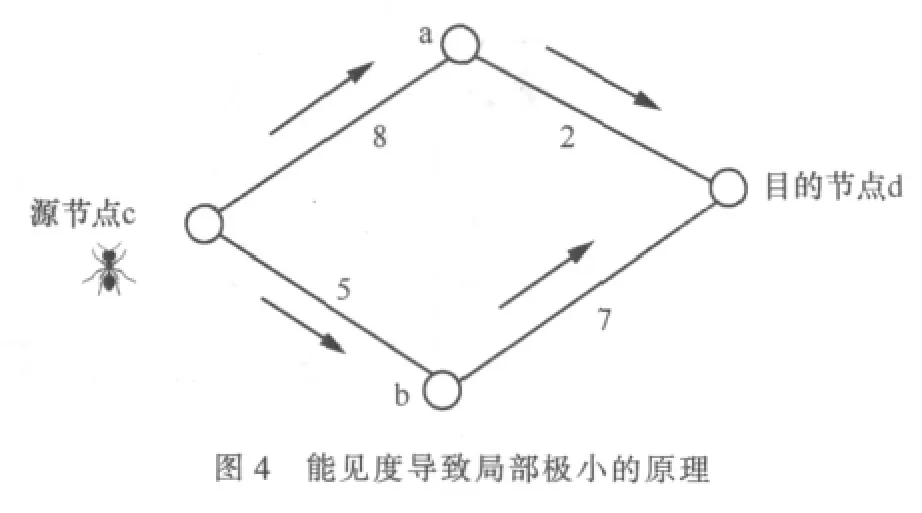
图4中蚂蚁初次从源节点c出发,因为初始信息素每条边都相同,而源c至b点的边比ca边短,概率上蚂蚁会选路径:源节点c→b→d(总时延12),因此该路径将增加信息素,下一个蚂蚁将更加偏向选该路径,并最终收敛到该路径,而实际上另一条路径c→a→d(总时延10)才是最好值。
假定a、b都有蚂蚁到达一次,边ca信息素增量为1/(8+2)=1/10,能见度为1/8;边cb的信息素增量为1/(5+7)=1/12,能见度为1/5。初始信息素残留0.1。根据经典蚁群算法概率转移公式,取α=β=1,算得边ca的转移概率为40.538%,边cb的转移概率为59.462%,局部解的选择概率竟然高于全局解。
(2)容易导致流量集中
本文中的节点时延为蚂蚁数据分组在路由器中的排队时延,链路时延(本文所指链路实际为一段线路,参考文献[20]将节点时延和线路时延合称链路时延)为数据分组在一段线路(光纤)中的传输时延。节点时延是与该节点相连的所有链(线)路共有的,不能为链路选择提供依据,因此实际能作为能见度的是链路时延,也即传输时延,但传输时延不会随流量负载变化,基本为固定的一个较小值[21,22]。即使某条时延低的链路流量很大,因为其能见度不变,蚂蚁仍然会选择它,从而导致流量集中。
(3)单个链路(传输)时延在实际系统中难以准确检测
如果取下一个节点的排队时延为能见度,在实际网络中的实现有较大难度。
4.2 新的概率转移公式
令τij(t)为t时刻链路(i,j)上的信息素强度,每条边有一个初始信息素c(给定的常数),在预搜索期间被选中的边的信息素为c+b,用禁忌表tubuk来记录蚂蚁k(k=1,2,…,m)当前所走过的节点,蚂蚁k根据各条边上的信息量来计算状态转移概率。

其中,α为信息启发式因子,Nk表示蚂蚁k下一步允许选择的节点:Nk=与节点i邻接的节点集-tubuk。
式(2)中没有ηij系数和与之相关的β系数,这与目前通用的方法不同,称之为去能见度蚁群算法,显然其比经典式子计算更简单,这是它的另一个优点。
5 实验与分析
采用两个不同的网络拓扑结构,两个不同的长度限制,分两部分共4个实验。
基本实验说明:开放式网络拓扑,在这种新的结构中,当某蚂蚁到达网络边界时,它有两种选择,或者向边界内走或者死亡——实际表示蚂蚁向边界外走,走向了其他的局域网或更大的骨干网,它很难再回到本局域网。从以上过程可以看出:通过这个较小的开放式拓扑结构可以模拟蚂蚁在一个大型网络中的行为,这种模拟相对于封闭式拓扑更接近实际环境。
