基于GPU实现汉克尔变换并行计算
2012-01-11戴云峰周志芳强建科
戴云峰,周志芳,强建科,刘 冰
(1.河海大学 地球科学与工程学院,江苏 南京 210098;2.中南大学 地球科学与信息物理学院,湖南 长沙 410083)
基于GPU实现汉克尔变换并行计算
戴云峰1,周志芳1,强建科2,刘 冰2
(1.河海大学 地球科学与工程学院,江苏 南京 210098;2.中南大学 地球科学与信息物理学院,湖南 长沙 410083)
地球物理勘探技术日新月异,地球物理勘探数据的处理和解释对高性能计算机的要求越来越高。相比于地震勘探,重力、磁法、电法勘探中的并行计算研究还都处于起步阶段。基于GPU的并行计算能够提供强大的计算能力和存储器带宽,同时具有良好的可编程性、较低的成本和较短的开发周期。这里实现了瞬变电磁法一维正演计算中汉克尔变换基于GPU的并行计算,比较了汉克尔变换串行算法和并行算法的计算耗时,基于GPU技术的并行计算相比串行计算,获得了很高的加速比。
图形处理器;汉克尔变换;并行计算
0 前言
计算机科学技术的高速发展和大型工程计算的需求,使得并行计算(Parallel Computing)技术已经成为目前乃至今后工程计算领域中一项重要技术。并行计算是相对于串行技术而言的,并行计算可以分为时间和空间上的计算,时间上的并行就是指流水线技术,空间上的并行则是指用多个处理器并发地执行计算。
随着地球物理勘探工作的深度和广度不断提高,数据处理结果的精度要求也越来越高。高性能计算技术对于地球物理勘察数据处理有着重要的推动作用,这是因为[1]:①地球物理勘察的数据量巨大;②地球物理勘察数据中蕴涵着大量可并行计算成份。
计算机图形处理器(Graphics Processing U-nit,GPU,俗称显卡)的技术定义是“具有集成转换、照明、三角形设置/剪切、渲染引擎并且每秒至少可处理一千万个多边形的单芯片处理器”。GPU通用计算技术虽然在石油勘探领域中略有使用,但是还不能满足石油工业的发展需要。地震勘探为了获得更加精确的成像效果,由二维勘探向三维勘探发展,以及由叠后处理向叠前处理发展,随之增加的数据处理量向高性能计算技术提出了更高的要求。GPU计算技术已经用于加速三维有限元地震波数值模拟以及地震属性的提取,钟勇[2]应用GPU加速计算提取三维地震图像的结构张量,由结构张量导向进行地震图像扩散滤波增强预处理;刘红伟等[3]针对叠前逆时偏移计算量大的问题,使用GPU实现算法加速,比传统的CPU计算速度提高了一个数量级。GPU计算技术在电法勘探中的使用较少,电磁法数据处理中包含了很多大规模矩阵的计算,涉及到矩阵乘法和线性方程求解,计算量较大。大地电磁正反演研究的热点开始向三维问题转移,交错网格法等已成为大地电磁三维正演计算的主要方法。直流电法和大地电磁法的三维正演,都存在需要求解大型稀疏对称系数矩阵线性方程组的问题,张帆[4]使用基于GPU并行计算和基于MPI的并行计算相结合的计算模式,对这两种电磁法已有的三维正演串行算法进行并行化处理,提高了运算效率。
作者在本文中介绍了图形处理器GPU并行计算的原理,以及CUDA编程模型,实现了汉克尔变换基于GPU的并行计算,比较了汉克尔变换串行计算和并行计算的计算耗时,探讨GPU在瞬变电磁法一维正演计算中的应用前景。
1 图形处理器GPU并行计算的原理
1.1 GPU与CPU结构比较
计算机中的处理器包括CPU(Central Processing Unit,中央处理器)和GPU图形处理器(Graphic Processing Unit,图形处理器)。CPU提高单个芯片性能的主要传统手段是提高处理器的工作频率,以及增加指令级并行。基于GPU的通用计算技术,它主要应用图形处理芯片(GPU)的高性能并行处理能力实现科学计算。与CPU相比,GPU的设计中能使更多晶体管用于数据处理(ALU,Arithmetic Logic Unit即算术逻辑单元),而非用于数据缓存(DRAM)和流控制(Control),见图1。

