一种生长法快速构造三角网的算法研究
2010-04-18王会然
王会然
(河北省地矿局测绘院,河北廊坊 065000)
一种生长法快速构造三角网的算法研究
王会然∗
(河北省地矿局测绘院,河北廊坊 065000)
针对DEM制作过程中大数据量构建三角网效率问题,提出了一种多级索引支持的三角网生长算法,该算法逻辑结构简单,编程实现容易,可以验正该算法比通用软件提供的相应未优化算法速度提高很多。
不规则三角网;Delaunay三角网;索引
1 引 言
数字高程模型(DEM),是一种描述地形起伏的数学模型。其可分为规则格网、不规则三角网和等高线几种类型。规则格网具有结构简单、直观的特点,但在对复杂地形特征表达和分析方面,不规则三角网与其他两种方法相比,具有较高的精度和效率,目前Delaunay三角网是公认的最优三角网。通过离散高程点和特征线、等高线构造生成三角网,已有许多专家进行了算法研究和改进,其方法类型主要有3类;
①分而治之法(由Shamos和Hoey提出),即对大量点分块构网,再合并成一个整体。构网时采用局部优化(Lop)算法保证其成为Delaunay三角网。其运算中大量使用递归,故实现起来有困难。
②数据点渐次插入算法(由Lawson提出),其方法是先找到最外层点作多边形将所有点包括进去形成一个凸壳。在此基础上构网,将内部点逐一加入,并采用Lop算法保证其成为Delaunay三角网,此算法简单,但效率不高。
③三角网生长算法,该方法算法简便,如果不加优化,则效率亦不高。本文就针对生长算法,提出了一种优化算法——区域索引加正方形搜索区域的方法。使生长法具有很高的效率。
2 关于Delaunay三角网
Delaunay三角网为相互邻接不重叠的三角形的集合。每一个三角形的外接圆内不包含其他点。Delaunay三角形有3个相邻点连接而成,这3个相邻顶点对应的Voronoi多边形有一个公共的顶点,此顶点也是Delaunay三角形外接圆的圆心。Delaunay法则就是在构造三角网时,确保每个三角形内角是锐角或者三边近似相等,避免钝角和过小锐角出现。
3 三角网的构建算法
三角网生长算法,就是首先在已知离散点中任选一点做起始点,找到其最近点,以两点连线作为起始基线,在基线右侧,应用Delaunay法则搜索第三点,生成Delaunay三角形(每条基线方向如图1,AB为起始基线),再以三角形新的两条边作为新基线(AC和CB),重复该过程,直到所有基线处理完毕。
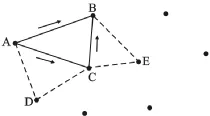
图1 三基形生长示意图
4 算法优化及实现
4.1 构网方法优化
(1)索引的建立:对采集的高程点(或等高线点)进行预处理。将数据读入后,按坐标计算范围,并统计点数,提出对话框询问是否建立点的分区索引以及要建立索引的分区行数和列数,根据点密度情况人工输入合理值。这里所说的对点进行分区,就是对所有点按坐标最小和最大所限定的范围在水平和垂直两方向等分,把这个范围均分成若干行若干列,见图2。对一个点,根据点的两坐标值与分区边缘比较一下,落在哪个区就统计在哪个区内,每个区有多少个点记录在一个由区号标识的数组变量中,每个区中的点,也记录在一个由区号标识的数组变量中。该数组变量除了包括点号和坐标外,还包括一个属性值表示该点是否参与过一次构网,初始值为0,表示未构网。因为分区数和区内点数是在运行中得到的,故这些变量都用到动态数组。

图2 对离散点进行索引示意图
(2)搜索正方形的使用:对要搜索的点,如果在一个正方形范围内进行搜索,搜到后再做点与基线关系的有关计算,则会使计算量进一步减少。以合适点为中心做一正方形,通过对正方形4顶点计算落在哪几个分区中这一简单比较运算,得到该正方形所用到的分区,在分区中将落在正方形中的点找到,再进行点与基线关系的运算,找出最佳点。开始构网时,是在所有点中先任选一个点(当然也可以选最左上一个点),在所有点中找到离它最近的点,此两点为起始边(起始生长基线,之后的生长基线统称基线),起始点可不在整个区域边缘,如取点时取文件的第一个点,该点就可能在中间某一位置,如图3,A为起始点,B为与A的最近点,线段AB为起始生长基线,图中搜索正方形中心点选基线的中点,边长选已分区水平方向边长的1/4,当正方形中无点或无合适点(如在AB所在直线左侧有点,右侧没发现点,或有点但它们已经构网且够两次即该点已完成了构网,当前基线不再构网,要进行基线转移,要到其他未完成的三角形上去找新基线)时,对正方形按一定数量增大边长(但不能增大超过三角网预设最大边长一定量级,如两倍,如果超过,基线右侧点有可能与基线距离会超过最大边长允许值,这个最大搜索正方形边长也是在开始根据三角网允许最大边长大小给定的),直到找到合适点或右侧无点(见图4和图5)。图4中,虚线正方形表示许可的最大搜索正方形。在图3中,如当不是开始构网而是在构网中间时段,则AB基线表示当前生长基线。图3为正方形落在一个分区内的情景,当然还可以落在几个分区内,即跨几个分区,见图6。

