并行系统中KMP串匹配算法的实现
2011-02-19李艳鵾付维娜
李艳鵾,付维娜,刘 帅,祝 明
LI Yan-kun1,FU Wei-na2,LIU Shuai3,ZHU Ming1
(1.长春工业大学 工商管理学院,长春 130012;2.长春工程学院 软件学院,长春 130012;3.吉林大学 计算机科学与技术学院,长春 130021)
0 引言
字符串匹配算法作为字符串所有算法的基础,其重要性毋庸置疑,KMP算法以其为n的线性函数的时间复杂性而成为字符串匹配中的常用算法[1,2],并一直使用至今。近年来也有很多关于KMP算法的研究[5,6],取得了很好的结果,同时也有很多KMP在模式识别、模式匹配方面的成果[8,9]。
但是,KMP算法的时间复杂性一直无法得到有效的改善。为了改善KMP算法的复杂性,本文将KMP算法推广至并行机进行并行处理,以降低其时间复杂性。
并行处理采用多处理机对多进程进行并行处理,对很多传统算法的并行化已成为一个计算机领域的研究方向[3]。因此,如果能将KMP算法并行化,则可以大大降低其时间复杂性。
因此,本文在文献[4,7]的基础上,将KMP算法并行化,并通过加入冗余串来解决KMP算法的丢解情况,并得出实验数据。通过实验可知,本算法可以在不降低代价的前提下,对KMP算法进行优化,并且其效率和扩展性均良好。
本文的贡献在于:1)对KMP的并行化有效的降低了匹配时间;2)并行化算法的效率和扩展性良好,已达到并行的最优界限。
1 并行算法参数设置
1)运行时间t(n)=tr+tc,其中tr为数据经由网络或存储器的选路时间,tc为数据在处理器内部进行算术、逻辑运算所需的计算时间。
2)处理器数目p(n),求解问题所需的处理器数目,通常p随问题规模n变化函数为p(n)=n1-e(0<e<1)。
3)并行算法代价c(n)=t(n)·p(n),若解决某一问题的并行算法的执行代价与最坏情况下串行算法的运行时间(步数)同阶,则称其为代价最佳。
4)加速比Sp(n)=ts(n)/tp(n),其中ts(n)为求解问题最快速的串行算法最坏情况下的运行时间,tp(n)为求解同一问题的并行算法在最坏情况下的运行时间。显然,Sp(n)越大,并行算法越好,1≤Sp(n)≤p(n)。
5)并行算法效率Ep(n)= Sp(n)/p(n),用于度量并行算法中处理器的利用效率。
6)并行算法伸缩性:给定处理器数目p,若Ep(n)随问题规模n增加而单调递增,则称此算法为可伸缩的。
2 KMP算法在并行系统中的实现
2.1 KMP算法简介
Knuth-Morris-Pratt串匹配算法主旨思想:自左向右进行字符匹配,通过构建模式串的next函数记录模式串自身属性信息,从而充分利用上次匹配得到的有效信息将正文与模式在不漏解的情况下尽可能的向右滑动足够大的距离。
设长度为n正文串以t[n]形式存放,模式串以p[m]存放,考虑构建KMP算法中的next函数应具有辨别匹配位置的特性,我们将next函数定义如下:

再由于KMP算法中的next函数有可能出现t[j]=t[k],影响匹配效果,所以对于所有的t[j]=t[k],我们约定j的next函数值为对k继续取next值,直至t[j]≠t[k]或者k=0,此时能够保证正文块相对滑动最大距离。
2.2 在SM并行系统中对KMP算法的改进
设长度为n正文串以t1-tn形式存放,处理器数目p(n)=k,则改进的算法如下所示:
1)初始化正文串分解:
将正文等分为k段,则每段长度s=n/k,在每段后面加上长度为m-1的扩展串,将此长度为s+m-1的k段正文按处理器序号依次放入处理器中,处理器i分配的正文子串为texti=t(i-1)·s+1~ti·s+m-1,这里默认正文与匹配串编号均从1开始。
2)对模式串p执行算法1求得next函数值。
3)并行匹配:
For all Pj where 0<j≤k do in parallel
对模式串p与正文子串textj执行算法2,输出结果,算法结束。
其中算法1与算法2如图1,2所示,算法1为next函数匹配过程,算法2为每个处理器的基本KMP算法。考虑到对子串进行分割可能造成的丢解情况,因此在本算法中对边界做出扩展,即需要在匹配串后端加入长度为m-1的扩展串,相当于在任意两段子串texti与texti+1之间有m-1个冗余字符。此时在各子串中以KMP方法进行匹配时能保证其不丢解,现证明如命题1所示。

图1 textr函数算法
命题1.改进的KMP并行算法不丢解。
证明:
i>显然原始的KMP算法不丢解。
ii>假设改进的KMP并行算法存在丢解情况,因为匹配串长度为m,故不妨设从tq开始至tq+m-1结束的字符串为遗漏解,则按照构造子串的方法,令r=q/s+1,则该串头tq应在textr中出现,且q<r ·s,则q+m-1< i ·s+m-1,而textr的结束字符序号为i ·s+m-1,因此该串应全部在textr中出现,即该串必能被在textr中找到,与假设矛盾。
iii>因此,假设不成立,即该算法为完备算法,不丢解。
证毕。

