网络数据包还原和内容分析系统的设计与实现
2011-11-27谢宝娣顾兆军黄宇宫
秦 倩,谢宝娣,顾兆军,王 超,黄宇宫
(1.北京博维航空设施管理有限公司,北京 100000;2.北京理工大学计算机学院,北京 100000;3.中国民航大学计算机学院,天津 300300)
随着互联网络的迅速发展,信息安全问题越来越引起人们的重视。近年来,研究基于内容安全的网络监控、审计系统已逐渐成为焦点,因为它是继防火墙等网络安全产品之后作为提高网络系统安全性的一个新的、重要的发展热点[1]。目前,一些发达国家已在因特网上建立了规模巨大的监控系统。就国内来说,基于内容安全网络监控的研究刚刚起步,在产品的可靠性、检测的准确性以及应用领域和规模等方面,与国外的产品还有一定的差距,对会话跟踪、信息实时还原等关键技术的应用还不是很好[2],这些都需要进一步的研究来解决。
本文研究的网络监控系统从网络传输的过程入手,采用旁路监听的抓包模式,在不修改不拦截网络正常通信数据的情况下,实现了数据捕获、应用数据还原、内容分析与过滤等功能,可实现局域网内容安全监控。
1 系统总体模型
根据网络体系结构的层次模型,本系统划分为数据包捕获、协议分析、会话重聚、应用数据还原、内容分析与过滤五个层次结构进行设计实现,系统模型如图1所示。
本系统从网络内容安全监控的角度出发,实现了基于内容安全的网络监控系统,主要包括以下两大模块:
1)网络数据内容还原
内容还原是本系统的关键内容之一,系统在网络通信的中间过程进行数据包捕获,经过协议分析、会话重聚、应用数据还原等关键技术后,能够逼真地重现用户会话过程。在此过程中,系统可以可视化实时显示网络中的网络状态信息、数据包信息、会话信息等内容,便于网络管理人员分析当前网络状态。

图1 系统模型Fig.1 System model
2)内容分析与过滤
内容分析与过滤是本系统的核心内容。对于经过数据还原得到的文件,系统首先采用文本挖掘中的文本分类技术,智能地分析出用户的网络数据内容;然后采取文本过滤技术对还原后的文本进行进一步分析,过滤出含有敏感信息的文件。最后,为了便于审计,系统以日志方式将内容分析与过滤的结果和当前网络运行状况保存起来。
2 模块设计与功能实现
2.1 数据捕获层
数据捕获层在局域网内容安全监控系统中承担数据采集的任务。本系统的数据捕获采用Java开源包JPcap开发完成,由于JPcap是构建在WinPcap基础之上,并且WinPcap采用旁听模式工作,因此,本系统利用旁听模式进行数据捕获。
2.2 协议分析层
协议分析层主要负责对捕获的数据包进行协议分析、判断该数据包所使用协议、所属会话以及解析相关协议特征等。例如,通过解析IP数据包首部的协议字段,即可判断该数据包使用的是TCP协议、UDP协议或其他协议,然后根据数据包类型,采用不同的数据还原策略进行数据包重聚。
对数据包的协议分析一般要进行多次,这是由于应用数据的传输要从应用层到物理层进行多次封装,在每一层都要对上层的报文添加相应的报头。协议分析层的设计如图2所示。