图1 CPU与GPU晶体管使用方式的对比Fig.1 Comparison of transistors used in CPU and GPU
GPU专门用于解决可表示为数据并行计算的问题,在许多数据元素上并行执行的程序,具有极高的计算密度(数学运算与存储器运算的比率)。由于所有数据元素都执行相同的程序,因此对精密流控制的要求不高。由于在许多数据元素上运行,且具有较高的计算密度,因而可通过计算隐藏存储器访问延迟,而不必使用较大的数据缓存。数据并行处理会将数据元素映射到并行处理线程,许多处理大型数据集的应用程序都可使用数据并行编程模型来加速计算。
1.2 基于GPU的CUDA编程模型
CUDA(Compute Unified Device Architecture,统一计算设备架构)是一种新型的硬件和软件架构,用于将GPU作为数据并行计算设备并在GPU上进行计算的发放和管理,而无需将其映射到图像 API(Application Programming Interface,应用程序编程接口)。随着以CUDA为代表的GPU通用计算API的普及,GPU的含义有可能从图形处理器(Graphic Processing Unit)扩展为通用处理器(General Purpose Unit)。GPU擅长的是图形类的或者是非图形类的高度并行数值计算,GPU可以容纳成百上千条没有逻辑关系的数值计算线程,它的优势是无逻辑关系数据的并行计算。GPU数值计算的优势主要是浮点运算,它执行浮点运算快是靠大量并行,但是这种数值运算的并行性在面对逻辑判断执行时却发挥不了作用。
CUDA编程模型将CPU作为主机(Host),GPU作为协处理器(co-processor)或者设备(Device)。在一个系统中可以存在一个主机和若干个设备。GPU计算的模式就是,在异构协同处理计算模型中,将CPU与GPU结合起来加以利用,CPU负责进行逻辑性强的事务处理和串行计算,GPU则擅长于执行高度并行化的线程任务。CUDA假设CUDA线程可在物理独立的设备上执行,此类设备作为运行C语言程序的主机协处理器操作,见图2。例如,当内核在GPU上执行,而C语言程序的其它部份在CPU上执行。
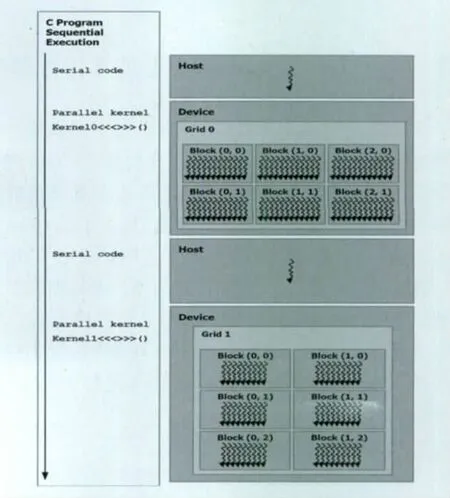
图2 异构编程(串行代码在主机上执行,并行代码在设备上执行)Fig.2 Heterogeneous programming(serial code running on the host,parallel code executes on the device)
在CUDA编程模型中,将threadIdx设置为一个包含三个元素的向量,因而可使用一维、二维或三维索引标识线程,构成一维、二维或三维线程块。在NVIDIA Tesla架构中,一个线程块最多可以拥有512条线程。但一个内核可能由多个大小相同的线程块执行,因而线程总数应等于每个块的线程数乘以块的数量。这些块将组织为一个一维或二维线程块网格,见图3。

图3 线程块网络Fig.3 Thread blocks network
2 基于GPU的汉克尔变换并行计算
目前,基于GPU计算的并行算法主要来源于两个方面:①将串行算法改写成并行算法;②从数学模型出发直接构造并行算法。作者在本文根据瞬变电磁法一维正演计算的算法,用C语言编制了正演的串行计算程序,并研究使用CUDA的并行算法对串行算法进行改写,以提高数据处理的速度。在windows操作系统下,本文作者所有程序都是在Visual Studio C++2005环境下运行。实验使用的是NVIDIA Geforce 8500GT显卡,它的计算能力为1.1。
2.1 汉克尔变换表达式
水平层状介质上瞬变电磁一维正演公式可表示为一个双重积分:内层含有零阶和一阶贝塞尔函数的汉克尔型积分,外层为正弦或余弦积分。在积分公式中,由于贝塞尔函数随自变量缓慢地震荡衰减,所以不采用常规的数值积分方法计算,采用数字滤波法具有良好的效果[5]。
