视频中藏文文本的检测方法研究
2024-01-26索朗曲珍高定国李婧怡白玛旺久
索朗曲珍 高定国 李婧怡 白玛旺久





摘要:随着各种视频的增多,对于大量视频中文字的提取与监测等方面提出了更高的要求,研究视频中文字的文本检测和识别对语音文本的收集、视频监测等有重要的意义。目前视频中藏文文本的检测、识别研究还处于起步阶段,该文采用DBNet、DBNet++、PSENet、EAST、FCENet等5种基于分割的深度学习文字检测算法对视频中藏文字幕进行了检测,对比分析了5种检测算法对视频中藏文字符的检测性能。实验表明,在文字检测阶段采用的渐进式扩展算法PSENet在测试集上具有更好的检测性能,其在测试集上的准确率、召回率、F1值分别达到了0.996、0.995、0.998。
关键词:视频;藏文文本;检测
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)35-0001-05
开放科学(资源服务)标识码(OSID)
0 引言
基于深度学习的视频文字检测是指检测定位连续的视频帧中包含文字区域的位置。视频字幕中所包含的文字信息有助于理解视频,是对视频内容的解释说明。通过对视频中的文字进行检测识别来监管确保其内容积极健康,如视频画面中是否含有反动宣言等,在快速传播的信息化时代下对维护国家安全、社会稳定和推动藏文信息处理的发展具有重要意义。
目前视频中文字的检测与识别研究主要集中在英文和中文,并取得了较好的成果,但视频中藏文的检测与识别研究仍处于起步阶段,以往的研究主要针对现代印刷体、木刻版藏文古籍文本以及自然场景下的藏文进行检测和识别。视频中藏文的检测识别与自然场景下藏文的检测识别相似,但存在着一定的差异。视频中的藏文字分为场景文字和人工添加文字,人工文本虽然比自然场景中的文字更加稳定,但由于视频背景和文字实时变化、字体多样且文字的位置和大小不固定,使得文字的检测定位存在困难,于是有必要研究视频中的藏文检测与识别。
1 相关工作
目前,中英文针对视频中的文本检测识别方式主要有两方面,分别是基于单帧的文本检测和基于帧间的文本关联。基于帧间的文本关联是指通过采用视频前后帧间的文本关系来进行检测定位文本区域。对于帧间的文本关联检测方式在按照时间间隔截取视频帧时存在丢失文本区域的现象。进行帧间融合时若没有足够的帧,则文本增强效果不佳,且当使用过多的帧时会出现文本的混淆。所以帧间的文本关联检测方式适合用于模糊不清的视频文本提取。基于单帧的文本检测是指将动态视频数据处理成一帧一帧的静态图片,然后采用文本检测算法在单帧图像上检测文本区域。对于单帧检测方式适合视频质量较好的检测,且单帧的处理方式不容易使视频出现丢帧情况。由于本文实验所使用的视频数据质量较好,所以本文采用基于单帧的文本检测方式。2019年,赵星驰[1]等人针对提取视频内部自然场景及人工添加文本,使用目标检测YOLOv3与基于实例分割的文本检测PixelLink相结合的方法检测提取视频内部的场景及人工添加文本。2020年张慧宇[2]等人采用基于候选框的 CTPN 算法,对不同背景的视频文本具有较好的定位效果。2021年,常为弘[3]等人在检测阶段采用基于改进的文字检测算法CTPN,将CTPN原有的基于VGG16的特征提取网络替换为带有残差结构的特征提取网络,并在每个残差块中添加了通道注意力机制和空间注意力机制,对重要特征赋予更高的权重,实验表明,添加了残差结构和通道注意力机制的检测模型效果更佳。
目前,针对视频中藏文的检测相关研究较少,视频可以切分成连续的帧图像,关于图像中的藏文文字检测与识别的相关研究主要有,王梦锦[4]采用CTPN算法和EAST算法对藏文古籍文本进行了检测,实验表明CTPN模型比EAST模型在其藏文古籍文本测试集上检测的准确率更高,达到89%。芷香香[5]采用基于分割的文字检测算法PSENet等对多种字体的手写藏文古籍文本进行检测,并对比了不同文本检测算法对不同大小字体的文本检测效果。洪松[6]等人采用可微分的二值化网络DBNet检测自然场景下乌金体藏文,在测试集上的准确率达到89%。仁青东主[7]针对藏文古籍木刻本复杂版面特征,采用基于候选框的文本检测算法CTPN,实验结果表明,在其测试集上的准确率达到96.31%。侯闫[8]采用基于分割的可微分二值化网络DBNet检测乌金印刷多字体藏文,在其测试集上的准确率达到99.82%。李金成[9]受基于分割的思想提出一种文本实例中心区域边界扩增的文字检测网络模型,该方法在其藏汉双语场景文字检测测试数据集上准确率达到75.47%。
