共享内存系统中高效并行FDTD计算方案
2010-04-26赖生建王秉中黄廷祝
赖生建,王秉中,黄廷祝
(1. 电子科技大学物理电子学院 成都 610054; 2. 电子科技大学应用数学学院 成都 610054)
目前,基于多核多处理器(CPU)和大容量内存的计算机已成为进行工程计算仿真的主流配置,许多商业电磁仿真软件都提供了支持在多核系统上的并行计算功能。在计算电大的电磁问题时,计算效率比单处理器系统有显著的提高。
在电磁仿真的各种数值算法中,时域有限差分(FDTD)法[1]由于Yee元胞上的场只与相邻元胞上的场有关系,因此具有天然的并行性,FDTD是最具并行计算效率的电磁场数值方法。传统的FDTD并行算法首先对计算区域进行并行区域划分,然后在各区域上单独进行FDTD计算,通过同步并交换并行边界面上的场量实现并行FDTD计算。并行边界数据交换技术一般有3种[2]:(1) 各并行边界面上的场量只计算一次的方式,再交换相邻区域的切向电场和切向磁场,但该方式要通过两次数据交换操作,并行效率低。(2) 采用只中断一次的方式,只交换一次相邻区域切向磁场数据,并行计算效率高,但交界面上的场分量要计算两次。(3) 各并行区域的交界面上重叠一个网格的方式,虽多消耗了一层网格占用的资源,但便于处理交界面的材料、共性网格等信息,该处理方式更具有通用性。
电磁场并行数值计算的编程实现通常采用消息传递方式(MPI)库进行开发[3-4],也有基于共享内存方式的OpenMP库开发[5]。并行FDTD计算也采用这些开发技术,通过MPI创建的每个并行区域计算任务(进程)[6-7],在计算进程中分配各区域的FDTD计算资源,进行当前区域的FDTD步进计算。通过MPI库的传送和接收函数实现并行边界上数据交换,再调用MPI的等待函数同步所有并行区域的计算任务,协调FDTD的并行计算。
传统并行FDTD计算通过并行边界上的数据交换方式实现,如果取消数据交换的过程,节省该过程的处理时间,可能会进一步提高并行FDTD的计算效率。基于这种思想,本文提出一种在共享内存系统中进行高效并行FDTD计算的方案,对方案所涉及的算法思路、并行区域划分方式及编程实现技术进行分析和讨论,最后进行数值仿真测试。
1 基于共享内存系统的并行FDTD计算方案
共享内存系统的应用程序开发有多进程和多线程两种方式。多进程程序中的各进程管理各自的计算资源,进程间的数据共享通过消息方式数据传递实现[8];而多线程程序中的各线程可以分享主进程程序分配的所有计算资源,直接共享程序中的数据,如图1所示。利用多线程程序开发的该特点,并行FDTD计算可以选择直接读取内存数据的方式实现并行计算。
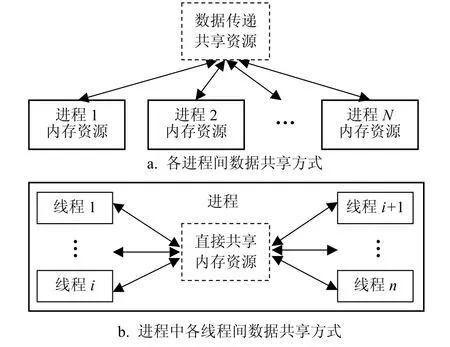
图1 应用程序共享数据资源示意图
