决策树C4.5连续属性分割阈值算法改进及其应用
2011-08-01姚亚夫邢留涛
姚亚夫,邢留涛
(中南大学 机电工程学院,湖南 长沙,410083)
分类问题是数据挖掘领域中研究和应用最为广泛的技术之一。近年来,分类问题在许多行业和领域都有广泛的应用[1],如何更精确、更有效地分类一直是广大科研工作者的目标。决策树以其预测准确率高、稳定性好、直观易懂等特点[2-4],得到广泛的应用。目前,构造决策树的算法比较多[5-6],用不同的算法可以构造出不同的决策树,其性能也不尽相同,决策树的构造通常包含 2个重要步骤[7]:生成决策树和决策树的剪枝。每个步骤都有不同的方法,相应地就有各种不同的决策树生成和剪枝算法,最早的决策树算法是由 Hunt等[8]于 1966年提出的 CLS(concept learning system)。ID3算法[9]和C4.5算法[10]是目前最具影响的决策树算法,已广泛应用于数据分类领域。C4.5算法是在ID3算法的基础上改进过来的,不仅可以处理离散型描述属性,还可以处理连续性属性。C4.5算法采用信息增益率作为选择分枝属性的标准,弥补了 ID3算法在使用信息增益选择分枝属性时偏向于取值较多的属性的缺陷,但C4.5算法也有一些缺陷[11]。本文作者研究C4.5算法中的连续性属性离散化技术,并提出了改进算法—局部择优法。将改进C4.5算法应用于行人和车辆模式识别,并对改进C4.5分类器与K-均值分类器以及传统C4.5分类器的分类性能进行比较。
1 C4.5算法
作为ID3算法的改进算法,C4.5算法克服了ID3算法的两大缺点:(1) ID3算法使用信息增益作为评价标准来选择根节点和各内部节点中的分枝属性,信息增益的缺点是倾向于选择取值较多的属性,在某些情况下这类属性可能不会提供太多有价值的信息,而C4.5算法采用信息增益率作为评价标准,克服了ID3算法的这点不足;(2) ID3算法只能处理描述属性为离散型的数据集,而C4.5算法既可以处理离散型描述属性,又可以处理连续型描述属性。C4.5算法也是一种基于信息论[12]的机器学习方法,其核心思想是通过分析训练数据集,在整个数据集上递归地建立一个决策树,其详细过程如下。
