基于多核处理器的高清实时MPEG-2—H.264转码器设计
2012-09-17叶朝敏陈颖琪高志勇
叶朝敏,陈颖琪,高志勇
(上海交通大学电子工程系图像通信与信息处理研究所,上海 200240)
随着网络与个人通信终端的发展,人们对于视频的要求已经越来越强烈。H.264视频压缩标准在提供了优异的压缩比的同时,保证了出色的解码视频质量,是窄带视频传输的理想选择,已经越来越广泛地应用于在线视频中。与此同时,目前已有的视频数据源,包括电影、电视等依旧采用MPEG-2编码。如果可以将MPEG-2视频源转化成为H.264,则可以极大地扩充H.264的节目来源,进一步丰富人民群众的精神文化生活。
H.264的出色性能是建立在庞大的运算量的基础上的,H.264虽然比MPEG-2节约了约50%的码率,但是付出的代价却是MPEG-2 3倍以上的编码计算复杂度。对于高清(本文特指分辨率为1 920×1 080的视频)实时的MPEG-2至H.264转码器,目前尚未有快速高效且效果显著的快速转码算法,采用全解全编的转码器又面临着庞大的计算复杂度的问题。
并行计算为实时实现高清MPEG-2至H.264转码器提供了切实可行的解决方案。良好设计的并行转码器可以提供接近线性的加速比,即便对于计算量最大的全解全编转码器,利用目前常见的四核处理器也能在原先1/4的时间内完成转码,对于核数更多的处理器,则能更进一步实现多路高清实时转码。
本文针对以往研究中存在的问题,提出并实现了1种采用了帧级、片级与数据级混合并行的多粒度高清实时全解全编转码方案,并在Tilera[1]公司Tile Pro64同构多核平台上成功应用。
1 研究现状
在并行程序设计中,功能分解与数据分解是常用的2种方法。具体到编解码器设计中,1帧数据通常由若干个宏块行组成,因此具有天然的数据可分解性。编解码器采用了模块化设计,每个功能模块任务明确,具有较好的功能可分解性。
在MPEG-2解码器设计中,最常用的并行设计方法是帧内数据分解。由于MPEG-2码流中1帧内各个宏块行(片)的解码互不相关,因此可以将不同宏块行的解码任务放在不同的核上进行[2]。
采用帧间并行的MPEG-2解码设计则相对复杂。解码器设计中,由于运动向量搜索范围可以包含一整帧数据,P帧的解码有可能需要用到I帧的完整数据,因此I帧与P帧之间很难实现并行。然而对于IBBPBBP的码流结构,可以在所有B帧的参考帧均解码完毕之后,对所有B帧进行帧级的并行解码[3]。对于非实时码流,采用GoP分组也是1种可行的帧间并行方案[4]。
除此之外,并行MPEG-2解码器还可以采用基于功能分解的设计方案,即采用流水线设计,将解码过程的不同模块分配到不同的核上以实现并行。然而功能分解的可扩展性较差[5],因此基于功能分解的编解码器研究并不多。
并行H.264编码器的研究主要突破点同样在于数据分解。数据分解重点在于设计并行的颗粒度:颗粒度过大,则容易出现空闲核等待状况;颗粒度过小,则会出现通信量过大,影响CPU真正执行编解码核心任务。
早期的研究主要集中于单一颗粒度的并行。从颗粒度最大的GoP级帧间并行[4],到颗粒度降低的帧级并行与片级并行[6-7],一直到颗粒度更低的宏块或者宏块组级并行[3,8-9],甚至于为加速编解码而引入的指令集(本文中也称为数据级)并行[10],均有相关文献发表。单一颗粒度的并行一定程度上提高了编码速度,然而很遗憾的是此种并行引入的并行加速比均较为有限。
