集成电路产业的多源数据融合前沿识别研究
2023-11-10张倩
张倩
(北京市科学技术研究院,北京 100089)
0 引言
科学技术的发展日新月异,是推动当今社会生产力发展的主要因素,因此有效识别重要领域的研究前沿和新兴技术显得尤为重要,应该做到及时性、准确性和全面性,从而为国家科技战略决策提供有力支撑。
本文结合情报研究方法和其他学科研究方法,将多个数据源进行融合处理,即通过不同渠道、多种采集方式获取的具有不同数据结构的信息汇聚到一起,形成具有统一格式、面向多种应用的数据集合[1]。采用多源数据融合分析识别研究前沿是当前情报学领域的研究重点,做到准确有效地把握研究前沿,能够为政府及企业相关部门制定科技政策和战略部提供更加全面的决策依据和参考[2-3]。
1 文献研究
广义的研究前沿包括了引起世界科学家高度关注的对未解的科学问题所做的种种探索并取得的重大突破和进步;面对未解决的问题、难点问题,目前正在进行的科技前沿的探索;当前或有限时间范围内的前沿方向[4-6]。可以看出广义的研究前沿识别不单单关注于某一具备高被引特征的单一实体或静态关系,而更加强调了不同实体间的动态关系,通过建立数据模型系统,深入挖掘不同实体间的深层含义和关联,从而快速准确地识别出当前该领域最具发展潜力的主题。
早期对于研究前沿的研究主要采用定性分析,汇集研究领域专家学者的意见,逐步总结出该领域的研究前沿与技术发展趋势。随着互联网技术的发展和科技文献的指数倍增长,便产生了基于文本挖掘的定量分析方法。根据原理和数据模型不同,可以分为基于引文、词汇、主题和基于融合的四类研究前沿识别方法。
冯佳[4]等通过建立载体-特征-关系融合模型,提出关注度、新颖度和中心度3 个识别指标,丰富了基于多源数据融合的研究前沿识别方法。邢颖等[7]以 SWOT分析方法为框架,利用专利文献、论文文献、行业标准反映研究主题的优势和劣势,提高了研究框架的科学性。张英杰[8]认为科学前沿探测方法是一系列特征探测方法的综合,他提出了两种针对科学前沿探测中出现的低频现象的探测思路,一种是构建主题词网络,结合社会网络分析法的结构指标来揭示主题的前沿演变过程;另一种则是基于相关离群点的理论。中国工程科技2035发展战略研究项目组[9]编著的《中国工程科技2035 发展战略研究》中应用了当前技术态势扫描、技术清单制定、德尔福调查、技术路线图绘制等技术预见手段,提高了研究结果的前瞻性、科学性和规范性。Blei D M等[10]提出,采用基于词汇的研究前沿识别方法包括共词分析、词频分析和爆发词探测。其中共词分析能够有效反映出研究领域各关键词汇间的共现强度,与其他定量分析法结合使用,有助于准确识别研究前沿[10]。大数据分析与情报分析具有很强的共性,化柏林等[11-13]通过构建智能情报分析系统实现了情报需求智能感知,海量信息智能获取,多源信息动态融合、多维关联综合分析、分析结果智能解读、报告自动生成等功能。
