基于居民便利服务信息的模型构建
2012-01-15刘晓云
刘晓云
(临沂职业学院 山东 临沂 276017)
近年来,随着计算机网络的不断发展,在居民小区中物流技术和网络技术逐渐广泛应用,文中通过设计开发居民便利服务系统,建立网络信息墙,向小区居民分栏发布最新的蔬菜产品价格行情、日常实用新产品技术、医疗保健信息、家政供求信息、政策法规通知等各类小区居民生活服务信息,供居民选用、订制,形成新的商品、服务营销模式。“网络信息墙”的设立,为供需双方的沟通提供了新的方式,提高了小区居民的信息化应用水平。
1 背景知识
1.1 数据挖掘
数据挖掘是指在已构建的数据对象中,采用数据准备、数据开采、结果表达和解释3个处理阶段从隐含在人们事先未知的、潜在的有用信息和知识中提取出可表示为概念规则、规律、模式等形式的知识。文中采用由R.Agrawal等提出的关联规则进行分析、研究[4-6]。
1.2 信息服务链
在居民便利服务系统中,根据小区居民订制的各类生活服务信息,及时汇总、保存,并进行数据信息挖掘、分析,以便发现浏览者感兴趣的信息或者服务,并根据该相关信息,预测出最近将来一段时间内,该用户还可能要购买那种商品的一种关联,以此形成的服务信息链为信息服务链。
2 网络信息墙的模型设计
2.1 多层次关联规则算法
在居民便利服务系统中,根据信息服务链的定义,会在数据库中存在大量的有用信息需要分析、挖掘,以便为后续营销或服务提供知识发现。如图1居民便利服务系统数据挖掘处理流程模型所示。

图1 居民便利服务信息库的数据挖掘流程模型Fig.1 Data mining procedural model of resident convenient service information database
居民便利服务是多层次、多方位、复杂化的。网络信息墙中存有大量的数据信息,首先从中进行取样(sampling)[8],通过对局部数据的统计和分析,建立确定从概念层次的中间挖掘的起点,以此挖掘到符合阈值的关联规则,最后采用多层次关联规则挖掘算法对网络信息墙中进行数据挖掘。
多层次关联规则挖掘算法ML_ARDM[6-7]
输入:贸易数据库TDB,概念层次树Tree,最小支持度Smin,最小可信度Cmin。
输出:多层次关联规则信息集。
主挖掘算法:
l)以Tid为依据进行取样,然后另存为取样数据库TDatabase;
2)运用取样挖掘算法对TDatabase中的数据进行取样挖掘;
3)把取样挖掘产生的S_Tree作为概念层次树,用于实现挖掘算法对整体数据进行实现挖掘。
取样挖掘算法:
l)计算频繁项集得到S_Tree;
2)从S_Tree中删除当前节点以及后续都不能组成频繁规则的节点,记为S_Tree′;
3)扩展S_Tree′中的S_Tree的叶子节点;
4)S_Tree:=S_Tree′+根节点, 重新构建S_Tree, 使之成为一棵完整的带有信息服务的树;
5)扩展S_Tree中的所有节点的下一级子节点,加入S_Tree,S_Tree使降低一层。
实现挖掘算法:
l)进行频繁项集计算处理;
2)计算后选规则集;
3)生成优化的规则集;
算法说明:取样挖掘算法目的是为了得到取样树S_Tree,为实现挖掘算法选择合适的起点。
取样挖掘算法中步骤3~5的作用是为S_Tree中尽可能多的包含可能组成规则的节点,目的是使实现挖掘得出的规则在挖掘结果中更具完整性。
2.2 需求购进量模型设计
在居民便利服务中,各类资源之间存在较为复杂的关系,比如:日用品及蔬菜配送、医疗保健、家政供求、人力配备、价格、居民人数等6个因素会存在利用冲突的问题。为此,居民服务中心从采购中心购进日用百货时,应考虑最大盈利问题,即:早上进的货零售,晚上将没有售掉的退回。根据居民区内居民通过网络或者实时通讯工具向居民服务中心提交的需求信息,由多层次关联规则挖掘算法,可以建立日用百货需求购进量模型。
设豆浆每份的购进价格b(buy),零售价为s(sale),返回价为r(return),则根据正常市场经济运行规则,可设:s>b>r。 因此,居民服务中心每销售一份豆浆可赚s-b,返回一份赔b-r。居民服务中心每天如果购进的豆浆太少,则无法满足顾客需要,盈利则少;如果豆浆购进太多,则无法全部售出,还要退回赔钱。为此,应根据需求量确定购进量。需求量是根据多层次管理关联规则算法得出的每日豆浆需求量概率数为x份的概率是f(x)(x=0,1,2,3…),则可以在f(x)和s,b,r之间建立关于需求购进量优化模型[7-9]。
假设每天豆浆购进量为n份,因为需求量x是随机不确定的,x可以小于n,等于n或大于n,因此,豆浆的日盈利也是变化不定的,作为优化模型的目标函数,应考虑的是一段时间的平均盈利。
若居民服务中心每天购进n份豆浆时的平均盈利为G(n),如果当天的需求量x≤n,则售出x份,退回n-x;如果当天的需求量x>n,则n份全部售完。考虑到需求量x的概率是f(x),所以

