汉蒙统计机器翻译中的调序方法研究
2011-06-28王斯日古楞斯琴图那顺乌日图
王斯日古楞,斯琴图,那顺乌日图
(1. 内蒙古师范大学 计算机与信息工程学院,内蒙古 呼和浩特 010022;2. 内蒙古师范大学 网络中心,内蒙古 呼和浩特 010022; 3. 内蒙古大学 蒙古学学院, 内蒙古 呼和浩特 010021)
1 引言
关于汉蒙机器翻译,我们曾经做过基于规则的研究[1],基于实例的研究[2]和基于短语的统计方法研究[3]。汉语和蒙古语的语序有较大的差别,在基于短语的汉蒙统计机器翻译系统中,我们发现存在大量的语序错误。在基于短语的统计机器翻译系统的具体翻译结果中,对于两种语言中语序相同的句子,翻译效果较好。例如:
(1) 输入:这张汇款单,在哪里取款?
输出:ENE MONGGO G0BIGVLHV HAGVDASV,HAMIG_A J0G0S GARGAJV ABHV BVI ?

(2) 输入:今天天气怎么样?
输出:ONODOR-UN CAG AGVR-VN BAYIDAL YAMAR BVI ?

可见,以上两个句子中汉语和蒙古语句子语序基本上一样,翻译效果还不错。但是,对于那些语序不同的句子,翻译结果就没那么理想了,会出现大量的语序错误。例如:
(1) 输入:我想参加一个旅游团。
输出:BI 0R0LCAY_A GEJU B0D0JV NIGEN JIGVLCILAL-VN BOLHOM .

(2) 输入:我没有汤匙。
输出:UGEI BI NIGE HALBAG_A .