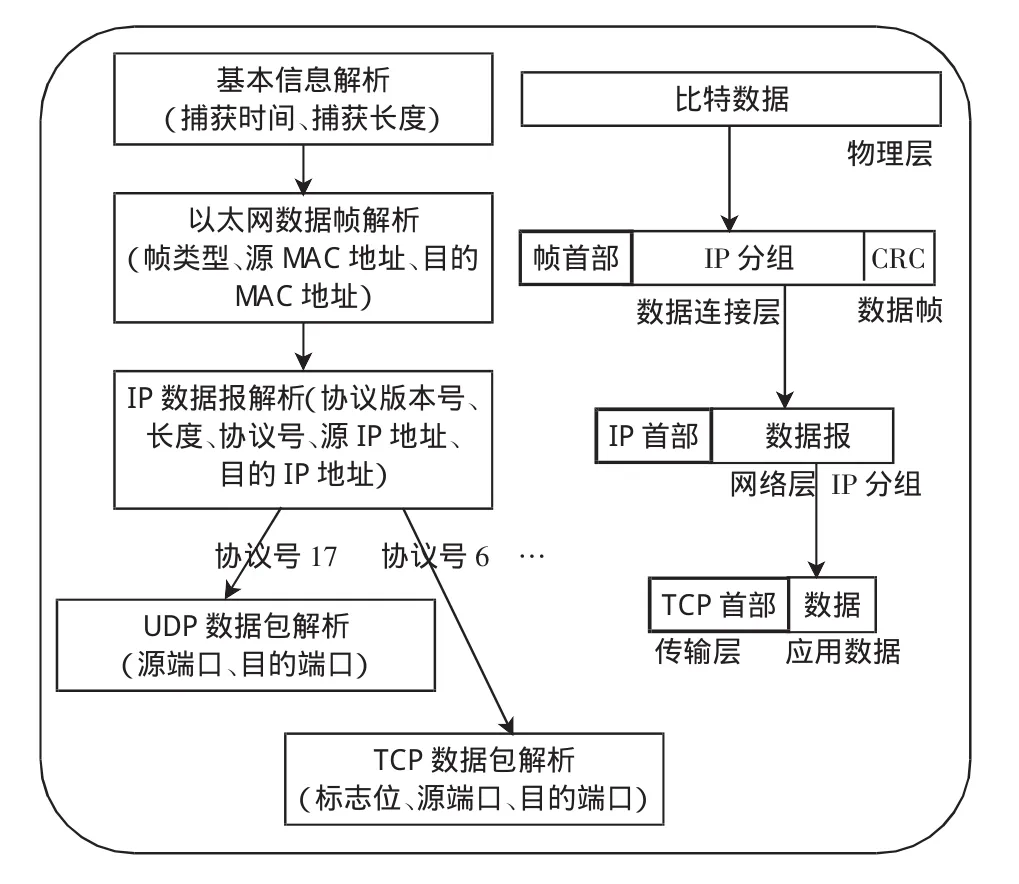
图2 协议分析层Fig.2 Analysis layers of protocol
2.3 会话重聚层
会话重聚层根据当前网络中传输的数据包创建会话,同时将相关数据包加入会话,并进行整理,最后将整理好的会话结构递交给应用数据还原层进行还原处理。会话重聚主要解决3个问题:①同一会话中的数据包标识问题;②同一会话中的数据包网络层分片问题、运输层分段问题;③同一会话中的数据包重传、丢失和乱序问题。模块实现的关键在于对第三个问题的处理。本系统主要实现了基于HTTP协议、FTP协议、SMTP协议的会话重聚。由于UDP协议是面向无连接的、不可靠的协议,因此,使用UDP协议传输的数据包不会存在重传、丢失和乱序等问题。本文讨论基于TCP协议的数据包重传、丢失和乱序等情况的解决策略。
TCP协议利用其首部字段ACK应答号、序列号、数据长度以及标志位SYN、FIN来标记数据包的传输顺序。因此,在了解它们之间关系后,找出了解决数据包重传、丢失和乱序情况的策略。具体步骤如下:
1)将捕获的数据包按其源IP地址、目的IP地址和端口分类存储在不同集合。
2)将位于同一集合下的数据包,按其序列号、确认号、时间多级排序,从而解决了数据包乱序情况。若出现序列号、确认号都一致的数据包,则认为出现数据包重传情况,根据时间丢弃前面的数据包。
3)将排序好的数据包,逐一推算其序列号和确认号,若出现不符,则认为出现数据包丢失情况,会话数据不完整。具体序列号的推算规则如下:若数据包的SYN或FIN标志位为1,则
下一个数据包的序列号=数据包的序列号+数据包的数据长度+1
否则
下一个数据包的序列号=数据包的序列号+数据包的数据长度。
2.4 应用数据还原层
应用数据还原层构建在会话重聚层之上,网络数据经会话重聚之后已可作为有用信息呈现给用户,但是,由于此时的信息比较孤立,一幅图片、一段文字,不能很好地展现完整和关联效果,需要进一步进行应用数据还原。应用数据还原层的作用是根据用户的需求,将会话重聚层传递上来的整理好的会话进行组合、还原。其关键技术在于资源组合、字符解码和标签语言还原。该模块包括基于HTTP协议的应用数据还原、基于FTP协议的应用数据还原和基于SMTP协议的应用数据还原三部分,限于篇幅,本文仅讨论基于HTTP协议的应用数据还原。图3展示了基于HTTP协议的网页还原流程。

图3 网页还原流程图Fig.3 Process of reverting to web page
如图3所示,网页还原主要实现以下3步即可重现网页。
1)将经过会话重聚后的各种资源按照其原始形式进行还原,并按其请求路径保存在本地。
2)查找网页文件中的关联的资源信息,若所请求资源已本地化,则修改网页文件中该资源的链接,将其从网络路径名称,修改为该资源在本地保存的路径名称。
