多层次分布式数据挖掘关联规则的研究
2010-08-24曹振强
王 锐,曹振强
WANG Rui1, CAO Zheng-qiang2
(1.郑州广播电视大学,郑州 450003;2.河南省图书馆,郑州 450052)
1 多层次关联规则描述
对于许多应用来讲,由于数据在多维空间中存在多样性,因此要想从基本或低层次概念上发现强关联规则可能是较为困难的,而在过高抽象层次的概念上所挖掘出的强关联规则或许表达了一些普通的常识。但是对一个用户来讲是常识性知识,可能对于另外一个用户就是新奇的知识。因此数据挖掘希望应该能够提供在多个不同层次挖掘相应关联规则知识的能力,并能够较为容易对不同抽象空间的内容进行浏览与选择。
以邮政报刊发行为例:
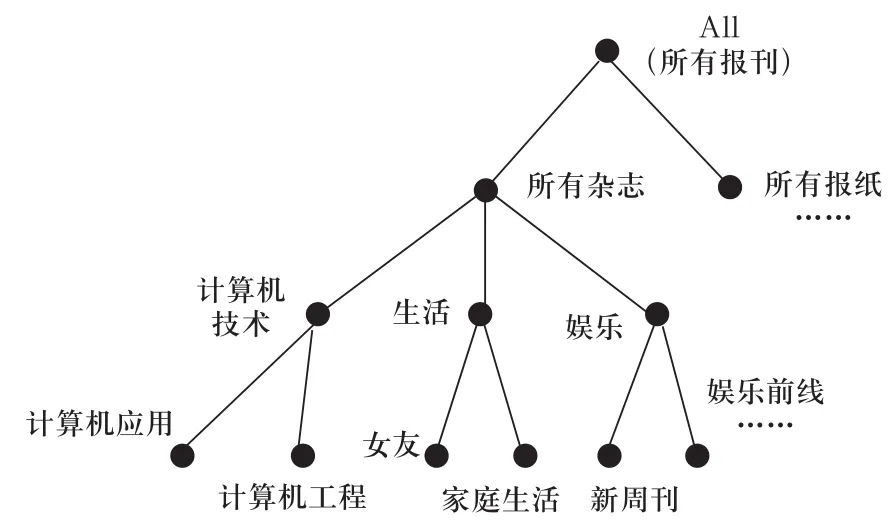
图1 报刊概念层次树
一个典型的报刊目录的层次结构,如图1所示。在这个层次树中描写了邮政报刊的一种分类方法,该层次树描述了从低层次概念到高层次概念的相互关系。在概念层次树中,利用高层次概念替换低层次概念可以是数据的泛化。如概念层次树共分为四层,分别为层次0,1,2,3;层次自顶而下从零开始。树的根节点标记为all。层次1包括:杂志,报纸;层次2包括:技术,生活,娱乐等分类。层次3则包括:计算机应用,计算机工程,女友,家庭生活,新周刊,娱乐前线等杂志报纸。概念层次结构可以由熟悉报刊数据组织结构的用户在报刊目录表中定义。[1]
2 挖掘多层次关联规则的方法
首先就给予支持度和信任度的挖掘方法作进一步讨论。一般而言,利用自上而下的策略从最高层次向低层次方向进行挖掘时,对频繁项集出现次数进行累积以便发现每一个层次的频繁项集指导无法获得新频繁项集为止。也就是在获得所有层次概念1的频繁项集后,再挖掘层次2的频繁项集,如此下去。对于每一个概念层次(挖掘),可以利用任何发现频繁项集的算法,如:Apriori或者FP-tree,FP-growth算法。
多层次挖掘关联规则算法的阙值取值分析:
1)对所有层次均使用统一的最小支持阙值,即对(所有)不同层次频繁项集的挖掘均使用相同的最小支持阙值,例如图2所示整个挖掘均使用最小支持阙值5%(从“技术”到“计算机应用”);“计算机工程”不是频繁的,但是“计算机技术”和“计算机应用”却是频繁的。
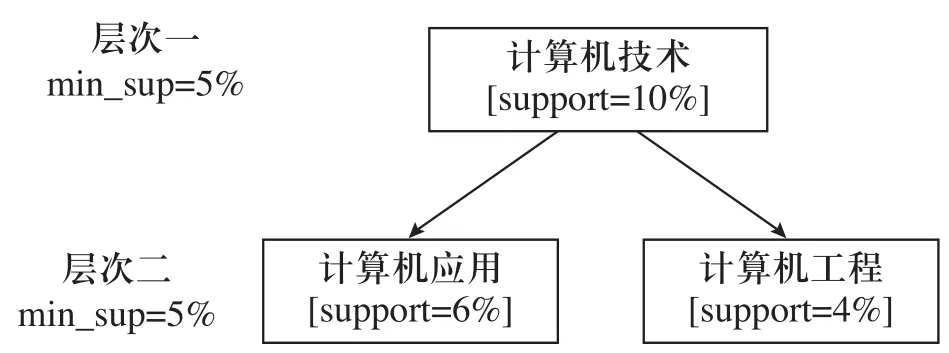
