科学文献主题建模方法及其效果评估研究
2024-04-14逯万辉
逯万辉


关键词:主题建模;LDA;Top2vec;Bertopic;科学文献;主题识别
科学文献是科学知识传播与交流的重要载体和媒介,其中蕴含着丰富的语义信息和主题信息,基于特定领域的文献数据集,挖掘和识别其中的研究主题并对其进行有效的知识关联和主题表示,是揭示领域知识演化脉络、探测领域研究前沿的一项基础工作。许多学者从不同角度对科学文献主题挖掘方法与应用进行了研究和探索,通过对科学文献的内容特征、引文网络、语义信息等不同维度信息的挖掘与计算,实现了科学文献的文本聚类与主题抽取,以辅助科研人员快速把握领域研究现状和趋势,提升科研效率。目前,科学文献主题挖掘技术已成为情报学与情报分析方法领域的重要技术基础,在研究前沿探测、技术主题演化分析、新兴研究领域主题结构挖掘、知识组织与知识图谱构建、学术评价与推荐研究等方面均表现出广阔的应用前景。科学文献主题挖掘方法主要来源于计算机领域的主题建模技术,该技术是一种较为通用的文本特征计算与隐性知识挖掘方法,主要应用于非结构化数据处理与分析之中。近年來,随着深度学习算法的不断发展和大语言模型技术的广泛应用,Doc2vec、BERT等新的文本特征计算方法的出现为主题建模技术提供了新的实现途径,随之出现的Top2Vec.BERTopic等新兴主题建模工具,为科学文献主题建模提供了新的解决方案。相较于传统主题建模方法(如LDA主题模型),新兴主题建模方法在文本特征计算过程和主题建模结果上均存在较大的差异性。研究和对比不同主题建模方法的算法特点及其在科学文献主题识别上的结果差异与优势表现,是针对研究目标科学选择主题建模方法开展主题挖掘实践与应用的重要前提。基于此,本文聚焦科学文献主题建模方法的主题识别效果评估视角展开实验研究,通过对不同类型主题建模技术的算法特点和建模效果进行对比分析,以期为科学文献主题挖掘在不同应用场景中选择合适的主题建模技术提供科学支撑。
1科学文献主题建模研究现状
1.1主题建模技术研究现状
主题建模(Topic Modeling)最早产生并应用于信息检索和自然语言处理领域,是一种数据降维和特征抽取技术,该技术引入了主题这一概念,通过扫描一组文档并检测其中的单词和短语模式,将文档集合中的词语规约到主题维度,从而达到高维数据降维的目的,同时主题中也包含了文档及其词语的潜在语义信息,因此具备更强的语义表达能力。LSA(Latent Semantic Analysis,潜在语义分析)、pL-SA(Probabilistic Latent Semantic Analysis.概率潜在语义分析)和LDA(Latent Dirichlet Alocation,隐含狄利克雷分布)等都是较为常用的主题建模方法。近年来,随着深度学习算法与大语言模型的快速发展,新兴主题建模技术如Top2Vec和BERTopic等也广泛应用于文本主题挖掘过程。
潜在语义分析(LSA),也称作潜在语义索引(Latent Semantic Indexing,LSI),是一种较为简单的主题建模技术,该技术最初主要用于解决语义检索领域中一词多义问题。潜在语义分析利用词语的上下文信息,可以捕获隐藏的概念或主题,操作过程中通过奇异值分解(SVD)技术将任意矩阵分解为3个独立矩阵的乘积:M=UxSxV,其中S是矩阵M的奇异值对角矩阵。通过LSA技术将原始的文本矩阵处理后提取出k维语义空间,在保留大部分信息的同时,使得k值远小于文档和词语维度,这样用低维词条、文本向量代替原始的空间向量,可以有效地处理大规模文本语料库。但是由于LSA技术将文档中的每一个词映射为潜在语义空间中的一个点,并没有很好地区分和解决多词一义的问题.因此,近年来不少学者也针对此问题进行了改进。Kim S等在此基础上结合深度学习算法提出了一种新的主题建模方法,即利用Word2vec捕获和表示语料库上下文信息的特性,构建了基于Word2vec的潜在语义分析方法(W2V-LSA)。概率潜在语义分析(pLSA)最初是Hofmann T在潜在语义分析(LSA)的基础上提出的一种新的主题建模方法,该方法使用概率模型来衡量文档、潜在语义、词语三者之间的关系,与潜在语义分析方法相比,pLSA中的多义词和同义词均可在潜在语义空间中得到合理的表示。