3)重新打开本地化的网页文件。
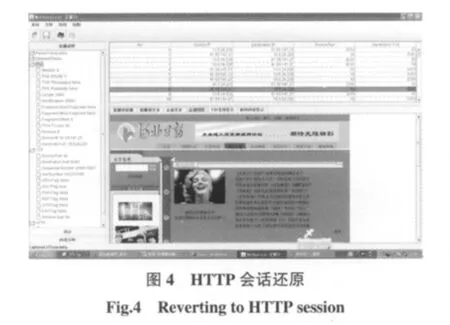
以HTTP会话为例,系统对其还原结果如图4所示。
何良诸十多年前,就领教了赵集的憨劲。那天,何良诸来到北大坎煤矿生活区,临街的小勺酒店,飞出猜拳喝令声。何良诸探头往里瞅,一个女人招呼道:“进来呀。”店内光线暗,酒气、汗腥、臭脚丫子味,呛鼻子,何良诸“啊乞”,打个喷嚏。
2.5 内容分析与过滤层
内容分析的主要功能是为了快速有效地找到用户所关注的文本内容,采用将文本分类的方式帮助用户分析文本的内容。内容过滤主要包含两个主要的功能,一个是向关键词数据库文件中加入用于文本过滤的关键词;另一个是根据关键词数据库中的关键词检索过滤所有需要分析过滤的还原结果文件,找到其中包含指定关键词的文件,并以图表等直观的形式给出统计结果。内容分析是该模块的核心,主要为几下几个步骤:
在本系统中,采用中国科学院计算机技术研究所研制出的基于多层隐马模型的汉语词法分析系统ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)进行中文分词。文本经中文分词之后,得到大量词语,而其中包含了一些频度高但不含语义的词语,如助词,利用停用词表将其过滤,以便于文本分类的后续操作。
1)文本特征提取
文本经过中文分词、去除停留词后得到的词语量特别大,由此构造的文本表示维数也非常大。并且,不同的词语对文本分类的贡献也不同。因此,有必要进行特征项选择以及计算特征项的权重。
本文采用CHI算法作为特征选择算法。CHI算法的主要思想是认为词汇与类别之间符合χ2统计,χ2统计量的值越高,词汇与类别之间的独立性就越小。
χ2统计量计算公式如下
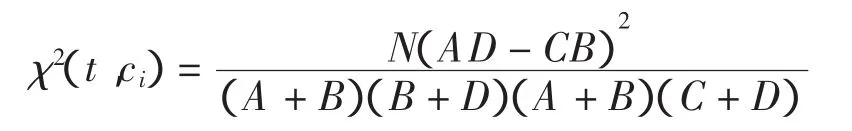
其中:N表示训练集中的文档总数;A表示属于主题ci且包含特征项t的文档个数;B表示属于主题ci但不包含特征项t的文档个数;C表示包含特征项t但不属于主题ci的文档个数;D表示不包含特征项t且不属于主题ci的文档个数。特征项t对主题ci的χ2统计值越高,与该主题之间的相关性就越大。
具体特征项的选择根据特征项的CHI值来判断。当CHI不低于某一阈值时,选择该特征项。
本系统采用以下公式作为词语权重的计算方法
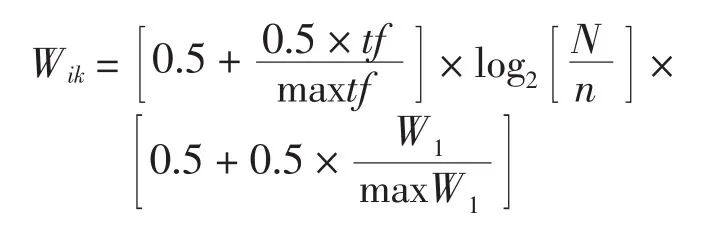
其中:Wik表示词语k在文本i中的权重;tf表示词语k在文本i中的频率;maxtf表示文本i中词频最大的词语的频率;W1为词语k的词长;N表示分析的文本集合包含的文本数;n表示在分析的文本集中包含词语k的文本数;maxW1表示文本i中词长最大的词语的词长。
2)文本表示
文本表示是指以一定的规则和描述来表示文本或者文本类,在过滤时,用这些规则和描述来评价未知文本与给定文本或文本类的相似度。目前,存在多种文本表示模型,常用的有:布尔逻辑模型、概率模型和向量空间模型等。本系统中,文本采用向量空间模型表示。
