一种时序关联规则挖掘算法的研究与实现
2012-07-02方跃胜
董 辉,方 晓,方跃胜
(1.亳州职业技术学院信息工程系 ,亳州236800;2.安徽水利水电职业技术学院电子信息工程系,合肥231603)
0 引言
数据挖掘是致力于对各类海量数据集进行分析和理解,以发现数据内部所蕴含知识的过程,而关联规则挖掘一直都是数据挖掘领域的一项重要研究内容,也是数据挖掘技术中的一个研究热点,其主要目标是发现数据中项目之间的相关联系,研究成果被广泛应用于商业、金融、电信等领域[1]。在数据挖掘的各类对象数据集中,有一类数据集的数据之间存在着时间上的关系,是按时间顺序取得的一系列相互关联的观测值,它们反映了某个事务或事件随着时间变化的状态,其状态可以用实数值或符号来表示,此类数据被称为时间序列,简称时序。如果该数据序列是连续的,称之为连续时序;否则称为离散时序。本文主要研究时序值为实数的时间序列,即传统狭义时序。在各个领域中,时序是普遍存在的,并且随着信息技术发展以及人们获取数据手段的多样化,人类所拥有的时序信息急剧膨胀,如证券公司拥有的大量股票信息时序数据、交通路口实时影像数据、医疗设备脑扫描数据等都可看作是时序。在这些海量的时序数据中,隐藏着大量的知识或信息急需我们来获取。因此,研究、探索新技术或方法,有效地从这些复杂的海量时序中挖掘潜在的有益知识和信息,具有重要的理论价值和现实意义,是知识发现(KDD)中的重要分支之一[2]。
时序数据挖掘是挖掘时序数据中潜在的有用的知识或信息的过程,在这一过程中必须考虑数据集之中数据间存在的时间关系,但是因为时序数据具备动态性、复杂性、高维性、高噪声特性及容易达到大规模的特性,从而使得时序挖掘也是数据挖掘研究中最具有挑战性的研究方向之一[2]。美国UC Riverside的E.Keogh和 UI Urbana-Champaign的J.Han研究小组是目前时序研究领域最为活跃的群体。大约从2000年,国内复旦大学、浙江大学、中国科技大学等高校陆续进行了相关研究,但是比较零散而没有系统性。在时序数据挖掘中,时序关联规则挖掘已经越来越引起研究者的关注,主要包括分为时序数据预处理、时序数据压缩、时序数据模式相似性度量、时序关联规则获取及解释和评价等过程,已有不少文献提出相关论述,如文献[2]对上述几个方面有所综述,文献[3]提出用滑动窗口法进行时序关联规则挖掘,文献[4]提出日历关联规则挖掘,文献[5]提出基于时间段的时序规则挖掘等。
由此可见,时序关联规则研究具有很重要的实用意义,本文主要研究时序列关联规则挖掘算法的设计与实现,并应用获取频繁时序列以有利于对时间列行趋势分析和预测,为决策者提供更好的帮助。
1 时序关联规则相关数据模型的概念
为了更清晰地表述内容,下面给出时序即时序关联规则的有关数据模型概念。
定义1 时序 时序是由值和值发生的时间组成的元素的有序集合,记为S = {Vt1,Vt2,…,Vtn},Vti表示时序在时间戳ti的取值,称为时序项,时间戳是严格递增的,即所有时序项按照各时序项的时间戳从小到大排列。
通常,时序研究采样间隔时间Δt=ti-1-ti等长,因此时序也可简记为S= {V1,V2,…,Vn},时序S= {V1,V2,…,Vn},所包含时序项的个数L,称为时序长度,长度为L的时序称为L-时序。
定义2 时序关联规则 设有时序S={V1,V2,…,Vn},事务T 为时序项的集合,D 为事务集合,A,B为S的子时序(A⊂S,B⊂S),且A∩B=Ф。时序关联规则是形如的蕴含式,该蕴含式表示在时序S中,子时序A出现在事务T的Δt时间间隔后,B也会在同一事务T中出现。
定义3 时序支持度 时序支持度B),表示S中同时包含A,B且满足时间间隔Δt的事务数γ与D中所有的事务数λ的比率,即为:表示D中同时包含A,B且满足Δt周期的事务数,又称之为D中同时包含A,B且满足Δt周期的事务的支持数。
