一种基于人眼视觉特性的压缩方法*
2010-03-14魏小文石旭利赵子武
魏小文,石旭利,赵子武
(上海大学 通信与信息工程学院,上海 200072)
1 引言
近几十年来,随着通信和多媒体技术的迅速发展,视频编码技术得到了广泛的应用。而数字无损压缩作为其核心技术就变得越来越重要。医学成像、遥感、视频传输都要求编码比特数尽可能少,并且传输的图像与原始图像在主观质量上几乎是一样的。JM软件正是在这样的背景下由国际视频编码组织提出并作为视频编码的标准,且随着视频编码技术的发展而进步,经历了H.261,H.263,H.264 以及 MPEG-1,MPEG-2,MPEG-3和目前的MPEG-4。当前的视频编码标准软件及相应的改进方法可以很好地解决时间冗余、空间冗余及编码冗余等问题,也就是无损地对视频编码比特数进行压缩。例如,文献[1]通过时域与空域相结合的自适应预测来达到无损压缩,视频编码器通过运动估计去除时间冗余。文献[2]通过人眼对图像灰度变化的不同敏感程度特性对DCT块进行分类,从而去除空间冗余。文献[3]根据图像内容的变化并且用小波变换来对视频图像进行无损压缩以去除空间冗余及编码冗余。但以上方法及当前的视频编码标准却很少考虑视觉冗余。笔者提出的基于人眼视觉特性的压缩方法可以有效地去除视觉冗余。其思想就是找到合适的恰可观测失真 (亮度变化不可见的最大值),也就是人眼对图像亮度变化的敏感度因子,通过敏感度因子对JM86代码流程中DCT变换前的亮度残差系数先进行量化,然后再变换、量化、编码,由此来进一步压缩比特数,去除视觉冗余,试验结果表明此方法有效。
2 人眼视觉系统(HVS)
当光进入人眼后,人眼视网膜上的光感受器对其进行采样,然后通过神经元发送光信号到大脑,从而形成了图像,视网膜上的光感受器(由杆状物和圆锥细胞组成)在人眼视觉系统中的作用就相当于传感器。这些杆状物对光照极其敏感并在光照较弱时不能感受到彩色[4]。如果由3种截然不同类型组成圆锥细胞,那么它的敏感度就要低得多,但是在适当的光照范围内能够让人眼感受到彩色,进入人眼的光信号有一个动态的范围,约为1∶1014,然而神经元传输信号的动态范围仅仅只有1∶103,人眼能够辨别的动态范围是10-12的数量级[5-7]。因此,这就要求人眼有一种自适应的机制,也就是人眼先感受到的是一些不变的亮度值,然后在亮度变化非常小的范围内来察觉图像,而亮度就是人眼对可见光主观感觉的大小。虽然人眼能够很容易检测到亮度的闪烁,但是很难用具体的数值对其强度进行量化。尽管如此,大量的试验已经证明了亮度强度通常近似为亮度的对数[6],当然这种关系取决于对周围发光体人眼的适应水平。人眼对亮度的不同适应水平就会产生不同的阈值,这是人眼视觉系统的一个重要特性。在这个阈值以内,人眼是不可见的。因此,可以将阈值看成是人眼不可见的最大值(MAX)。信号强度越大,其MAX也就越大。因此,对于视频编码而言,可以对亮度强度大的信号增大其MAX,然后进行量化。文献[7]将Weber原则和人眼对图像的感知习惯结合,其中背景亮度与恰可观测失真max的关系式为

式中:M指预测像素的亮度,K,a为依据经验设定的参数。这里用预测像素而不用预测块是因为预测块内的像素亮度不是恒定不变的,用预测像素可以更准确预测不可见的最大值,用预测像素的亮度代替当前像素的亮度是因为当前像素亮度不易得到。
3 量化
在JM86代码中,假定A′代表预测亮度像素值,A代表当前亮度像素值,那么亮度残差值B为
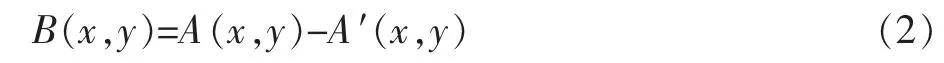
然后通过恰可观测模型来对B(x,y)进行第一次量化,去除视觉冗余。得到