图2 利用统一最小支持阙值的多层次挖掘
利用统一最小支持阙值,可以简化搜索过程。由于用户只需要设置一个最小支持阙值,因此整个挖掘方法变得比较简单。基于一个祖先节点是其子节点的超集,可以采用一个优化技术,即可避免搜索其祖先节点包含不满足最小支持阙值的项集。
但是利用统一的最小支持阙值也存在一些问题。由于低层次项不可能比相应高层次项出现的次数更多。如果最小支持阙值设置过高,那就可能忽略了一些低层次中有意义的关联关系。若阙值设置过小,则可能产生过多的高层次无意义的关联关系。因此产生了第二种算法。
2)在低层次里用减少的阙值(又称为递减支持阙值)。所谓递减支持阙值,每一个抽象层次均有相应的最小支持阙值。抽象层次越低,相应的最小支持阙值就越小。例如图3
所示,层次1和层次2的支持度分别为5%和3%这样:“计算机工程”、“计算机技术”和“计算机应用”都是频繁的。[2]
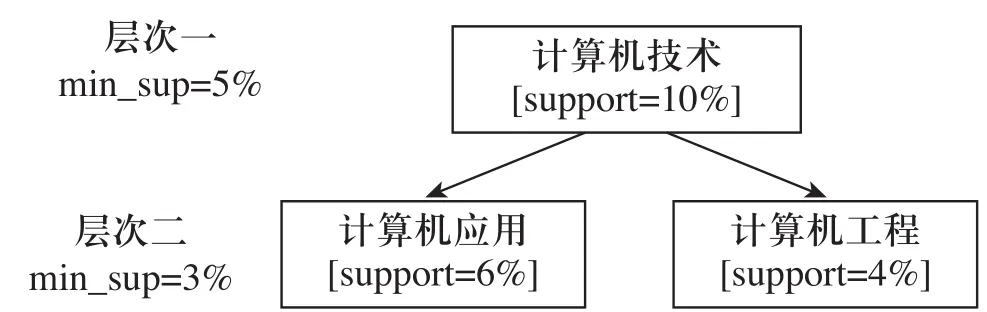
图3 利用递减阙值的多层次挖掘
利用递减阐值挖掘多层次关联知识,可以选择若干搜索策略:
1)层与层独立。这是一个完全宽度搜索。没有利用任何频繁项集的有关知识来帮助进行项集的修剪。无论该节点的父节点是否为频繁的,均要对每一个节点进行检查。
2)利用单项进行跨层次过滤。当且仅当相应父节点在(i-1)层次是频繁的,方才检查在i层次的单项。也就是说,根据一个更普遍的来确定检查一个更具体的。
3)利用k-项集进行跨层次过滤。当且仅当相应的父k-项集(i-1)层次是频繁的。方才检查在i层次的k-项集。
层与层独立策略由于它过于宽松而导致其会要检查无数低层次概念的频繁项,并会发现许多没有太大意义的关联知识。例如:如果“生活类”杂志很少被订阅,那么在去讨论其子节点“家庭生活”和“女友”杂志之间是否存在关联就没有任何意义。但是如果“计算机技术”经常被订阅,那么检查其子节点“计算机应用”与“计算机工程”之间是否存在关联就很有必要。[3]
利用k-项集进行跨层次过滤策略,容许挖掘系统仅仅检查频繁k-项集的子节点。由于通常并没有许多k-项集(特别是当k>2时)在进行合并后仍是频繁项集,但是利用这种策略可能会过滤掉一些有价值的模式。