由上述可知,基于深度学习的文字检测算法在不同场景下藏文图像检测上取得了较好成果。本文通过参考和借鉴一些成功应用于中英文视频检测模型,开展研究藏文视频检测的任务。本文首先利用网络爬虫收集大规模藏文视频数据,并对其进行预处理和标注,在此基础上根据视频特点探究适合藏文视频文本检测的方法。本研究选用5种基于分割的深度学习文本检测算法对视频中藏文字幕进行检测定位,并评估5种算法对藏文视频文字的检测性能,最后实验分析得到适合藏文视频文字檢测的算法。
2 数据集构建
2.1 视频中藏文字的特点分析
为了有效地检测视频中的藏文字,有必要分析其特点。通常情况下,视频中的藏文字分为两种,一是视频拍摄过程中拍摄到的自然场景中的场景文字;另一种是视频制作时,被人工添加在画面特定位置的人工文字。对于人工文字进一步可细分为两种,部分文字显示设计在与对比度较大的背景之上,被称为分层人工文字;另一部分文字是直接嵌入画面中,与背景易混淆,被称为嵌入人工文字。具有以下特点:
1) 字体多样性:视频中使用的不同藏文字体间的风格差异较大,并且藏文字具有特殊性,与汉字相比在形体上从左到右的横向和上到下的叠加构成了长宽不等的二维平面文字给检测识别带来困难,尤其检测中容易漏检藏文元音符号,导致改变藏文的本意。
2) 文字不完整:对于位于视频下方滚动的藏文字幕存在模糊、背景复杂且在特定帧中出现不全等情况,这类文字的检测识别是一项极大的挑战。
3) 复杂背景:对于场景文字,由于拍摄角度的变化、物体遮挡被随机嵌入在复杂的自然背景中,给检测识别带来困难。对于人工文字,嵌入人工文字由于藏文字體本身的复杂性,且使用的字体色与背景色相似,导致其检测识别难度相较于分层人工文字具有较高的挑战性。
4) 视频模糊:视频是经过图片压缩处理的,视频帧文字具有模糊、带有虚影等增加了检测识别难度,容易出现漏检、误检。
5) 外界环境的制约:由于视频拍摄中光照不均匀、视角等因素,直接影响视频画面的质量。
本研究以复杂背景中,水平方向的藏文乌金体人工字幕为研究对象,构建了本文实验所需数据。
2.2 视频数据预处理
本采用网络爬虫技术共收集400多条藏文视频数据,每段视频的时长为24分04秒,帧率为24fps,其多样性体现在背景色、字体位置及大小、高强外界的干扰等方面。然后使用OpenCV-Python读取视频数据,在此基础上保证数据不丢失的情况下,将原始视频按照每隔10秒提取一帧图像的方法来对视频数据进行预处理操作。最后,每段视频平均得到1 490帧图像,用于视频检测识别模型所需的训练数据集,其中部分帧图片如图1所示。
2.3 数据的标注
本研究使用(VGG Image Annotator,VIA)标注工具对视频中藏文帧图像的文本区域进行标注,标注后生成JSON格式的标签文件,然后将其转化为和ICDAR2015数据集一致格式的txt文件,具体流程如图2所示。
3 视频检测方法研究
目前,基于分割的方法在场景文本检测中能够更准确地描述任意形状的场景文本。因此,本文采用以下几种基于分割的方法用于藏文视频中文字的检测定位。
3.1 DBNet算法概述
本研究采用的DBNet[10]网络结构如图3所示,在检测阶段将藏文视频帧图像输入网络后,首先通过特征提取网络ResNet-18提取图像中藏文的特征,并进行上采样融合,然后通过concat操作后生成图3中的特征图F,采用F分别预测出概率图P和阈值图T,最后由可微分的二值化算法计算出近似二值图[B],最终得到视频中藏文的检测结果。
视频中藏文检测阶段的可微分的二值化过程如式(1)所示,其中,[B]表示近似的二值图,([i,j])表示概率图中的坐标,[P]和[T]分别表示网络学习的概率图、阈值图,[k]是一个因子。式(1)之所以能提高网络整体性能,可从它的梯度反向传播来解释,定义一个[f(x)]如式(2)所示,其中[x=Pi,j-Ti,j],在使用交叉熵损失函数,将正样本的损失记为[l+],如式(3)所示,负样本的损失记为[l-],如式(4)所示。正、负样本对输入的[x]进行链式求导,得出相应的偏导数,分别为如式(5)、(6)所示。由此从微分式中可以看出,[k]是梯度增益因子,梯度对于错误预测的增益幅度很大,进而既促进在反向传播中对参数的更新,又有利于精准预测视频中藏文边缘的特征。