将C(x,y)进行整数DCT变换,得到变换后的残差值 D(x,y),令

对 D(x,y)进行第二次量化,得到 E(x,y),量化后分为两步,一步是进行熵编码,形成码流,进行传输;另一步就是反量化,得到 F(x,y),再对 F(x,y)进行反 DCT 变换,进行重构,得到的重构图像为A″

将重构图像与当前图像相减得到差值G(x,y),即
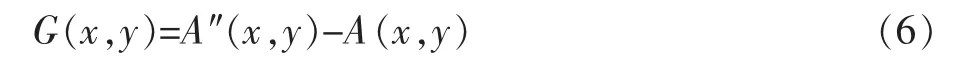
进一步去除视觉冗余

4 试验结果与分析
笔者提出的方法是在JM86上实现的。因为JM86使用的是整数DCT变换,所以要对恰可观测失真表达式取整,即 max=ceil[K×(1.219+M0.4)2.5+a],通过对 JM 代码亮度数据的分析,K的取值只能在[0.01,0.10]之间。本试验测试的视频序列为Bream,Mobile,Mother_Daughter,Container,Akiyo等 5个 QCIF标准视频测试序列(176×144),每个序列编码 50帧,帧内周期为 0(第 1帧是I帧,其余都是P帧)。 在帧率为30 f/s(帧/秒),RDO为1的状态下改变P帧QP的值来统计测试结果 (这里QP 取 24,26,28,30,32),可得最佳的经验值为 K=0.06,a=0,此时的试验结果如表1所示。

表1 试验前后比特数的变化
由表1中5个标准测试序列在不同的量化参数值比特数的变化可以看出每个测试序列的平均总比特数都有明显的下降,且下降的比特率在8%~20%之间。说明此方法能很好地去除视觉冗余,提高编码效率。下面通过图1检验视频测试序列的主观质量。
通过解码出来的主观图像效果对比可以看出,两者几乎是没有明显的差别,说明在量化之后(也就是进一步去除冗余之后)图像的主观质量并没有下降,但是比特数的压缩率却减少了近一半(Akiyo为44.44%,Bream为41.93%,Mother_Daughter为37.6%),有的甚至超过一半(Mobile为77.42%)。这说明了通过人眼的视觉系统,图像中存在较多的视觉冗余,有进一步优化的必要。
5 小结
针对人眼的视觉特性,也就是对恰可观测失真区域内亮度不敏感的特性,提出了一种基于恰可观测失真背景亮度模型来对亮度残差进行量化,在保证视频主观质量没有明显变化的前提下,提高了编码效率。另外,本方法还能在一定程度上降低JM86参考软件的复杂度,因为通过恰可观测失真模型对亮度残差进行量化处理之后,其数据得到明显的压缩,再进行DCT变换时,其运算量就会得到明显的降低,从而达到了降低其运算复杂度的效果。试验结果表明,5个标准视频测试序列的主观质量并没有下降,但各个测试序列总比特数的平均压缩率在8%~20%之间,证明了此方法有效。

[1]ZHANGMingfeng, HU Jia, ZHANGLiming.Losslessvideocompression using combination of temporal and spatial prediction[C]//Proc.IEEE International Conference on Neural Networks and Signal Processing.Shanghai,China:IEEE Press,2003,2:1193-1196.
[2]WEIZhenyu,NGAN K N.Spatio-temporal just noticeable distortion profile for grey scale image/video in DCT domain[J].IEEE Trans.Circuits and Systems for Video Technology,2009,19(3):337-346.
[3]DING JR, YANG JF.Adaptive entropy coding with (5,3) DWT for H.264 lossless image coding[C]//Proc.TENCON 2007-2007 IEEE Region 10 Conference.Taipei,China:IEEE Press,2007:1-4.
[4]XU Shilin,YU Li,ZHU Guangxi.A perceptual coding method based on the luma sensitivitymodel[C]//Proc.IEEE International Symposium on Circuitsand Systems.New Orleans,LA,USA:IEEEPress,2007:57-60.
[5]YANG X K, LIN W S, LU Z, et al.Motion-compensated residue preprocessing in video coding based on just-noticeble-distortion profile[J].IEEE Trans.Circuits and Systems for Video Technology,2005,15(6):742-752.
[6]徐士麟.于人眼观测特性的视频编码技术研究[D].武汉:华中科技大学,2009.
[7]IRANLIA,WONBOK L,PEDRAM M.HVS-aware dynamic backlight scaling in TFT-LCDs[J].IEEE Trans.Very Large Scale Integration(VLSI) Systems,2006,14(10):1103-1116.