Step 1 对数据集进行预处理,若数据集为连续型描述属性,需将数据集离散化,并计算所有属性的信息增益率,选择信息增益率最大的描述属性作为根节点的分枝属性。
(1) 设整个数据集为T,类别集为{C1,C2,…,Ck},总共分为k个类,每个类对应 1个数据子集Ti(1≤i≤k)。令|T|为数据集T的样本数,|Ci|为数据集T中属于类别Ci的样本数,则各类别的先验概率为Pi=|Ci|/|T|,对数据集T进行分类所需要的信息熵[13]为:
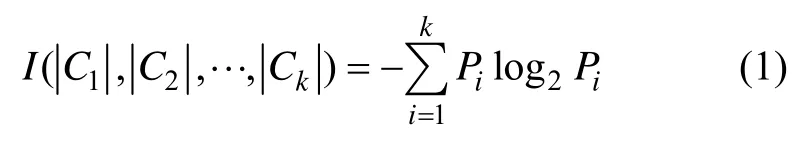
(2) 设描述属性Ak(k=1,2,…,m)有q个不同的取值{a1k,a2k,…,aqk},用描述属性Ak可将数据集T划分为q个子集{T1,T2,…,Tq},Tj(j=1,2,…,q)中的样本在属性Ak上具有相同的取值为子集Tj中的样本数,为子集Tj中属于类别Ci的样本数,则由描述属性Ak划分数据集T所得信息熵为:
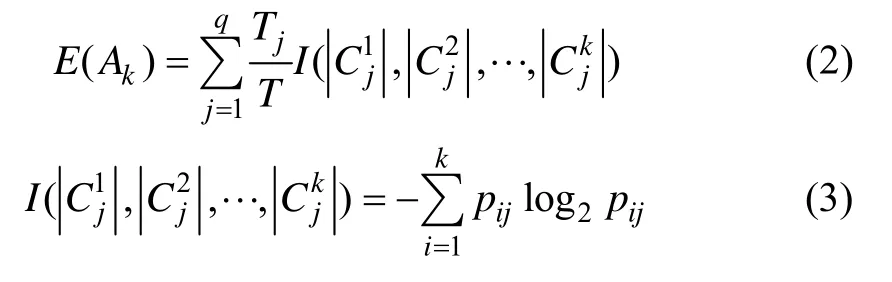
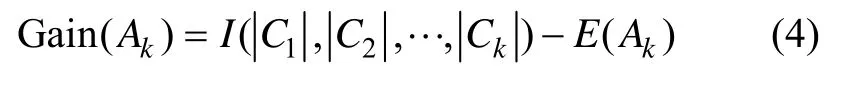
(3) 属性Ak的信息熵为:
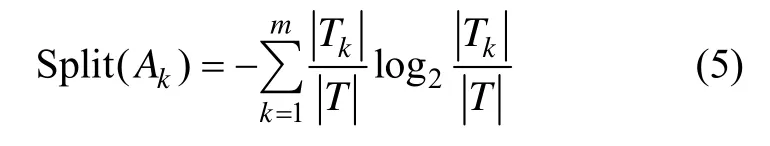
由式(4)和(5)可得信息增益率的计算公式:
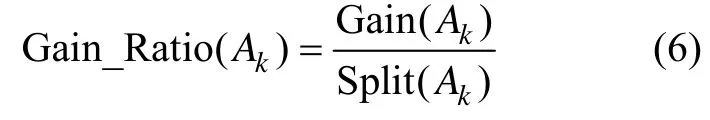
式中:k=1,2,…,m,此式即为描述属性Ak划分数据集T的信息增益率。
Step 2 根据根节点属性不同取值所对应的数据子集,采用与Step1相同的方法递归地建立树的分枝,选择分枝中信息增益率最大的属性作为子节点,如此循环下去,直到所有分枝节点中的样本属于同一类别,即叶节点中所有样本属性取值相同时为止。