图2 KMP算法
3 算法的计算复杂性研究
3.1 算法在SM分布式系统中的时间复杂性
算法的时间复杂性tp(n)主要包括:分配文本的时间tt(n)与改进的KMP算法的时间tk(n)。
1)分配文本的时间tt(n):如果将字符串复制作为基本操作的话,则显然tt(n)=n/k+m-1=s+m-1,其时间复杂性为O(s+m)。
2)改进的KMP算法的时间tk(n):其中计算模式串的next函数需要时间O(m),由于各分段的长度均为s+m-1,故计算各分段的KMP算法时间实际是tk(n)=O(m)+O(s+m-1)=O(s+2m)。
因此算法在SM分布式系统中的时间复杂性为tp(n)= tt(n)+tk(n)=O(s+2m)。
3.2 算法在DM分布式系统中的时间复杂性
算法的时间复杂性tp(n)同样由分配文本的时间tt(n)与改进的KMP算法的时间tk(n)构成。
1)分配文本的时间tt(n):与算法在SM系统中不同,此时的文本分配时间应在SM的基础上加入初始分配的时间,显然此时间为O(log2k)故tt(n)=O(s+m+log2k)。
2)改进的KMP算法的时间tk(n):与算法在SM系统中相同,为O(s+2m)。
因此算法在DM分布式系统中的时间复杂性为tp(n)= tt(n)+tk(n)=O(s+2m)+O(s+m+log2k)。故log2k≤m,即k≤2m时复杂性 为O(s+2m),当k>2m时复杂性为O(s+m+log2k)。因为k为系统中处理机数目,m为模式串长度,故在常规情况下可认为k≤2m。此时时间复杂性为tp(n)为O(s+3m)。
3.3 算法代价、效率与可扩放性
1)代价
因为算法在SM与DM系统下的计算时间仅有m的差异,故可统一计算代价,代价c(n)=tp(n)·p(n)≈k ·O(s+c·m)=O(n+ckm),(其中c=2,3),所以在ck≤n/m时算法代价为O(n)达到最佳,最佳情况需满足ckm≤n,即正文串足够长时达到最优,显然此为本算法适用范围。
观察最坏情况下串行KMP算法复杂度可知其复杂度为O(m+n),因此当正文串n>>模式串m时其复杂度可看作O(n),此时本算法的执行代价与最坏情况下的串行算法所需时间已经同阶,因此本文中提出的并行算法在满足ckm≤n时为代价最佳的并行算法。
显然可知,通常情况下能够满足此条件。
2)效率与可扩放性
效率主要由算法的加速比和效率得出。
其中加速比Sp(n)=最坏情况下最优串行算法运行时间ts(n)/tp(n),ts(n)即为改进的KMP算法所需时间tKMP(n)=O(m+n),如设通信时间开销为ε(n)忽略不计,则加速比Sp(n)= ts(n)/tp(n)≈O(m+n)/O(n+ckm)。
而效率Ep(n)= Sp(n)/p(n)。当ckm≤n时Ep(n)≈1/k,两者均达到最优。因此本算法的下一阶段工作应着重在降低通信复杂度上。
由算法效率可知,只要满足ckm≤n,则本算法最优,则由可扩放性的概念显然可知,本算法的可扩放性为线性的。
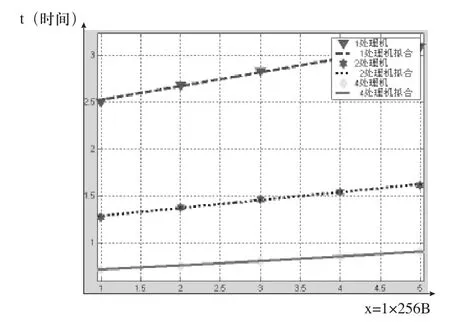
图3 126K正文的拟合
4 实验与结论
下面由图3、4给出拟合的实验结果,图3正文长度为126K,图4为284K,模式串长度分别为256B,512B,1K,2K与4K。处理机数目分别为1,2,4。

图4 248K正文的拟合
由图3、4可以看出,随着处理机数目的增加,本算法在处理时的各项并行指标相对于1处理机而言均接近于最优,且随模式串长度的改变不明显。当处理机增加一倍时,处理时间接近原来的一半,若同时将正文串增加一倍时,则处理时间近似不变。且在实验过程中没有丢解现象发生,由此可以验证上文结论。
本文提出的并行KMP算法是并行字符串运算的基础,也是并行模式识别的基础,在文中提出的并行算法是最优代价算法。在模式匹配领域中一个待解的问题就是无法有效地降低匹配的时间开销,而文中算法在有效降低处理机的排列与通信时间复杂度的前提下可以最大化的降低模式匹配时间开销。
[1]Boyer R S,Moore J S.A fast string searching algorithm [J].Commun ACM,1977,20(10):762-772.
[2]Knuth D.E,Morris J.H,Pratt V.R.Fast Pattern Matching in Strings,SIAM J.Computing,1977,6:323-350.
[3]徐甲同,李学干.并行处理技术[M].西安:西安电子科技大学出版社.1999:1-199.
[4]苏德富,钟诚.计算机算法设计与分析[M].北京:电子工业出版社.2005.7:92-102.
[5]蔡晓妍,戴冠中,杨黎斌.一种快速的单模式匹配算法[J].计算机应用研究.2008,25(1):45-46,81.
[6]张国平,徐汶东.字符串模式匹配算法的改进[J].计算机工程与设计.2007,28(20):4881-4884.
[7]陈国良,林洁,顾乃杰.分布式存储的并行串匹配算法的设计与分析[J].软件学报.2000,11(6):771-778.
[8]郭薇,耿伯英,陈文静.改进的KMP算法在舰船图像匹配中的应用[J].舰船电子工程.2008,28(6):113-116.
[9]戈晓斐,黄竞伟,胡磊.改进的KMP算法在生物序列模式自动识别中的应用[J].计算机工程.2004,30(10):140-142.