对于这两个译文,我们是没法接受的。其主要原因是译文语序不符合蒙古语句子的语序。这是由于汉蒙两种语言的语序差异较大,基于短语的翻译模型只能解决一些局部语序的调整。因此,我们考虑使用句法规则,在汉蒙统计机器翻译系统中进行调序。本文提出了基于蒙古语语序的汉语句子调序方法,此调序方法对基于短语的汉蒙统计机器翻译系统的NIST和BLUE值都有明显的提高。
2 基于蒙古语语序的汉语句子调序方法
基于短语的统计机器翻译只解决了短距离的局部调序,为了解决长距离调序,研究人员开始使用基于句法的调序方法。随着统计机器翻译技术的发展,基于句法的统计机器翻译已经成为近几年的研究热点。基于句法的统计方法将句法信息引入翻译中,以句法结构作为翻译单元,建立结构之间的互译关系。在基于句法的模型中,结构之间的互译关系是通过翻译规则联系起来的,这些规则可以从平行语料库中自动获取,也可以通过人工进行归纳总结。
文献[4]和[5]都在源语言预处理阶段使用了语言学句法分析。文献[4]中的规则是对双语语料的学习后得到的,在英语到法语的机器翻译系统实验中BLEU值提高了10%。文献[5]中对于德语到英语的翻译,根据语言学知识总结出六种德语子句到英语的调序规则。文献[6]提出了一种将句法分析和基于短语的统计机器翻译的优点结合起来进行调序的概率方法,对于给定的句子及其句法树,通过树操作生成调序后的n_best作为基于短语统计解码器的输入,此方法在汉语到英语的翻译实验中BLEU值提高了1.56%。
我们在基于短语的汉蒙统计机器翻译系统中提出基于蒙古语语序的汉语句子调序策略。主要方法是对于输入的汉语句子先进行分词和词性标注,之后对句法树进行分析,根据调序规则对需要调序的部分进行调序,使得汉语句子的语序尽量接近蒙古语句子的顺序,最后将调序后的汉语句子送到统计解码器进行单调解码。基本流程如图1所示。
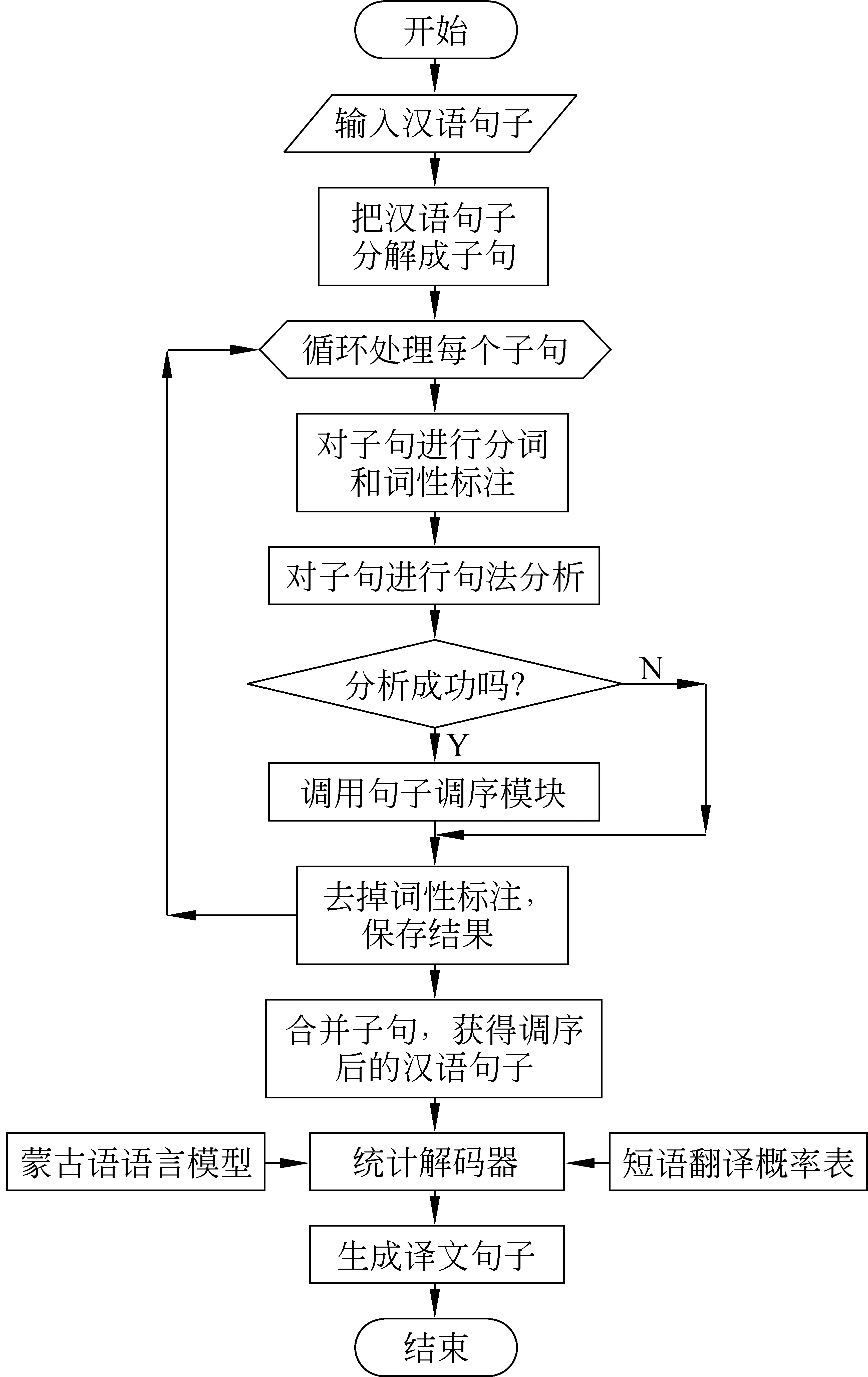
图1 融入调序模型的系统流程
在汉蒙机器翻译系统中,对汉语的分析是前提。为了进行调序,首先要对汉语句子进行分词和句法分析,我们选择了中国科学院计算技术研究所的网上资源ICTCLAS和ICTPROP。
ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)是中国科学院计算技术研究所研制的汉语词法分析系统,作者采用一种基于层叠隐马模型的汉语词法分析方法[7],目前已经升级到了ICTCLAS3.0,我们使用了免费的ICTCLAS1.0,对汉语句子进行分词和词性标注。ICTPROP是中国科学院计算技术研究所开发的一个概率型的自然语言句法分析器[8]。ICTPROP 的分析算法是综合了多种优化策略的改进型chart分析算法, 分析结果是概率最大的一棵分析树。我们使用ICTPROP对汉语句子进行句法分析。
在具体实验过程中,汉语句法分析器对于较长的汉语句子分析成功率较低。为了提高句法分析器的成功率,我们首先将汉语句子分解成子句,然后对每个子句进行分析和调序,最后将调序后的各个子句按照顺序合并成一个句子。一般,汉语句子翻译成蒙古语后,各个子句的顺序是不会改变的,所以这种做法不会影响整个句子的翻译结果。我们通过汉语句子中出现的逗号(,)、分号(;)、冒号(:)、感叹号(!),问号(?)和句号(。)等将汉语句子切分为子句。子句调序的依据是汉蒙句子转换规则,因此我们首先对汉蒙句子转换规则进行了研究,从中总结归纳出了具有语序变化的规则,然后编写了子句调序模块。下面详细介绍调序规则和调序算法。
3 调序规则
我们把汉语句法规则分为两部分,一部分是与蒙古语语序相同的,另一部分是与蒙古语语序不同的。我们只考察那些语序不同的规则,给出相应的变换形式。
规则格式定义为:
其中:X为源语言汉语的短语结构句法规则,对应汉语的正确语序,我们将其称为分析规则,即汉语句法分析规则;Y是汉语规则中的每个语法成分对应到蒙古语时的顺序和成分,即调序部分,我们称其为调序规则。Z是限制条件,指出用此规则调序时,对某个语法成分可设置单词限制条件。条件部分是可选的,即可以有,可以没有。
分析规则X的形式为:α->β
其中α为规则的左部,是一个汉语短语标记(见表1)。β是规则的右部,由一个或多个标记组成,标记可以是短语标记,也可以是词性标记(见表2),各个标记之间以一个空格分割。