Step 3 对生成的决策树进行剪枝,消除噪声和孤立点等随机因素的影响,以得到简化的决策树,C4.5采用的是后剪枝算法[14]。
Step 4 提取决策规则[15]。在C4.5算法中,对于生成的决策树,可以直接获得决策规则,无论是决策树还是决策规则都可以对新的数据集进行分类预测。
C4.5算法在ID3算法的基础上增加了处理连续型属性的功能。在选择某节点上的分枝属性时,对于离散型描述属性,C4.5的处理方法与ID3相同,按照该属性本身的取值个数进行计算;对于某一连续型的描述属性Ak(本文所处理的属性即为连续型属性),如果某节点中数据集的样本数量为Tj,C4.5算法进行如下处理:
(1) 将该节点上的所有数据样本按照连续型描述属性的具体取值,由小到大进行排列,得到属性值的取值序列 {A1k,A2k,…,ATjk}。
(2) 在描述属性序列 {A1k,A2k,…,ATjk}中共生成Tj-1个分割点,共有Tj-1种对数据集的划分方式。设第i(1≤i≤Tj)个分割点的取值为:
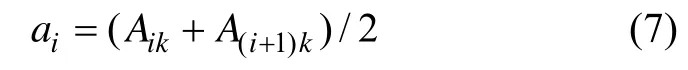
它将该节点上的数据集划分为2个数据子集,可用区间[A1k,ai],(ai,ATjk]的数据样本来表示描述属性Ak的取值。
(3) 属性Ak的Tj-1种分割中的每一种情况,都可作为该属性的2个离散取值,重新构造该属性的离散值,按照上述公式计算每一种分割所对应的信息增益率Gain_Ratio(Ak),选择其中信息增益率最大的分割阈值作为属性Ak的最佳分割阈值,即
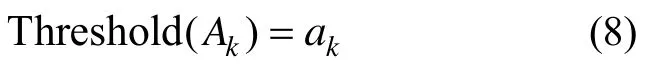
Gain_Ratio(ak) = max{Gain_Ratio(ai)},即ak是ai中信息增益率最大者。
2 C4.5算法的改进
