混凝土性能预测及配合比优化系统Compos的设计与实现*
2011-05-22陈斌刘西军张晓悦陈晓东刘国华
陈斌,刘西军,张晓悦,陈晓东,刘国华
(1. 浙江水利水电专科学校,杭州,310018;2. 中国水电顾问集团华东勘测设计研究院,杭州,310014;3. 浙江大学建筑工程学院,杭州,310058)
1 引言
在给定原材料品种、质量及配合比的情况下,混凝土性能(包括强度、工作性和耐久性)具有唯一对应值,因此必然是可预测的。通过建立各种线性或非线性数学模型,使预测精度得到一定保证,则可用于混凝土配合比设计和生产质量控制等各个方面,是混凝土工程的基础性工作之一。传统的混凝土性能预测方法以水灰比定则(保罗米公式)为代表,其认为可塑性混凝土的抗压强度完全受水灰比的控制,而与其他因素无关。近年来,由于混凝土不断向高强、高性能化发展,成分不断复杂,水灰比定则已不完全适用[1]。因而发展出各种调整方法。然而,最直接的混凝土性能预测,仍在于以原材料用量及质量为自变量,通过合适的数学模型,直接推求混凝土性能,已被证明比以各种比率指标(如水胶比、砂率、浆骨比等)为自变量推求混凝土性能更为有效[2]。笔者基于国内文献公开发表的613组配合比,采用逐步线性回归和支持向量机等方法,建立混凝土性能预测模型;继而采用线性规划的单纯形法、粒子群算法建立配合比优化模型,最终集成为Compos混凝土性能预测及配合比优化专家系统。系统同时提供了按《规范》(JGJ55-2000)设计配合比和大体积混凝土温度场分析功能。
预测、优化变量的选取见表1、表2。
2 混凝土性能预测模型的建立
2.1 线性逐步回归模型
多元线性回归是最简单、最直接的变量相关性统计分析方法,具有物理意义明确、确定性强等优点。由于混凝土性能预测模型的自变量数量较多,可能并非所有的自变量都与因变量有显著关系,换言之,部分自变量的作用可以忽略,其加入甚至可能降低模型的预测准确性。因而产生了如何从大量可能相关的自变量中挑选出对因变量有显著影响的部分自变量的问题。逐步回归分析方法应运而生,其基本思想是:将变量逐个引入,引入变量的条件为偏回归平方和经检验是显著的,同时每引入一个新变量后,对已选入的变量逐个检验,将不显著变量剔除。这样保证最后所得的变量子集中的所有变量都是显著的,经若干步后,可得“最优”变量子集。有关逐步线性回归方法的具体算法可参考相关文献[3],本文不赘述。Compos系统的多元逐步线性回归界面,如图1所示。

表1 预测、优化模型的可选自变量

表2 预测、优化模型的可选因变量
2.2 BP人工神经网络
线性回归模型虽然具有简单、直接的优点,但拟合能力有限。若混凝土性能与各自变量间存在非线性关系,则需采用非线性预测模型。最常规的非线性模型当属多项式拟合。根据泰勒定理,当泰勒级数的项次趋向无穷时,可以任意精度拟合任何函数。但是经验表明,多项式拟合计算效率较低,但自变量数量较多时,耗时量相当大,且实际选用的项次不可能过多。近年来,人工神经网络模型(主要为BP人工神经网络)受到较多关注。所谓BP人工神经网络,就是以输入单元为自变量,输出单元为因变量、网络单元间的连接权值和阈值为调整参量,按最小误差原则逐步反馈修正而使网络达到最佳模拟状态的一种数学算法。其拓扑结构如图2所示[4]。
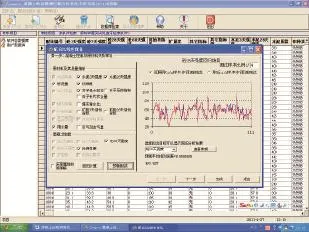
图1 Compos系统的混凝土性能线性回归分析界面