为实现共享内存系统下的并行FDTD计算,本文提出多线程下的并行FDTD计算思路:首先根据仿真实例统一分配和计算FDTD仿真所需的资源,即统一剖分Yee元胞、激励源、材料、后处理和边界条件等一系列FDTD仿真前处理所涉及的各物理量的分配和计算,完成FDTD循环步进计算前的准备;然后根据FDTD并行计算设置,对仿真区域进行区域划分;再采用多线程技术分配和管理各区域的FDTD计算;最后通过直接读取各区域间的并行边界上场量数据,实现整个仿真区域的FDTD并行计算。该实现思路针对整个FDTD计算资源离散化,对各区域资源进行并行计算控制。对任意复杂模型都可以采用相同的处理过程,因此它具有很强的实践性和通用性。
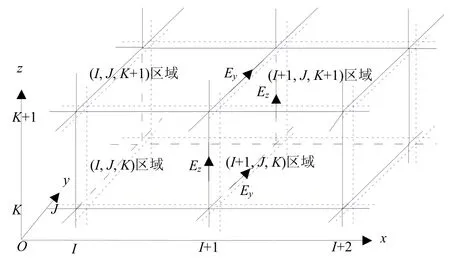
图2 基于共享内存系统的FDTD并行计算区域划分示意图
基于本文提出的并行FDTD计算思路,进行区域划分,其划分方式与传统并行FDTD计算一样,并行区域边界面与Yee电场网格重合,如图2所示。为了自然地共享并行边界上的场量,本文提出一种巧妙而又简洁的对并行边界上场量的分配策略:区域中坐标轴正方向上的并行边界,包含在该区域进行FDTD计算;坐标轴负方向上的并行边界,就排除该区域范围,并入紧邻区域进行FDTD计算。该种排列方式可以避免在并行边界上计算两次场量的情况发生,也不会有因两个区域共用并行边界造成的数据交换操作。图2中,虚线包含的区域为并行区域的FDTD计算范围,如图中所标识的(I,J,K)并行区域,在x轴负方向上的并行边界(左边界)上,场量在该区域不计算,而是由(I−1,J,K)区域的FDTD计算;右并行边界面上场量由本区域的FDTD计算,其他方向类推。
并行计算的编程实现大都采用MPI库,该库是一个功能齐全、可移植性强的并行计算控制库[9]。然而所提出的并行FDTD计算策略,因其并行计算的资源控制比较简洁,只需要同步计算控制等少数操作,并不需要很复杂控制的庞大MPI函数库。另外,采用MPI库编写的程序要受MPI程序控制,并行计算的开发和调试不方便。另一个广泛使用的并行控制库OpenMP也有相似的特点。因此,利用多线程开发技术共享内存资源的特点,本文采用自主开发多线程编程技术[10]实现并行FDTD计算,即各并行区域的FDTD计算由各计算线程控制并协调并行FDTD计算。并行边界上的场量数据采用直接读取共享内存中数据的方式,实现“数据交换”。
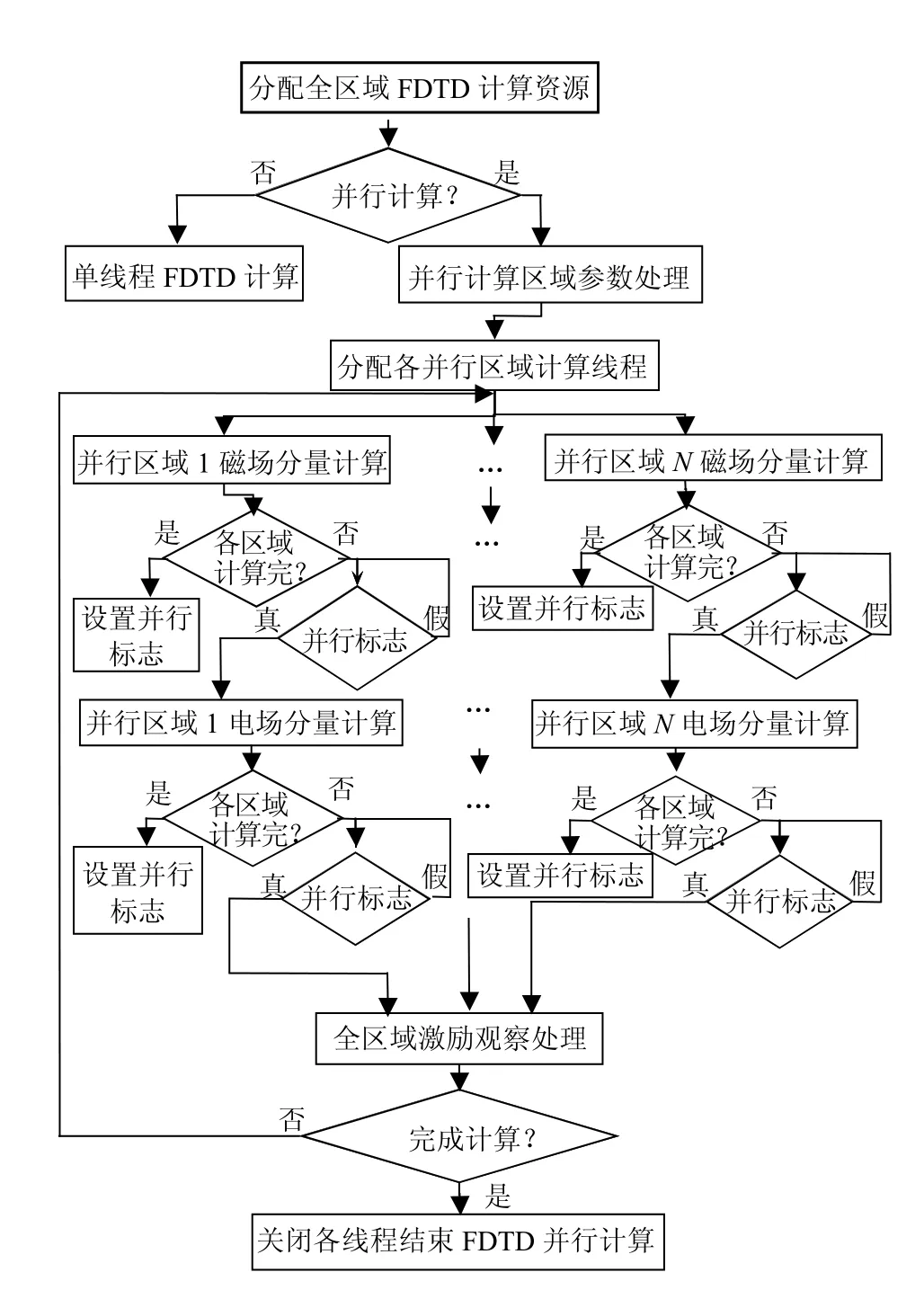
图3 共享内存方式的并行FDTD计算流程图
