基于ArcPy的地名地址和POI数据判重实现
2023-12-13彭莲香王龙秀郭星涛肖雄
彭莲香 王龙秀 郭星涛 肖雄


[关键词] ArcPy;判重;天地图;地名地址和POI;近邻表
地理信息公共服务平台(天地图)是自然资源部主导建设的网络化地理信息公共服务平台,由国家、省、市三级节点构成,目的是将天地图作为大数据对外提供公益性、基础性服务的统一出口,提高测绘地理信息公共服务能力和水平,为政府、企业、公众等用户提供权威、标准、统一的在线地理信息服务。为实现跨层级(国家、省、市)的数据查询、统计分析等应用需求,国家主节点于2013年利用数据融合手段开始节点同构工作,通过整合国家、省、市各级节点的数据资源,提高天地图各级节点数据的现势性,丰富数据内容。融合的数据类型包括矢量数据、地名地址和POI数据、影像数据。按照主节点的数据融合处理要求和验收标准,地名地址和POI数据中不能出现重复的数据,本文将结合作者实际生产过程对地名地址和POI数据的判重进行深入探讨。
地名地址和POI数据基于母库数据,利用本省基础测绘、最新地理国情监测、市级节点数据、国家下发的最新导航数据进行更新。因涉及的数据来源多样、生产标准不一致、数据分类和属性不统一、总体数据量大、覆盖范围广,通过人工逐条去筛选判重既费时又费力而且不可避免地会出现遗漏,很不现实。郑佩燕[1]、付治河[2]、赵秋菊[3]对判重处理的原理进行了论述。徐凤英[4]提到“判别重复,删除相似度大于80%的数据,保留更完整数据”,但没有具体说明相似度如何计算的。王银花[5]首先采用名称字段挂接筛选出名称完全重复的点,然后利用FME构建模糊查询模块筛选名称不完全一致的情况。刘芙蓉[6]将重复点出现的情况分为(1)位置名称完全一致;(2)名称相同位置有偏差的;(3)位置和名称都存在差异三种情况,前两种情况利用空间分析解决,第三种也同样利用FME构建名称模糊匹配模块进行查重。张庆全提出用程序完成名称完全一致、名称不完全一致但意思一致2种地名重复情况的处理思路,但对具体程序实现未进行详细说明[7]。利用ArcPy进行判重处理的研究较少,本文将探讨利用ArcPy进行判重的思路和具体实现,为批量输出地名地址和POI判重结果提供一种思路。
1. 技术路线与实现
1.1 Python 介绍Python 是一种不受局限、跨平台的开源编程语言,具有简单易学、开源免费、可移植性强,而且具有丰富的扩展库,具有强大的图形处理、数学处理、文本处理、表格处理、多媒体处理等模块,广泛使用于web开发、爬虫、云计算、人工智能、科学运算等领域,是目前最流行的程序设计语言之一。
1.2 ArcPy 介绍
ArcGIS 9.0 社区中引入了Python。此后,Python被视为可供地理处理用户选择的脚本语言并得以不断发展。ArcPy是从ArcGIS 10版本后推出的一个以成功的arcgisscripting 模块为基础并继承了arcgiss?cripting 功能进而构建而成的站点包。站点包是Py?thon 术语,表示用于将附加函数添加到Python 中的庫,而ArcPy站点包则用于将GIS函数添加到Python中的库。ArcPy 站点包随ArcGIS 一起安装。采用新的ArcPy命名空间取代arcgisscripting命名空间,可通过引用ArcPy站点包直接调用其提供的一系列方法、类和模块,主要由制图模块(arcpy.mapping)、数据访问模块(arcpy.da)、空间分析模块及扩展模块(arcpy.sa)和基本函数功能组成[8],可实现地理数据分析、数据转换、数据管理和地理自动化创建。使用以ArcPy编写的ArcGIS应用程序和脚本的优势在于,可以访问并使用由来自多个不同领域的GIS专业人员和程序员开发的大量Python模块[9]。