利用单项进行跨层次过滤策略,就是上述两个极端的综合。但是这种方法或许会遗漏掉有关低层次项之间的关联只是。这些项在使用递减支持阙值时是频繁项集;即使它们的祖先结点不是频繁的。例如:若根据相应测光那次的最小支持阙值,在概念层次i中的“新周刊”是频繁的,但是根据i-1层次的最小支持阙值,它的父结点“娱乐”却不是频繁的。这样会遗漏掉诸如“家庭生活→新周刊”这样的频繁关联队则。
利用单项进行跨层次过滤策略的一个改进版本,称为受控利用单项进行跨层次过滤策略。它的具体做法是:设置一个阙值称为“层次通过阙值”(level passage threshold ),它将容许相对频繁的项“传送”到较低层次。换句话说,这种方法容许对那些不满足最小支持阙值项的后代进行检查,只要它们满足“层次通过阙值”。每一个概念层次均有自己相应的“层次通过阙值”。给定一个层次,它的“层次通过阙值”取值,通常在本层次最小支持阙值和下一层最小支持阙值之间值。用户或许会在高概念层次降低“层次通过阙值”以使相对频繁的后代能够得到检查;而在低概念层次降低“层次通过阙值”,也将会使所有项的后代均能得到检查。在图4中,设置层次1的“层次通过阙值”为8%,将使层次2结点“计算机应用”和“计算机工程”得到检查,并发现是频繁的;即使它们的父结点“计算机技术”是非频繁的。建立这一方法,将使得用户能够更加灵活的控制在多概念层次上的数据挖掘以减少无效关联规则的搜索与产生。
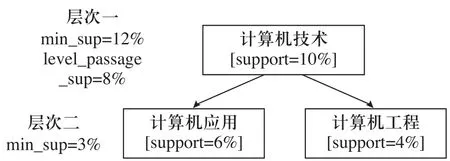
图4 利用受控单项跨层次过滤多层次挖掘
到现在为止,我们讨论的频繁项集挖掘所涉及的项集,都是一个项集中的所有项均属于同一个概念层次,从而发现诸如“计算机技术幼生活”(计算机技术和生活都属于层次2)得关联规则。若要发现跨概念层次的关联规则,如:“计算机技术→家庭生活”(其中两个项分属于层次2和层次3),这样规则也称为跨层次关联规则(cross-level association rules )。
如果要挖掘层次i和层次j(i<j)之间的层次关联规则,那么就应该整个使用层次j的递减支持阙值,所以使得层次j中的项能够被分析挖掘出来。
3 基于概念层次树的多层次关联规则算法
基本思路:
输入:交易数据库TDB,概念层次树tree,最小支持度Smin和最小可信度Cmin。
输出:符合最小支持度Smin和最小可信度Cmin的多层次关联规则。
步骤:
1)对概念层次树的每个节点进行编码;
