Apriori算法改进研究
2011-04-23罗晓丽福州职业技术学院计算机系福建福州350007
罗晓丽 (福州职业技术学院计算机系,福建福州350007)
随着信息时代的到来,越来越多数据大量涌现,如何从这些大量的、复杂的、有噪声的原始数据中发现有价值的信息成为目前数据挖掘的主要任务,数据挖掘[1]即从大量的、不完全的、有噪声的数据中,挖掘出的隐含的、事先未知的、潜在的对决策者有用的信息和知识的过程。Agrawal等提出经典的关联规则挖掘算法,即Apriori算法[2]。该算法每次循环都要扫描一遍数据库,用来计算候选项集的支持数。但随着项集阶数的增加,候选项集的个数逐渐减少,包含这些候选项集的记录数也越来越少,因而没有必要对数据库中的所有记录都进行扫描计算支持数,由此导致数据挖掘效率较低。为此,许多学者对Apriori算法进行了改进,如基于散列 (Hash)技术的优化算法[3]、基于项编码的Cording-Apriori算法[4](简称CA算法)、基于减少数据扫描记录数的AprioriTid算法[5](简称TID算法)等。笔者在研究上述改进算法的基础上,通过压缩原有数据库生成包含有频繁1-项集的数据库作为扫描的数据库,并运用CA算法进行编码转换,逐步缩小了数据库搜索的时间和编码转换的时间和位长,从而提高数据挖掘的效率。
1 Apriori算法原理
Agrawal等首次提出将关联规则[6]应用于解决挖掘顾客交易数据中项目集间问题,其核心是基于2阶段频繁集思想 (即发现频繁项目集和生成关联规则)的递推算法,其典型算法是Apriori算法,该算法的主要内容如下:①使用逐层搜索的迭代方法。首先扫描数据库,计算出各个频繁1-项集的支持度,找出所有频繁1-项集L1,得到频繁1-项集的集合。②连接步。由2个只有一个项不同的频繁1-项集进行JOIN运算得到的候选频繁2-项目集C2。③剪枝步。对C2进行修剪得到频繁项集L2。④通过扫描数据库,计算各个项集的支持度,将不满足支持度的项目集去掉,通过迭代循环,重复步骤2~4,直到找到最大频繁项集,此时算法停止。
随着扫描的数据量增大,Apriori算法也呈现出明显不足:①候选集Ck中的每个元素都必须通过扫描数据库一次计算支持度,来确定其是否能成为频繁项集Lk中的元素,而多次扫描事务数据库,需要很大的I/O负载。②随着扫描数据库的事务量增大,可能有庞大的候选集产生。规模巨大的候选项集,不仅处理需要占用大量的主存空间,而且算法必须耗费大量的时间来处理。例如:对于频繁1-项集个数如果是10000个,那么可能产生的候选集就会有个。
2 基于项编码的CA算法
基于项编码的CA算法[7],只需要扫描数据库一次,并对每个项完成编码转换,根据它在数据库中出现的事务记录用0和1进行编码,以后的过程都是针对编码进行运算,统计1的个数计算支持数k项频繁项集,通过编码与运算生成k+1项频繁项集,不需要再次扫描数据库。其具体特点如下:①编码运算。该算法只需要扫描一次数据库,并对每个项在某个事务记录中是否出现进行编码,以 “出现为1,不出现为0”的原则进行编码,以后的过程都是针对编码进行与运算。与Apriori算法相比,该算法仅扫描数据库一次,因而减少了算法的I/O负载。②连接前剪枝。CA算法在对频繁 (k-1)-项集Lk-1通过与运算进行连接,得到候选频繁k-项集Ck,并对Lk-1中1的个数进行计数处理,根据计数结果删除Lk-1中包含出现次数小于 (k-1)的项的项集,以减少参加连接的 (k-1)项的数量,从而降低了组合的数据量,也减小了候选频繁k-项集Ck的大小。但该算法在进行编码转换时需要消耗大量时间,而且编码数位过长,I/O的负载过大;同时由于编码过长,造成与运算的繁复,可见记录的个数极大地影响了该算法运行的时间。
3 基于减少数据扫描记录数的Tid算法