定义4 频繁时序 同时包含A,B且满足时间间隔Δt的子时序在时序S中出现频率大于最小支持度阈值或者同时包含A,B且满足时间间隔Δt的子时序在时序S出现的频次大于最小支持数阈值δ的子时序,称该子时序为频繁时序。
定义5 时序置信度 时序关联规则的置信度,表示D中同时包含A,B且的事务数γ与D中包含A事务数μ的比率,可表示为:
定义6 强时序关联规则 如果时序关联规则同时满足B)>minconf,其中minsup、minconf分别为最小支持度和最小置信度阈值,则称时序关联规则A⇒ΔtB为强时序关联规则。
2 时序关联规则挖掘分析
2.1 时序关联规则挖掘基础
时序关联规则挖掘是一个复杂的系统工程,包括时序数据预处理、时序数据压缩、时序数据相似性度量、时序频繁模式获取及强时序关联规则生成等步骤,每一步骤挖掘方法的优劣都直接影响和制约着最后挖掘的时序关联规则的可靠性与有效性[6]。囿于篇幅,本文主要研究时序频繁模式获取算法。与传统的关联规则挖掘相比,时序关联规则挖掘的是诸如顾客不同时间多次购物行为中的规律,挖掘的结果是由若干项集组成的序列。由于引入了时间概念,时列关联规则挖掘算法也较传统关联规则挖掘算法更为复杂,传统的关联规则频繁模式挖掘与强关联规则算法已不再适用,如经典Apriori算法和FT_Growth算法,而只能应用新的挖掘算法来发现时序频繁模式或生产强时序关联规则,其中以改进的ApriorAll算法和基于滑动窗口的符号化序列获取强时序关联规则较为著名[7]。本文作者在学习总结有关时序关联算法基础上,提出一种基于滑动窗口和时序树的频繁时序获取算法。
2.2 挖掘频繁时序算法原理与设计
2.2.1 算法原理
针对时序S= {V1,V2,…,Vn}、最小支持数阈值δ(或最小支持度阈值的minsup)和最小置信度minconf,取滑动窗口W 的长度为wl,在时序关联规则获取过程中,每次向后滑动一步,可得到时序的一个子时序,多次滑动后,可把时序S离散成若干子时序集:
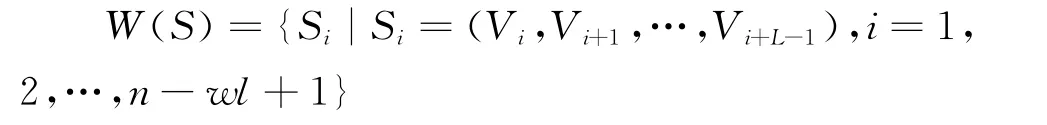
然后把离散后的子时序的每个时序项插入到一个以NULL值为根节点的树中,在插入的过程中对每个时序项计数,所以此树的除根节点外,其他节点的数据有2部分构成,可表示为:(Vi∶x)(Vi时序值,x为计数值)。然后通过遍历此树,获取频繁时序。需要说明的是,由于在时序中,因为每个时序项值的出现,有一定的时间先后顺序,在构造树的过程中,相同是时序值,因为出现的时间不同,所以有时并不能合并到一个节点上。
如 时 序 S = {a1,a2,a1,a2,a1,a2,a1,a2,a2,a2},设滑动窗口W 的长度wl=3,每次向后滑动一步,由此可把时序S离散成如下子时序集:
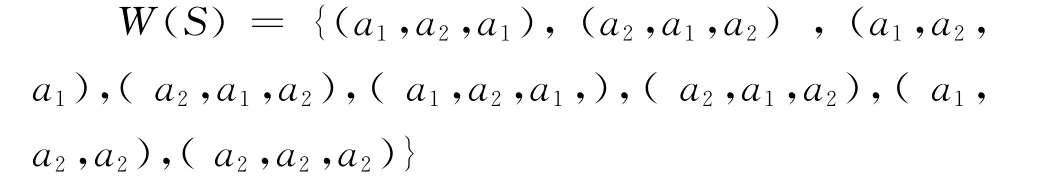
以上述W(S)构造一个时序树的步骤如下:
第1步:创建以NULL为值的根节点。从时序项读取长度wl=3的第1个子时序项,为根节点创建一个有3个节点的分支,即 < (a1∶1),(a2∶1),(a1∶1)>,其中第1个(a1∶1)为(a2∶1)的父节点,第2个(a1∶1)为(a2∶1)的子女节点。
第2步:滑动窗口W一步,读取读取长度为3的第2个子序列 < (a2,a1,a2)>,遍历在根节点的子女节点,发现没有a2,创建第2个分支 < (a2∶1),(a1∶1),(a2∶1)>,其中第1个(a2∶1)为(a1∶1)的根节点,第二个(a2∶1)为(a1∶1)的子女节点。