2)ptree:= tree;/*ptree中存放上一次挖掘中能组成频繁规则的节点,即组成选验估计的节点/
3)do;
4)抽样(按TID ),另存为DB';
5)在概念层次树ptree’中计算频繁项集;
6)根据频繁项集,测试ptree中的节点是否能组成频繁规则,能组成的加入ptree';
7)对ptree叶子节点x,如出现在ptree'中,扩展x的子节点x1,x2,…,xn,测试x1,x2,…,xn能否组成频繁规则。如xi可以,加入ptree',并扩展xi,循环向下;
8)ptree’中的节点及根节点组成新的ptree;
9)while DB'<DB;
10)对ptree'中的节点,计算后选规则集c_rules;
11)检查c_rules中的规则的支持度和可信度,删除支持度和可信度小于给定值的规则,得规则集rules;
12)净化规则集rules;删除冗余规则,删除误导规则和无效规则;
13)输出 rules;
4 基于语义划分的多层次关联规则冗余处理
关联规则挖掘会产生大量的规则,有时候甚至多达数十万条,要想从如此巨大的规则集合中结合语义信息搜索冗余规则无疑需要很大的运算量,为能更快速准确地对规则进行冗余处理,文中提出前缀树扫描方法来减少冗余处理过程的运算复杂度,提高处理结果的准确度。
方法主要分为3 部分:1)按照规则前项对规则进行预处理,用规则前项中的项为节点构建前缀树。这步完成后,把所有规则都压缩到规则前缀树集合中。2)结合语义本体遍历每棵前缀树,从前缀树根节点到的其它节点的所有路径都有可能是一条规则的前项,从根节点开始遍历前缀树的每个节点同时查找本体,找出这个节点的关联节点,组成项目列表,如果该项目列表能构成规则前项,则把它加入冗余规则候选集合中。这步完成后每条规则都被加入相应的冗余规则候选集合,3)扫描每个冗余规则候选集合,进行相应的冗余处理。
4.1 构建前缀树
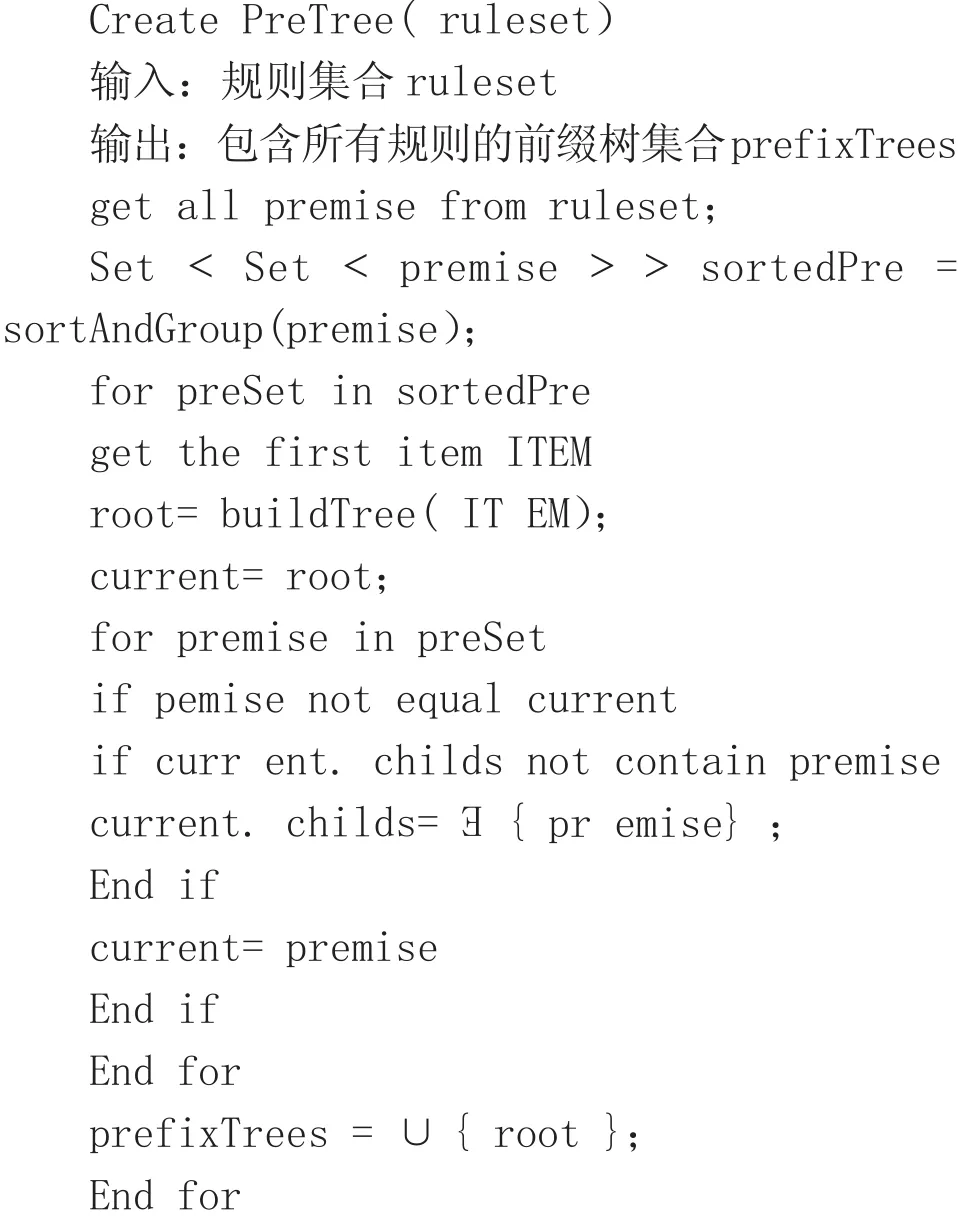
使用规则前项中的项为节点构造规则前缀树。首先,对每条规则的前项进行排序预处理,把第一个项目相同的规则放在一个集合中;对于每个集合,用集合中每条规则前项都含有的相同第一个项目作为前缀树的根节点,依次扫描集合中的每条规则前项,构造前缀树, 使得前缀树从根节点到树中其它节点的路径都对应着规则前项。这步需要遍历规则集合中所有的规则,完成后所有的规则都被包含在前缀树集合中。