图2 BP神经网络示意
BP神经网络的主要参数为隐含层(中间层)单元数。合适的隐层单元数选择是一个比较复杂的问题,最佳的隐层单元数与输入、输出单元数,训练集样本数均有关系,目前尚无成熟的理论方法,基本上依赖经验选定。隐层单元数过少,训练达不到应有精度,容易出现“欠拟合”;隐层单元数过多,则易出现“过拟合”。笔者经过大量试验,发现隐层单元数输入样本数的1/2(9个),预测精度基本已达到最优。考虑输入、输出层单元数的变化,基本认为隐层单元数取10,通常情况下均能适用。
为了控制过拟合,笔者进一步提出了一种“误差跟踪策略”,即:首先进行第一次网络训练和预测,以其预测误差作为最优误差的初始值。而后网络每训练一次,立即对预测样本组进行预测,若预测误差小于初始值,则取其为最优值并记录发生位置,如此不断重复计算,直至网络训练误差或训练次数达到预定值为止,见图3。从图上看,预测相对误差过程线开始上扬的A点,即为训练截止点,超过该点,网络训练即进入过拟合状态。
2.3 支持向量机模型
BP人工神经网络具有较强的非线性拟合能力,但实践表明,其过拟合控制能力较差。所谓“过拟合”,即指模型过度拟合样本的个别甚至错误信息,而偏离了对整体规律的把握。支持向量机模型(SVMs)是一种基于统计学习理论的新型算法,其建立在统计学习理论的VC 维理论和结构风险最小原理基础上,能有效抑制过拟合,被普遍认为优于人工神经网络[5,6]。

图3 过拟合状态示意
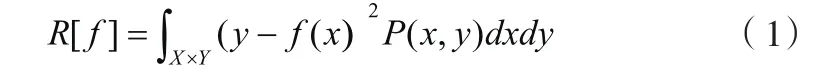
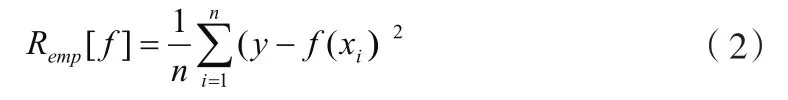
根据大数定律,式(2)只有当样本数n趋于无穷大且函数集足够小时才成立。这实际上是假定最小二乘意义的拟合误差最小作为建模的最佳判据,结果导致拟合能力过强的算法的预报能力反而降低。为此,SLT用结构风险函数 ][fRh代替 ][fRemp,并证明了 ][fRh可用下列函数求极小而得:
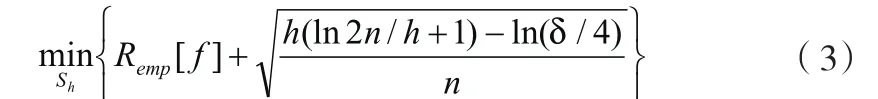
此处n为训练样本数目,Sh为VC维空间结构,h为VC 维数,即对函数集复杂性或者学习能力的度量。1-δ为表征计算的可靠程度的参数。
SLT要求在控制以VC维为标志的拟合能力上界(以限制过拟合)的前提下追求拟合精度。控制VC维的方法有三大类:1)拉大两类样本点集在特征空间中的间隔;2)缩小两类样本点各自在特征空间中的分布范围;3)降低特征空间维数。一般认为特征空间维数是控制过拟合的唯一手段,而新理论强调靠前两种手段可以保证在高维特征空间的运算仍有低的VC维,从而保证限制过拟合。
对于分类学习问题,传统的模式识别方法强调降维,而SVM与此相反。对于特征空间中两类点不能靠超平面分开的非线性问题,SVM采用映照方法将其映照到更高维的空间,并求得最佳区分二类样本点的超平面方程,作为判别未知样本的判据。这样,空间维数虽较高,但VC维仍可压低,从而限制了过拟合。即使已知样本较少,仍能有效地作统计预报。
对于回归建模问题,传统的算法在拟合训练样本时,将有限样本数据中的误差也拟合进数学模型了。针对传统方法这一缺点,SVR采用“ε 不敏感函数”,即对于用f (x)拟合目标值y时时,即认为进一步拟合是无意义的。这样拟合得到的不是唯一解,而是一组无限多个解。SVR方法是在一定约束条件下,以取极小的标准来选取数学模型的唯一解。这一求解策略使过拟合受到限制,显著提高了模型的预报能力。
3 混凝土配合比优化模型
3.1 单纯形法优化混凝土配合比
当混凝土性能预测模型为线性方程,则可采用线性规划的单纯形法进行配合比优化。以1m3混凝土的成本最低为优化目标,以混凝土的设计强度、工作性或耐久性指标为约束条件,优化的数学模型表示如下:
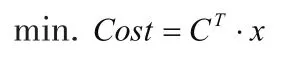