作为ID3算法的改进算法,C4.5在算法功能上增强了不少,但也存在一些不足之处[11]:C4.5算法采用信息增益率作为最佳分裂属性的评判标准,计算描述属性的信息增益率,并选择其中信息增益率最大的描述属性作为节点分裂属性。在连续型属性离散化时,由上述C4.5算法连续型属性离散化方法可知,算法要在任一属性的不同取值中插入若干个分割点,再计算所有分割点的信息增益率,选择其中信息增益率最大的分割阈值作为连续型属性的最佳分割阈值。当决策树的节点数量比较多、连续型属性数量比较多、连续型属性中任一属性取值又比较多时,算法的计算量是相当大的,这将会在很大程度上影响决策树的生成效率。本文针对C4.5算法中连续型属性最佳分割阈值选择算法的计算复杂性问题提出了一些改进,以提高决策树的效率。
2.1 连续型属性处理算法的改进
C4.5算法在连续属性离散化过程中,要对所有划分情况进行预测,这将占用很多时间。如何快速选择一个最佳的划分阈值已成为亟待解决的问题。Fayyad等[16]证明:无论用于学习的数据集有多少个类别,不管类别的分布如何,连续型属性的最佳分割点总在边界点处。
本文根据 Fayyad边界点原理[16]将连续型描述属性按升序排列,选取排序后某一连续型属性的相邻两类边界点处的 6个属性取值ai-2,ai-1,ai,ai+1,ai+2和ai+3(ai-2<ai-1<ai<ai+1<ai+2<ai+3)作为测试属性值。其中:ai是类1中的最大值,ai+1是类2中的最小值。计算相应的信息增益率,选择信息增益率最大的属性值作为最佳分割阈值进行划分。改进后的算法只需计算边界点处6个属性值的信息增益率,相对于传统C4.5算法遍历所有的属性值的信息增益率,其计算复杂度降低了许多。当连续型属性只有2个类别时,简化后算法的计算效率则更高,本文的所要处理的应用对象的实验数据就属于这种情况;当遇到特殊情况即每个属性值仅代表1个类别时,改进算法的计算复杂度与C4.5算法的相当。
2.2 改进决策树C4.5算法描述