汉克尔变换的一般表达式[6]:
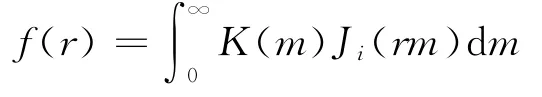
其中 Ji是i阶第一类贝塞尔函数;K(m)是积分变换函数;m是被积变量。
数字滤波器有一组滤波系数,两个常数:位移a和抽样间隔s。位移a决定了输入函数抽样起始点,间隔s决定抽样时的时间间隔。由
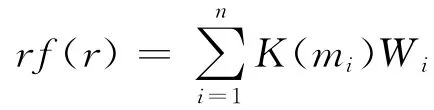
可得出
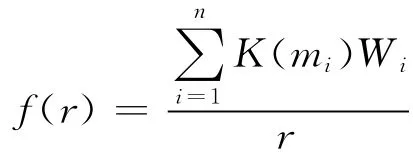
其中 mi= (1/r)*10[a+(i-1)s](i=1、2、…、n);Wi为滤波器系数。
2.2 汉克尔变换串行算法性能分析及并行算法实现
零阶汉克尔变换的串行程序,使用clock_t和clock()函数来获得程序各部份的运行时间。计算所耗时间与计算过程中所取时间点个数的关系见图4,横坐标为所取的时间点数,纵坐标为对应的计算耗时(单位:S),分别测得200、300、500、700、900、1 000个时间点的程序计算耗时。在测试运行单元时间时,先清除上一次运行的解决方案,然后再生成新的解决方案。
当时间点的个数小于500点时,即使测试的是整个程序运行的时间,由于运行速度很快,加上计时函数的精度限制,所得的计算耗时几乎为“0”值,见图4。在这种情况下,使用并行的算法来实现汉克尔变换反而得不偿失。根据CUDA实现效果原则,计算量太小使用CUDA不划算。作者在对汉克尔变换的串行算法与并行算法进行计算性能对比时,所取时间点个数为512(单个线程块最多拥有的线程数)。
作者在本文中进行了汉克尔变换的并行计算,计算出N点的零阶汉克尔变换(一阶变换原理相同,不再重复)。使用取对数间隔函数,获得的对数间隔时间点,即计算式中r的值,以数组的形式作为汉克尔变换计算的输入。对于单个的时间点计算涉及累加的操作,但各个时间点之间是没有影响的,故具有较好的并行性。因为只是进行汉克尔变换并行计算,数据量不大,所以只使用了一个线程块,每个线程块中定义与时间点相同个数的线程(每个线程块Block最多可以定义512条线程Thread),每个线程负责进行一个时间点的汉克尔变换。汉克尔变换的系数为单精度,计算结果和串行计算汉克尔变换的结果相同。数值计算的精度取决于积分区间的长度n,抽样点的位置λi和加权系数Wi。
所取时间点数为512的汉克尔变换串行计算与并行计算性能的对比,时间单位:ms,见图5。串行计算用时为15ms,而并行内核函数计算的用时为0.027 937ms,即使包含计算结果从显存输出到内存中计算耗时(图中并行计算1代表)也仅仅只有0.525 206ms。
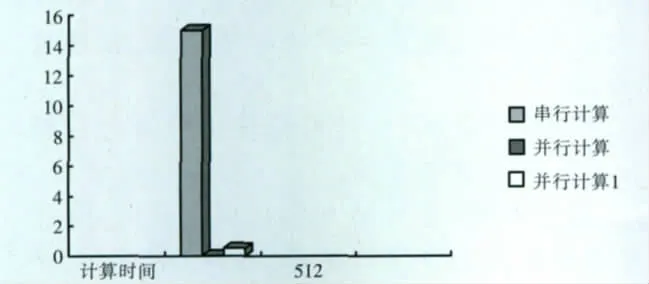
图5 汉克尔变换串行与并行运行耗时对比(单位:ms)Fig.5 Time-consuming comparison of Hankel transform serial and parallel operation(unit:ms)
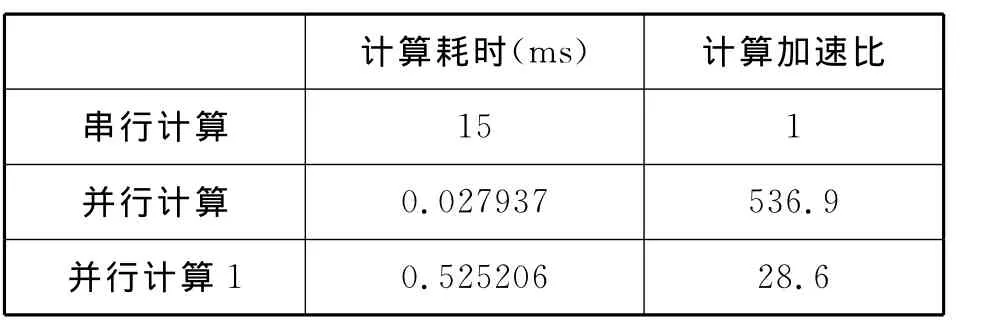
表1 汉克尔变换并行计算相对串行计算加速比Tab.1 Hankel transform parallel computing speedup relative serial
由此可见,对于数据量比较大的汉克尔变换,使用并行计算可以获得很大的性能提高,见表1。但是并行计算的过程相对于串行算法的计算过程略显繁琐,而且CUDA的编程模型很大程度上依赖于硬件的模型,特别是CUDA存储器使用的限制,这就给编程带来了一些麻烦。鉴于设备内寄存器和共享存储器的容量有限,在进行大型科学计算的过程中一定要考虑内存的溢出。GPU单精度性能远远超过双精度,作者在本文中使用过的双精度需要截断成单精度,在程序运行时出现了一些警告,但这并不影响程序的运行,可能计算精度会稍微差一点。使用共享存储器使得汉克尔变换计算过程中线程间的通信延迟最小,性能大幅度提高。