式中, A = [ aij]m×n为线性约束方程组的系数矩阵;为线性约束方程组的右端项矩阵;x = [x ,x...x]T12n为原材料的用量;C =[c1,c2...cn]T为不同原材料的价格;m为约束条件数量,n为自变量数量。
单纯形法通过从可行域的一个极点出发,先判断该点是否是极小点,如是,则运算结束;否则沿能使目标函数下降的方向搜索,抵达下一个极点;继续执行这一过程,直到获得最优点为止。其基本过程包括求基本可行解,换基、转轴运算等。有关单纯形法的原理和计算过程可参见文献[7]。图4和图5为采用单纯形法优化混凝土配合比的参数设定及计算结果界面。
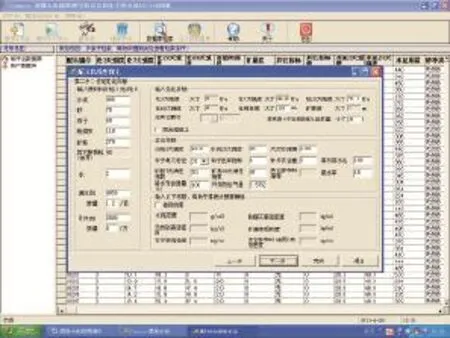
图4 Compos系统优化配合比的参数选择界面
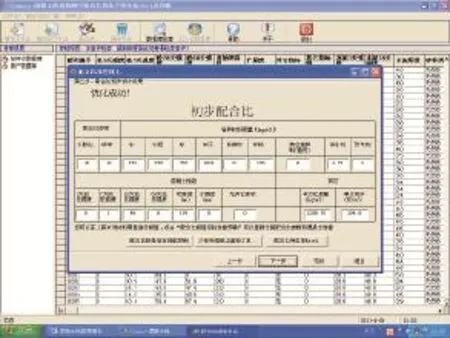
图5 Compos系统优化混凝土配合比的结果输出界面
3.2 粒子群算法优化混凝土配合比
粒子群优化算法或称微粒群算法(PSO)是1995年Russell Eberhart和James Kennedy提出的[8],PSO源于人工生命理论和鸟类和鱼类的群集行为,是一种基于群体智能的优化技巧。与其他进化类算法相似,PSO也采用“群体”与“进化”的概念,同样也是依据个体(粒子)对环境的适应度大小进行操作,所不同的是粒子群算法不像其他进化算法那样对于个体使用进化算子,而是将每个个体看作是在多维搜索空间中没有体积和重量的粒子,以一定的速度飞行搜索,并按照个体的飞行经验和群体飞行经验动态地调整飞行的速度,经若干代的并行搜索趋近最优解。现考虑如下的优化模型:

其中,f ( X)为定义在D维欧氏空间 ED的区域S上的实函数,设 N为群体规模,为粒子i的当前位置,为粒子i的当前飞行速度,fitnessi= f (Xi)为粒子i的适应度值,其中 i = 1 , 2 ,L,N.记pbesti和分别为粒子i曾经达到的最佳适应度值及其对应于D维空间中的位置,gbest和 Pg=(pg1, pg2,L,pgD)T分别为群体中所有粒子曾经达到的最佳适应度值及其对应位置。基本粒子群算法采用的进化方程(动态调整规则)是:
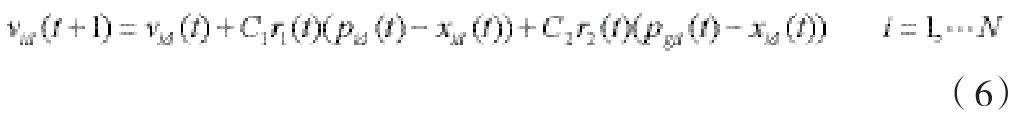