算法:决策树 C4.5算法,Function Tree=Create_C4.5(T,A,target)。
输入:训练集T,描述属性A,描述测试样本的类标 target。
输出:决策树Tree,预测分类准确率。
步骤:
(1) 在训练集T中创建根节点N;
(2) 若训练集T中的样本属于同一类别C,则以C标记节点N,并以节点N作为叶节点,返回;
(3) 如果描述属性为空,那么以数据集中占多数的描述类别C标记节点N并将N作为叶节点,返回;
(4) 从描述属性A中选出信息增益率最大的描述属性Ak作为节点N的分裂属性,转入下一步;
(5) 若描述属性是离散型,设属性Ak有v种取值a1,a2,…,av,则数据集T将被Ak分为v个样本子集,每个子集都是由属性取值相同的样本组成的;
(6) 若描述属性是连续型,则用改进的连续型属性分割算法选择最佳分割阈值,并对属性集A进行划分,用离散化后属性集对数据集T进行步骤(5)同样的操作,返回;
(7) 选择剩余描述属性中最佳分裂属性在数据子集上创建子节点,返回;
(8) 对进一步划分的数据子集,即新建各内部节点,递归调用步骤(2)~步骤(7),继续选择最佳分枝属性作为内部节点,直到所有的样本都归类于相应的叶节点为止。
3 实验及结果分析
实验数据由 2个部分组成:(1) 经处理的数字视频图像中行人和车辆的特征数据;(2) 从标准数据集UCI中采集的部分数据。
3.1 实验Ⅰ及结果分析
实验Ⅰ的内容是对改进C4.5算法与传统C4.5算法的分类性能进行比较。实验1所用的部分数据如表1所示。
为了降低分类器的误判率,对部分人车特征数据进行了归一化处理。实验1主要在决策树生成效率和预测能力方面对改进C4.5算法与传统C4.5算法进行了比较。实验数据由训练数据和测试数据2部分组成。实验采用10重交叉验证决策树的分类准确率,各组实验数据的数量不同,逐组均匀增加。实验数据(m,n)分别代表训练集和测试集的样本数量。在各组实验数据上分别训练测试10次,求其平均分类准确率作为本实验的记录值,结果如表2所示。