基于共享内存方式并行FDTD计算的流程图如图3所示。首先分配FDTD在整个仿真区域上的计算资源,在内存中这些计算资源按整个仿真区域分配FDTD仿真所需的三维数组变量。若采用并行计算,在并行方向上以均衡方式自动划分各并行区域网格数目和计算并行FDTD计算的全局参数。然后创建各区域的FDTD计算线程;启动各计算线程进入各区域的FDTD计算;各区域计算完磁场后,判断其他区域是否完成磁场计算,若没有,则当前计算线程进入判断全局并行标志的空循环中,等到为真时退出;若其他线程都完成了磁场计算,则设置全局并行标志为真,各计算线程退出循环,进入电场及边界计算。各计算线程完成电场及边界计算后,各计算线程等待一次,其处理方式与前面磁场计算相同。计算完电场后,全域FDTD仿真中的场源激励计算和观测数据保存等处理部分单独计算,由最后计算完电场的计算线程来完成,然后判断FDTD仿真是否完成,若没有完成,所有计算线程进入下一步进的计算。
因采用并行边界上只计算一次场量的区域划分策略,并行边界相邻一个网格上场量的计算都需要相邻区域的场量,各并行区域FDTD的电场和磁场单独计算后,要求等待其他并行区域的FDTD计算完成后,才能继续计算,即每次FDTD步进计算需等待两次。
与传统并行FDTD计算相比,本文提出基于共享内存方式的并行FDTD计算方案没有数据交换过程,采用没有计算线程的挂起和恢复等并行控制操作,减少了影响并行计算的因素,提高了并行FDTD计算效率。下面通过数值仿真实验,测试所提出的基于共享内存系统并行FDTD计算方案的计算效率,并与传统并行计算方式进行比较。
2 并行FDTD计算方案测试
加速比是衡量并行系统计算性能的参数,定义多核计算机系统中并行FDTD计算的加速比为:

式中tseq为用单线程计算全区域FDTD所需的时间;tp为用p个线程控制p个并行区域的FDTD计算相同问题所需的时间,p个并行区域构成整个FDTD仿真区域。
采用双Xeon E5310 CPU服务器测试并行FDTD计算方案的计算性能。E5310 CPU是主频为1.6 GHz、266 MHz的前端总线、系统总线为1 066 MHz、二级缓存为4MB×2的4核处理器,共有8个计算内核。测试的计算实例是大小为100×100×100标准Yee元胞测试盒,总仿真步长设为1 000步。
在不同方向上采用不同并行区域划分方式,所提出的并行方案与传统数据交换方式并行方案的加速比对比表如表1所示。表中,NX、NY、NZ分别表示仿真区域在x、y、z坐标方向上的并行区域数目。从表中可看出,前8行是单独在x方向划分并行区域方式,基于共享内存方式加速比比传统数据交换方式高,并且随着并行区域的划分越多,加速比越高。主要原因是传统数据交换方式的并行FDTD仿真中,每次步进计算都要交换一次并行边界数据,并行区域越多,要交换数据量也越大,而不交换数据的共享内存并行FDTD计算没有这部分过程,提高了并行计算效率。即使不交换数据的共享内存方式有两次线程等待过程,多等待一次的时间比通过数据交换时间要少得多。
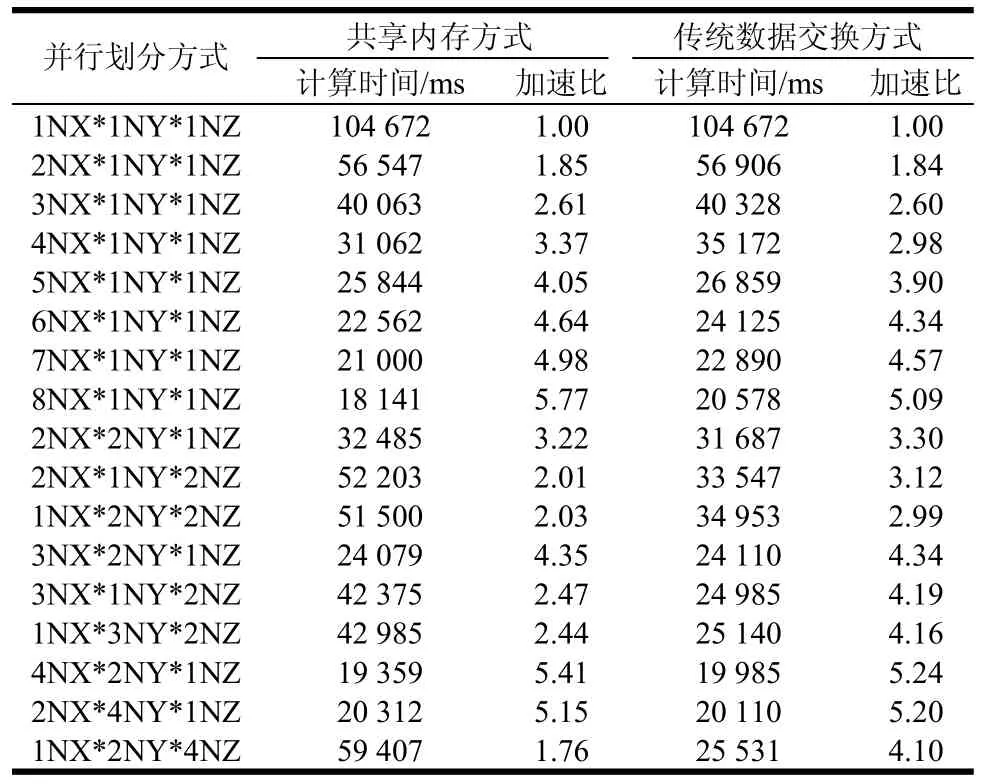
表1 Xeon E5310服务器上并行FDTD计算性能