相比较单颗粒度并行,采用多颗粒度的并行编码器则展现出了优异的性能。混合采用B帧并行、片级并行、宏块级并行以及数据级并行的设计在码率增长4%的基础上获得了34倍左右的性能提升[3]。事实上,各级并行虽然较为独立,但是在编码过程中可以完美地融合在一起。帧级并行调用帧内并行,帧内并行调用宏块级并行,宏块级并行调用数据级并行,各级并行完成各自任务,最终完成编码。多颗粒度并行编码器中,可以通过良好的任务分配,保证适中的颗粒度,避免出现过久的空闲和等待,并且也不会出现通信量过大的情况。
本文实现了1种全解全编的实时并行MPEG-2至H.264转码器。在解码端,可以对任何符合MPEG-2标准的码流进行解码;在编码端,目前仅支持Baseline的H.264编码。本文的MPEG-2并行解码器采用了常见的片(1个宏块行)级并行与数据级并行混合并行算法,H.264编码器则采用了独特的帧级并行、片(若干个宏块行)级并行、数据级并行的多粒度混合并行模型。
2 并行转码器设计方案[11-12]
本设计由主线程与包含若干个线程的线程池以及包含若干个任务的任务池组成。其中主线程负责初始化线程池以及创建帧级并行任务等,任务池负责完成具体的编解码任务。为了管理好任务池,本设计中实现了1个用户态的调度器。调度器遍历任务池查找依赖性满足的,即可以被执行并行任务并分配给空闲的线程执行,对应线程完成该任务之后便会将该任务移除出任务池。
2.1 并行MPEG-2解码器设计
在MPEG-2码流中,1个宏块行为1个片(Slice),码流start_code中包含了片的序号,其变化范围由slice_min_start_code,slice_max_start_code确定。由于各个片之间不具有任何相关性,因此MPEG-2码流具有天然的帧内可并行性。
在解码分辨力为1 920×1 080的高清码流时,共有[1 080/16]≈68个片,如果以每个片的解码作为1个基本的并行任务,每1个基本并行任务颗粒度较小,总计有68个并行基本任务,对于核数少于8的处理器而言,任务数已经足够,因此不再引入帧间并行。当处理器核数更多时,可以引入基于B帧的帧间并行[3],进一步提升基本并行任务个数,以便进一步提高加速比。
单独的并行MPEG-2解码器流程图如图1所示。
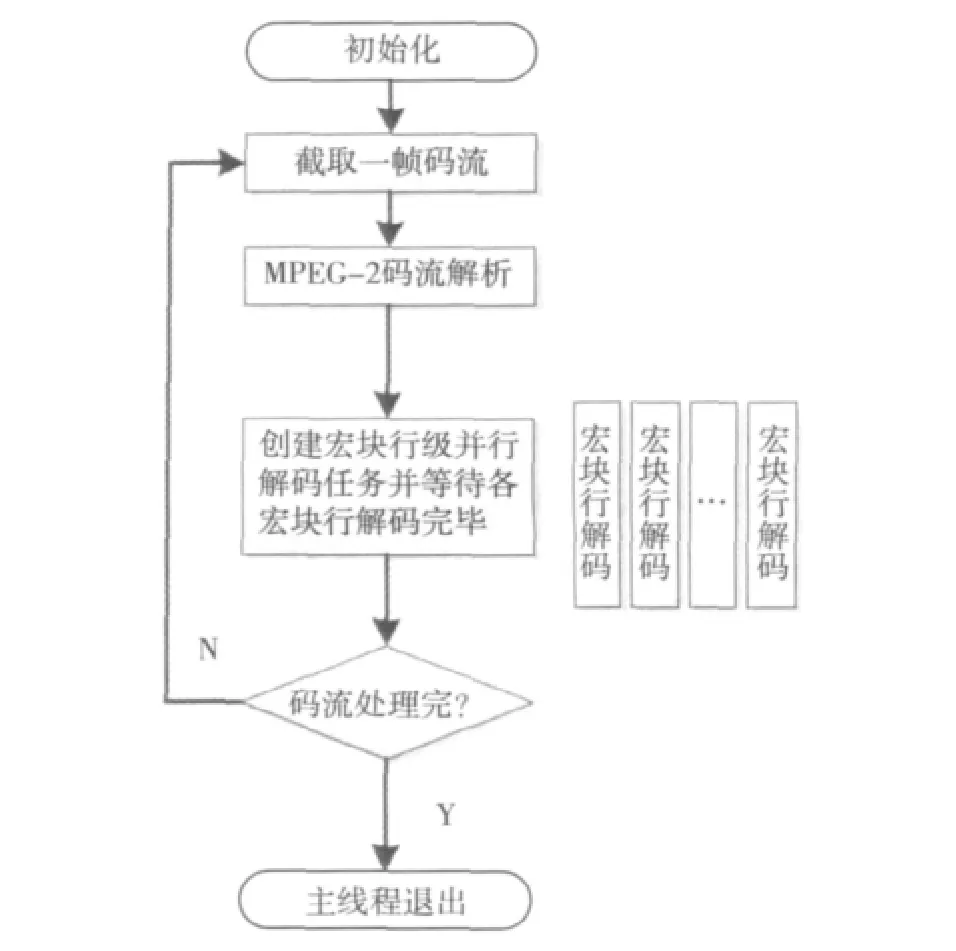
图1 并行MPEG-2编码流程图
主线程首先从输入码流中通过搜索截出解码1帧所需的码流数据,随后对截出的码流进行解析,在解析到slice_header的时候开始创建片级并行任务,各个片级任务经调度器管理在不同的线程上独立完成,主线程在等待1帧的所有片均解码完并输出1帧之后开始解码下1帧,如此往复,直至码流解码完毕。
2.2 并行H.264编码器设计
2.2.1 帧级并行
运动搜索引入的帧间依赖性阻碍了帧级并行的实现。为了解决此问题,可以将1帧数据进行分片编码,人为规定运动向量搜索范围为其参考帧对应的片的高度。假设1帧的每1个片由numMbr个宏块行组成,为了保证数据的依赖性得到满足,第N帧开始编码后,第N+1帧可以在第N帧的[numMbr/2]宏块行编码完成之后才开始编码。在第N+1帧编码到某一个Slice时,会检测第N帧对应的Slice是否已经编码完成(此处只考虑Baseline不包含B帧的情形,如果包含B帧,则需要检测第N+1帧所依赖的参考帧对应的Slice编码完成情况),只有在第N帧对应的Slice已经编码完成后才会真正开始对第N+1帧进行编码。