节点共140个,除5条边的长度大于24但小于34,其余边长为12~24的随机数,精确到小数点后一位。除实验1、2中有一条从源节点到目的节点的路径跳数为8跳,其余都不小于14跳。显然这个距离显著超过了目前绝大部分有关QoS的文章中的最短距离。使用4个蚂蚁,共做80次试验。
5.1 长边少跳数实验
以下两个实验采用相同的网络,且特地设置一条8跳的路径,其中有几条长度较大的边(大于24),该路径的总长度为194.4,为最短路径,其余路径的跳数都不低于14跳。
5.1.1 实验1
在这个实验中,规定蚂蚁的生存周期内其已经走过的路径最大长度为:限制路径长度≤14跳×平均边长18×系数1.5跳 =378此处采用限制最大路径长度而非最大跳数,是基于以下考虑:
·目标是最小长度的路径,而不是跳数;
·存在着跳数很多,但是总长度并不大的路径;
·要公平对比无能见度和有能见度两种方式,只有采用长度限制,关于这一点在后面的分析中有说明。
实验曲线如图5所示。
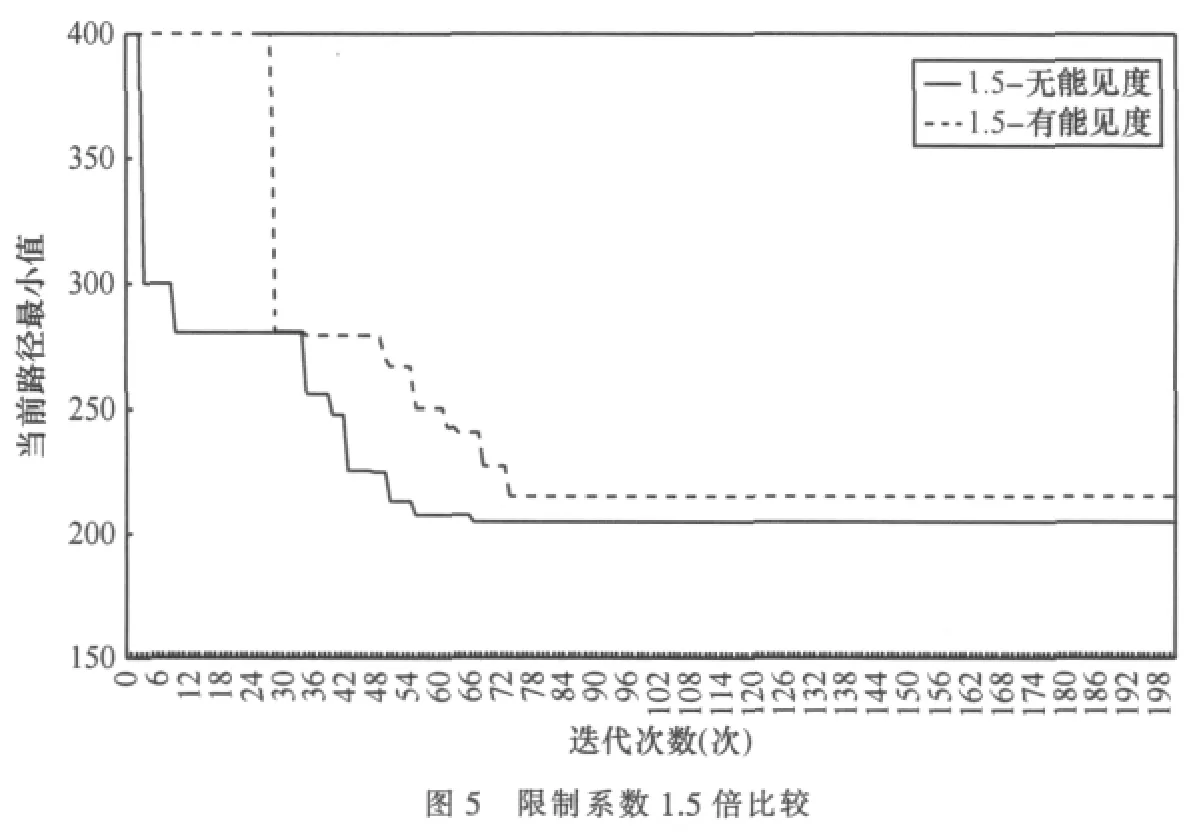
图5的虚线反映了有能见度算法的运行状态,实线反映了无能见度算法的运行状态,考虑到版面宽度的限制,仅仅绘制到200代。显然实线的下降速度和最小值都明显好于虚线,即本文的无能见度算法优于经典的有能见度蚁群算法。
图5给出了两个实时运行的曲线,因为蚁群算法有较大的随机性,每次运行的数据均不相同,因此曲线也不同。为公平起见,均取有代表性的某次运行画图。所谓有代表性,即运行的结果既不是最好,也不是最差,而是接近多次运行的平均值(参见表1)。本节的其他曲线也采用同样的方式绘制。
分别使用有能见度的蚁群算法和无能见度的蚁群算法进行80次实验,得到表1的结果。
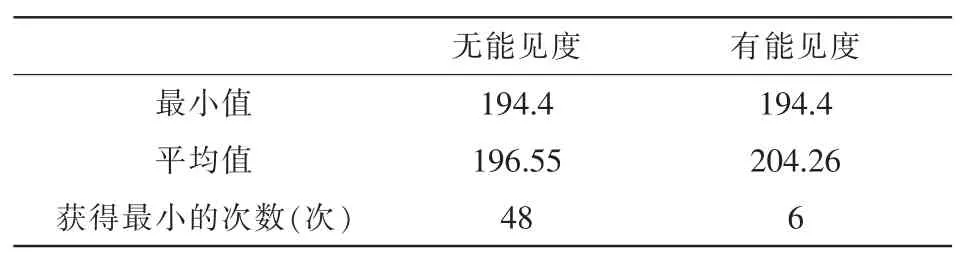
表1 限制系数1.5的比较结果(80次)
5.1.2 实验2
在这个实验中,规定蚂蚁的生存周期内已经走过的路径长度为:
限制路径长度=14×平均边长18×系数1.25跳 =315
本实验采用的网络与实验1相同。
实验曲线如图6所示。
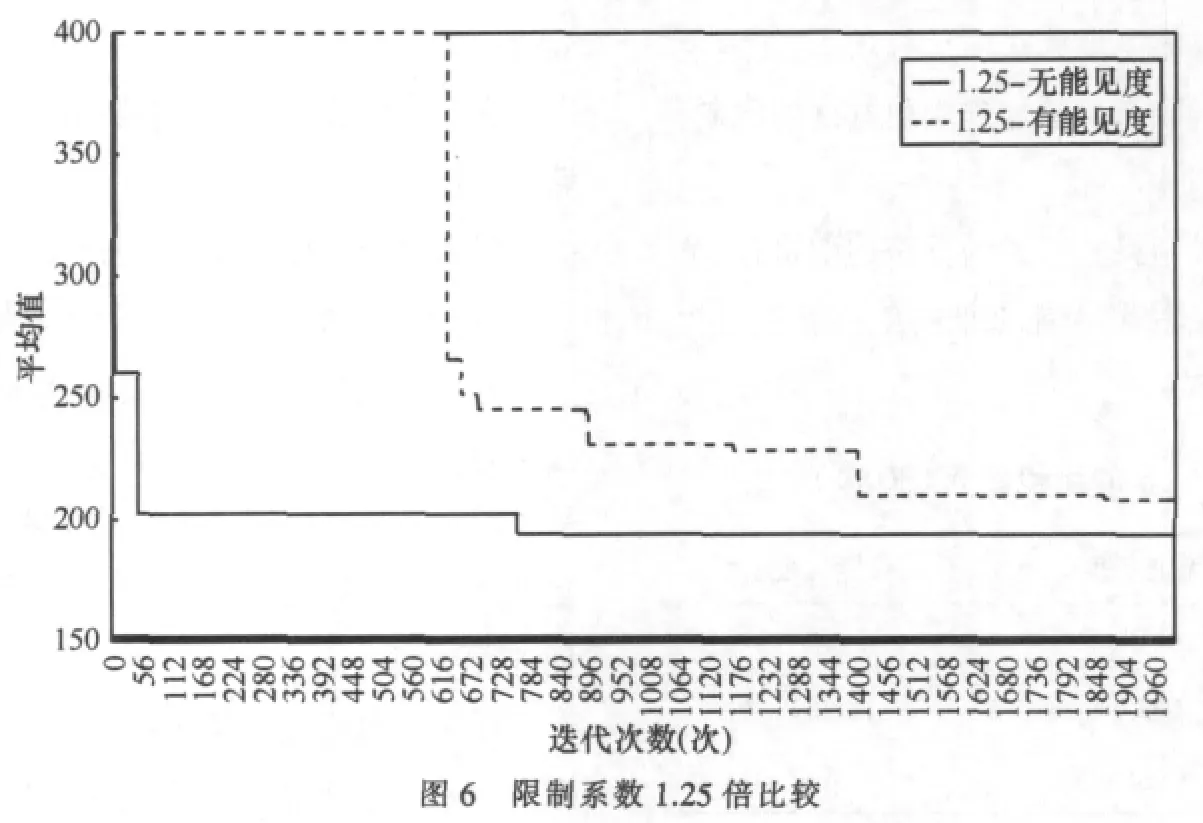
该图采用了与图5不同的x轴刻度单位,其原因是在更严格的长度限制下,有能见度的经典蚁群算法需很长时间才能找到目的地。
图6的曲线仅为某次结果,考虑到算法的随机性,分别使用有能见度的蚁群算法和无能见度的蚁群算法进行80次实验,得到表2的结果。
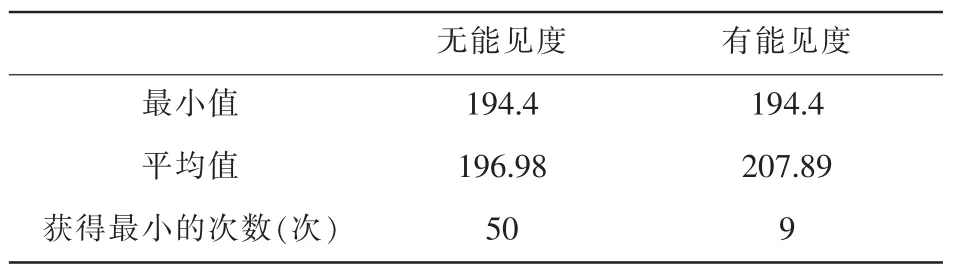