从表中还可看出,在两个计算线程下,基于不交换数据的共享内存方式的并行FDTD计算,其加速比达1.85,而文献[11]采用MPI编程技术,对同样的问题进行计算,双核时的加速比只能达到1.3左右。本文采用传统的数据交换方式,其加速比也达到1.84,说明采用不同的并行计算策略对并行效率有很大的影响。另外,本文又在双核Intel E6550个人计算机上对以上相同的问题进行测试,所提出的方案其加速比也达1.90。虽然基于共享内存系统的并行FDTD计算因争抢计算机的系统总线、内存等资源,降低了加速效率,但本文的方案充分挖掘了并行FDTD的计算潜力和利用了多核计算系统的计算能力,具有很高的加速比。
3 结 论
在科学计算中,如何充分利用计算资源提高计算效率是高性能数值计算中的研究内容。本文提出一种不交换并行边界数据的并行FDTD计算方案,并采用自主开发的多线程编程技术控制各区域并行FDTD计算。通过数值仿真测试表明,只在x方向并行区域划分方式下,不交换数据的并行计算方案比传统数据交换方案有更高的加速比,是一种理想的共享内存系统的并行FDTD计算方式。
[1] YEE K S. Numerical solution of initial boundary value problems involving Maxwell’s equations in isotropic media[J]. IEEE Transaction Antennas and Propagation, 1966,14(1): 302-307.
[2] YU W H, SU T, MITTRA R, et al. Parallel finite difference time domain method[M]. London: Artech House, 2006.
[3] YU W H, MITTRA R, SU T, et al. A robust parallelized conformal finite difference time domain field solver package using the MPI library[J]. IEEE Transaction Antennas and Propagation, 2005, 47(3): 39-59.
[4] GUIFFAUT C, MAHDJOUBI K. A parallel FDTD algorithm using the MPI library[J]. IEEE Transaction Antennas and Propagation, 2001, 43(2): 94-103.
[5] BUCHAU A, HAFLA S M W, RUCKER W M.Parallelization of a fast multipole boundary element method with cluster OpenMP[J]. IEEE Transaction Magnetics, 2008,44(6): 1338-1341.