研究证明,采用多源数据融合分析方法能够实现数据间的相互补充和交叉证明,以确保分析结果的准确性和客观性。构建多源数据分析模型,对行业数据去冗分类,去粗取精,采用大数据分析与情报分析相结合的方法,实现对指数级增长的专利、文献、科技资讯、产业政策、研究报告等多源异构文本进行深入融合处理,不同形式的信息相互补充,全面多角度地挖掘研究前沿。
2 数据融合模型构建
2.1 实验的平台框架与计算环境
多源数据融合的多领域数据综合分析平台基于Spring Boot 框架进行开发,将采集到的数据经过数据格式适配、抽取、分析,存入Neo4j 数据库。同时,基于eCharts 和jQuery 等前端框架开发数据分析与检索可视化系统,对从Neo4j 中检索到的数据进行可视化展示。
在多源数据融合分析平台中,Spring Boot 主要用作项目骨架,衔接各应用模块和Neo4j 数据库,实现离线数据处理流程。同时对外提供Rest 风格的访问接口,提供数据给前端可视化呈现模块。
2.2 系统架构与数据处理流程
多源数据分析系统架构从下到上可以分为:数据层、抽取层、图谱层、算法层及展示层[14]。其中数据层负责对采集到的多源数据进行格式适配、类型转换、数据清洗;抽取层负责在预处理后的数据基础上,抽取并封装知识图谱实体、属性和关系;图谱层负责对封装后的数据进行持久化;算法层负责在Neo4j 图数据库提供的算子基础上,根据综合分析平台的数据分析需要,实现特定的分析算法,如共词统计算法、关键词词频统计算法、数据报表统计算法等。最终由展示层对分析结果和图谱数据进行可视化。数据处理流程如图1 所示,可分为离线的数据分析处理流程及在线的数据可视化呈现两部分。
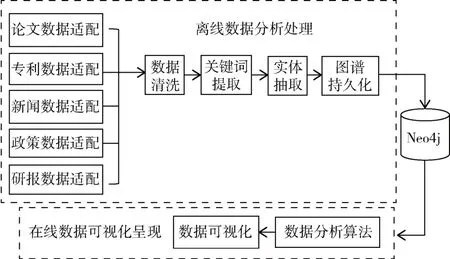
图1 数据处理流程
其中,离线的数据分析处理流程负责对采集到的数据进行适配、格式转换、数据清洗,进而借助分词算法对文本进行分词和词频、逆文档频率统计,从而提取出候选关键词;依据候选关键词,对数据的文本内容进行进一步的关键词匹配,从而将不同来源的数据分别封装为不同类型的实体,并与国家、机构、个人、关键词等实体建立管理,形成知识图谱,持久化存储到Neo4j 中。
在Neo4j 图数据库中包含两种基本的数据类型:Nodes(节点)和Relationships(关系)。Nodes 和Relationships 还可以包含key/value 形式的属性。Nodes 通过Relationships 所定义的关系相连起来,形成关系型网络结构,如图2 所示。