表2 限制系数1.25的比较结果(80次)
不同限制路径长度对结果有一定影响:当限制路径较短时,获得最优值的次数增加,但平均值有所下降,其原因是蚂蚁致力于寻找最小路径,一旦某次路径超过最小要求就死亡,因此成功率反而有所下降。
从有能见度的式(1)可以看出,该算法偏向于选择较短的边,而很难发现那些长边、少跳数的路径,也即经典算法偏向于短边、多跳的路径,所以采用长度限制才能公平比较两种算法。
5.2 短边多跳实验
总的来说,实验1和2不利于有能见度算法,以下的2个实验的网络设置则有利于该算法。
仍然保留那条8跳的路径,其中有几条长度较大的边(大于24),该路径的总长度为194.4;但是另有一条18跳,每边都较短,总长度为190的最短路径,其余路径的跳数都不低于14跳。
5.2.1 实验3
在这个实验中,规定蚂蚁的生存周期内其已经走过的路径长度为:
限制路径长度=14×平均边长18×系数1.5跳 =378分别使用有能见度的蚁群算法和无能见度的蚁群算法进行实验,得到图7的曲线。
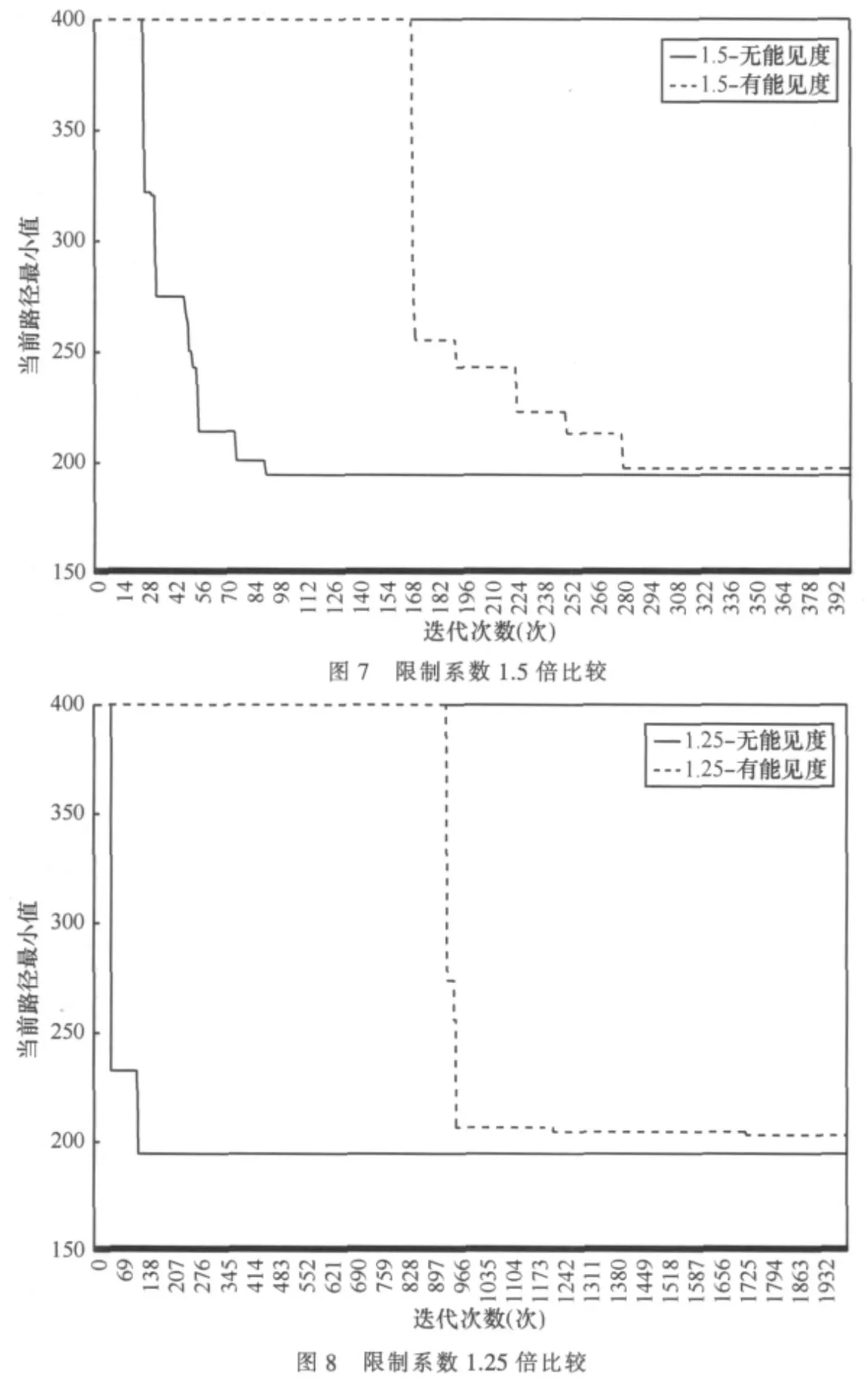
图7的虚线反映了有能见度算法的运行状态,实线反映了无能见度算法的运行状态,考虑到版面宽度的限制,仅仅绘制到400代。
图7的曲线仅为某次结果,考虑到算法的随机性,分别使用有能见度的蚁群算法和无能见度的蚁群算法进行80次实验,得到表3的结果。

表3 限制系数1.5的比较结果(80次)
5.2.2 实验4
在这个实验中,规定蚂蚁的生存周期内其已经走过的路径长度为:
限制路径长度=14×平均边长18×系数1.25跳 =315
本实验采用的网络与实验3相同。
分别使用有能见度的蚁群算法和无能见度的蚁群算法进行实验,得到图8的曲线。
图8采用了与图7不同的x轴刻度单位,其原因是在更严格的长度限制下,有能见度的经典蚁群算法需很长时间才能找到目的地。
图8的曲线仅为某次结果,考虑到算法的随机性,分别使用有能见度的蚁群算法和无能见度的蚁群算法进行80次实验,得到表4的结果。

表4 限制系数1.25的比较结果(80次)
从实验3和4的结果可以看出:在短边多跳的条件下,有能见度的蚁群算法的性能好于实验1和2,但是其仍然不如无能见度算法。经过仔细分析有能见度算法的多次运行结果,发现该算法有不少次数找到一条长度为198的路径,该路径上有不少较短的边,从而导致算法限于局部极小。
6 结束语