Tid算法[5]使用了Apriori-Gen函数,以便在遍历事务数据库之前确定候选频繁项集。该算法的特点是在第一次扫描之后就不再使用原来的事务数据库来计算支持度,而是通过在第一次扫描生成的候选事务数据库Ck,来计算候选频繁项集的支持度。随着频繁项集的维数的增加,扫描的数据库遂渐缩小,因而减少了扫描的时间。尤其是对于数据库的记录是海量数据时,运行扫描的时间大大减少,同时减少的数据量,减少了内存的占用空间,因而数据挖掘的效率较高。
4 改进算法
通过上述分析可知,要提高算法的运行效率,可从如下方面进行处理:①降低扫描事务的记录数。②计算支持度时减少扫描数据库的次数。由此笔者提出通过减少数据库的记录数来减小编码转换时间的改进算法,其基本思路是先进行一次扫描,计算出候选频繁1-项目集,将含有1-项目集的记录重新组合生成新的数据库 (比原来的数据库记录大为减少,尤其是海量数据库减少的记录数量更多),并利用CA算法对新生成数据库进行编码转换。这样以后不再扫描的数据库,而是通过编码与运算生成候选频繁项集,通过统计项编码中1的个数计算支持度。由于只进行一次扫描,且缩小了扫描范围,因而加快了运算速度,提高数据挖掘的效率。
改进算法的具体描述如下:

5 实例分析
为了解改进算法与CA算法、Tid算法在性能上的差异,进行以下相关试验。试验用服务器:P4 2.0GHz 4G内存、SQL Server2000;客户机:P4 2.0GHz、1M内存。以福州职业技术学院计算机系2007级计算机专业学生 (600名)成绩构成原始数据库,该数据库共有61113条记录。
使用数据库中前30000条记录在不同最小支持度阈值条件下进行关联规则挖掘。最小支持度阈值min_sup分别设置为5%、10%、15%、20%、25%。分别用Tid算法、CA算法和改进算法法进行关联规则挖掘,其结果如图1所示。
从图1可以看出,随着最小支度的增大,3种算法的执行时间呈下降趋势,其中改进算法的执行时间始终最少,说明其挖掘效率较高。
在最小支持度阈值相同的条件下,选取数据库中不同记录数进行关联规则挖掘。分别选取数据库的前5000条、前10000条、前15000条、前20000条、前25000条和前30000条记录,最小支持度阈值min_sup=20%。分别用Tid算法、CA算法和改进算法进行关联规则挖掘,其结果如图2所示。

图1 不同最小支持度阈值条件下改进算法、Tid算法和CA算法的执行时间比
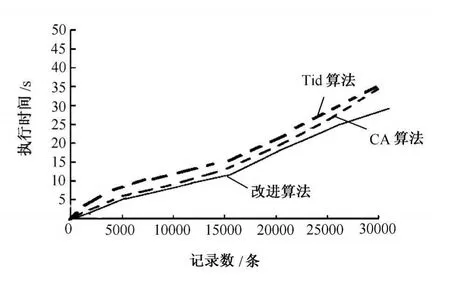
图2 不同记录数条件下改进算法、TiD和CA算法执行时间
从图2可以看出,当数据记录比较少时,3种算法的执行时间差别不大;当数据库中记录数较大时,CA算法与Tid算法的执行时间比改进算法的执行时间多。究其原因,是因为随着数据库规模的增大,由于编码转换的位长增长和与运算的复杂性加大,导致CA算法与Tid算法的执行时间较多,而改进算法由于先进行数据库的压缩,当针对海量数据时,其运行时间明显减少。
6 结 语
通过阐述Apriori算法原理,指出该算法的不足。针对该算法的不足之处,提出了一种保留含有频繁1-项集的数据库作为扫描数据库的改进方案。实例分析表明,改进算法不仅缩小了扫描数据库的规模,而且减少编码转换位长,逐步缩小了数据库搜索及与运算的时间,从而提高了数据挖掘的效率。
[1]韩家玮.数据挖掘·概念与技术[M].北京:机械工业出版社,2006.
[2]焦亚冰.关联规则挖掘算法的研究与应用 [D].济南:山东师范大学,2008.
[3]彭永供,王靓明.基于散列技术的高效剪枝关联规则挖掘算法[J].南昌大学学报,2009,33(5):494-498.
[4]叶晓波.一种基于二进制编码的频繁项集查找算法 [J].楚雄师范学院学报,2009,24(3):13-19.
[5]曲春锦.Aproiri-T IDS算法设计及其在教育决策信息挖掘中的应用 [D].上海:上海海事大学,2006.
[6]黄建明.关联规则挖掘算法的研究与应用 [D].西安:西安建筑科技大学,2009.
[7]李磊,向正义.一种基于二项编码的改进设计[J].微计算机信息,2009,7(3):214-215.
