基于最大间隔的决策树归纳算法
2011-12-21焦树军安志江
焦树军 安志江
(河北华航通信技术有限公司 河北 石家庄 050031)
基于最大间隔的决策树归纳算法
焦树军 安志江
(河北华航通信技术有限公司 河北 石家庄 050031)
决策树归纳是归纳学习的一种。由于NP困难,寻找最优的决策树是不现实的,从而探索各种启发式算法去产生一个高精度的决策树变成了这类研究的焦点。考虑到支持向量机(SVM)的分类间隔与泛化能力的关系,可以使用SVM的最大间隔作为生成决策树的启发式信息,使得决策树有较强的泛化能力。本文针对实值型数据,提出了一种基于最大间隔的决策树归纳算法。实验结果表明了本文算法的有效性。
支持向量机;支持向量机反问题;间隔;决策树归纳
0 引言
决策树归纳是归纳学习中最实用最重要的学习和推理方法,由于构造最优的决策树问题已经被证明是NP完全问题[2,3,4],因此典型的决策树学习算法都是在完全假设空间的自顶向下的贪心搜索算法,但各搜索算法所采用的启发式有所不同。其中选用最小信息熵为启发式信息的ID3算法是一个典型代表,这种方法生成的决策树规模小且计算复杂度低,但其泛化能力(generalization)不佳。
统计学习理论(Statistical Learning Theory或SLT)是一种专门研究小样本情况下机器学习规律的理论,它是建立在一套较坚实的理论基础之上的,为解决有限样本学习问题提供了一个统一的框架。V.Vapnik等人从六、七十年代开始致力于此方面研究[5],到九十年代中期,随着其理论的不断发展和成熟,也由于神经网络等学习方法在理论上缺乏实质性进展,统计学习理论开始受到越来越广泛的重视[7,8]。在这一理论基础上发展了一种新的通用学习方法——支持向量机(Support Vector Machine或SVM),它已初步表现出很多优于已有方法的性能,尤其是较强的泛化能力。
根据统计学习理论,SVM分类间隔越大,泛化能力越强,考虑到这一关系,我们可以用最大间隔作为决策树归纳的启发式信息,以此来划分决策树结点,构造决策树。一方面,可以从原始数据中产生高质量的决策树,最大限度地提高决策树对新观察事例的预测准确性;另一方面,理论上它将两种重要的归纳方法互补地结合在一起(支持向量机泛化能力强但得到的知识即超平面不易理解,决策树泛化能力一般但归纳出的知识容易理解)。
1 支持向量机
1.1 支持向量机基本问题
支持向量机是由Vapnik等人提出并以统计学习理论为基础的一种新的学习机器。其基本问题描述如下:设有训练数据

可以被一个超平面

分开。如果这个向量集合被超平面没有错误的分开,并且离超平面最近的向量与超平面之间的距离是最大的,则我们说这个向量集合被这个最优超平面(或最大间隔超平面)分开。如图1所示。

图1 最优分类超平面是以最大间隔将数据分开的超平面
我们使用下面的形式;来描述分类超平面:

并且有紧凑形式:

容易验证,将样本点无错误分开的超平面(1),其间隔为:

由统计学习理论可知,一超平面的泛化能力,即对未知样本准确预测能力,取决于超平面的间隔margin,从而最优超平面就是满足条件(2)并且使得

最小化的超平面。并且通过解决下述优化问题来构造最优超平面:
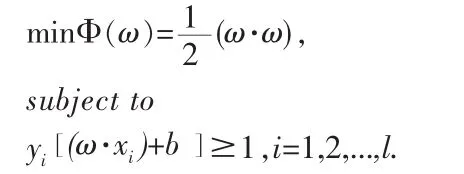
最优超平面是在线性可分的前提下讨论的,在线性不可分的情况下,可以在条件中加入一个松弛变量ξi≥0,这时的最优超平面称为广义最优超平面,通过解决如下问题得到:

其中C是一个常数。最优超平面可通过解下面对偶问题得到:


最优分割超平面有如下形式:
事实上,对于大多数实际问题,样本点在原空间中一般不是线性可分的,所以用上述方法往往得不到好的决策函数(最优超平面)。为此,Vapnik将支持向量机从原空间中推广至特征空间。其基本思想如下:支持向量机通过某种事先选择的非线性映射将输入向量x映射到一个高维特征空间Z,在这个高维特征空间中构造最优分类超平面。如图2。
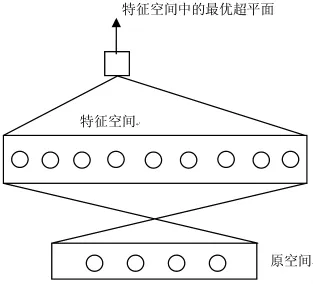
图2 支持向量机通过非线性映射将输入空间映射到一个高维特征空间,在这个高维特征空间中构造最优超平面
Vapnik等人发现,在特征空间中构造最优超平面并不需要以显示形式来考虑特征空间,而只需要能够计算支持向量与特征空间中向量的内积。根据Hilbert-Schmidt定理,在Hilbert空间中两个点的内积有下面的等价形式:


1.2 支持向量机反问题
对于给定的一组没有决策属性的样本点,我们可以随机的把其分为两类。此时我们可以利用前面的知识来求出最优分割超平面,并计算出最大间隔。若划分为两类的样本点线性不可分,间隔计为0。显然,间隔的大小取决于对原样本点的随机划分,支持向量机反问题就是如何对样本点进行划分,才能使最优分割超平面的间隔达到最大。支持向量机反问题是一个优化问题,其数学描述如下:设S=}为一样本集,其中 xi∈Rn,i=1,2,..,N,Ω表示从S到{-1,1}的函数全体。对于给定的一个函数f∈Ω,集合S被划分为两个子
其中K(x1,x2)式满足下面条件的对称函数,也成为核函数。
所以有分割超平面有如下形式:集,并可以计算出其相应的间隔。我们用Margin(f)表示由函数f所决定的间隔(泛函),那么反问题就是要解决如下问题:

2 基于最大间隔的决策树归纳学习
2.1 算法描述
考虑到支持向量机较强的泛化能力,我们可以将支持向量机反问题应用于决策树的归纳过程,即在归纳过程中用最大margin来作为启发式。
其设计思想为:对于一个给定的各属性取值为连续型数据的训练样本集,一开始我们不考虑样本的类别,通过求解SVM反问题,可以得到该样本集的一个具有最大margin的划分,即将样本集分为两个子集。这些子集被作为决策树的分支,被标记为-1的样本集合作为左支,被标记为+1的样本集合作为右支,和这一划分相对应的超平面被作为该结点处的决策函数。当我们对新来的样本进行测试时,将其代入决策函数,取值为负被分到左支,取值为正被分到右支。
以两类问题为例,具体算法为:

2.2 实验结果
用最大间隔作为启发式来生成决策树和用最小熵作为启发式生成二叉决策树针对的均为实值型数据,我们从UCI数据库中挑选了Iris,Rice,Pima,Image Segment四个实值型数据库(表1列出了各个数据库的特征),进行了实验,对比了生成决策树的测试精度。对于多类数据库,只选取了其中的两类来进行实验。
实验结果如表2所示,算法1代表二叉决策树归纳算法,算法2代表基于最大间隔的决策树归纳算法,所用时间为运行算法2所需的时间。

表1 数据库特征表

表2 测试精度对比表
从实验结果中可以看出,用最大margin做启发式,将SVM的相关理论用于决策树归纳过程,使决策树的泛化能力在一定程度上得到了提高。
3 总结
启发式算法是决策树归纳学习的重要研究课题,由于NP困难,寻找最优的决策树是不现实的,从而探索各种启发式算法去产生一个高精度的决策树变成了这类研究的焦点。
决策树的生成过程是对结点进行划分的过程,而支持向量机反问题研究的是如何寻找具有最大间隔的划分,因此可以将其应用到决策树归纳过程,用最大margin作为启发式来生成决策树,以提高其泛化能力。本文主要对基于最大间隔的决策树归纳学习算法进行了设计与实现。实验数据表明该算法生成的决策树的测试精度比用最小熵做启发式的二叉决策树有一定提高。
[1]Tom M.Mitchell,Machine Learning,The Mcgraw-Hill Companies Inc, Singapore,1997.
[2]Hyafil L,Rivest R L.Constructing Optimal Binary Decision Trees Is NPComplete[J].Info Proc Letters,1976,5(1):15-17.
[3]Hong JR.AE1:An extension approximate method for general covering problem [J].International Journal of Computer and Information Science,1985,14(6):421-437.
[4]谢竞博,王熙照.基于属性间交互信息的ID3算法.计算机工程与应用,2004:93-94.
[5]Vladimir N.Vapnik.Estimation of dependences based on empirical data.New York:Springer-Verlag,1982.
[6]Vladimir N.Vapnik.The nature of statistical learning theory.Berlin:Springer-Verlag,1995.
[7]Vladimir N.Vapnik.An overview of statistical learning theory,IEEE Trans.Neural Networks,1999,10(5):88-999.
[8]王国胜,钟义信.支持向量机的理论基础:统计学习理论.计算机工程与应用, 2001,19:19-20.
王爽]
