基于多维度并联卷积神经网络与质谱数据的芬太尼分类模型研究
2024-04-22薛凌云刘亦安
唐 龙,薛凌云,徐 平,刘亦安
(杭州电子科技大学自动化学院,浙江 杭州 310018)
0 引 言
过去7年,由于北美非法制造芬太尼和芬太尼类似物导致的阿片类药物过量死亡人数增加[1],导致国际社会对这些物质更广泛地扩展到非法药物市场感到担忧[2]。在美国[3]和加拿大[4]的许多地区非法芬太尼在很大程度上取代了海洛因作为主要阿片类药物使用。有效阻止这一问题的主要方法是提高现有的检测和处理芬太尼及其类似物[5]的能力。通常,研究人员通过传感技术[6]采集未知物质的光谱,如红外光谱[7],拉曼光谱[8]和质谱[9]。质谱方法不仅可以用于芬太尼及其衍生物检测[10-13],还可以分离多组混合物,便于混合样品中的芬太尼检测。综上所述,我们选择利用质谱数据进行芬太尼的分类。
近些年来,学者对芬太尼类似物的分类技术进行了研究。主成分分析(PCA)[14]被用来降低芬太尼类似物的质谱维度,然后分层聚类算法被用于识别芬太尼类似物[15]。当总类别已知时,可用于芬太尼类似物的分类和定性分析。近年来,基于相似性度量的光谱库搜索方法被应用于芬太尼类似物的分类[16-19],其中基于孪生网络和质谱库搜索的方法可以获得最佳的分类性能[19]。尽管基于孪生网络和质谱库搜索的方法可以在芬太尼类似物之间上获得相对较好的分类性能,但在非芬太尼类似物和芬太尼类似物上效果不佳。而区分非芬太尼类似物和芬太尼类似物是阻碍毒品传播的有效途径。一种基于峰值和基于相似度特征提取方法被用来芬太尼分类,并且实现了99%的检测概率[20]。但由于手动提取特征需要大量的领域知识,这是一个繁琐,费时又易出错的过程。因此,应开发更有效的模型来分类。而深度学习方法不仅无需手工参与,而且可以提取更深层次、更为抽象的特征。但是在芬太尼分类领域仅发现基于孪生网络和质谱库搜索的方法利用深度学习的方法[19],而该方法用于解决小样本的分类问题。因此我们尝试将新的深度学习方法应用于芬太尼分类,从而达到更好的分类效果。
目前,质谱数据分析方法主要包括经典的库匹配[21]、遗传算法[22]、卡方检验[23]、主成分分析(PCA)[24]、人工神经网络[25]和支持向量机(SVM[26])。还有一些组合方法[27],如PCA和SVM、小波和神经网络、VAE和全连接网络。随着近几年深度学习的快速发展,神经网络已经被广泛应用到质谱领域,特别是在质谱用于癌症分类[28-30]的领域中已经有了大量使用深度学习的例子。Qiang Hu等人中提出一种将质谱的一维谱图拼接为二维图像的方式,并且利用卷积神经网络进行特征提取[30]。该方法可以更有效地识别具有相似质谱的化合物[30]。目前,深度卷积网络在图像领域已得到广泛应用,学者先后提出GoogLeNet、ResNet、MobileNet等深度学习网络模型。
在本文数据集中非芬太尼类物质样本数量是芬太尼类物质的18倍,数据分布不均衡。而经样本分布不均衡集训练的分类器,判别结果可能会偏向数量多的类别。导致传统的分类方法在芬太尼数据中分类效果不佳,分类敏感性很差,分类准确度较低。
基于上述讨论,本文提出了一种高效的芬太尼质谱分类模型。在模型中使用一种特殊的卷积特征提取模块(Fusion模块)。它可以增强网络对不同特征尺寸的适应性,来提高模型的分类性能。该模型将一维原始数据与拼接图像数据输入到并行二维卷积层和一维卷积层进行特征提取,来避免图片拼接时丢失的一维空间信息。最终通过特征融合的手段将上述并行网络的特征融合进行分类。该模型利用Focal loss[25]损失函数作为损失函数来解决样本不均衡问题。
1 方法
1.1 基于多维度并联卷积神经网络与质谱数据的芬太尼分类模型
基于多维度并联卷积神经网络模型结构如图1所示:

(a)一维卷积神经网络;(b)二维改进神经网络
图1所示为基于多维度并联卷积神经网络模型的整体结构,该网络左边部分为一维卷积神经网络,右边为二维改进卷积神经网络。二维改进神经网络由两串联Fusion模块组成。该结构既能保证对增强为二维图像数据的处理,又能对保留原始空间结构的一维数据进行处理。因此该网络包含更多的特征信息,从而提高分类精度。
由于Sigmoid是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最接近生物神经元,输出层激活函数采用公式(1)中Sigmoid。优化器采用随机梯度下降(SGD)。在公开数据集中NIST05,正负样本的分布是不平衡的。普通的损失函数,均方损失方法对于稀疏和不平衡的质谱数据,并没有取得很好的分类效果。此外,一些难分样本,如异构体很难区分。考虑到Focal loss对解决目标检测中的极端不平衡问题是有效的[31],因此引入公式(2)中的Focal loss作为目标函数来解决样本不均衡问题。
(1)
其中x为输入。
Fcalloss=-α(1-pt)γlog(pt)
(2)
其中权重α平衡正样本和负样本,pt是一个样本的模型的估计概率,γ是一个调制因子,γ越大,简单样本损失的贡献会越低。对于两个超参数,通常来讲,当γ增大时,α应当适当减小。实验中γ取2、α取0.25时效果最好。
1.2 一维卷积神经网络

(3)巨量淤泥的出路令项目实施单位感到棘手。河道清淤工程中,采用堆场把淤泥堆放在指定的位置等其自然干燥是目前主要的处理方式,但堆场存放会占用大量土地资源,且巨量淤泥长年累月堆放处置不现实。同时,这些堆场的淤泥水分难以蒸发,只在表面形成一层硬壳,形成沼泽地。

图2 一维卷积运算示意图
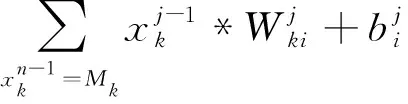
(3)
1.3 数据预处理
其中阿芬太尼、卡芬太尼、芬太尼、瑞芬太尼和舒芬太尼的质谱被选作参考谱。因为这五种化合物是因为它们广为人知,而且存在大多数参考库中[20]。在质谱库检索中Qiang Hu等人提出了一种谱图拼接的方法,取得很好的分类效果[30]。此研究借鉴这种拼接方式对质谱进行数据增强。
如图3所示,每个质谱数据分为20段,每个段长度为40。将查询样本谱图和经典参考谱图的每段谱段按顺序堆放。将样本对堆放成40×40的矩阵。拼接操作如图3所示。质谱数据经上述操作之后可以作为输入,利用二维卷积神经网络进行分类。

图3 拼接操作
1.4 Fusion模块
本文提出的Fusion模型共有9层,深度为7,模型结构如图4所示。传统Inception结构的优势在于利用1×1卷积进行降维操作,并结合不同尺寸小卷积操作与池化操作达到获取不同感受野特征信息、减少参数量的目的。然而由于使用了大量1×1卷积,导致大量不必要的冗余参数产生。针对以上情况,本文提出的Fusion模型结构,将5个通道共用一层1×1卷积来降低参数。由于质谱数据比较稀疏,所以我们利用1×1卷积将5个通道数据通过线性组合压缩到1个通道,来降低参数量。最大池化层(Max Pooling)可以保留主要的特征的同时减少参数和计算量,并且防止过拟合,提高模型的泛化能力。由于训练中会存在梯度消失的问题,采用缩放指数线性单元(SeLU)作为激活函数。根据该激活函数得到的网络具有自归一化功能,从而避免了梯度爆炸和梯度消失。SeLU公式为

图4 Fusion模型结构
SeLU(x)=scale×(max(0,x)+min(0,α×(ex-1)))
(4)
其中scale=1.050 700,α=1.673 26,x为输入。
2 实验与讨论
2.1 实验数据
从美国国家标准与技术研究所(使用NIST05 MS搜索演示软件分发的库集合)和缴获药物科学工作组获得了3718个EI质谱,网站:https://www.swgdrug.org/ms.htm。这一组质谱数据中包括195芬太尼的类似物的质谱,如芬太尼、卡芬太尼、和舒芬太尼,并且获得了3523个非芬太尼物质。本文中将每个质谱数据强度值归一化,使每个光谱中单个峰的最大强度为1000。处理后的质谱数据如图5所示,质谱特征比较稀疏。归一化公式如下:
(5)

(a)为芬太尼质谱图;(b)为非芬太尼质谱图。
其中I代表维质谱强度,x代表维度,I*表示归一化后的强度。
对数据进行利用主成分分析进行二维可视化如图6所示,样本之间的距离越远,说明其组间的代谢产物的差距越大。从图6中可以直观看出样本之间混叠严重,说明其组间的质谱特征不明显。