分类准确率定义为测试集中被正确识别出类别的样本数占总样本数的比例。实验结果表明:改进C4.5分类器与传统C4.5分类器的平均分类准确率相当,但在决策树生成时间方面,改进C4.5分类器有很大的改进,减少了很大一部分用时,在一定程度上提高了 C4.5分类器的生成效率。
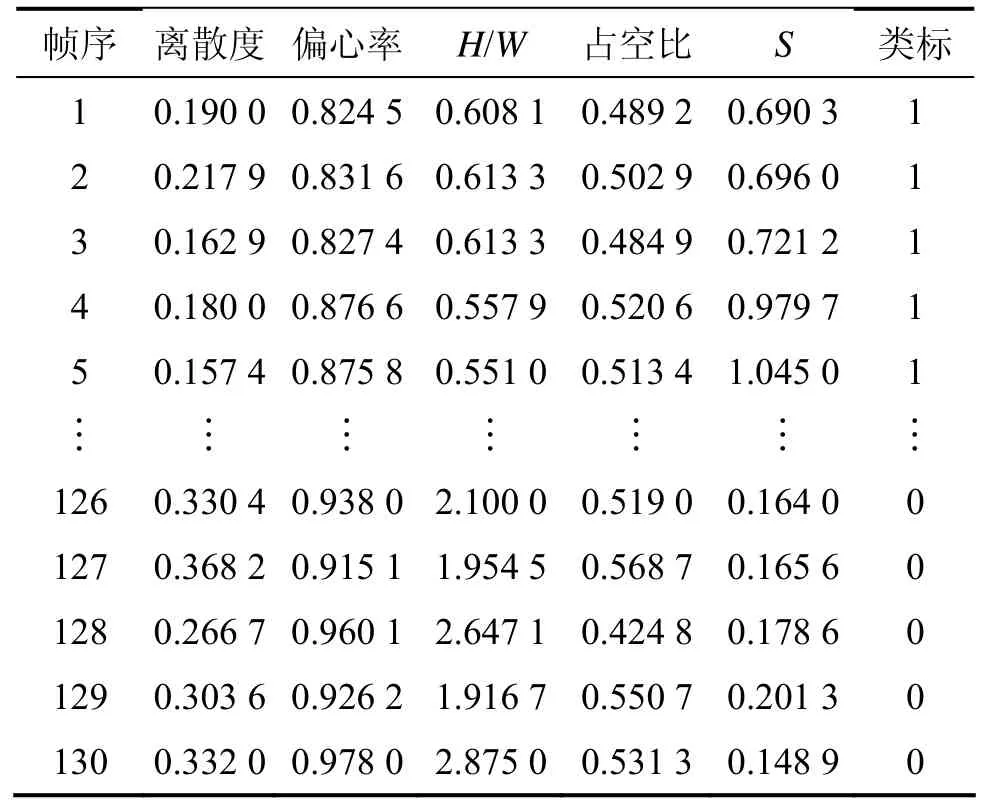
表1 人车特征数据(部分训练特征)Table 1 People and vehicle feature data(part of raining feature)
3.2 实验Ⅱ及结果分析
实验Ⅱ的内容是对改进C4.5分类器与K-均值分类器以及传统C4.5分类器的分类性能比较。所采用的实验数据如表3所示,数据取自标准数据集UCI,每组数据包含数据名称、实例个数、类个数以及属性个数等信息,共11组。实验采用10重交叉验证法在标准数据集上对改进C4.5分类器的预测能力进行测试。各分类器分别在每组数据上测试10次,每次测试采用不同的数据划分方法,采用10次测试分类准确率的平均值作为实验记录结果,最终以各分类器在总数据集上的平均分类准确率为依据,进行分类性能比较。
由实验Ⅱ的结果可知:改进C4.5分类器的平均分类准确率为85.011 0%,比传统C4.5分类器的平均分类准确率高约2.4%,比K-均值分类器高约5.7%。实验结果表明:无论是改进 C4.5分类器还是传统C4.5分类器都有较强的稳定性;改进C4.5分类器和传统 C4.5分类器均比 K-均值分类器的分类性能要好;在某些数据集上,改进C4.5分类器的分类准确率更高。
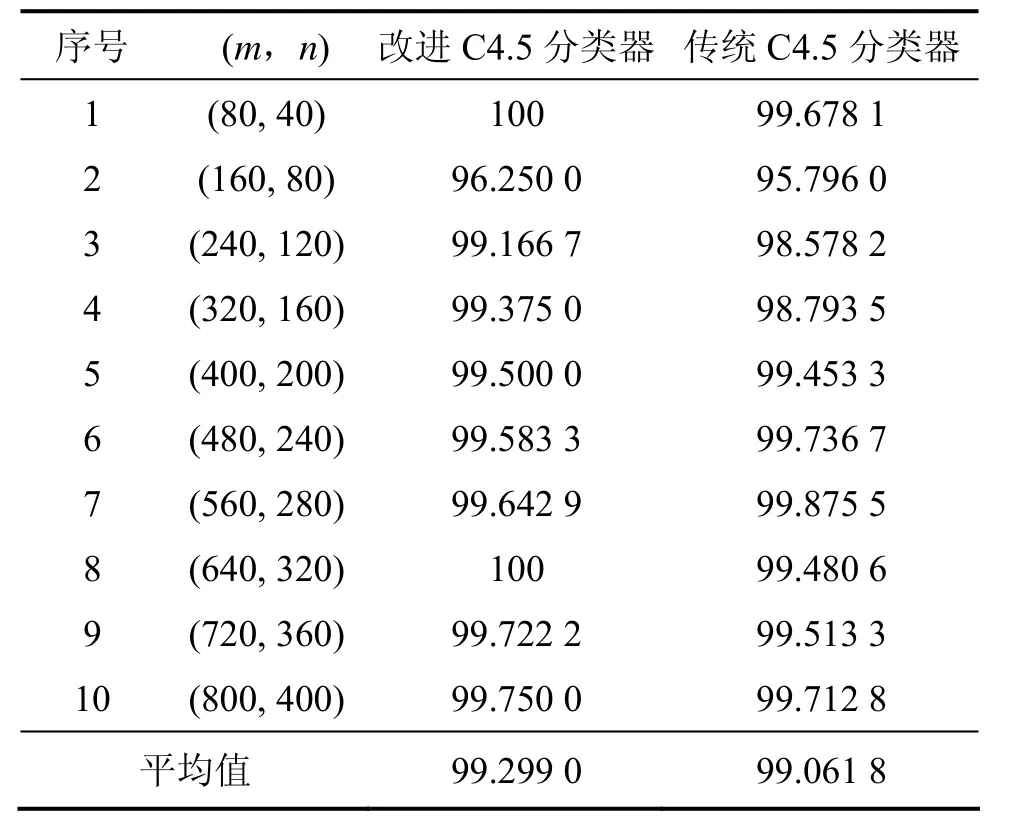
表2 实验Ⅰ的结果Table 2 Results of experiment Ⅰ %
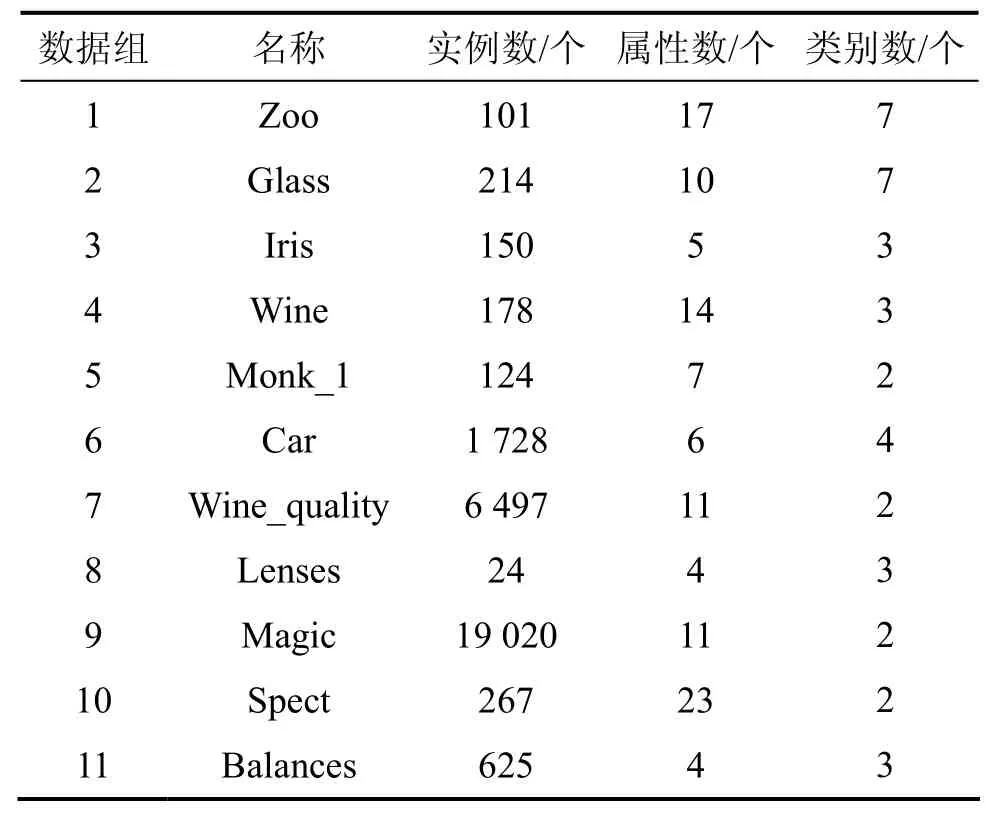