LDA主题模型是在概率潜在语义分析的基础上又进一步衍生出的主题建模技术,该模型为三层贝叶斯概率模型,包含“文档一主题一词”三层结构,实现了对文档中隐含主题建模,并且考虑了上下文语义之间的关系。其中,主题即词汇表上词语的条件概率分布,与主题关系越密切的词语,它的条件概率越大,反之则越小。LDA主题模型被提出以来,在文本分类、文本聚类、查询检索、话题检测与追踪、学术文献挖掘、时态文本流分析等众多领域产生了广泛且深入的应用,已成为处理篇章级文本数据挖掘的重要工具。同时,随着研究的不断深入,研究人员对LDA主题模型的研究和应用也在不断拓展,例如利用文档作者与文章内容间的关系衍生出了作者主题模型(Author Topic Model,ATM)、通过对主题间的关系建模衍生出了相关主题模型(Correlated Topic Model,CTM) cis],以及考虑主题的时序动态演化因素所提出的动态主题模型(Dynamic Topic Model,
DTM)等。
近年来,深度学习算法与大语言模型的融合与应用不断拓展,衍生出了Top2Vec、BERTopic等基于预训练词嵌入算法的主题建模技术。这类方法首先通过嵌入(Embedding)模型(如Word2Vec、Doc2Vec、BERT等)计算出文档和词语的向量表示,然后把它们嵌入到同一个语义空间中进行相关计算。例如,Top2Vec模型使用Doc2Vec等算法在同一向量空间中训练词向量和文档向量,构造出在特定主题以及上下文环境中的词向量,能够在大型数据集和非常独特的词汇表中生成更加准确的主题向量。BERTopic采用基于BERT的深度学习预训练模型,通过Sentence-Transformers等嵌入模型和c-TF-IDF算法对句子进行编码和计算,实现了语义层面上的文档主题聚类与主题表示,相较于LDA主题模型等主题建模技术,BERTopic在NPMI(Nor-malized Pointwise Mutual Information)指标上能够表现出更好的主题识别效果。
1.2科学文献主题建模及其应用现状
科学文献主题建模一直是情报研究与知识发现领域的研究热点,特别是基于大规模科学文献的研究主题探测和前沿识别成为近年来情报学领域的重要研究方向。在科学文献的主题建模过程中,主题由具有同样研究基础的一组文章构成,对科学文献的主题建模实际上也就是通过科学文献聚类并自动抽取类别标签的过程。目前,众多学者在此领域开展了大量工作,并且在实践中已经拓展出广泛应用,国际大型数据库商爱斯维尔开发的SciVal工具在主题创建过程中,对旗下的Scopus数据库中论文和参考文献进行聚类后,识别形成了全域微观主题及其显著性指标排序,为探测全域研究前沿提供了重要的数据支撑。
在学术界,从方法论层面研究主题建模技术在科学文献知识挖掘上的应用,并用之探索特定领域的科学研究趋势,是当前国内外学者们关注的焦点,基于LDA主题模型的领域主题抽取与研究趋势分析是当前学者们主要采用的方法。如Palanichamy Y等基于LDA主题模型探析国际环境科学与工程领域的主要研究趋势和区域差异:王日芬等基于LDA主题模型比较分析了主题模型方法在全局主题和学科主题抽取中所存在的差异:Daud A等构建了基于LDA主题模型的群体层面的主题建模方法并进行了会议信息挖掘。随着深度学习算法的兴起,陈翔等通过引入分段线性表示方法和Word2Vec模型构建了动态关键词语义网络,在此基础上利用社区发现算法识别动态网络中的社区来表征主题,实现了信息科学领域的主题演化路径识别,并在基于专家意见构建的领域“主题一关键词”标准集上与LDA主题模型等方法对识别出的主题词集合的差异性进行了对比。