多种情况下的仿真实验结果表明,去掉能见度的蚁群算法获得最短路径的次数明显好于经典的蚁群算法,能见度容易导致局部极值。去掉能见度的蚁群算法的平均值也优于经典的蚁群算法,这也是获得最小值次数较多的原因。总之,在开放式的网络拓扑结构中,去掉能见度的蚁群算法明显优于经典的蚁群算法,这也意味着去掉能见度的蚁群算法更适合应用在大型网络中。
目前的各种蚁群算法(包括本文提出的去能见度蚁群算法)都是单目蚁群算法,即蚂蚁从一个源节点寻找到一个目的节点的最佳路径。然而,在分布式非结构化P2P文件共享系统中,大多数情况下,会有很多个节点拥有同一个想要下载的文件,这些都是候选目的节点,且它们的数量是未知的(对于源节点而言)。显然,在这种情况下不但存在路径优化问题,还存在目的节点选择问题。在将来的研究工作中,将提出一种新型蚁群算法,集资源搜索、选择目的节点和路径优化于一体。
参考文献
1 Dorigo M,Maniezzo V,Colorni A.Ant system:optimization by a colony of cooperating agents.IEEE Transactions on Systems,Man and Cybernetics,Part B:Cybernetics,1996,26(1):29~41
2 Stützle T,Hoos H.The max-min ant system and local search for the traveling salesman problem.Proceedings of IEEE-ICEC-EPS’97,IEEE International Conference on Evolutionary Computation and Evolutionary Programming Conference,IEEE Press,1997:309~314
3 Stützle T,Hoos H.Improvements on the ant system:introducing max-min ant system.Proceedings of the International Conference on Artificial Neural Networks and Genetic Algorithms,Springer Verlag,Wien,1997:245~249
4 Stützle T,Hoos H.Max-min ant system and local search for combinatorial optimization problems.Meta-Heuristics:Advances and Trends in Local Search Paradigms for Optimization,Kluwer,Boston,1998:137~154