表1 概率句法分析器中的句子、短语标记及其对应规则数
调序规则Y的形式为:A(γ1γ2……),其中A表示规则中左部汉语短语标记对应的蒙古语短语标记,每个γi表示一个替换项或一个插入成分。替换项的形式为B/C, 含义是分析规则中的汉语语法成分C在蒙古语中对应语法成分为B,B是蒙古语的词类或短语标记(见表3),C为汉语的词类或短语标记。插入成分形式为D,D为蒙古语的词类或短语标记,S表示蒙古语的一个单词或附加成分,含义是用这个规则调序时,在此位置要插入S。
限制条件Z是单词限制条件,格式:C=S 或C!=S,用来指出某个分析规则中的语法成分对应的单词与S中给出的一个或多个单词相等或不等。

表2 汉语词性标记集

表3 蒙古语词类标记集
例如:vp->vp np=>VP(NP/np VP/vp)$vp!=是
分析规则X为:vp->vp np ,表示汉语的vp由一个vp 后跟一个np组成。
调序规则Y为:VP(NP/np VP/vp),表示汉语的动词短语对应到蒙古语时也是动词短语VP,此VP由NP后跟VP构成,NP对应分析规则的np, VP对应分析规则的vp,可见语序是不同的。
限制条件Z:vp!=是,表示使用此规则调序时,分析规则右边的vp对应的单词不等于“是”。
汉语短语标记使用了汉语概率句法分析器中的短语标记集,见表1。汉语词语用ICTCLAS进行词性标注时选择了北大标记集,即在《现代汉语语法信息词典详解》[9]中规定的汉语词性标记集,见表2,共26个标记。
蒙古语的词类标记使用了在2008年11月通过的《信息处理用蒙古文词语标记集》国家标准[10]。其中一级标记集规定了25个标记,见表3。
对于蒙古语短语,在《蒙古语语法信息词典框架设计》[11]中把蒙古语短语分为名词短语(NP)、形容词短语(AP)、动词短语(VP)、代词短语(RP)、数词短语(MCP)、数量词短语(MP)、方位词短语(OP)、时间词短语(TP)、副词短语(DP)、后置词短语(GP)等10 种,同时根据实际需要,我们参考了文献[12]和[13],将主谓短语(DJ)、语气词短语(SP)和情态词短语(XP)等都放到蒙古语的短语标注集中,共有13个蒙古语短语标记。
确定规则格式和标记集后,我们构造了基于蒙古语语序的汉语句子调序规则。我们在汉语分词、词性标注和句法分析的基础上,对如何将一个汉语句子的短语结构树转换成相应的蒙古语语法树进行了研究,进一步从中归纳出12条具有语序变化的转换规则,把这部分规则我们称之为汉蒙调序规则,包括7条动词短语调序规则,3条介词短语调序规则和2条主谓短语的调序规则,在文献[14]中给出了详细说明。
4 调序算法
根据调序规则,我们设计了调序算法,编写了调序程序。程序主要把以文件形式的规则转换成线性表的形式,同时为了便于调序将概率句法分析器的分析结果树转换成二叉树的形式,最后进行具体调序。调序算法的基本流程为:(1) 根据规则文件,建立相应规则数据表;(2) 根据规则对带词性标记的句子调序;(3) 释放申请的资源;
其中(1)和(2)对应初始化模块和调序模块。
初始化模块主要把文本文件形式的调序规则转换成线性表数据结构,以便分析处理。初始化模块算法流程如下:
打开规则文件
规则序号I=0;
WHILE(规则文件不结束)
{
读入一条规则;
原始字符串规则列表后面插入规则;
从原始字符串规则分离出左边规则;
将〈左边规则,编号I〉对应到关系映射MAP;
分离右边规则;
分析规则,建立反应左边规则变换成右边规则的conv_node数组;
建立调序规则线性表conv_list;
I++;}
调序模块首先将汉语概率句法分析程序的结果树用孩子兄弟表示法转换成一棵二叉树,然后通过二叉树进行语序调序。调序时使用了后序遍历的递归算法。后序遍历的递归算法如下:
Conv_tree(struct_mynode *root)
{ Conv_tree(root.child)
Conv_tree(root.brother)
if(root->child != NULL)
{获取当前规则左部;
获取当前规则右部;
从rulenum查找当前规则,得到编号I;
根据编号从调序规则表CONV_LIST中查找对应调序规则;
如果找到,则根据调序规则进行调序;}
}
我们将调序程序嵌入到统计机器翻译系统中,以开关形式选择是否进行调序。调序模块与统计解码器相互独立,互不影响。
5 实验及其分析
实验语料我们使用了CWMT2009 汉蒙评测语料,实验语料规模如表4所示,开发集和测试集上的实验结果如表5所示。其中:baseline系统[3]是基于短语的汉蒙统计机器翻译系统;QF表示对训练语料进行了形态切分; JF:表示进行了句法调序。

表4 实验语料说明
从表5中我们可以看到,形态切分对于系统性能的提高是非常明显的。同时,调序规则对于在开发集和测试集上的性能都有一定的提高。在开发集实验中, BLEU值在形态切分后提高了1.06%,调序后提高了2.07%。在测试集实验中,切分后BLEU值提高了 1.84%,在切分的基础上进行调序后BLEU值又提高了0.37%。
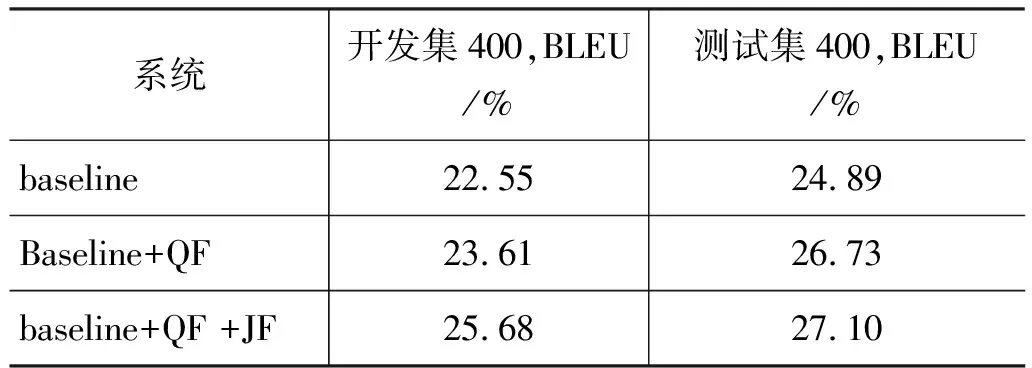
表5 开发集和测试上的实验结果
为了测试句法调序模块的真正作用,我们通过人工分析,从开发集和测试集中将词法和句法分析错误的句子去掉,从400个句子的开发集中挑出了261个汉语分析正确的,从400个句子的测试集中挑出了244个汉语分析正确的句子进了实验,实验结果如表6所示。表6给出的实验结果显示,在语言模型和短语表相同的情况下,我们看到在基于短语的汉蒙统计机器翻译中,使用词法和句法等语言学知识能够提高系统性能。在开发集实验中,BLEU值切分后提高了0.27%,调序后提高了3.59%。在测试集实验中,切分后BLEU值提高了2.15%,在切分的基础上进行调序后BLEU值提高了0.65%。