在科学文献主题建模及其效果评价方面,关鹏等通过对不同语料下基于LDA主题模型的科学文献主题抽取效果进行分析,采用查全率、查准率、F值以及信息熵等定量指标对主题抽取效果进行评价后发现,摘要作为语料的LDA主题抽取的效果要优于单纯使用关键词作为语料的主题建模。随着主题模型使用范围的不断扩大,有关主题模型建模效果评价的指标也不断丰富,为科学使用主题建模工具、优化主题建模过程和评估主题建模效果等提供了极大的便利,但是在科学文献主题建模的应用效果評估方面,尚未形成统一客观的评价方法与评价准则。近年来,以LDA主题模型为代表的主题建模技术在科学文献主题挖掘过程中被广泛使用,但主题模型的建模效果是否优于传统聚类技术,LDA主题模型是否是科学文献主题建模的最优选择,这些问题也引起了学者们关注和讨论。与此同时,随着Top2Vec、BERTopic等基于深度学习算法与大语言模型技术等新兴主题建模工具的出现,相较于传统主题模型来说,不同主题建模方法的建模效果之间的差异性如何,需要做出科学系统的对比评估。特别是在科学文献主题建模过程中,该如何选择最优的主题建模工具或构建最适用的主题建模方法来实现研究目标,是摆在科研人员面前的一个重要问题。从上述这些问题出发,本文将聚焦科学文献主题建模方法的效果对比研究,通过构建实验数据集,分别基于LDA主题模型、Top2Vec和BERTopic等算法,采用量化指标对不同建模工具的使用效果进行对比分析,以期为主题建模工具在科学文献主题建模应用过程中提供科学的选择依据。
2研究思路与方法
2.1研究目标与整体研究思路
为了对比不同类型主题建模技术在科学文献主题建模过程中的实现方式和使用效果,分析不同类型语料环境下的主题建模方法对主题建模质量的影响,研究如何优化主题建模参数并提升主题建模效果,进而为面向实际科研问题的解决、选择和构建适用的主题建模方法提供参照,是本文的主要研究目标。一般来说,主题建模过程包含主题聚类与主题表示两个步骤,主题聚类效果反映了主题建模工具对文档内容的挖掘深度,主题表示结果反映了主题建模工具对文档主题的抽取效果,对不同建模工具从主题聚类效果和主题表示结果两个方面展开研究,是完整评价主题建模工具的建模效果的必要环节。基于上述思路,本文重点选择LDA主题模型、Top2Vec模型和BERTopic模型3种比较具有代表性的主题建模方法,分别在中英文科学文献实验数据集上展开实验,进行主题建模效果评价。同时,为了全面反映主题建模技术的特点,本文也将采用传统聚类算法进行聚类实验作为对照,并与基于主题建模的聚类进行对比。本文的研究思路如图1所示。
2.2实验数据集构建与评估指标
为了同时反映不同主题建模技术在聚类效果与主题识别方面的效果,本文需要开展两个方面的实验:一是关于不同算法的聚类效果的对比和评价,即开展实验①的相关研究。二是对不同主题建模技术在科学文献主题建模上的应用效果评价,即开展实验②的相关研究。为了充分展现不同主题建模工具的使用场景与效果差异,在实验数据集的构建与选择上,本文将分别采集科学技术领域的中、英文学术文献数据集,构建实验语料来展开上述实验研究。