1.3 技术路线分析
2020年内蒙古自治区天地图地名地址和POI数据融合的数据源包括省级节点本地数据和天地图国家主节点下发数据两部分。前者包括内蒙古自治区地理国情监测数据(2019年)、市级节点地名地址和兴趣点数据;后者包括导航地名地址与兴趣点数据(2020年春)、国家母库地名地址与兴趣点数据。按照《天地图数据融合技术要求(2020)》,融合不同来源数据,得到全区70多万条地名地址和POI数据成果。地名地址和POI 数据中包括ELEMID(唯一标识码)、NAME(名称)、LON(经度)、LAT(纬度)、ADDRESS(地址)、TELEPHONE(电话)、TYPE2018(类型编码)等字段。
70多万条地名地址和POI 的重复点处理是一项繁琐且令人头大的工作,采用ArcGIS 软件的工具和人工结合的方式常常耗时长且不可避免地出现遗漏。为解决这一问题,笔者利用ArcPy 和Python,分盟市按照地名地址和POI的类型编码分情况判断NAME、ADDRESS、TELEPHONE 和点之间的距离,分别进行相同判重和相似判重,然后人工按照判重结果进行重复点处理。
相同判重包括四种情况:1)NAME、ADDRESS、TELEPHONE都相同;2)仅NAME、ADDRESS 相同;3)仅NAME、TELEPHONE 相同;4)仅NAME 相同。对于学校、医院、单位(博物馆、科技馆、电视台、图书馆、政府及管理机构、公检法等)及乡镇以上行政地名等类型的数据,不限定判重距离,其他类型的数据判重距离设定为1.5km。
相似判重是指NAME、ADDRESS、TELEPHONE都互不完全相同,但是可通过两个点的NAME得到相似度。判重距离设定为1.5km。
判重距离可根据实际情况设定,设置的距离越大生成判重结果中的干扰项会越多,距离设置小会出现判重不够彻底的情况。
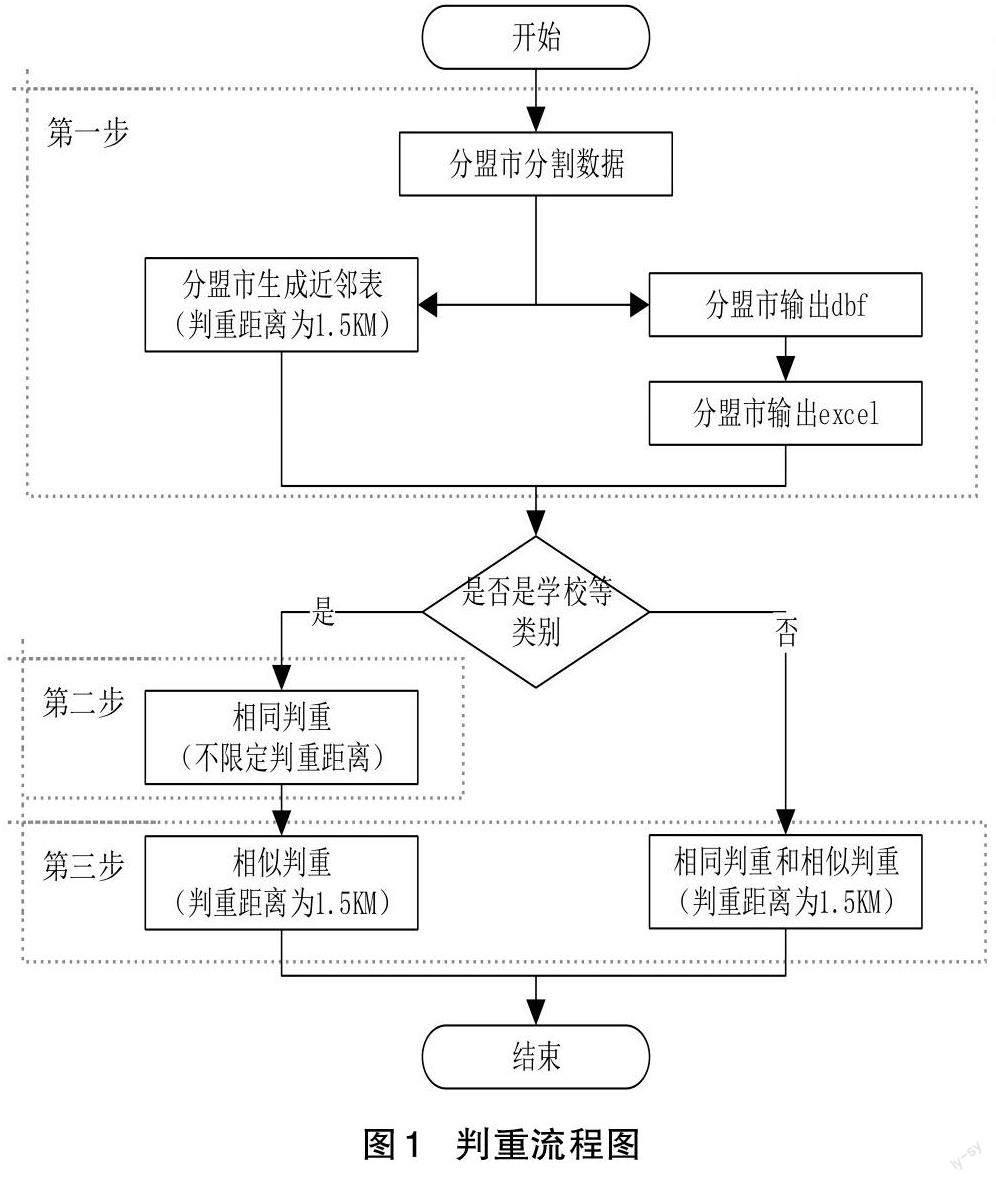
判重实现详细步骤如图1,可大体分成三步:
1.因全区数据庞大,将数据按照盟市进行分割,分盟市进行判重;
2.分盟市按判重距离1.5km生成近邻表;
3. 分盟市导出dbf(只保留ELEMID、NAME、TYPE2018、ADDRESS、TELEPHONE、LON、LAT 等与判重相关的字段),然后分盟市导出Excel表。
4.判断数据类型,若为学校、医院、单位(博物馆、科技馆、电视台、图书馆、政府及管理机构、公检法等)及乡镇以上行政地名等类型的数据,相同判重不限定判重距离,否则相同判重距离设定为1.5km。所有数据的相似判重距离均为1.5km。
5.相同判重分盟市输出相同判重结果,分别对应相同判重的1)、2)、3)、4)中情况将判重结果分别存放于repeat_poi_name_address_phone. txt、repeat_poi_name_address. txt、repeat_poi_name_phone. txt、re?peat_poi_name_coordinate(1.5km).txt。
