基于信用机制的网络用户管理方法研究
2012-07-25郭延锋
郭延锋,孙 娜
(辽宁工业大学 电子与信息工程学院,辽宁 锦州121001)
0 引 言
传统网络管理往往是针对网络进行操作、监督、维护和提供网络操作系统以及相关软件[1]。这些年,随着网络信息化迅猛发展,网络用户数量呈现指数级增长,这也使得如何更好、更高效地管理网络成为网络管理的难点和国内外学者研究热点。在现有的网络管理机制中,网络管理员起到了举足轻重的作用,但是面对成千上万网络用户时,管理员往往表现出力不从心,因为他们不仅仅要维护网络系统的稳定,还要应对各种网络病毒和攻击。
个人信用管理模型最早产生在美国,伴随着世界金融的发展,目前已在金融领域广泛使用,例如保险业,银行业等。金融机构通过分析客户在一定时间内的消费行为,对客户进行个人信用评估,最终建立个人信用评估系统,并利用其用户进行管理和分类,为金融决策提供支持。随着信用评估技术的发展,目前已经产生了很多信用分析和管理的方法,例如,线性概率方法,人工神经网络 (artificial neural networks,ANN)和数学规划方法等[2-4]。其中最为流行和被行业认可的是人工神经网技术,由于其高准确率和稳定性被广泛使用[5-10]。支持向量机 (support vector machine,SVM)是人工神经网络技术之一,它继承了人工神经网络的优点并结合有监督学习方法,对分类和预测问题效果明显[11],目前多用于解决各类实际问题,例如模式匹配,生物医学等。
本文提出一种新的网络用户行为管理方法。该方法利用信用模型并结合网络用户行为,对用户进行信用评估,并给出相应的信用值,通过对信用值排序和分析,对网络用户进行管理,这样大大减轻了网络管理员的工作强度,提高网络运行的稳定性。实验结果证明了基于信用的管理用户模型的可行性和有效性。
1 SVM模型
服务器中的网络日志可以看成一种高维时间序列,其中记录着网络中用户的任何网络行为,并且随着时间而更新,考虑到日志中各个属性之间的关系复杂性和数据的海量性。传统方法,尤其是基于数学统计和概率的,因其自身的不可学习性和自身调节不灵活,往往显得力不从心。
1998年Vapnik等人首次提出支持向量机模型,该模型本身是一种基于空间风险和时间风险最小化原则的机器学习算法,通过多年发展,其泛化能力和鲁棒性大大增强,并且在不同领域使用反馈来看表现优异[12]。支持向量机模型的基本思想是基于Mercer定理,通过非线性变换函数将输入向量从低维空间映射到高维空间中,并根据结构风险最小化原则构造最优线性回归函数,即最优分类超平面。最优分类超平面必须满足能够尽可能多的将两类数据点正确分开,同时使分开的两类数据点距离分类超平面最远[13]。
假设给定训练样 本:(x1,y1),(x2,y2),...,(xn,yn),其中xi∈Rn是样本输入向量值,yi∈R是样本输出 (即类别标签),支持向量机模型的决策函数可以表示为

式中:w——权值向量,b——函数偏置常量。
由于最优超平面必须满足向量到超平面距离最大的原则,因此支持向量模型在高维空间求最优分类超平面问题可以表示为

式中:‖w2‖——结构风险,代表模型的复杂程度,使函数变化曲线更为平缓,提高鲁棒性能力;——经验风险,代表模型的错误分类;C——惩罚系数,ξi——松弛系数。
其对偶问题采用拉格朗日方法进行求解,式 (2)变为

当样本点无法被线性可分时,SVM模型将原始样本集通过一个非线性映射函数φ(x),映射到高维特征空间中,在此空间中进行线性分类。在高维空间中使用核函数进行内积运算,核函数表示为K(xi,xj)=φ(xi)·φ(xj),因此高维空间的计算只需在原低维空间进行核函数运算即可,则式 (3)修改为
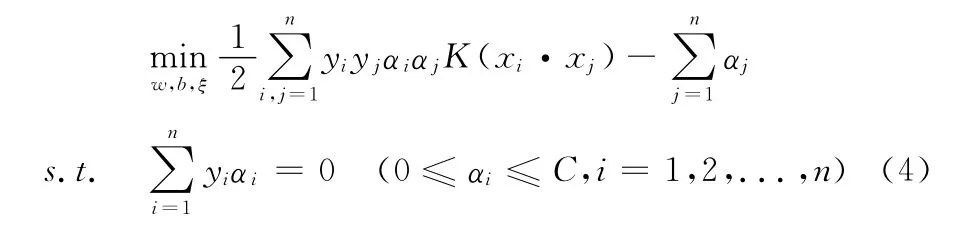
得到最优解α*=(α*1,α*2,...,α*n)T。
选取的α*一个小于C的正分量α*j,计算
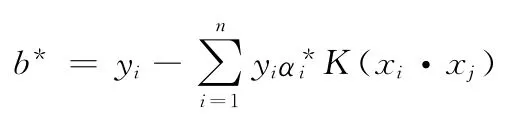
则SVM分类决定函数表示为