表3 实验Ⅱ的数据集Table 3 Data set of experiment Ⅱ
实验Ⅰ和实验Ⅱ的结果表明;改进C4.5分类器比传统C4.5 分类器的分类准确率略高,但改进C4.5分类器的计算量要比传统 C4.5分类器的计算量减少近20%,大大提高了决策树的生成效率。无论是改进C4.5分类器还是传统C4.5分类器,都比K-均值分类器的分类准确率要高,在算法稳定性方面,前两者也比K-均值分类器要好,由实验结果可知:改进C4.5分类器和传统 C4.5分类器的分类准确率对决策树的节点容错率(同一节点中允许存在的错误样本数占总样本数的比例)较稳定;当节点容错率在0~8%的范围内调整时,改进的与传统的C4.5分类器的分类准确率不变;当容错率继续调大时,二者的分类准确率均缓慢下降;当容错率超过12%时,分类准确率则大幅度下降。分类器的稳定性较差,而K-均值分类器其分类准确率受错误样本的影响较大,如有少量错误样本,K-均值分类器的分类准确率就会明显降低。
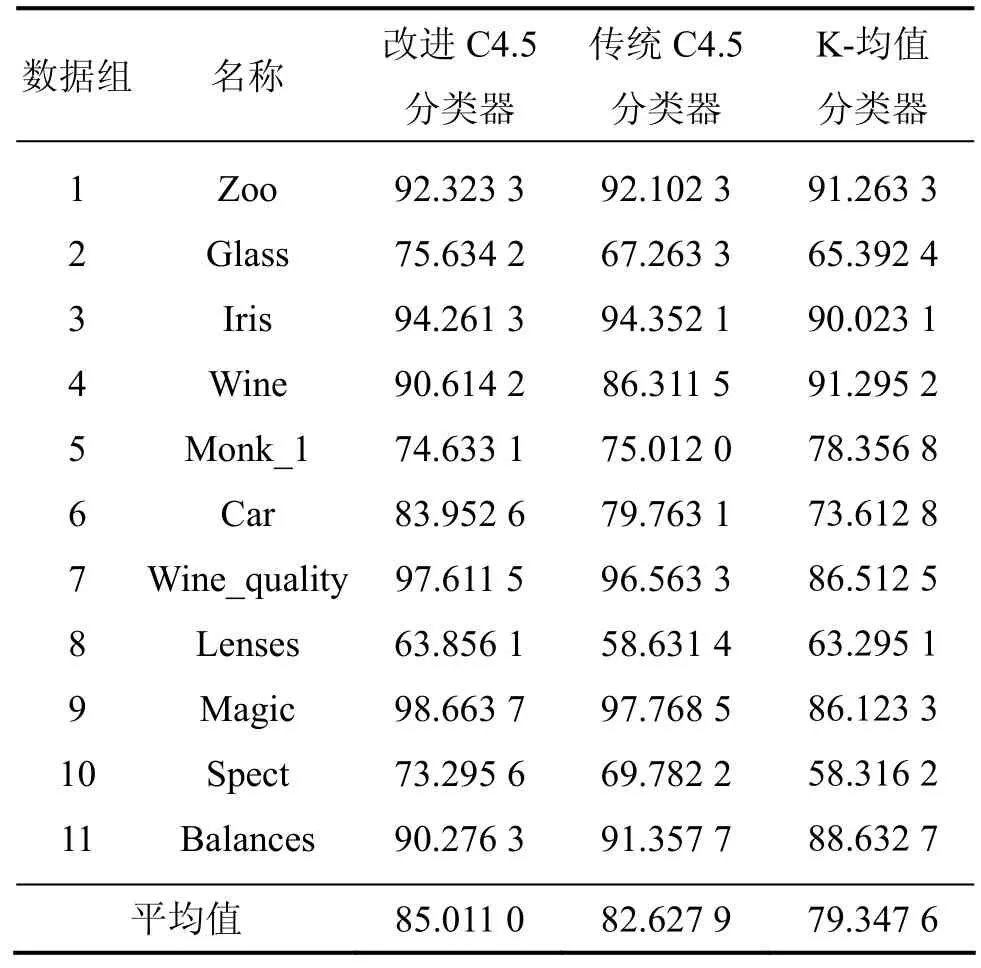
表4 实验Ⅱ的结果Table 4 Results of experiment Ⅱ %
4 结论
(1) 对传统 C4.5分类器处理连续型属性的算法进行改进,提出了一种局部最佳分割阈值选择算法,该算法在很大程度上减少了原算法的计算量,提高了决策树的生成效率,特别是当预测数据集的类别数目比较少时,改进算法的效果更明显。改进的算法可行,决策树的生成效率提高了近20%,改进C4.5分类器具有较好的应用价值。
(2) 在最佳分割阈值选择算法中,如何确定边界点处连续属性的取值个数是关键,取不同的属性个数对算法的计算量影响很大,是否有更好的方法确定边界点处连续属性的取值个数有待进一步研究。
[1]Haykin S. Neural networks and learning machines[M]. Beijing:China Machine Press,2009: 1-7.