在评估指标的选择上,本文采用主题内容相似度的方法来判断主题建模过程中的聚类效果,通过计算聚类后各个主题内部文档间的平均相似度与不同主题间的平均相似度的比值,来反映聚类结果的内聚性与耦合性特征,即以类簇内主题高相似度和类簇间主题的低相似度共同构成评价主题聚类效果的指标。该指标的最终得分与类内主题的内聚性呈正比变化关系,与跨类主题的耦合性呈现反比关系,从而实现以高内聚低耦合来评价主题聚类效果的最终指标(HCLC,High Cohesion&Low Coupling)。在主题内文档相似度计算方法上,不同主题建模方法均分别采用向量空间模型(Vector Space Model,简称“VSM”)和Doc2vec算法作为文档相似度的基础算法,进行实验①的聚类效果评价实验。HCLC指标的计算方法如式(1)所示:
式中,K为聚类主题数目,n为每个类簇内文档的数目,sim(di,d)表示类簇内两个文档间的相似度,通过迭代计算类簇内两两文档间的相似度,得到该主题数目下各类簇内文档的平均相似度:』7v为跨主题的文档对数量,sim(d,d)为跨主题文档对(m,n)的文档相似度,通过上述两个步骤的计算得到聚类效果。
在实验②中,本文在现有主题建模测度指标和工具的基础方法上,结合科学文献主题建模的特点,选择主题多样性(Topic Diversity,亦称“主题差异性”,简称TD)、主题语义一致性(TopicCoherence,简称TC)、主题稳定性(Topic Stability,简称TS)和主题离散性(Topic Variability,简称TV)等指标开展不同主题建模方法的科学文献主题建模效果评价。
主题多样性(主题差异性)的计算过程相对简单,该指标通过计算主题建模结果中所有主题中不重复出现的主题词的占比情况后得出。主题多样性数值越小,表示模型识别出的主题信息冗余度较高;主题多样性数值越大,则表示模型识别出了更加多样的主题,主题多样性(TD)的计算方法如式(2)所示:
主题语义一致性指标主要用于评估主题模型的主题连贯性。从逻辑上看,语义上高度相关的词也应当被分配到同一个主题下。因此,连贯性衡量的是主题中各单词彼此之间的相似程度、是否互相支撑。当前基于词共现模式的主题连贯性已经被验证是一种可靠的主题分类质量指标,根据词组确认度(Confirmation)计算方法的不同,主题语义一致性的计算方法包括UCI Coherence、UMass Coherence等。有研究表明,采用Normalized PMI(NPMI)方法计算词组确认度的主题一致性指标表现更好,因此,本文将其作为主题语义一致性(TC)评价指标来进行主题建模工具的建模效果对比研究,其计算方法如式(3)所示:
主题稳定性(TS)和主题离散性(TV)指标是基于主题建模过程数据产生的评价指标。在主题建模过程中会产生两个矩阵,一个是主题一词分布,另一个是文档一主题分布。主题稳定性即在考虑主题一词分布的基础上产生的测度指标,其计算方法如式(4)所示:
主题离散性是在文档一主题分布基础上产生的主题建模效果测度指标。LDA主题模型和Top2vec模型在训练后能够直接得出文档可能归属的多个主题以及其概率排序,而Bertopic模型则需要在模型训练时设置“calculate _probabilities=True”参数,输出计算过程数据来得到文档主题分布。主题离散性指标计算使用了主题建模的过程数据,由于不同主题建模算法的文本抽样方式不同,计算出的“文档一主题”分布概率存在较大差异。因此,为了消除量纲差异,本文在文献的基础上,采用变异系数的方法对主题离散性指标进行改进,使得不同建模方法得出的主题离散性具有可比性。主题离散性计算方法如式(5)所示:
式中,D表示文档集的规模,主题K的离散性指标可以概括为文档集内每个文档在该主题上的概率分布的变异系数,该值越大,表示文档被划分到相关主题的倾向性越强,也可以反映出文档主题识别的质量越高。
3科学文献主题建模方法与效果评估
3.1实验数据描述与主题抽取