常用的SVM核函数包括,线性核函数、多项式核函数、Sigmoid核函数和高斯径向基核函数 (RBF)[14-16]。
2 基于信用的网络用户管理
利用个人信用进行决策和分析,目前在金融领域已广为应用,产生了很多方法和工具。尤其是2008年美国经济危机爆发以后,如何更好的利用信用机制去管理客户和为金融决策服务成为新的研究热点。本文首次在网络用户管理中引入个人信用管理机制,在传统网络管理方式的基础上有所突破,为网络管理提供了一个新的思路。方法整体流程如图1所示,主要包括3个部分,首先是使用网络数据训练集对支持向量机模型进行训练;其次是优化支持向量机模型内部参数以提高分类准确率;最后是根据模型的分类结果对网络中用户进行信用评估。

图1 信用模型整体流程
个人信用网络管理具体步骤如下:
(1)使用公开的网络数据:在本文中,为了保证算法的有效性和可重复性,我们使用公开的网络数据KDD CUP 99作为基本数据,此数据集包含了丰富的网络用户行为信息,并且数据是平衡的 (正常的数据数量和异常的基本相等)有利于此后对模型训练和分析。
(2)训练支持向量机模型:为了保证网络数据各维度之间关系的完整性,尽可能的减少数据损失,本文中我们没有对数据进行归一化和降维处理,而是直接使用原始数据,通过随机抽取的方式产生出训练集和测试集。而支持向量机模型,我们使用比较流行的LIBSVM作为实验工具。通过使用不同核函数,我们构成了3种不同的支持向量机模型。在训练的过程中,将数据直接输入到模型中,并进行训练,建立一个粗糙的模型,并比较这3种不同内核SVM模型的分类准确率高低。
(3)参数优化和构建信用模型:由于SVM自身的特点,因此对SVM模型参数进行寻优是十分重要和必要的步骤。在本文中我们使用的SVM模型属于C-SVM类型,因此更有必要对其优化。试验中使用网格优化 (grid search)算法对参数 (C和g)寻优以提高模型的分类准确率。
(4)用户信用值计算:支持向量机模型建立并进行优化后,将测试集输入到SVM模型中,通过计算将网络数据进行预测分类,分为正常 (+1)和异常 (-1)两类,而后使用数据向量到超平面的距离作为信用度量,进行信用评估。
(5)利用信用进行网络管理:使用步骤 (4)提供的信用评估结果进行汇总分析,进而对网络用户进行管理。针对低信用值用户加强管理,甚至采取断网等极端措施,而对信用度好的网络用户则减少管理或不需要管理。
使用信用机制作为管理手段,主要是从心理学角度上来控制和规范网络用户的行为,并且在将来可以引入类似于足球升降级制度,对网络用户信用值进行动态调整。
3 实验结果及分析
本实验使用KDD CUP 99数据集作为原始数据集,此数据集是完全公开的,可从UCI数据库中获得 (http://archive.ics.uci.edu/ml/datasets/KDD+Cup+1999+Data),此数据集包含494021条记录,每条记录42维。试验中我们将数据分为两类,一类是正常网络连接,另一类是异常连接,例如网络攻击等,分别用+1和-1表示。为了方便运算,本试验中,我们从原始数据中分别随机抽出20000条记录作为训练集和2000条数据作为测试集。
3.1 核函数选择
由于SVM模型核函数对实验结果的重要性,因此我们首先使用不同的核函数进行比较试验,以便从中挑选出最合适核函数,为模型所用。试验结果如表1所示。

表1 不同核函数比较
从表1中我们可以看到,在没有对支持向量机模型参数优化的前提下,这4个核函数中RBF核函数准确率最高,达到了90.2%,Sigmoid核函数准确率最低仅77.6%,而Line核函数与Polynomial核函数准确率几乎一样,因此通过比较我们选择RBF作为信用模型的核函数,为下一步做准备。
3.2 SVM模型参数优化
除了核函数外,影响SVM模型分类准确率另一个因素是模型内部的变量,因此为了进一步提高模型分类准确率我们还应该对模型参数进行寻优操作。
本次试验中为方便计算,我们使用网格寻优算法对模型中惩罚系数C和RBF核函数参数g进行寻优,具体来说使用交叉验证 (cross validation)[13]方法对进行两次寻优。第一次为粗寻优,C和g的变化范围都是2-10,2-9,…,29,210,搜索结果如图2所示,其中x和y轴分别表示C和g取以2为底的对数后的值,等高线表示取相应的C和g所得到的准确率,从图2中可看到把C缩小到2-2到24,同时g的范围可以缩小到2-4到24,这样在粗选参数的基础上可以进行二次寻优。在第二次寻优中我们限定C的变化 范 围 为 2-2,2-1.5, …,24,g的 取 值 范 围 为 2-4,2-3.5,…,24,最终寻优结果如图3所示。