[Bi,j =11+e-kPi,j-Ti,j] (1)
[fx=11+e-kx] (2)
[l+=-log11+e-kx] (3)
[l-=-log1-11+e-kx] (4)
[∂l+∂x=-kfxe-kx] (5)
[∂l-∂x=kfx ] (6)
网络训练的损失函数[L]如式(7)所示,是概率图的损失[Ls]、二值图的损失[Lb]、阈值图的损失[Lt],其中[α]和[β]值分别设置为1.0和10。式(7)中的[Ls]和[Lb]使用二值交叉熵损失,如式(8)所示,其中[Sl]是经过采样的数据集,其正样和负样本的比值为1:3。[Lt]采用的是计算[Gd]内预测与标签之间[L1]的距离之和,如式(9)所示,其中,[Rd]为标注框经过偏移量[D]扩充后得到的框[Gd]里的一组像素的索引。
[L=Ls+α×Lb+β×Lt] (7)
[Ls=Lb=i∈Slyilogxi+1-yilog1-xi ] (8)
[Lt=i∈Rdy*i-x*i ] (9)
3.2 DBNet++算法概述
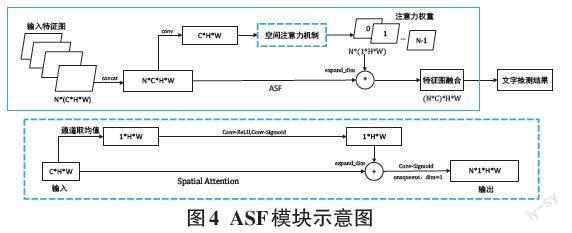
DBNet++[11]是基于DBNet的改进算法,该算法的核心是提出了自适应尺度融合模块(Adaptive Scale Fusion,ASF),如图4所示。首先,金字塔特征图上采样到相同大小,然后输入ASF模块中,对经过尺度缩放的特征图进行concat,再经过3×3卷积,获得中间特征S,并对其采用空间注意力机制(attention)。最后,注意力权重[A∈RN×H×W]分别与输入的特征图对应相乘后再concat得到ASF的输出,很好地考虑了不同尺度特征图的重要性,使得DBNet++模型具有更强的尺度鲁棒能力,尤其是对本文大尺度的视频文本目标更鲁棒,但藏文元音符号出现较严重的漏检。
3.3 PSENet算法概述
PSENet[12]网络的整体框架如图5所示,该算法首先采用主干网络ResNet50[13]提取n个通道特征图,其次,使用函数来将低级纹理特征和高级语义特征相融合,并映射到F,此时促进了不同尺度的内核生产。然后产生了n个不同尺度的分割结果,其中最小尺度的分割结果是整个文本实例的中心位置,而最大尺度的分割结果是文本实例的完整形状。最后使用渐进式扩展算法(PSENet),首先将最小内核的分割结果通过连通分析形成不同连通域,进而确定各种实例的中心位置,其次,通过广度优先算法合并相邻像素逐渐扩展到最大尺度分割结果,对于合并间存在冲突像素,采用先到先得的策略,从而获得最终的藏文视频检测结果。
3.4 EAST算法概述
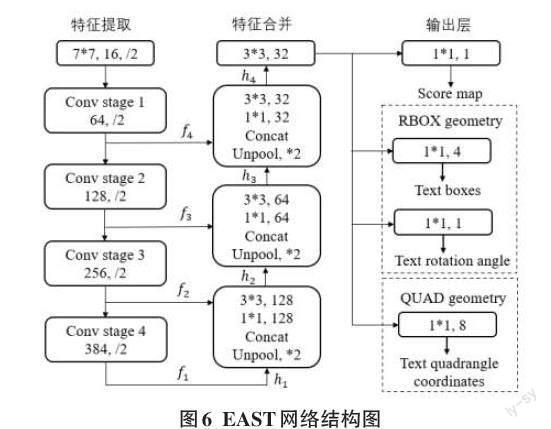
EAST[13]网络结构如图6所示,该算法只包含两个阶段,分别是全卷积网络(Fully Convolutional Networks,FCN)和非极大值抑制(Non-Maximum Suppression,NMS)。首先将视频帧图像送到FCN网络结构中,由PVANet提取输入图像特征,并生成单通道像素级的文本分数特征图(score map)和多通道几何图形特征图(geometry map),再使用上采样、张量连接、卷积操作进行特征合并,之后输出部分直接产生文本框预测。文本区域采用了两种几何形状:旋转框(RBOX)和水平(QUAD),分别设计了不同的损失函数。然后采用阈值过滤几何,其中评分超过预定阈值的几何形状被认为有效,并将生成的文本预测框经过非极大值抑制(NMS)筛选,产生最终结果。
本文在视频藏文检测阶段采用EAST网络原始的损失函数,如式(10)所示,其中,[Ls]表示分类损失、[Lg]表示几何损失、[λg]表示两个损失的重要性,在本文实验中将其设置为1.0。[Ls]表达式如式(11)所示,其中[Y]是score map的预测值,[Y*]是Ground Truth真实标签,参数[β]是每一张帧图像的正样本和负样本的平衡因子,其公式如式(12)所示。
[L=Ls+λgLg] (10)