4.2 结合语义本体遍历前缀树
scanPrefixTree( pfnode,ontology ,r elType,weig ht,premises)
输入:前缀树节点pfnode,本体ontology,关联类型relType,weight关联权值,premises 存储的前缀树从根节点到其他节点的路径集合,表示已经发现的所有规则前项输出:冗余规则候选集合candreds

结合语义本体遍历规则前缀树,这步是冗余处理的核心。输入前缀树根节点root,本体ontology,关联类型relType,关联权值weight,采用深度优先方式遍历。从前缀树根节点开始,记录从根节点到其它节点路径上的所有节点,如果这些节点能够成一条规则前项,则建立冗余候选集合。同时遍历本体,返回与当前节点有指定关联类型relType且权值大于weight 的关联节点,如果关联节点能够与当前节点对应的路径上除当前节点的所有节点构成规则前项,则把这条规则加入到相应的冗余候选集合,递归地遍历当前节点的每个子节点。这个过程总的时间代价大约为O(n2)。如此,遍历完前缀树后,所有的规则都被加入到相应的冗余候选集合中。
4.3 对冗余规则候选集合进行冗余处理

对每个冗余候选集合进行处理。冗余候选集合中每条规则的前项都是具有前面定义的某一类关系的项集,这时只需要考察候选中每条规则的后项。如果某两个候选的后项也符合这类关系,那么这条规则被认为是这类型的冗余规则,进行相应的处理。
最后用某手机订阅服务数据集作为实验数据进行试验。实验表明,使用本文提出的冗余处理方法能有效消除多层关联规则冗余,使得挖掘出的规则更加符合实际情况,在实际应用更加具有指导意义;同时通过处理冗余和不处理冗余挖掘时间耗费的对比,表明文中提出的方法在时间耗费上也是可以接受的。
5 结论
数据仓库和数据挖掘技术是当今信息技术领域研究和应用的热点技术。本文从数据挖掘的概念和特点入手,以邮政报刊发行数据库为例,讨论了数据挖掘技术的有关概念、挖掘的过程和方法,并详细论述了关联规则挖掘算法的思想和实现。
[1] 张维明,等.数据仓库原理与应用[M].北京:电子工业出版社,2002.
[2] 彭木根.数据仓库技术与实现[M].北京:电子工业出版社,2002.
[3] Claude Seidman.SQL Server2000数据挖掘技术指南.北京:机械工业出版社,2002.