图3 搜索正方形构建示意图

图4 当前生长基线AB右侧无点的情况
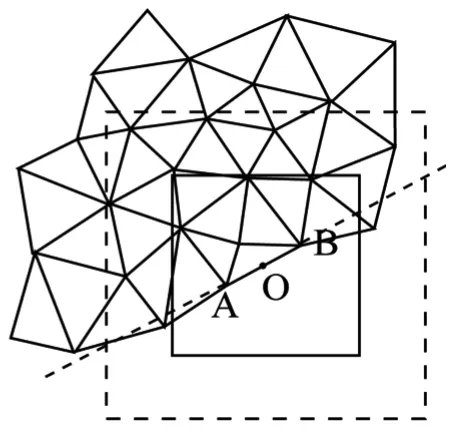
图5 当前生长基线AB右侧有点 但再没有未曾构网点的情况

图6 搜索正方形跨几个索引区的情形
4.2 算法实现
当无优化时,构造三角网如图7,当前基线为AB,为了找到符合条件的C点,需要对所选点与基线位置关系进行判断,将最好的点如C作为下一个构网点,这就要将可能构网的所有点都要进行这种判断计算,如图6中的D、E、F、G、H、I……等等,即每构一个新三角形,就要对可能点进行遍历搜索。当构网点数很大时,构网速度和效率就会很低。本方法所论述就是为改善这种情况的优化方法。首先进行分区:对读入数据变量应包括:点号(按读入顺序)、x、y、z三坐标、区编号q(初始值为0),假如x、y坐标最小值和最大值分别为xmin和xmax,ymin和ymax,如果分成m行n列,则共有m×n分区,记△x=(xmax-xmin)/n,△y=(ymax-ymin)/m,当读入数据后再给出行列数,这些值就可以算出。接着就是对所有点按分区归档,进行第一次遍历数据,对一个点(x,y),当xmin+(kh-1)×△x≤x<xmin+kh×△x则点所在区落在第kh列(1≤kh≤n的整数),同理,当ymin+(kl-1)×△y≤y<ymin+kl×△y则点所在区落在第kl行(1≤kl≤m的整数)。当kh和kl求得后,分区号q=kh×n+kl,将q值赋与该点区编号。用一个数组变量记录每个区的点数累加值。接着进行第二次遍历数据,根据所得每个区的点数累加值d(q),取d(q)最大者,创建分区点信息数组p[q,d(q),5],第三维中包括点号dh、三坐标x、y、z、是否曾构网判断值gw。如果为了节省内存,可将第三维数组分开表示为:pdh[q,d(q),1]、px[q,d(q),1]、py[q,d(q),1]、pz[q,d (q),1]、pgw[q,d(q),1],这样就可以用整型变量表示点号和用短整型表示点已构网次数。