5 Stützle T.Max-min AntSystem forQuadratic Assignment Problems.Technical Report AIDA-97-04,Intellectics Group,DepartmentofComputerScience,DarmstadtUniversity of Technology,Germany,1997
6 吴庆洪,张纪会,徐心和.具有变异特征的蚁群算法.计算机研究与发展,1999,36(10):1 240~1 245
7 Marcin L P,Tony W.Using genetic algorithms to optimize ACSTSP.Proceedings of 3rd Int Workshop ANTS,Brussels,2002:282~287
8 Chi-Jen Wu,Kai-Hsiang Yang,Jan-Ming Ho.An ant search algorithm in unstructured Peer-to-Peer networks.Proceedings of the 11th IEEE Symposium on Computers and Communications,2006
9 Junqing Li,Quanke Pan,Shengxian Xie.Research on peer selection in Peer-to-Peer networks using ant colony optimization.Proceedings of the Fourth International Conference on Natural Computation,2008
10 Walter J,Gutjahr.ACO algorithms with guaranteed convergence to the optimal solution.Information Processing Letters,2002(82):145~153
11 吴湘宁,汪渊.基于蚁群算法的P2P文件共享系统.计算机工程与应用,2007,43(20):145~148
12 刘萍,高飞,杨云.基于遗传算法和蚁群算法融合的QoS路由算法.计算机应用研究,2007,24(9):224~227
13 刘永娟.改进蚁群算法在QoS路由中的应用与研究.通信技术,2008,41(9):128~133