式中,下标i表示第i个粒子,d表示粒子的第d维,t表示第t代,C1,C2为学习常数,分别称为认知参数和社会参数,通常在0~2间取值, r1~∪(0,1)和r2~∪(0,1)为两个相互独立的随机数。
为了改善算法的收敛性能,1998年Y.Shi和R.C. Eberhart在速度进化方程中引入惯性权重w[9],即:
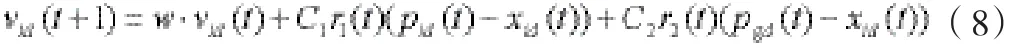
采用(6)(7)式的称基本粒子群算法,采用(8)(7)式的称标准粒子群算法。
取混凝土各种原材料的用量为“粒子”,可建立上述的PSO优化模型。优化模型中,需考虑强度、工作性、耐久性等约束条件。可采用适应度与违反度双值控制法。将约束条件与目标函数分离,让每个粒子都具有两个函数值,一个对应于目标函数的适应度值,一个对应问题的约束条件,反映粒子关于约束的违反程度。

粒子的优劣将由上述二个函数按一定规则决定:
a.当二个粒子i和j都可行时,比较它们的适应度值fitness i和fitness j,适应度值小者为优;
b.当二个粒子i和j都不可行时,比较它们违反度值voilationi和 vo ilationj ,违反度值小者为优;
c.当粒子i可行,粒子j不可行,如果voilalionj>e则粒子i为优;若voilalionj<e则比较它们的适应度值fitness i和fitness j,小的粒子为优。有关PSO算法的具体过程可参见有关文献[10]。图6是PSO算法优化混凝土配合比的过程。
4 Compos系统的集成
以配合比数据库为平台,笔者集成了混凝土性能预测与配合比优化系统。系统同时包含了按《普通混凝土配合比设计规程》(JGJ55-2011)和《水工混凝土试验规程》(SL 352-2006)设计配合比,以及基于有限元法的大体积混凝土温度场分析的模块。系统框架如图7所示。
图6 PSO算法的优化过程

图7 Compos系统框架
系统同时具有Excel数据导入与导出、试验调整等功能,方便用户的整个配合比设计、试验流程。
[1]陈斌,李富强,刘国华,等. 混凝土配合比的非线性多目标优化研究[J]. 浙江大学学报,2005, 39(1): 16-19.
[2]Dias W P S, Pooliyadda S P. Neural networks for predicting properties of concretes with admixtures[J]. Construction and Building Materials, 2001(15): 371-379.
[3]徐世良主编. C常用算法程序集(第二版)[M]. 北京:清华大学出版社,1996.
[4]刘国华,陈斌等,基于人工神经网络和Monte-Carlo法的混凝土配合比优化设计研究,水力发电学报[J],2003(4):45-53.
[5]S. M. Gupta. Support Vector Machines based Modeling of Concrete Strength[J]. International Journal of Electrical and Computer Engineering, 2008,3(5): 312-318.
[6]崔海霞. 高强混凝土强度预测的支持向量机模型及应用[J]. 混凝土, 2010(5): 49-51.
[7]汪树玉,刘国华. 系统分析[M]. 杭州:浙江大学出版社,2002.
[8]Kennedy J., Eberhart R.C . Particle swarm optimization [C].In: Proc. IEEE Int. conf. on neutral network,1995,1942-1948
[9]Shi Y., Eberhart R.C. A modified particle swarm optimizer[C]. In: IEEE world congress on computational intellegence,1998, 69-73.
[10]刘华莹,林玉娥,王淑云. 粒子群算法的改进及其在求解约束优化问题中的应用[J]. 吉林大学学报(理学版),2005(4):