[2]ZHU Xiao-liang,WANG Jian,YAN Hong-can,et al. Research and application of the improved algorithm C4.5 on decision tree[C]//IEEE International Conference on Test and Measurement,Hongkong,2009: 184-187.
[3]de Toledo P,Rios P M,Ledezma A,et al. Predicting the outcome of patients with subarachnoid hemorrhage using machine learning techniques[J]. IEEE Trans on Information Technology in Biomedicine,2009,13(5): 794-801.
[4]Tsang S,Kao B,Yip K Y et al. Decision trees for uncertain data[C]//IEEE International Conference on Data Engineering,Shanghai,2009: 441-444.
[5]LI Fa-chao,LI Ping,JIN Chen-xia. Summary of decision tree algorithm and its application in attribute reduction[R].Shijiazhuang: Hebei Univ of Sci and Technol,2009: 313-317.
[6]谢金梅,王艳妮. 决策树算法综述[J]. 软件导报,2008,7(11):83-85.XIE Jin-mei,WANG Yan-ni. Summary of decision tree algorithms[J]. Software Guide,2008,7(11): 83-85.
[7]王阗,佘光辉. 决策树 C4.5算法在森林资源二类调查中的应用[J]. 南京林业大学学报: 自然科学版,2007,31(3): 115-118.WANG Tian,SHE Guang-hui. Application of C4.5 based decision tree algorithm about investigation and analysis of forestry resources[J]. Journal of Nanjing Forestry University:Natural Sciences Edition,2007,31(3): 115-118.
[8]Hunt E B,Marin J,Stone P T. Experiments in induction[M]. San Diego: Academic Press,1966: 77-89.
[9]CHEN Jin,LUO De-Lin,MU Fen-xiang. An improved ID3 decision tree algorithm[C]//4th International Conference on IEEE Computer Science and Education. Chengdu,2009:127-130.
[10]Quinlan J R. C4.5: Programs for machine learning[M]. San Mateo: Morgan Kaufmann Publishers Inc,1993: 17-42.
[11]杨学兵,张俊. 决策树算法及其核心技术[J]. 计算机技术与发展,2007,17(1): 44-46.YANG Xue-bing,ZHANG Jun. Decision tree algorithm and its key techniques[J]. Computer Technology and Development,2007,17(1): 44-46.
[12]Roiger R J,Geatz M W. 数据挖掘教程[M]. 翁敬农,译. 北京:清华大学出版社,2008: 60-85.Roiger R J,Geatz M W. Data mining tutorial[M]. WENG Jing-mong,trans. Beijing: Tsinghua University Press,2008:60-85.
[13]Maszczyk T,Duch W. Comparison of Shannon,Renyi and Tsallis entropy used in decision trees[J]. Artificial Intelligence and Soft Computing,2008,5097: 643-651.
[14]Kantardzic M. Data mining: Concepts,models,and algorithms[M]. New York: John Wiley and IEEE Press,2003:139-164.
[15]ZHOU Chi,XIAO Wei-min,Tirpak T M,et al. Evolving accurate and compact classification rules with gene expression programming[J]. IEEE Transactions on Evolutionary Computation,2003,7(6): 519-531.
[16]Fayyad U M,Irani K B. On the handling of continuous-value attributes in decision tree generation[J]. Machine Learning,1992,8(1): 87-102.