本文实验所用的多核平台为同构多核,各核处理速度可认为一致,第N+1帧由于落后第N帧[numMbr/2]个宏块行,因此第N+1帧的某个Slice需要等待第N帧对应Slice编码完成的可能性比较小,帧间并行性非常高。另一方面,由于每1帧相对于前1帧编码都要落后[num-Mbr/2]个宏块行的处理时间,因此无限增加帧间并行以提高速度意义不大。实际实现时需要根据核的个数调整可以并行的帧数。
2.2.2 片级并行
如前所述,本设计将1帧数据分成若干个片进行独立编码。1个帧级编码任务仅仅是接收来自上层的参数并根据对应的参数创建多个片级编码任务。调度器随后将片级的编码任务分发到各个核上同时执行,各个片编码完成之后再将各个片的码流重组在一起进行输出(例如写入文件或者封包成RTP数据包)。
产生了片级的并行任务之后,可以根据核的个数决定是否采用更小粒度的并行。如果并行帧数为4,帧内片数为14(即5个宏块行为1个片),则理论上最多同时有4×14=56个颗粒度较小的并行任务,对于10个核以下的处理器,任务数已经足够。此外,引入分片之后,由于帧内相关性降低[3,9],会导致编码之后码率增大,因此虽然分片可以增大并行加速比,但是不可能为了提高编码速度无限提高分片数。实现时分片数可以根据具体性能予以调整。
对于本设计,并行任务细化到片级并行任务时任务数已经足够,因后不再进行粒度更小的宏块级并行。此时1个片级并行任务包含了如下功能:
1)接收来自上层的参数并存取。由于采用了并行设计,很多参数都会随着并行的出现发生改变,因此在进行真正的片级编码之前,需要首先备份来自上层的有关参数。
2)帧内数据从变换量化预测补偿到熵编码的一整套编码流程。每片的编码任务仅仅会在该片所需数据已经准备就绪的时候才开始,因此一旦并行任务开始执行时,该片编码已经不用考虑依赖性问题,保证了高效并行。
3)各片已编码码流整合。分片编码之后需要按照各片顺序将码流重组最后有序输出。
2.2.3 数据级并行(指令级并行)
数据级并行,或者指令级并行,是指利用处理器提供的多媒体处理指令集(例如Intel SSE/SSE2指令集、Tilera[1]公司的SIMD指令集等)中提供的SIMD(Single Instruction Multiple Data)指令对编码过程中的一些核心计算模块进行优化所引入的并行。
采用数据并行不需对编码器并行框架进行任何修改,使用方便,但是所引入的并行加速比却非常可观。本设计采用Tilera公司SIMD指令优化离散余弦变换、运动补偿、去块滤波、量化等模块之后,可以引入5倍以上的并行加速比提升。然而由于指令集并行涉及模块多,且数据并行的加速比提升受限于上层编码器设计,因此很难事先估计单纯引入指令集所带来的并行加速比。
2.3 并行转码器设计
并行转码器设计流程图如图2所示,图中粗箭头是指在线程任务池中完成的任务。
解码函数并行框架类似于图1中所示的单独解码器,解码函数与编码函数之间的联系除了用于缓存解码器输出的YUV缓冲区以及YUV缓冲区对应的可读可写标志之外,再没有别的联系。此外,具体的并行解码任务与并行编码任务都被放置在线程任务池中,由调度器统一管理。具体流程描述如下:
1)主线程首先初始化MPEG-2解码器与H.264编码器,创建YUV缓冲区队列并设置所有缓冲区可写标志,随后读入MPEG-2码流。
2)主线程检查YUV缓冲区队列对应YUV缓冲区是否可写。若可写,则调用并行解码函数解析码流并创建并行解码基本任务(在主线程中)。若不可写,即代表该缓冲区正在被编码器使用,解码器暂停直至该缓冲区可写标志重新被设置。