按照上述研究思路和方法,本文在开展基于LDA主题模型、Top2vec模型和Bertopic模型的科学文献主题建模效果评估实验过程中,分别选取中英文科学文献构建实验语料并进行对比试验。其中,英文实验语料以Web of Science(简称“WoS”)数据库为数据源,检索并下载SSCI和SCI数据库收录的自然语言处理领域学术文献作为实验对象构建英文科学文献数据集:中文实验语料以中国人文社会科学引文数据库(简称“CHSSCD”)为基础,按照不同学科文献规模,等比例随机抽取人文社会科学领域的中文学术文献构建实验数据集。中英文语料实验数据集的基本信息如表1所示。
在實验环境搭建上,以一台硬件配置为Intel(R)
Core(TM)
i7-7700双核3.60GHz CPU+16GBRAM的台式计算机搭建科学文献主题建模实验环境,基于Python3.8编程语言,以Gensim4.3.1(LdaModel).Top2vec1.0.29和Bertopic0. 14.1等开源工具包为基础,进行编程运算和文本数据处理,并开展主题建模实验研究。
通过采用LDA、Top2vec和Bertopic主题模型方法对上述语料进行主题建模后,可以直观展现不同主题建模方法的建模结果及其差异。由于在基于LDA主题模型进行主题建模时,需要在其参数中设置文档的主题数目,并且主题数目会直接影响主题建模效果。Top2vec和Bertopic虽然不需要预先设置该参数,但是在默认参数条件下的主题建模中会出现大量的冗余主题,因此也需要在主题建模后通过主题相似度阈值的设定来实现主题归并。在对比实验中,为了保证不同建模工具的最终建模效果可比,本文基于困惑度指标以及主题重叠度和完整度等算法,对实验语料文本特征进行计算,获取文档集内的最优主题数目范围,并将其作为LDA主题模型的基本参数(主题数量K)进行建模;由于Top2vec模型在训练过程中不能预设主题个数,因此需要在模型训练完成后对基于该模型的topic_merge_delta参数进行调整,将主题间较为相似的主题进行冗余主题的合并;Bertopic模型则需在训练完成后,用基于该模型的reduce_outliers方法将训练过程中的离散主题再次进行合并归类:最终使得不同主题模型识别的主题数目保持一致,从而具有可比性。
基于上述思路,分别对本文构建的中英文实验语料进行主题建模并得到主题识别结果。通过困惑度指标以及主题重叠度和完整度等算法对文档集内的最优主题数目进行计算,得到中文语料的最优主题数目在75+1个,英文语料的最优主题数目在62+1个,在下文中基于K-Means算法的文本聚类实验中也将其作为类簇数目参数。通过对不同主题模型识别出的主题集合的相似度计算后发现,不同建模工具的主题识别结果表现出较大的差异性。其中,LDA模型和Bertopic模型的主题识别结果中具有相似性关系的主题占比仅为9.81%(英文语料)和7.46%(中文语料),Top2vec模型识别出主题与LDA模型和Bertopic模型的识别结果相似度均仅在2%左右,具体结果如图2所示。该结果直观展现了不同建模方法在主题识别与表示上的不同,但是另一方面也显示出不同建模工具的主题词抽取算法的巨大差异。因此,为了进一步研究和评估不同方法和工具的主题建模效果,本文接下来将对不同主题建模方法在文档处理过程中的表现进行更深层次的对比研究,具体包含两个方面:一方面是在文档聚类上的表现能力:另一方面是主题词抽取能力的对比。
3.2不同建模方法的文本聚类效果对比
前文基于不同主题建模方法和工具的主题识别结果可以看出,不同建模方法在主题识别与主题表示上存在巨大差异,这种差异一方面可能存在于主题建模前期文档的聚类算法上,另一方面也可能存在于聚类后期的主题词抽取与表示方面。为了进一步评估不同主题建模方法的效果与差异,本小节先对主题建模过程中的文档聚类效果进行对比研究。