[Ls=balanced-xentY,Y* =-βY*logY-1-β1-Y*log(1-Y)] (11)
[β=1-y*∈Y*y*Y*] (12)
由于文本在视频场景中的尺度变化较大,因此本文在RBOX回归的AABB部分采用原网络中使用的[IoU]损失,其[Lg]表达式如式(13)所示,其中,[LAABB]和旋转角度损失计算公式分别如式(14)、(15)所示。当几何图是QUAD时,对其采用尺度归一化的[smoothedL1]损失函数,其损失值如式(16)所示,其中[NQ*]是四边形的短边长度,其表达式如式(17)所示,从而保证文本尺度变化的稳定性。
[Lg=LAABB+λθLθ] (13)
[LAABB=-logIoUR,R*=-logR∩R*R∪R*] (14)
[Lθθ,θ*=1-cosθ-θ* ] (15)
[Lg=LQUADQ,Q* =minQ∈PQ*ci∈CQ,ci∈CQsmoothedL1ci-ci8×NQ*] (16)
[NQ*=mini=1,2,3,4DPi,Pi mod 4+1] (17)
3.5 FCENet算法概述
FCENet[14]算法提出了傅里葉轮廓嵌入(Fourier Contour Embedding,FCE)方法来将任意形状的文本轮廓表示为紧凑的傅里叶特征向量。该网络结构由可变形卷积的残差网络模型作为特征提取层(backbone- ResNet50_DCN)[15]、特征金字塔网络FPN[16]作为neck层来提取多尺度特征、FCE作为head层。其中,head层分为分类分支和回归分支。分类分支用来预测文本区域和文本中心区域。回归分支用来预测文本的傅里叶特征向量,并将其输入反向傅里叶变换进行文本轮廓点序列的重建,最后通过非最大值抑制(NMS)获得最终的视频文本检测。
4 实验结果与分析
4.1 实验环境
本文检测网络训练的硬件环境为CPU: Intel®CoreTMi9-9900K、GPU:NVIDIA GeForce RTX 2080Ti,内存:24GB,软件环境为Ubuntu 20.04+cuda11.8+Python3.8+PyTorch1.12.1。
4.2 评价指标
为了评估不同算法的性能,本文采用准确率(Precision)、召回率(Recall)、F1值(H-mean)、帧速率(FPS)4个指标对视频中藏文帧图像的文本区域检测结果进行评价。
4.3 视频中藏文文本的检测
本文视频藏文文本检测实验中,首先对数据预处理得到的2 752帧图像进行去重操作,共得到878帧实验所需数据,并将数据按照8∶1∶1随机分为训练集、验证集、测试集。在此基础上对比基于分割的DBNet、DBNet++、EAST、FCENet文字检测算法与本文所采用的渐进式扩展算法PSENet在视频中藏文的检测效果。其中检测效果如图7所示,图(a)为DBNet检测效果,图(b)为EAST检测效果,图(c)为FCENet检测效果,图(d)为DBNet++检测效果,图(e)为PSENet检测效果。在测试集上的结果如表1所示。
从图7和表1中可以看出,DBNet算法在单一背景下检测效果较好,但对于复杂花色的背景下检测效果不佳,而DBNet++网络在复杂背景下能检测定位到文本区域的4个坐标点,故所检测的准确率也高,但整体相比DBNet严重出现了藏文元音符号的漏检,进而易改变藏文本意。EAST算法在检测视频中相对较长文本行时存在较严重的漏检,且会生成多余的检测框并重叠在一起,不适合用于检测视频场景的文字。FCENet检测算法能够有效检测视频中较小尺度的字幕,但由于视频文字的位置和大小不固定,对于检测较大尺度的文字易出现漏检。本文采用的渐进式扩展算法PSENet既有效解决对于视频中复杂背景、大小不固定的藏文字幕检测,又可有效检测藏文元音符号,在准确率、召回率、F1值上都达到99%以上。
5 总结与展望
为研究藏语视频中出现的文字信息,对其检测定位是前提任务。本文通过分析视频本身的特点及检测难点,采用5种基于分割的文字检测算法用于藏文视频字幕的检测。在人工收集的藏文视频数据集上进行初步实验,实验结果表明,基于分割的渐进式扩展算法PSENet在藏文视频文字检测中具有较好的效果,其准确率、召回率、F1值都达到99%以上,证明该方法在藏文视频文字检测中具有可行性。同时,通过分析实验结果在后续研究中需要进一步开展不同位置、多字体以及复杂背景下藏文视频场景文字的研究。