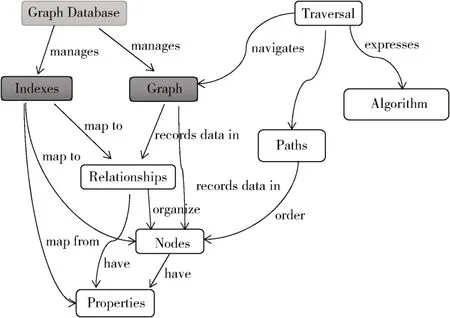
图2 Neo4j 图数据库结构图
数据源包括专利、论文、产业政策、科技资讯、研究报告。专利数据库主要以Orbit(https://www.orbit.com)数据库为主,采集的信息包括:标题、摘要、公开(公告)号、公开(公告)日期、发明人、权利人、国别等。中文文献数据库以知网(https://www.cnki.net)为主,外文数据库选取Web of Science(WOS,http://www.webofknowledge.com/)数据库为主,采集的信息包括:论文标题、作者、单位、出版年份、期刊/会议、关键词和摘要等。新闻和政策数据以人工筛选的集成电路领域12 个权威行业网站为主,辅以35 个微信公众号;研报数据源于万德和慧博数据库,提取的内容包括研报标题、研报摘要、研报作者、所在机构等。
2.3 数据采集范围及方式
对上述5 类数据,采用人工与爬虫相结合的方法进行采集,具体采集过程描述如下:
(1)在进行数据采集前,人工给出10 个中英文领域关键词,用于在文献、专利、研报等数据源中进行检索,以确定数据采集范围。检索关键词如表1 所示。
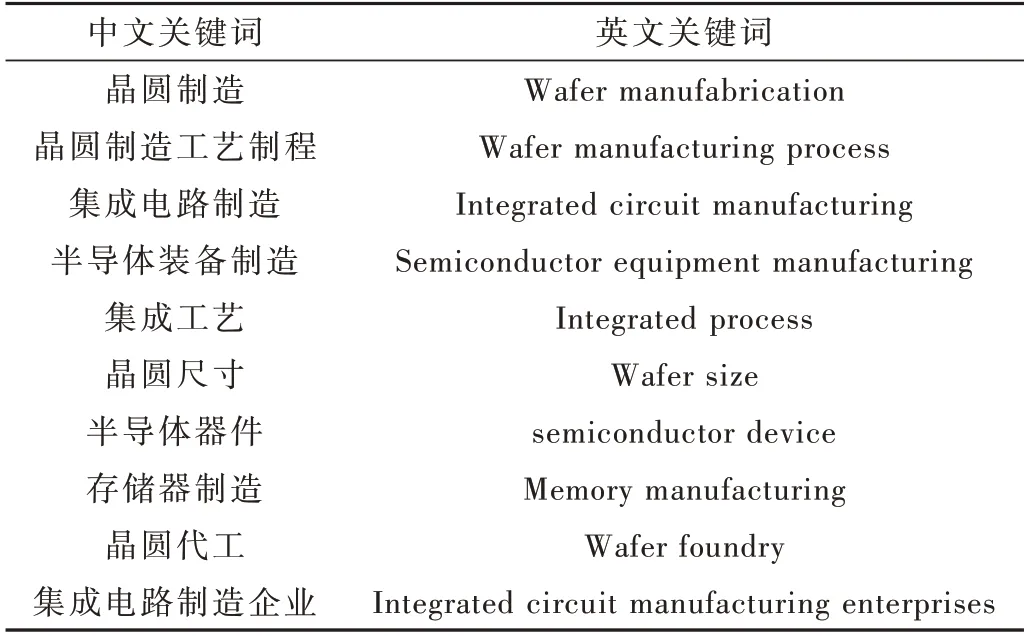
表1 IC 制造领域检索关键词列表
(2)对检索得到的数据条目,采用爬虫(主要针对新闻咨询)和人工(针对专利及文献)相结合的方式进行数据采集。检索时间为2012 年1 月1 日至2022 年12 月31 日。
2.4 动态关键词词频统计算法
研究领域前沿技术识别运用到动态关键词词频统计TF-IDF 算法(Term Frequency-Inverse Document Fre-quency,词频-逆文档频率算法),TF 仅衡量词的出现频次,IDF 强调词的区分能力。该算法首先筛选指定数据范围(起止时间、数据集、TOPN、语言、领域等)内的文档,然后逐个文档提取关键词,计算关键词的对数词频和逆文档频率数据,计算TF-IDF,将TF-IDF 排名前N(N≤100)个关键词输出。算法模型如公式(1)所示:
其中,词频(Term Frequency,TF)指的是某一个给定的词语在该文件中出现的频率。分子是该词nij在某一条文本数据中的出现次数,而分母则是在某一条文本数据中所有字词的出现次数之和。
其中,逆向文件频率(IDF)是一个词语普遍重要性的度量,|D|是数据集中的文本数据总数,|j:{ti∈di}|表示包含词语ti的数据数目。如果该词语不在数据集中,就会导致分母为零,因此一般情况下使用式(3)来计算IDF。
最后,将TF 与IDF 相乘,即可得到TF-IDF 权重,如式(4)所示。