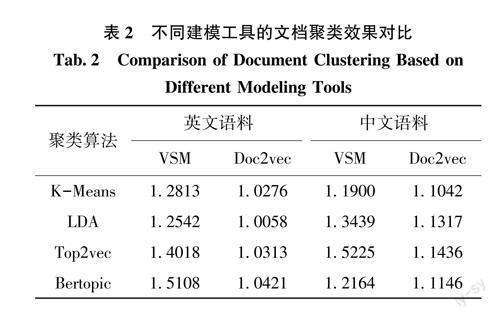
本文分别采用LDA主题模型、Top2vec模型和Bertopic模型对中英文实验语料进行主题建模,对建模后的文档主题分布进行提取后,实际上可以将主题建模转化为文档聚类。同时,采用K-Mean聚类算法对文档进行聚类作为对比实验,采用前文构建的HCLC指标(即High Cohesion&Low CouplingIndex)进行聚类效果评价,结果如表2所示。
从计算结果来看,在英文实验语料中,Bertop-IC模型表现出相对较好的聚类效果,其HCLC指标得分为1.5108,经过预训练的语言模型在科学文献主题聚类上也展现出较好的应用表现,其次是Top2vec模型,其在英文语料上的聚类效果稍逊于Bertopic模型,但是相较于LDA算法和K-Means算法的文档聚类表现来说表现较好,在没有特征优化与参数调整的环境下,LDA算法的文档聚类效果相较于K-Means算法来说,其优势并没有得到很好的发挥。因此,在使用LDA主题模型进行科学文献主题建模过程中,必须结合实验数据特征进行必要的参数优化和特征抽取以发挥其最佳效果。在中文实验语料中,文档聚类效果表现最优的是Top2vec模型,因为本实验中该方法采用了基于Doc2vec的文档相似度计算,在中文语料的复杂语义环境中该算法的优势得到了充分发挥,其次是LDA算法,由于相较于英文文档的词语特征多变问题(形态、时态等),中文词语的类型相对单一,但是语义更加复杂,因此其面向语义的文档处理优势在中文科学文献主题聚类上得到了较好的表现。而Bertopic模型是基于其预训练的文档嵌入算法,虽然也集成了多语言模型,但是在针对科学文献的文档建模具体任务中,必须对其预训练模型进一步微调(Finetune)才能发挥其最佳效果。
3.3不同建模方法的主題识别效果对比
在基于不同主题建模工具的科学文献主题识别与主题表示的效果评估指标选择上,本文分别采用主题多样性(TD,也称主题差异性)、主题一致性(TC)、主题稳定性(TS)和主题离散性(TV)4个指标来进行主题建模效果对比。为了充分对比不同方法工具的建模表现,在对中英文语料上的主题建模过程中,LDA主题模型分别采用词袋(Bag ofWords)和TFIDF算法进行文档特征抽取与主题建模比较;Top2vec模型则分别采用Doc2vec算法和预训练文档嵌入算法(分别在英文语料和中文语料中使用All-MiniLM-L6-v2和Paraphrase-Multilin-gual-MiniLM-L12-v2预训练模型,下文均简称为“MiniLM”)进行文档嵌入表示;Bertopic模型采用通用预训练文档嵌入算法(MiniLM和SciBert)进行主题建模。
分别采用上述3种主题建模工具(LDA、Top2vec和Bertopic)和5种文档特征表示方法(Bagof Words、TFIDF、Doc2vec、MiniLM、SciBert)进行中英文科学文献主题建模,并对主题建模后的主题多样性、主题一致性、主题稳定性和主题离散性指标进行对比,结果如表3所示。可以发现,在主题多样性(TD)指标上,基于Doc2vec算法的Top2vec主题模型(以Top2vec-Doc2vec表示,下同)在中英文语料中均表现最优,这一指标说明基于该方法获取的主题重合度较低,能够获取具有较强差异性的主题信息;在主题一致性(TC)指标上,Bertopic-SciBert模型在英文语料上表现出较好的效果,但是由于没有对照专门的中文科学文献大语言模型,基于通用语言模型的Bertopic主题建模的主题语义一致性指标略逊于Top2vec-Doc2vec方法;在主题稳定性(TS)指标和主题离散性(TV)指标上,Bertopic-SciBert模型在英文语料上均表现出较优的识别效果,但是对中文语料而言,在没有垂直领域训练模型的情况下,利用通用语言模型开展主题建模识别仍然是次优选择,其中Top2vec-MiniLM模型的主题稳定性指标较高,Bertopic-MiniLM模型的主题识别离散性指标较高,可根据具体应用场景和目标选择使用不同方法。