向量空间模型用向量 D=D(t1,wt1;t2,wt2;…;tn,wtn)的形式来表示文本,其中tk(1≤k≤n)是文本中的特征项,wk是tk的权重。为了简化分析过程,暂时不考虑tk在文本中的顺序并且tk互异。此时,若把t1,t2,…,tk看成一个 n 维的坐标系,w1,w2,…,wk则为相应的坐标值,这样便可将文本向量表示简记为D(w1,w2,…,wk),进而把文本之间的表示与匹配问题转化为了空间向量之间的表示与匹配问题。
3)文本分类
文本分类过程中,本系统采用K-近邻分类法完成文本分类。K-近邻分类法的原理如下:在对待测文本分类时,选择训练集合中的已知文本与待测文本之间距离(相似度)最近的K个文本,即K个“最近邻”,然后将待测文本指派到它的K个“最近邻”中的多数类。
本系统中文档相似度的计算采用夹角余弦计算,计算公式如下
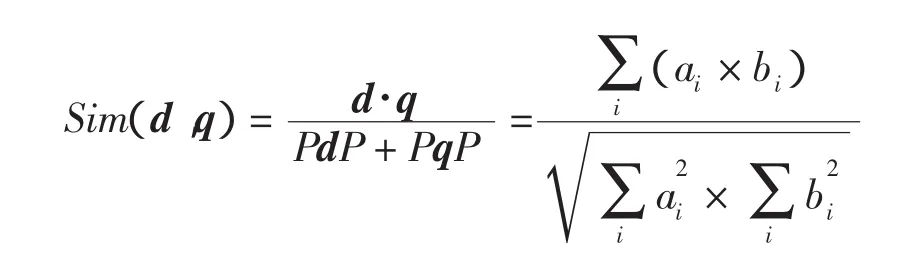
其中:d代表文档向量;q代表了用户查询向量(也即用户兴趣向量)。文档与用户兴趣向量相似度越高,说明
文档符合用户兴趣趋向。
对该还原网页执行内容过滤,将经过系统处理后的本地化文件进行关键词匹配过滤,关键词数据库中已包含1600个敏感关键词。过滤检测,发现3份文件中包含了敏感关键词。这3份文件如表1所示。

表1 内容测试结果Tab.1 Content test results
3 结语
本文实现的网络监控系统通过多层次可视化的安全监控,使网络监控更加人性化;通过多任务的实时监控在最短时间内发现网络中存在的问题,达到了快速反应、监管便捷的应用目标;通过多角度的全面监控全面保证了网络传输中的内容安全;快速高效的中文分词算法大大提高了分词的效率和准确度,从而加快了后续的内容过滤过程。该内容安全监控系统为管理人员提供一种高效、准确的网络内容安全监控手段,实时还原用户上网行为。该系统是在网络数据包没有加密的情况下实现的,下一步的工作是要采用解密技术对传输的数据进行最大限度地还原。
[1]方滨兴.信息安全及其关键技术探讨[R].国家网络与信息安全中心,2005.
[2]北京大学公共政策研究所.我国互联网信息内容安全及治理模式研究报告[R].北京大学公共政策研究所,2007.
[3]胡晓元,史浩山.WinPcap包截获系统的分析及其应用[J].计算机工程,2005,31(02):96-98.
[4]赵章界,余智华,张丙奇.HTTP协议流解析系统的设计与实现[J].计算机工程,2005,31(24):38-40.
[5]黄贻望,万 良,李 祥.以太帧的捕获、解析与应用[J].贵州大学学报(自然科学版),2009,26(01):44-46.
[6]王银利.基于启发式规则和文本分类的信息过滤技术[D].北京:北京交通大学,2007.
[7]杨晓懿.基于内容分析的信息安全过滤技术研究[D].四川:四川大学,2005.