表6 过滤后开发集和测试上的实验结果
下面是加入调序模块后的系统运行过程及翻译结果实例。
输入:我想参加一个旅游团。
分词之前: 我想参加一个旅游团。
分词之后: 我/r 想/v 参加/v 一个/m 旅游团/n 。/w
调序之后: 我/r 一个/m 旅游团/n 参加/v 想/v 。/w
使用的规则: vp->vp np=>VP(NP/np VP/vp)$vp!=是
使用的规则: vp->vp vp=>VP(VP//vp VP/vp)
去掉标记后: 我 一个 旅游团 参加 想 。
译文2: BI NIGE JIGVLCILAL-VN BOLHOM-DU 0R0LCAHV GEJU B0D0JV BAYIN_A .

实验结果显示对于语序差异较大的汉语和蒙古语,基于蒙古语语序的汉语句子调序方法对于系统性能的提高相当有效。下一步,我们将不断地完善调序规则,扩大语料库规模,进一步提高基于短语的汉蒙统计机器翻译系统的性能。
[1] 那顺乌日图,刘群,巴达玛放德斯尔.关于汉蒙机器辅助翻译系统[J].阿尔泰学报,2001:91-95.
[2] 侯宏旭,刘群,那顺乌日图.基于实例的汉蒙机器翻译[J].中文信息学报,2007,21(4):65-72.
[3] 王斯日古楞,斯琴图,那顺乌日图.基于短语的汉蒙统计机器翻译研究[J],计算机工程与应用,2010,(5):138-142.
[4] Fei Xia, and Michael McCord 2004. Improving a Statistical MT System with Automatically Learned Rewrite Patterns[C]//Proceedings for COLING 2004.
[5] Michael Collins, Philipp Koehn, and Ivona Kucerova.2005. Clause Restructuring for Statistical MachineTranslation[C]//Proceedings for ACL 2005.
[6] Chi-Ho Li, Dongdong Zhang, Mu Li, Ming Zhou, Minghui Li, Yi Guan,A Probabilistic Approach to Syntax-based Reordering for Statistical Machine Translation[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, June, 2007:720-727.
[7] 刘群,张华平,俞鸿魁,等,基于层叠隐马模型的汉语词法分析[J].计算机研究与发展,2004,41(8):1421-1429.
[8] 张浩,刘群,白硕.结构上下文相关的概率句法分析[C]//第一届学生计算语言学研讨会(SWCL2002)2002.
[9] 俞士汶,等.现代汉语语法信息词典详解[M].北京:清华大学出版社,1998年.
[10] 那顺乌日图,等.《信息技术 信息处理用蒙古文词语标记集》国家标准[S].2008年11月.
[11] 那顺乌日图.蒙古语语法信息词典框架设计[D].内蒙古大学,2000年博士学位论文.
[12] 巴达玛敖德斯尔.面向机器翻译的汉蒙短语转换规则研究[M].呼和浩特:内蒙古教育出版社,2006年3月.
[13] 达胡白乙拉.蒙古语基本动词短语自动识别研究[D]. 呼和浩特:内蒙古大学, 2005年博士学位论文.
[14] Wang.Siriguleng,Siqintu and Nasun-urtu. The research on reordering rule of Chinese-Mongolian statistical machine translation[J]. Advanced Materials Research Vols,268-270(2011): 2185-2190.