第3步:再次滑动窗口W一步,读取读取长度为3第3个子时序项(a1,a2,a1),通过遍历第2步完成的时序树,发现已有以a1为根节点的左子树,把左子树根节点计数值加1,接着遍历左子树的子女节点,发现a2存在,同样把该节点的计数值累加1,再遍历a2的子女节点,发现a1存在,把该子女节点计数值加1。
第4步:多次重复第3步,直至把最后的时序项值插入该树中并完成相应时序项的计数,构成该时序一个完整的时序树如图1所示。
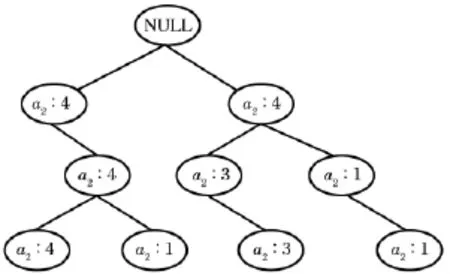
图1 时序树
通过采用深度优先的原则对图1的遍历,可以挖掘出频繁时序,设最小支持数阈值为δ=3。步骤如下:
首先遍历左子树,读取其根节点(a1∶4),其计数值大于3,如此类推再遍历其子女节点(a2∶4),计数值为4,大于3,同理其子女节点(a1∶4)计数值4大于3,子女节点(a2∶1)计数值1小于3。因此由(a1∶4)、(a2∶4)、(a1∶4)、(a2∶1)4个节点,构成的满足大于最小支持数阈值δ=3的候选频繁时序集合为:{(a1,a2,a1),(a1,a2),(a2,a1)}。又滑动窗口 W 的长度wl=3,故在上述频繁时序集中只能取子时序{a1,a2,a1}作为时序的频繁时序。
第2步遍历右子树,同样发现满足大于最小支持数阈值δ=3的候选频繁时序集合为:{(a2,a1,a2),(a2,a1),(a1,a2)},滑动窗口W 的长度wl=3,同理频繁时序集中只能取子时序{a2,a1,a2}作为时序的频繁时序。
第3步:综合第1、2两步,得到时序S的长度为3的频繁时序集合为{(a1,a2,a1),(a2,a1,a2)}。为了避免挖掘遗漏频繁时序,然后把此2个序列连接,生成长度为4的子序列{a1,a2,a1,a2},在S序列中搜索发现,子序列{a1,a2,a1,a2}只在S 中出现2次,小于最小支持数阈值δ=3,因此{a1,a2,a1,a2}不是频繁序列,至此频繁时序挖掘结束。
2.2.2 算法设计实现
根据2.2.1的分析,时序关联规则挖掘算法设计实现如下:
输入:时序S= {V1,V2,…,Vn}、滑动窗口W的长度wl、最小支持数阈值δ
输出:频繁时序项集合
Proc TSDPM()
(1)Create Rote_node(NULL);//创建时序树根节点,节点值为NULL
(2)For(j=int(n/wl),j≥1;j--)//当时序项数小于滑动窗口长度wl时,读取结束
(3)Sj=NULL;//把Sj子时序初始为 NULL
(4)For(i=1,i<=wl,i++)
(5)Sj=Sj+{vi};//Sj为子时序,vi为顺序读取的时序项值,为Si的第i项
(6)If(∃(Cnode(vi)∈Node(V’)))//Node为父节点,Cnode为子女节点*/
(7){Cnode(vi).x=Cnode(vi).x+1;}//Cnode为节点计数值加1*/
(8)Else
(9){Create Cnode(vi);//创建 Cnode节点,初始计数值为1*/
(11)Cnode(vi).x=1;}
(12)Endfor
(13)Endfor;//时序树构造结束
(14)FP_Find(node);//遍历时序树,获取频繁时序
(15)Return;
其中FP_Find()函数返回的是频繁时序项集合,其过程如下:
FUNC FP_Find(Node)
(1){S’=Null;//时序S’初始为 NULL
(2)For
(3)If(Node(vi).x≥δ)
(4){Add Node to S’//把节点 Node加入到时序S’
(5)FP_Find(Cnode);//针对 Node的所有子女节点Cnode,递归调用FP_Find()
(6)If(Node’s Cnode.x<δ)//若 Node不再有子女节点的计数值小于支持计数阈值