[6] 张 玉, 李 斌, 梁昌洪. PC集群系统中MPI并行FDTD性能研究[J]. 电子学报, 2005, 33(9): 1694-1697.ZHANG Yu, LI Bin, LIANG Chang-hong. Study on performance of MPI based parallel FDTD on PC clusters[J].Acta Electonic Sinica, 2005, 33(9):1694-1697.
[7] 梁 丹, 冯 菊, 陈 星. 高效率FDTD网络并行计算研究[J]. 四川大学学报(自然科学版), 2006, 43(3): 549-555.LIANG Dan, FENG Ju, CHEN Xing. A study of efficient parallel FDTD methods on cluster systems[J]. Journal of Sichuan University (Natural Science Edition), 2006, 43(3):549-555.
[8] 何元清, 孙世新, 傅 彦. 并行编程模式及分析[J]. 电子科技大学学报, 2002, 31(2): 173-175.HE Yuan-qing, SUN Shi-xin, FU Yan. Parallel programming mode and analysis[J]. Journal of University of Electronic Science and Technology of China, 2002, 31(2):173-175.
[9] GROPP W, EWING L, ANTHONY S. Using MPI: portable parallel programming with the message-passing interface[M]. 2th Ed. Cambridge: MIT Press, 1999: 10-35.
[10] DAVID J K, SCOT W, GEORGE S. Programming microsoft visual C++[M]. 5th ed. USA: Microsoft Press,1999.
[11] CIAMULSKI T, HJELM M, SYPNIEWSKI M. Parallel FDTD calculation efficiency on computers with shared memory architecture[C]//CEM-TD 2007 Workshop. Italy:Perugia, 2007.