3 结论
(1)在水平层状介质上瞬变电磁测深一维正演计算中,对于汉克尔变换的计算,基于GPU技术的并行计算相比串行计算获得很高的加速比。并行计算的过程相对于串行算法的计算过程略显繁琐,而且CUDA的编程模型很大程度上依赖于硬件的模型,但是GPU在并行计算方面的优势以及超强的浮点运算性能可以大大缩短计算时间。作者在本文中仅仅实现了汉克尔变换不同时间点的并行计算,仅仅是整个正演程序的一部份,对于整个串行正演程序更深入的并行算法有待进一步研究。
(2)相比于地震勘探,重力、磁法、电法勘探中的并行计算研究还都处于起步阶段,我们需要基于GPU计算平台开发更多应用于地球物理方面的并行计算软件。研究并行算法和编程模型,在地球物理勘探数据处理中具有广阔的前景。
[1] 刘羽,王家映.地球物理数据处理与并行计算[J].桂林工学院学报,2004,24(4):412.
[2] 钟勇,陈磊.基于GPU计算的三维地震断层解释[J].石油物探,2011,50(2):160.
[3] 刘红伟,李博,刘洪,等.地震叠前逆时偏移高阶有限差分算法及 GPU实现[J].地球物理学报,2010,53(7):1725.
[4] 张帆.基于MPI和GPU直流电法和大地电磁法三维正演的并行算法研究[D].北京:中国地质大学,2011.
[5] 唐宝山.瞬变电磁法中心回线装置一维正反演研究[D].北京:中国地质大学,2008.
[6] 刘桂芬.回线源层状大地航空瞬变电磁场的理论计算[D].吉林:吉林大学,2008.
[7] 赵改善.地球物理高性能计算的新选择:GPU计算技术[J].勘探地球物理进展,2007,30(5):399.
[8] 赵改善.可重构计算技术及其在地球物理中的应用前景[J].勘探地球物理进展,2007,30(4):309.
[9] HE CHUAN,SUN CHUANWEN,LU MI,et al.Prestack Kirchhoff time migration on hight performance reconfigurable computing platform[J].Expanded Abstract of 75th Annual international SEG Meeting ,2005:902.
[10]HE CHUAN,QIN GUAN,ZHAO WEI.Highorder finite difference modeling on reconfigurable computing platform[J].Expanded Abstract of 75th Annual international SEG Meeting 2005:755.
[11]张舒.模式识别并行算法与GPU高速实现研究[D].成都:电子科技大学,2009.
[12]赵国泽,陈小斌,汤吉.中国地球电磁法新进展和发展趋势[J].地球物理学进展,2007,22(4):1171.
[13]NVIDIA CUDA计算统一设备架构编程指南2.0[S].
[14]罗延钟,张胜业,王卫平.时间域航空电磁法一维正演研究[J].地球物理学报,2003,46(5):719.
[15]KNIGHT JH,RAICH AP.Transient electro-magnetic calculations using the Gaver-Stehfest inverse Laplace transform method[J].Geophysics,1982,47(1):47.
TP 317.4
A
10.3969/j.issn.1001-1749.2012.05.20
1001—1749(2012)05—0614—05
水利部公益性行业科研专项经费项目资助(201001020)
2011-11-24 改回日期:2012-04-02
戴云峰(1988-),男,硕士,从事水文地质方面研究。