图6 芬太尼与非芬太尼物质数据进行行主成分分析2D
图6中黄色的点代表芬太尼及其类似物的样本,紫色的点代表非芬太尼及其类似物。
2.2 实验数据划分

表1 加入参谱图的数据划分

表2 不加入参谱图的数据划分
其中阿芬太尼、卡芬太尼、芬太尼、瑞芬太尼和舒芬太尼的质谱被选作参考谱。因为这五种化合物是因为它们广为人知,而且存在大多数参考库中。
2.3 实验设计
实验总体方案如下:
实验1:将原始一维质谱作为输入,利用传统机器学习算法中的线性判别算法(LDA)、主成分分析(PCA)+支持向量机(SVM)和遗传算法(Ga)+支持向量机(SVM),以及深度学习算法中一维卷积神经网络进行分类。将原始一维质谱和5条参考谱图一起作为输入,输入到一维卷积的6个通道中,利用一维卷积神经网络进行分类。
实验2:将原始一维质谱与参考谱图拼接后的二维图像数据作为输入,利用我们改进的卷积神经网络(两串联Fusion模块)进行分类。并且与深度学习算法中残差神经网络(Resnet-18)和移动网络(MobileNet V1)进行对比。
实验3:将原始一维质谱以及拼接后的二维图像数据作为输入,利用本文提出的基于多维度并联卷积神经网络模型进行分类。
2.4 实验环境
实验环境:PyTorch深度学习开发框架,采用Python作为开发语言。实验采用的CPU为Intel酷睿i7-9700F,GPU为单个NVIDIA GeForce RTX 2080。在训练过程中选用随机梯度下降(SGD)作为优化器,batch size设置为1,初始学习率设定为0.0025,epoch为100。
2.5 实验评价指标
为了评估分类方法的有效性,由于数据集不平衡,我们使用了3个评价指标。分别为准确性、敏感性和特异性的评价标准分别定义如下:

(6)

(7)
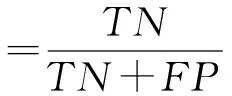
(8)
其中TP:被模型预测为正类的正样本;TN:被模型预测为负类的负样本;FP:被模型预测为正类的负样本;FN:被模型预测为负类的正样本。
2.6 实验结果
将原始一维质谱为输入进行分类,在传统机器学习模型中,PCA+SCM模型分类精度最高,高达97.96%。一维卷积神经网络的分类精度98.60%。而将原始一维质谱和5条参考谱图一起作为输入,利用一维卷积神经网络进行分类,分类精度高达98.60%。在加入参考谱图后一维卷积神经网络的分类精度为99.38%,提升了0.78%.将原始一维质谱与参考谱图拼接后的二维图像数据作为输入,Resnet-18、MobileNet V1和二维改进神经网络的分类精度分别是99.38%、99.41%和99.43%。将原始一维质谱以及拼接后的二维图像数据作为输入,利用本文提出的基于多维度并联卷积神经网络模型进行分类,分类精度为99.73%。
2.7 讨论
由表3可以看出,实验一中深度学习算法分类精度比传统机器算法的分类精度要高。在加入参考谱图后一维卷积网络的分类精度得到了提升,说明加入参考谱图有利于提高网络的分类性能。实验2中的分类精度高于实验1中的分类精度,可以得出结论,将一维谱图拼接成二维图像数据,是一种可行的转换手段。其中二维改进神经网络取得了与最好分类精度,充分体现了Fusion模块具有功能强大的优势。实验3中基于多维度并联卷积神经网络模型分类精度达到了99.73%,优于其他分类方法。由此可知基于多维度并联卷积神经网络模型结构的对提升芬太尼数据分类准确的具有一定效果。

表3 实验分类结果
3 结束语
本文针对传统分类方法对该数据集分类准确度不高的问题,提出了基于多维度并联卷积神经网络,提高了芬太尼数据分类灵敏度和准确度。结果显示该方法的分类性能优于许多已有的分类方法。不同于手动提取特征的传统分类方法,该方法能够自动提取特征,不仅为芬太尼分类提供了新的思路,甚至可以用于对蛋白组学和代谢组学的质谱数据分类中。本文方法在深度学习分类器的训练上需要花费较长时间,网络的结构也较为复杂,因此对于优化模型参数,加快模型训练速度,还需进一步的研究。