3a)主线程等待一帧数据解码完毕。
3b)调度器调度各线程执行具体的解码任务。
4a)1帧数据解码完毕之后主线程输出解码产生的YUV数据至YUV缓冲区中并清空该缓冲区对应的可写标志。之后主线程调用编码函数创建帧间并行任务。主线程随后继续解码下1帧。
4b)调度器调度线程执行帧间并行任务以及其后的片级并行任务。1帧YUV数据编码完毕之后输出该帧码流并设置缓冲区可写标志。
上述流程中,包含3b)的任务是计算量最大的任务,由调度器管理,由各工作线程完成,其余任务由主线程完成。上述流程除了4a)依赖于3b)之外(不包括由于缓冲
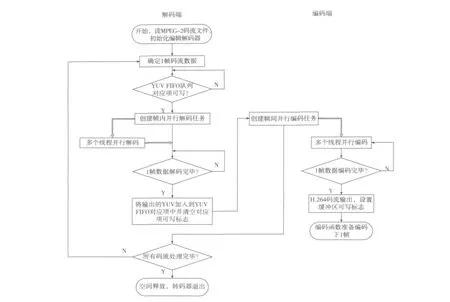
图2 转码器流程图
区引入的等待),主函数与线程任务池之间没有依赖。从而保证了二者都可以各自执行自己的任务,提高了效率从而保证了较高的并行性。实际实现时,YUV缓冲区队列的长度可以根据具体性能以及可用的内存资源确定一个较为合理的值:当缓冲区队列长度较小时,容易造成编码器与解码器过多的等待,影响转码器性能;而队列过长,并不能带来太多性能的提升,反而造成内存资源的浪费。
3 Tilera平台并行转码器实现
3.1 Tilera平台简介
本设计的实现平台即采用Tilera公司Tile Pro64处理器的计算服务器。该处理器由64个同构的核构成,单核频率最高为866 MHz。核间通信通过Tilera公司独特的核间互联技术实现,保证了极高的吞吐率与极小的时延,是实现多核设计或者众核设计的出色的实验平台。此外,服务器共有4个DDR2 667控制器,每个控制器控制2 Gbyte内存,共8 Gbyte内存。
3.2 Tilera平台并行转码器性能
本设计测试了3个 MPEG码流,即:CrowdRun(25 Mbit/s),Tractor(25 Mbit/s)以及 Life(25 Mbit/s),转换之后的H.264码流码率为6 Mbit/s。
通过比较YUV缓冲队列长度对于转码性能的影响,最终确定的YUV缓冲区队列长度为4。
3.2.1 并行线性
并行线性是指并行设计的加速比随着核数的增多而线性增长的性质。对于一个并行设计的转码器而言,线性无疑是最重要的性质。对相同码率不同码流转码速度的测试结果如图3所示。

图3 相同码率不同码流转码结果
可以看到,在核数较少的时候(10个核以下),本设计有着接近线性的并行加速比:10个核时加速比达到了9.8。随着核数的增多,核间通信以及不同任务之间同步随之增多,处理器进行真正编解码工作的时间减少,并行加速比提升逐渐放缓,16个核时,并行加速比为12.8。可以想象,随着核数的增多,并行加速比增加的趋势会逐渐趋缓直至最后缓慢下降。本设计在16个核时即可满足实时高清转码的需求,为了充分利用处理器资源,可以使用处理器进行多路并行转码。
3.2.2 转码实用性
转码器实用性取决于转码器的速度以及转码的有效性,即转码前后视频的质量差。前者取决于并行设计的线性,后者则主要取决于MPEG-2与H.264标准本身。
使用16个核对3个高清MPEG-2码流进行转码测试,所得结果如表1所示。

表1 16个核转码速度
从表1可以看出,对于运动较复杂的Crowdrun序列,本设计平均转码速度依然达到了30 f/s以上。实验显示,采用18个核时便可使该序列的每1帧都在1/30 s的时间内完成转码,从而满足实时性要求。