参考文献:
[1] 赵星驰.基于深度学习的视频文字检测技术[D].北京:北京邮电大学,2019.
[2] 张慧宇.广电视频文字检测与识别的研究[D].郑州:郑州大学,2020.
[3] 常为弘.视频中的文字检测识别算法的研究与实现[D].成都:电子科技大学,2021.
[4] 王梦锦.基于深度学习的藏文古籍文献文本检测研究[D].拉萨:西藏大学,2020.
[5] 芷香香,高定国.手写多字体藏文古籍文本检测方法研究[J].高原科学研究,2022,6(2):89-101.
[6] 洪松,高定国,三排才让,等.自然场景下乌金体藏文的检测与识别[J].计算机系统应用,2021,30(12):332-338.
[7] 仁青东主.基于深度学习的藏文古籍木刻本文字识别研究[D].拉萨:西藏大学,2021.
[8] 侯闫,高定国,高红梅.乌金印刷多字体藏文的文本检测与识别[J].计算机工程与设计,2023,44(4):1058-1065.
[9] 李金成.藏汉双语自然场景文字检测与识别系统[D].兰州:西北民族大学,2021.
[10] LIAO M H,WAN Z Y,YAO C,et al.Real-time scene text detection with differentiable binarization[J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):11474-11481.
[11] LIAO M H,ZOU Z S,WAN Z Y,et al.Real-time scene text detection with differentiable binarization and adaptive scale fusion[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(1):919-931.
[12] WANG W H,XIE E Z,LI X,et al.Shape robust text detection with progressive scale expansion network[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach,CA,USA.IEEE,2019:9328-9337.
[13] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas,NV,USA.IEEE,2016:770-778.
[14] ZHOU X Y,YAO C,WEN H,et al.EAST:an efficient and accurate scene text detector[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu,HI,USA.IEEE,2017:2642-2651.
[15] ZHU Y Q,CHEN J Y,LIANG L Y,et al.Fourier contour embedding for arbitrary-shaped text detection[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Nashville,TN,USA.IEEE,2021:3122-3130.
[16] ZHU X Z,HU H,LIN S,et al.Deformable ConvNets V2:more deformable,better results[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach,CA,USA.IEEE,2019:9300-9308.
[17] LIN T Y,DOLLÁR P,GIRSHICK R,et al.Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu,HI,USA.IEEE,2017:936-944.
【通聯编辑:唐一东】