6.相似判重分盟市输出相似判重结果。按照相似度区间90%~100%、80%~90%、70%~80%、65%~70%、60%~65%、分别将判重结果存放于poi_match_result_90_100. txt、poi_match_result_80_90. txt、poi_match_result_70_80. txt、poi_match_result_65_70.txt、poi_match_result_60_65.txt。
7.根据判重结果,人工处理数据。
1.4 具体实现
1.4.1 程序使用的Python扩展库
本程序使用的Python 扩展库及相应的函数如表1:
1.4.2 程序使用的ArcPy类及函数
本程序使用的ArcPy类及函数如表2:
1.5 实现效果
1.5.1 判重结果目录结构
判重结果按盟市输出,分别存放在以盟市命名的文件夹中,每个盟市的文件中包括10个txt,前5个为相似判重结果,后5个为相同判重结果,如图2:
1.5.2 相同判重结果示例
相同判重结果结构如图3。以repeat_poi_name_address.txt的判重结果为例,如图4,3行为一组判重结果,表示唯一码ELEMID1和ELEMID2的两个点距离小于1.5 km,并且名称和地址完全相同。第一行是表示两个点的ELEMID,第二行表示点1对应的属性信息,第三行表示点2对应的属性信息。
1.5.3 相似判重结果示例
相似判重结果结构如图5。以poi_match_result_90_100.txt的判重结果为例,如图6,5行为一组判重结果,表示唯一码ELEMID1和ELEMID2的两个点距离小于1.5km,并且名称的相似度区间处于90%~100%之间。第一行是表示两个点的ELEMID,第二行表示点1对应的属性信息,第三行表示点2对应的属性信息,第四行表示两点之间的距离,第五行表示两点之间的相似度。
1.5.4 运行时间统计
笔者工作站配置为16 核32 线程、128G 内存、512G固态硬盘、P5000显卡,安装ArcGIS 10.2,补充了64位GP处理模块,利用64位Python 2.7.3编写程序,对全区70多万条地名地址和POI数据进行测试,列举以下盟市各个步骤的运行时间,如表3。可以直观地看出,一是近邻表的条目数巨大,普遍达到千万级,甚至超过亿,比如乌兰察布数据条目有5万余条,近邻表达到了8千万余条;赤峰数据条目有8万余条,近邻表达到了1亿余条,利用Python多线程模块可在第二步、第三步中实现对大数据量近邻表的查询处理,充分利用工作站资源,快速输出结果,可避免程序运行时间过长或者报错得不到完整结果的问题;二是程序的运行时间虽然与数据条目数有关,但是主要取决于近邻表中的条目数,而这跟地名地址和POI数据的密集程度有关,比如,包头和锡林郭勒盟的数据条目数均约7万条,但锡林郭勒盟的近邻表仅8千万余条,因包头数据分布密度高,其近邻表达到近2亿条,程序总运行时间也是锡林郭勒盟的2倍多。
2. 结语
在大数据量的情况下,手动检查的人工成本较高,效率低且易出错[10],而已有的文献中,分情况采用空间分析或者FME模块处理的方法不能一次性输出判重结果,为解决这些问题,笔者利用ArcPy和Python编写程序综合考虑相同判重和相似判重的情况,利用多线程模块优化程序,实现大数据量的判重结果的自动输出,应用于实际生产中,能解决判重结果批量输出的问题。但是后续还需要人工辅助完成判重处理,这也需要一定的工作量,怎么快速的处理判重结果,彻底释放人工,还需要进行下一步深入的研究。