通过上述研究,可以得出以下几点结论:在科学文献主题建模过程中,若希望获取包含更加丰富的主题信息,优先推荐使用基于Doc2vec的Top2vec模型进行主题抽取;如果需要使最终获取的主题信息具有更加强健的稳定性和离散性,优先推荐使用Bertopic模型进行主题建模。此外,在基于LDA主题模型进行主题建模的过程中,基于词袋的方法和基于TFIDF特征选择的方法在主题多样性上存在一些差异,但是在主题一致性、稳定性和离散性等指标上的表现差异不大,如果希望建模后的主题之间具有较强差异,则优先推荐使用TFIDF进行LDA主题建模。
4研究结果与讨论
针对主题建模技术的不断发展和广泛应用,不同建模方法和实现算法在科学文献主题建模实践应用上的表现情况和使用局限是本文的主要研究问题。本文通过构建中英文科学文献实验数据集,选择LDA主题模型、Top2vec和BERTopic等算法工具,以及基于词袋和TFIDF的特征提取算法,结合Doc2vec算法、All-MiniLM-L6-v2和SciBert等文本预训练模型,对不同主题建模方法和工具的建模效果进行了实验和对比。通过对不同主题建模方法工具的文本聚类效果和主题识别结果的多样性(差异性)、一致性、稳定性、离散性等指标计算,本文得出以下几点结论:①不同建模工具的主题识别结果表现出较大的差异性,在不同建模工具识别的主题上,LDA模型和Bertopic模型的主题识别结果中具有相似性关系的主题仅占比9.81%(英文语料)和7.46%(中文语料),而Top2vec方法识别出主题与LDA和Bertopic的结果相似度均在2%左右;②在文档的主题聚类效果上,Top2vec模型在中文语料上的聚类效果较好.BertoDic模型在英文语料上的聚类效果较好,LDA主题模型必须结合实验数据特征进行必要的参数优化和特征抽取才可以发挥其最佳效果;③在主题识别结果与主题表示方面,基于Doc2vec算法的Top2vec工具在科学文献主题识别的主题多样性(主题差异性)指标上的表现相对最优,能够获取具有较强差异性的主题信息;在主题语义一致性指标上,Bertopic-SciBert模型在英文语料上表现出较好的效果,基于通用语言模型的Bertopic-MiniLM方法在中文语料上的主题识别效果略逊于Top2vec-Doc2vec方法;采用文本预训练模型(MiniLM)的不同主题建模方法(Top2vec、Bertopic)的主题识别结果在主题稳定性和主题离散性指标上的表现均优于传统建模方法。
在具体应用过程中,主题多样性、主题一致性、主题稳定性和主题离散性指标不仅可以用于评测主题模型的建模效果,也可以将之应用于主题建模参数优化。例如,在基于LDA主题模型和Ber-topic模型的主题建模过程中,主题数目优化是模型训练中最为关键的基础问题,不同主题数目对建模效果影响巨大,实际使用过程中可以结合主题多样性、主题一致性、主题稳定性和主题离散性指标等评估指标评价建模效果并优化模型训练参数:Top2vec虽不能直接设定主题数目,但是也可以基于建模结果的各类评估指标并结合其“topic_merge_delta”参数来调整和优化最终的主题建模信息。本文的不足之处在于未构建和使用基于中文科学文献的文本预训练模型,伴随着大语言模型技术的快速发展和广泛应用,基于大语言模型技术的科学文献自动化处理技术已是大势所趋,后续需要加快实现科学文献的预训练模型研发,并将之应用于科技情报业务具体实践,这是当前的重要工作,也是未来科技情报研究的重要方向。