问题归结为在f(x),b,s,r已知时,求n使G(n)最大。
通常需求量x的取值和购进量n都相当大,将x视为连续变量更便于分析和计算,此时概率函数f(x)转化为概率密度函数p(x),(1)式变为:

化解计算得:

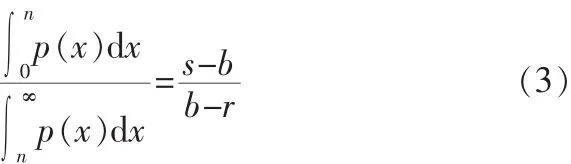
要使居民服务中心的平均盈利达到最大的购进量n应满足(3)式。因为,因此表达式(3)也可表示为:
由需求量的概率密度p(x)的图形能交容易从(3)式确定购进量n。 在图2中,P1,P2分别表示曲线p(x)下的两块面积,则(3)式可表示为:

图 2 由p(x)确定n的图解法Fig.2 By p(x) graphic method of determining n

居民服务中心可以运用此优化模型的目标函数在其他进货商品中使用,以此提高需求进货量的效益。而基于局域网的服务信息,通过网络信息墙及时显示已预定的相关便利服务,以便其他居民及时调整选择其他服务[10]。网络信息墙的部署图如图3所示。

图3 网络信息墙的部署图Fig.3 Deploy diagram of network information wall
3 结束语
在居民小区局域网中,根据居民个体需要,在其家内安装信息墙,利用网络实时获取小区居民订制的各类日常服务信息,并运用多层次关联规则挖掘算法和需求购进量模型目标函数分析、挖掘得到确定的居民便利服务信息,同时通过网络将相关信息显示在信息墙,方便其他居民选择不同的便利服务信息,以此提高居民信息化服务水平。
[1]蔡敏,徐慧慧,黄炳强.UML基础与Rose建模教程[M].北京:人民邮电出版社,2006.
[2]刁成嘉.UML系统建模与分析设计[M].北京:机械工业出版社,2007.
[3]Ronald J.Norman:Object-oriented system analysis snd design[M].Prentice Hall,inc,1996.
[4]范明,孟小峰.数据挖掘概念与技术[M].北京:机械工业出版社,2001.
[5]康晓东.基于数据仓库的数据挖掘技术[M].北京:机械工业出版社,2004.
[6]陈子阳,郭景峰.多层次关联规则的快速挖掘算法[J].燕山大学学报,2003(10):363-366.CHEN Zi-yang,GUO Jing-feng.Fast mining algorithm for multilevel association rules[J].Journal of Yanshan University,2003(10):363-366.
[7]程继华,施鹏飞.多层次关联规则的有效挖掘算法[J].软件学报,1998(12):937-942.CHENG Ji-hua,SHI Peng-fei.Effective mining algorithm for multi-level association rules[J].Journal of Software,1998(12):937-942.
[8]胡健颖,孙山泽.抽样调查的理论、方法和应用[M].北京:北京大学出版社,2000.
[9]范锡军.基于博弈的供应链均衡模型研究[D].山东:山东师范大学,2008.
[10]陈蜀宇,陈四清.基于局域网的系统级概率分布式故障诊断[J].计算机科学,2000(5):516-522.CHEN Shu-yu,CHEN Si-qing.Fault diagnosis of probabilistic distributed system-level based on LAN[J].Computer Science,2000(5):516-522.