由此可以得到数据中的某个词在整个数据集中作为关键词的权重。将所有关键词的权重由高到低排列,最终识别研究领域前沿技术。
3 实验结果
3.1 样本采集规模
本研究选取高精尖产业中的集成电路制造领域作为分析对象,利用多源数据融合分析模型对结构化和非结构化的数据分析处理,集成电路制造领域数据采集规模如图3 所示。

图3 数据采集规模
采集得到的数据,经过数据清洗、去重、实体关系抽取,形成图谱中的实体。本实验提取了包含专利、文献等五类数据源实体以及关键词、机构、个人等在内的关联实体。图谱的实体规模如表2 所示。从图谱规模上,总的实体数量超过260 万。

表2 图谱实体规模
3.2 研究前沿识别
从前沿识别结果中抽取排名靠前的的关键技术和研究领域如表3 所示。结果表明:近十年来集成电路领域前沿关键技术包括双扩散金属氧化物半导体场效应晶体管、横向绝缘栅双极晶体管、电流源型逆变器、射流电沉积、GAA FET、铁电场效应晶体管、新型存储器、4H-碳化硅双极晶体管、FD-SOI 等。
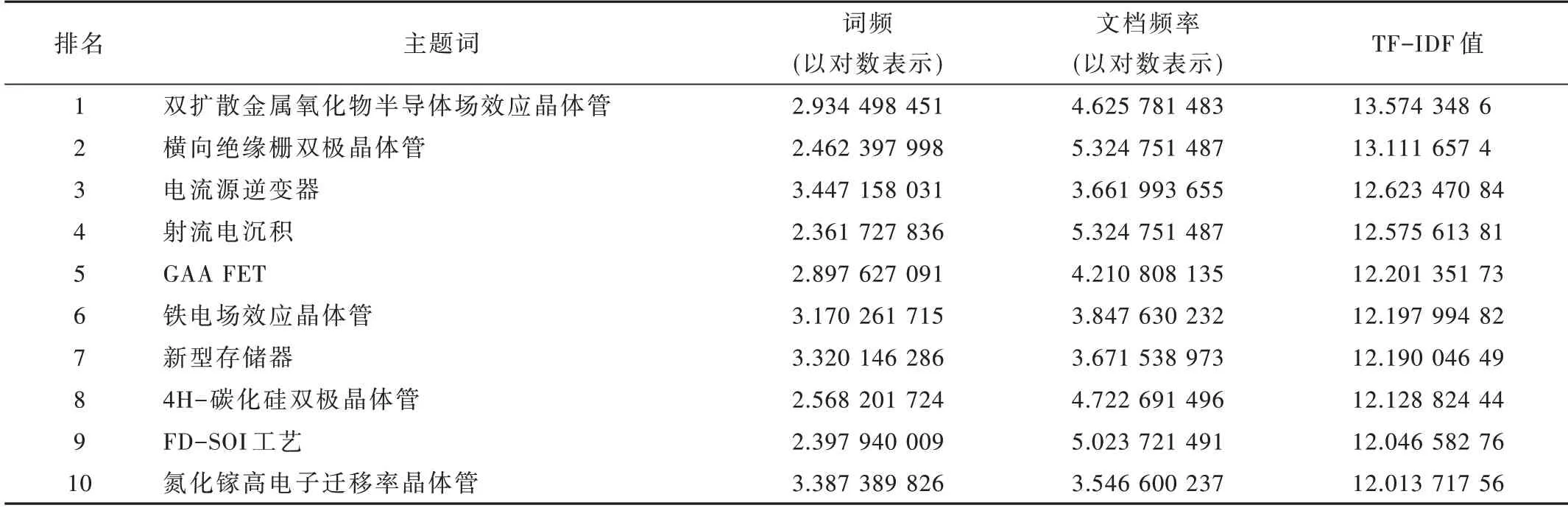
表3 关键技术TF-IDF值
利用多源数据融合模型中的专利分析部分,可以得到全球集成电路技术领先企业的专利分布情况,前10大主要申请人中,第一名是三星电子,第二名是ASML,第三名是Intel,其他依次是高通、台积电、瑞萨电子、SEIKO、SK 海力士等。
在主要申请人国家中,有3 名美国企业,2 名韩国企业,3 名日本企业,而中国集成电路制造龙头企业中芯国际没有入围,说明美韩等国家在集成电路领域已经形成“领头羊”效应,技术集中且优势明显。而我国专利的竞争力及创新性有待提高。集成电路高端产品的国产化率仍然较低,亟需加快技术创新,投入资金继续开展创新研发。
美国“芯片法案”与“四方联盟”背景下,中国半导体国产化迫在眉睫。研究发现当前全球在该领域的研究热点和重点发展方向集中在半导体制造设备、高制程制造技术上,重点产品集中在高端芯片、功率器件、传感器、存储器以及第三代半导体的相关产品上,与当前我国半导体技术和产业的发展方向相符。在未来一段时期,中国集成电路产业应注重加强关键技术研发及重点产品的突破,有针对性地制定各项政策措施,推动产业从以前的“以加工为主”转向“以产品为中心”的产业发展模式[15]。
4 结论
本文借助多源数据融合方法针对集成电路领域进行研究前沿识别分析,实验数据源除了以往研究中常见的期刊文献和专利文献外,还增加了研究领域的研报、政策和行业新闻数据,从而使分析结果更加全面。不足之处在于因受到国外行业网站的访问限制,数据源中未加入国外行业新闻数据。希望本文的前沿识别结果为政府与企业提供有价值的决策支持和参考。