通过两次寻优操作对SVM模型进行优化,可以更为精准的获得参数C和g的最优值,从而保证信用模型的准确性和可靠性。
3.3 网络用户信用评估
由于网络数据是实时的、海量的,因此为了锁定网络用户身份,在具体实践中,我们使用IP地址和MAC地址捆绑方式来识别用户,作为用户的身份标识,并且在实际应用中发现,使用支持向量机模型分类后,距离超平面距离较远的数据,往往是比较稳定的,即非常好或非常坏的。因此我们可以通过计算数据向量点到超平面的距离作为信用度量标准,对同一用户在一定时间内的信用均值作为其信用值。从整体角度,按照信用值进行排序,从中选择信用最差的用户 (例如选100个)加强跟踪和管理,而对于信用好的用户则减少或不进行管理,这样做将大大减轻网络管理员的工作负担。信用排序如图4所示。右下角表示信用差的用户分布,从图4可以看出,大部分用户信用都可以,只有小部分用户信用值低,对网络产生危害。

图4 网络用户信用值分布
除了引入信用机制外,我们还引入升降级制度,在一定时间内对网络用户信用值进行动态调整,信用不好的用户若 “改过自新”,则可以成为信用度好的,同理信用好的用户也有可能变成差的,这样提高了网络用户管理的弹性和可靠性。
4 结束语
鉴于网络管理的重要性和必要性,本文提出了一种新的网络管理方法——基于个人信用机制的网络管理方法。尽管目前,个人信用评估机制已经广泛应用于金融领域,并取得了很好的效果,而在网络管理中目前还没有相关研究。本文通过实验分析表明,基于个人信用的网络管理方法可以在一定程度上减轻网络管理员的工作压力,提高网络整体的稳定性,并且由于针对网络用户行为控制,从根源上提高了网络的稳定性,也为未来网络管理发展提供了一个新的思路和发展方向。
[1]WANG J L,MING C D,John C S L.Credit-based network management[C].International Conference on Communication Systems and Networks and Workshops,2009:473-482.
[2]LING G.Insurance credit evaluation incorporated qualitative and quantitative information [C].2nd International Symposium on Computational Intelligence and Design,2009:68-72.
[3]Gutierrez P A,Hervas-Martinez C,Martinez-Estudillo F J.Logistic regression by means of evolutionary radial basis function neural networks[J].IEEE Transactions on Neural Networks,2010,22(2):246-263.
[4]MIN J H,LEE Y C.A practical approach to credit scoring[J].Expery System with Applications,2008,25 (2):1762-1770.
[5]PING Y.Hybrid classifier using neighborhood rough set and SVM for credit scoring [C].International Conference on Business Intelligence and Financial Engineering,2009:138-142.
[6]WU C,XIA H.Study of personal credit evaluation under C2C environment based on support vector machines ensemble [C].International Conference on Management Science and Engineering 15th Annual Conference,2008:25-31.
[7]ZHANG D,HIFI M,CHEN Q,et al.A hybrid credit scoring model based on genetic programming and support vector machines[C].4th International Conference on Natural Computation,2008:8-12.
[8]YU L,YUE W,WANG S,et al.Support vector machine based multiagent ensemble learning for credit risk evaluation[J].Expert Systems with Applications,2010,37 (4):1351-1360.
[9]KIM H S,SOHN S Y.Support vector machines for default prediction of SMEs based on technology credit [J].European Journal of Operational Research,2010,201 (3):838-846.
[10]Hsieh N C,Hung L P.A data driven ensemble classifier for credit scoring analysis [J].Expert Systems with Applications,2010,37 (1):534-545.
[11]WANG N,NIU D X.Credit card customer churn prediction based on the RST and LS-SVM [C].Xiamen:6th International Conference on Service Systems and Service Management,2009:275-279.
[12]LUO S T,CHEN B W,HSIEH C H.Prediction model building with clustering-launched classification and support vector machines in credit scoring [J].Expert System with Application,2009,36 (4):7562-7566.
[13]HUANG C L,WANG C J.A GA-based feature selection and parameters optimization for support vector machines [J].Expert Systems with Applications,2006,30 (2):231-240.
[14]CHOU P H,WU M J,Chen K K.Integrating support vector machine and genetic algorithm to implement dynamic wafer quality prediction system [J].Expert Systems with Applications,2010,37 (6):4413-4424.
[15]HUANG C C,CHUNG R G,CHEN R C,et al.Finding an optimal combination of key training items using genetic algorithms and support vector machines [J].Information Technology Journal,2010,9 (4):652-658.
[16]GUO L,XIAO H T,FU Q.SVM model optimal multi-parameter selection method for imbalanced data target recognition[J].Journal of Infrared and Millimeter Waves,2009,28(2):141-145.