14 陈岩,杨华江,沈林成.基于再励学习蚁群算法的多约束QoS路由方法.计算机科学,2007,134(15):25~44
15 杨华江,陈岩,沈林成.基于改进蚁群算法的多约束QoS路由方法.计算机应用与软件,2008,25(5):15~17
16 Wu C J,Yang K H,Ho J M.Antsearch:an ant search algorithm in unstructured peer-to-peer networks.Proceedings of the 11th IEEE Symposium on Computers and Communications,Cagliari,2006:429~434
17 Wu G Y,Liu J Y,Shen X,et al.ERAntBudget:a search algorithm in unstructured P2P networks.Proceedings of the Second InternationalSymposium on IntelligentInformation Technology Application,Shanghai,2008:765~769
18 Li J Q,Pan Q K,Xie S X.Research on peer selection in peer-to-peer networks using ant colony optimization.Proceedings of the Fourth International Conference on Natural Computation,Jinan,2008:516~520
19 Cao Y,Li S Z.Research on P2P hybrid information retrieval based on antcolony algorithm.Proceedings ofthe 10th International Conference on Computer Supported Cooperative Work in Design,Nanjing,2006:1 048~1 052
20 刘萍,高飞,杨云.基于遗传算法和蚁群算法融合的QoS路由算法.计算机应用研究,2007,24(9):224~227
21 焦利,林宇,王文东等.一种负载均衡网络中内部链路时延推测算法.软件学报,2005,16(5):886~893
22 郭小雪,秦勇,蔡昭权等.多链路时延反馈共享令牌流量拥塞控制.计算机工程与应用,2010,46(2):75~78