为了进一步验证转码有效性,图4列出了转码前后图像的对比,该图像来自于码流中的第10帧图像。

图4 转码前后图像对比图
4 总结
本文设计并在TilePro64平台上实现了1种MPEG-2至H.264的全解全编并行转码器。其中MPEG-2解码采用了片级并行与数据级并行,H.264编码采用了帧级、片级以及数据级混合并行。实验表明,本设计有着出色的并行加速比,并且在只占用TilePro64处理器中1/4数量的核的时候,即可实现1路高清实时转码。
:
[1]Tilera[EB/OL].[2012-03-20].http://www.tilera.com/.
[2]许洁斌,韦岗,布礼文.多处理器MPEG2并行解码系统的设计[J].数据采集与处理,1998,13(4):367-373.
[3]于海清,李江,魏海涛.基于同构多核处理器的H.264多粒度并行编码器[J].计算机学报,2009,32(6):1100-1109.
[4]蒋兴昌,周军,罗传飞.H.264并行编码算法的研究[J].电视技术,2008,32(2):33-35.
[5]LIN C,SNYDER L.Principles of parallel programming[M].陆鑫达,林新华,译.北京:机械工业出版社,2009.
[6]GE S,TIAN X,CHEN Y K.Efficient multithreading implementation of H.264 encoder on Intel hyper-threading architectures[C]//Proc.the 2003 Joint Conference of the Fourth International Conference.[S.l.]:IEEE Press,2003:469-473.
[7]CHEN Y K,TIAN X,GE S,et al.Towards efficient multi-level threading of H.264 encoder on Intel hyper-threading architectures[C]//Proc.the 18th InternationalParalleland Distributed Processing Symposium.[S.l.]:IEEE Press:63-72.
[8]孙书为,陈书明.高效的H.264并行编码算法[J].电子学报,2009(2):357-362.
[9]冯飞龙,陈耀武.基于H.264实时编码的多核并行算法[J].计算机工程,2010(24):226-227.
[10]ZHOU X,LI E Q,CHEN Y K.Implementation of H.264 decoder on general purpose processors with media instructions[C]//Proc.the SPIE Conference on Image and Video Communications and Processing.Bellingham:SPIE-IS&T,2003:224-235.
[11]田韬,李鹏,张悠慧.H.264并行解码的设计与实现[J].微计算机信息,2008(14):114-115.
[12]郭倩,陈耀武.基于功能模块的H.264并行解码算法[J].计算机工程,2010(23):231-233.