图7 构造三角网无优化时情况示意图
下面是搜索正方形建立及搜索构网点的具体过程:构网的第一个点从坐标最外围为原则如左上、左下等,这样构网是从边缘开时的。如果第一个点按文件数据顺序,则第一个点可能出现在区域内任一位置,这样构网可能在区域内开始,两种情况没实质差别。第一个点确定后,先判断它在哪个索引区,然后在该区和所有相邻区内(有时该点可能与相邻区内某点最近)查找最近点,两点连线作为第一条生长基线。以基线中心点坐标为中心,构造搜索正方形,正方形起始边长,可取分区的宽的四分之一。构造正方形时,以基线中点坐标,由边推算出对应四角点坐标,然后对正方形四顶点坐标值与各分区边纵横坐标进行比较,确定该正方形所在的分区(一个或几个)。在这些分区内,将所有区内点与正方形边范围比较,找出所有在正方形内的点。当无点时,把正方形按起始边长的一半扩大正方形,直到找到点。找到点后,计算所有在正方形内点与基线关系,选出离基线最近的点,直到右侧无点。对找到的点,计算该点与基线关系,应满足以下两种要求:①该点要在基线的右侧。方法是按下面函数计算: F(x,y)=y+Ax+B。式中A=(y2-y1)/(x1-x2);B=(x1×y2-x2×y1)/(x2-x1)。 x1,x2,y1,y2分别为基线两端点坐标。当F(x,y)〉0时,该点在基线左侧,相反在右侧。F(x,y)=0表示该点在基线上。②读取该点是否已构网状态,判断该点是否参与构网,未曾构网时直接进行下一步。当已构网时在已构网边中判断是否与该基线两点中任意点达到两次,达到两次时,该点不再使用。③该点为顶点的角要取最大的。根据余弦定理c2=a2+b2-2abcosC可得cosC=(a2+b2-c2)/2ab,取cosC最小的,此时C值最大,cosC<0时说明C角是钝角,这里不排除钝角这一情况,当点位不均匀或等高线平行性发生突变时,会出现这种情况。对合适的点,构建好三角形后,以新边为基线,重复以上过程,直到把所有边都进行了搜点构网。
5 结 论
该算法运算公式简单,可容易地用VC++和VB编写程序实现,由于建立格网索引只需两次遍历所有点,在对搜索正方形时,也只用一些简单坐标比较就可以在一个或几个分区内找到在搜索正方形内的所有点,这样就避免了在大量的点中判断符合与基线构造三角形的条件计算问题。当点数很大时,设有一万个点甚至几十万个,如果不优化,每构一个三角形都要对所有点进行是否在基线右侧、点是否已构网两次、到基线距离是否最小这些判断,其中第1和第3两项有公式运算,构网效率就很低。当用该方法优化时,先生成搜索正方形,再定位其4个角点所在索引格,然后在所有索引格中找正方形内点,最后在正方形内点进行上述判断。所处理点数与正方形内点数有关,所以当正方形不用扩大时,其边长为一个索引格宽1/4,如果我们共有M×N索引格,且我们索引时在水平和垂直两个方向上索引格边长大致相当,且我们同时设定高程点分布是比较均匀的(不均匀也没关系,点的稀密也使落在正方形内的点同样多或少,不影响最终全部处理的时间,这里假设这种情况,是为了好理解),那么,每个正方形占全部点分布面积的比例为:1/(M×N×16),也就是说,对点进行计算时所用点数为原来的1/(M×N×16),由此可知,速度可以提高到(M×N×16)倍,值得一提的是,没有计算生成搜索正方形、判断正方形所在索引格、在索引格中找正方形中的点这些时间,实际上,我们处理的是当数据量很大时的情况,当数据量不大时,什么算法都不会有明显优势(计算机很快)。数据很大时每个索引格不会太小(至少几百个点),对于生成正方形是一个加减法运算,对正方形所在索引格判断也只是4个点坐标与几个索引格坐标比较,对落在正形内点判断也只是几个索引(1~4)内点与正方形边坐标比较,这些做比较的次数不多且简单,会使最终效果与上面估计的有所降低,但不是很大。对于正方形需增大找点的情况并不多,实际上每个起始正方形内往往会有上百个点。由此可知,此方法与不进行优化相比,速度提高几十倍到几百倍并不困难。只是注意,我们对索引格建立时,要大小合理,当太大时M和N都变小,根据效率倍数估算(M×N×16)可知会使率降低,但当太小时,会使最终搜索正方形内点太少,正方形内出现无点情况就增多,扩大正方形情况也就多了,同时相关比较运算也会增多。所以合适的索引格大小,也是保证最佳速度的关键。
6 存在问题
由于索引建立和其他相关数组建立,需要更多的内存,主要体现在:①对每个点要增加一个索引区号分量(整型),增加内存1/7。②分区后又按区进行统计,等于是复制一遍数据,对于新增的判断构网次数分量,可能其他方法也都用到,这里不妨也算上,共增加内存1.2倍。③为索引等服务的少量变量。最后估计多用内存近1.5倍。但现在计算机的内存已很大,这方面已不是主要问题。还有,没有论述对所有点进行优化筛选,通过筛选,可以把一些对相对平坦或坡度均匀的多余点进行去除。同时没有考虑特征线的情况,希望以后把这方面内容考虑进去(就是一条特征线间点是一定要连线构网的,这项做起来相对简单些。)以使算法更加完善。
[1]彭李,刘少华,卢学军.一种基于动态正方形的TIN的构建算法[J].现代测绘,第30卷第2期,2007
[2]唐丽玉,朱泉锋,石松.基于STL的DelaunayTIN构建的研究与实现[J].遥感技术与应用,第20卷第3期,2005
Research of an Algorithm to the TIN Construction with the Growing Method
Wang HuiRan
(The institute of surverying and mapping of geologic Bureau of Hebei Province,LangFang 065000,China)
Aiming at inefficiency of triangulation construction for large data in the DEM production process,a triangulation growth algorithm supported by multi-level index is proposed in this paper.The logical structure of the algorithm is simple so that it can be implemented easily by programming.It can be tested that the new method will process more faster than the corresponding algorithm provided by some common softwares.
Irregular Triangulation;Delaunay Triangulation;Index
1672-8262(2010)02-146-04
P209
A
2009—06—29
王会然(1966—),男,工程师,现从事测绘遥感工作。