(7)Add all Cnode in CurrentPath to S’;//将当前路径的所有时序项添加到时序S’中
(8)Else
(9)Break;}
(10)Endfor
(12)Return S’;}
2.2.3 算法分析
本算法中所创建的时序树深度与滑动窗口的长度相等,与时序项个数无关,树节点的数量与时序项值数量、窗口W 的长度及最小支持数阈值相关,而且在实际应用中,它们的值都为有限的常数,因此算法的时间复杂度T(n)=O(n),空间复杂度S(n)=O(1),为原地算法,空间消耗较少。
3 算法实验结果
实验环境:PC配置为Windows8系统、Core双核i3CPU、PC1333 2G内存PC、Turbo C++3.0编程环境;样本数据为上海股市中国银行(SH:601988)2008年—2011年全部的每日收盘价样本时序数据,收盘价在2.82~6.61元之间波动。设最小支持数阈值δ=3,滑动窗口W 的长度wl=8。
用Turbo C++3.0编程实现TSDPM算法过程,在所给定的软硬件环境下实现对样本时序数据进行处理,共获取满足条件的频繁时序76项,耗时32ms。而同等环境下,以经典时序挖掘Aprioriall算法实现对此样本数据处理,在获取同样数量频繁时序的情况下,耗时为46ms。可见TSDPM算法可满足对时间序列挖掘需求,挖掘效率有所提高,两种算法的运行效果如图2所示。

图2 算法运行效果比较
4 结语
时序数据挖掘日益成为数据挖掘的一个重要方面,本文在研究时序数据挖掘的基础上,重点分析了时序关联规则挖掘知识,并在此基础上提出一种基于滑动窗口和时序树结构的时序关联规则挖掘算法,给出算法伪代码过程,并以实例分析其实现步骤。通过实验分析,在同等环境和条件要求下,该算法执行效率较高,完全满足对时间序列数据挖掘的需要。
[1]王华金,兰红.一种基于FP-tree挖掘最大频繁模式的改进算法[J].长春工程学院学报:自然科学版,2007,8(1):59-62.
[2]贾澎涛,何华灿,刘丽,等.时间序列数据挖掘综述[J].计算机应用研究,2007,24(11):15-18.
[3]Mannila H,Toivonenand H,Verkamo A I.Discovery of frequent episodes in event sequences[J].Data Mining and Knowledge Discover,1997,1(3):259-289.
[4]FU HG,NGUIFO EM.A Parallel A Igorithm to Generate Formal Concepts for Large Data[A].Peter ERlund.Second International Conference on Formal Concept A-nalysis,ICFCA 2004[C].Sydney,Australia:Springer,2004,394-401.
[5]Kam PS,Fu AWC.Diseovering temporal Pattems for interval-based events[A].Yahiko kambayashi,Mukesh Mohania,A Min Jjoa.In:Proceedings of the 2nd International Conference on Data Warehousing and Knowledge Discovery (DawaK2000)[C].London,UK:Springer,2000:317-326.
[6]周勇.时间序列时序关联规则挖掘研究[D].成都:西南财经大学,2008.1-6.
[7]张宁.基于滑动窗口的时间序列离群数据挖掘[J].燕山大学学报,2008,32(6):483-486.
