网络实验室虚假数据注入攻击深度识别仿真
2023-10-29魏枫林
魏枫林,王 凯
(吉林大学计算机科学与技术学院,吉林 长春 130012)
1 引言
现代通信、网络以及计算机等相关技术的飞速发展,信息技术的应用领域也不断扩大。网络实验室是一种范围较大且复杂度较高的实时系统,主要涉及计算机科学以及控制理论等多个不同的学科。虽然国内的网络实验室起步比较晚,但是在相关领域专家的重视下,网络实验室的研究取得了较好的成绩,尤其是网络安全方面[1,2]。现阶段,国内相关专家针对网络攻击数据识别方面的内容也进行了大量研究,例如张超群等人[3]将人工标注网络日志数据作为研究对象,对LSTM网络分类模型进行训练,将经过转化处理的数据输入到LSTM网络中进行分类,最终实现网络攻击识别。王小英等人[4]引入关联规则算法组建隐蔽目标识别模型,同时组建目标识别总体框架,通过APT目标的相关属性对各个网络威胁之间的关联规则进行计算,提取目标档案数据,最终根据可信度实现网络威胁隐蔽目标识别。
基于上述两种已有方法的实现过程,提出一种网络实验室虚假数据注入攻击深度识别方法。经实验测试可知,所提方法可以全面降低计算开销、存储开销以及能量消耗,有效提升识别率。
2 方法
2.1 网络实验室虚假数据注入攻击预处理
由于实验室网络中包含大量数据,对网络实验室虚拟数据注入攻击识别会耗费大量的时间,同时计算过程也十分复杂,因此需要优先对虚假数据注入攻击进行预处理,有效降低识别时间。
通过小波阈值去噪方法[5,6]处理虚假数据注入攻击行为,详细的操作步骤如下所示:
1)优先确定网络实验室虚假数据的分解层数,具体的计算式为
c=lgl-5
(1)
式中,c代表网络实验虚假数据的分解层数;l代表虚假数据的总数。
利用式(2)给出虚假数据的信噪比计算式
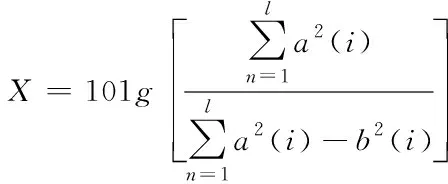
(2)
式中,X代表信噪比;a2(i)代表含有噪声的信号;b2(i)代表原始信号。
虚假数据的均方根误差可以表示为式(3)的形式

(3)
式中,J代表虚假数据的均方根误差;n代表原始虚假数据。
2)根据选定的阈值,可以对各个尺度的虚假数据对应的分解系数进行处理。
3)在识别网络实验室虚假数据注入攻击过程中,需要确保识别结果的准确性,同时还需要对欺骗性的数据进行分析。在上述基础上,对虚假数据进行重构,实现网络实验室虚假数据注入攻击预处理[7,8]。
2.2 虚假数据注入攻击深度识别模型
由于新型虚假数据注入攻击具有很强的欺骗性,攻击识别的首要任务是确保识别精度。对于网络实验室数据而言,需要对虚假数据的输入攻击机理进行分析,将数据样本划分为正常实验室数据和受到攻击的网络实验室数据,进而组建含有标签的正负数据样本,采用机器学习的分类方法对识别模型进行训练。同时根据挖掘数据之间的关系,可以全面识别结果的准确性以及稳定性。其中,机器学习的攻击识别机理如下所示:
1)如果给定含有攻击前后的正负的网络实验室虚假数据,则有
S={si},i={1,2,…,n}
(4)

(5)
网络实验室虚假数据注入攻击的识别问题可以表示为以下形式
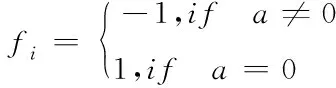
(6)
利用图1给出基于机器学习的虚假数据注入攻击深度识别流程图:

图1 虚假数据注入攻击深度识别流程图
为了确保识别结果的精度[9,10],在识别特征数据集的基础上,采用机器学习对二分类问题进行处理,同时通过监督学习的方式,将决策树算法和梯度提升框架进行迭代组合。决策树是一种有效的机器学习模型,需要将相同的虚假数据划分至相同的节点,采用递归学习的方式对网络实验数据虚假数据进行分割,同时在每次划分的过程中获取最优分割点,不断降低下一层分割的误差。同时可以被应用于处理大部分的分类回归任务中。
设定现阶段含有n个网络实验室数据样本,则构建的虚假数据注入攻击数据集G可以表示为式(7)的形式
G={(x1,x2),(x2,x2),…,(xn,xn)}
(7)
式中,(xn,xn)代表攻击数据集的子集。
通过式(8)计算损失函数
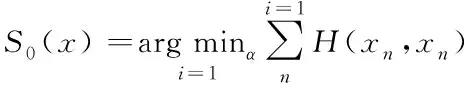
(8)
式中,S0(x)代表损失函数;H(xn,xn)代表错误样本出现的概率。
当得到损失函数以及初始化基学习器后,需要不断进行迭代,模型的每一次提升是在上一代模型的损失函数的基础上降低残差取值,组建精度更高的分类器,直至满足迭代需求,详细的操作步骤如下所示:
1)设定迭代次数为x,则对应极小值方向的残差为

(9)
式中,cim代表残差;(xi,yi)代表数据子集的坐标位置。
2)将式(9)获取的残差设定为输入,获取决策树叶节点区域Qm
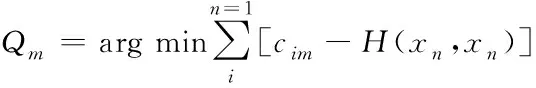
(10)
3)求解损失函数在梯度下降方向的最优步长,同时将损失函数进行极小值化处理。
4)组建分类精度更高的弱分类器模型[11,12],同时设定学习率的取值范围,有效避免模型出现过分拟合的情况。
5)迭代结束,通过多个高准确性的弱分类器组合获取最终梯度提升决策树模型Fbest(i),具体的表达形式为
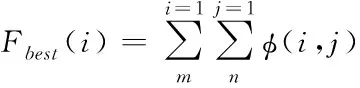
(11)
式中,φ(i,j)代表弱分类器总数。
当完成对模型的训练之后,可以计算网络实验室受到攻击和未受到攻击的概率,如式(12)所示
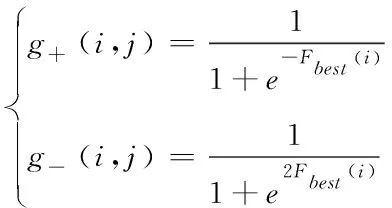
(12)
式中,g+(i,j)和g-(i,j)分别代表网络实验室受到攻击和未受到攻击的概率。
通过以上分析,通过决策树算法和梯度提升框架构建虚假数据注入攻击深度识别模型S(i,j),如式(13)所示

(13)
2.3 模型参数优化及虚假数据注入攻击深度识别
果蝇优化算法[13,14]是一种获取全局最优的方法,果蝇可以更好地通过嗅觉器官感受空气中的不同气味,通过气味获取事物所在的位置,同时朝着该方向飞行。
通过果蝇对食物进行搜索,以下给出果蝇算法的详细操作步骤:
1)设定种群规模,同时还需要设定最大迭代次数,对各个果蝇个体位置进行初始化处理。
2)各个果蝇个体进行食物搜索,将果蝇和食物之间的距离称为搜索距离,详细的计算式为
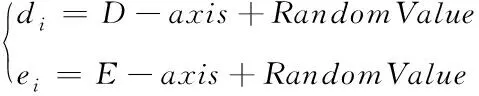
(14)
式中,di和ei代表果蝇个体的坐标位置;D-axis和E-axis分别代表不同果蝇个体的搜索长度;RandomValue代表搜索距离。
3)由于无法直接获取事物的准确坐标位置,需要计算目标和原始两者之间的距离,同时计算最新位置的味道浓度判定值pi,具体计算式为
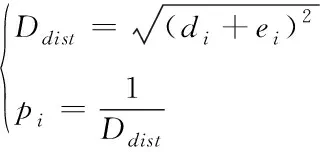
(15)
式中,Ddist代表距离倒数。
4)通过步骤3)获取的味道浓度判定值求解不同果蝇个体的味道浓度值。
5)获取群体中味道浓度最佳的个体。
6)记录并保存最佳味道浓度值,同时确定果蝇最终飞去的方向。
7)进行迭代寻优,同时重复以上操作步骤,直至满足设定需求;反之,则跳转至步骤6)。
由于基本果蝇算法的收敛速度比较慢,且收敛精度比较低,为此,需要对其进行改进,提出一种自适应混沌果蝇优化算法,详细的操作步骤如图2所示。
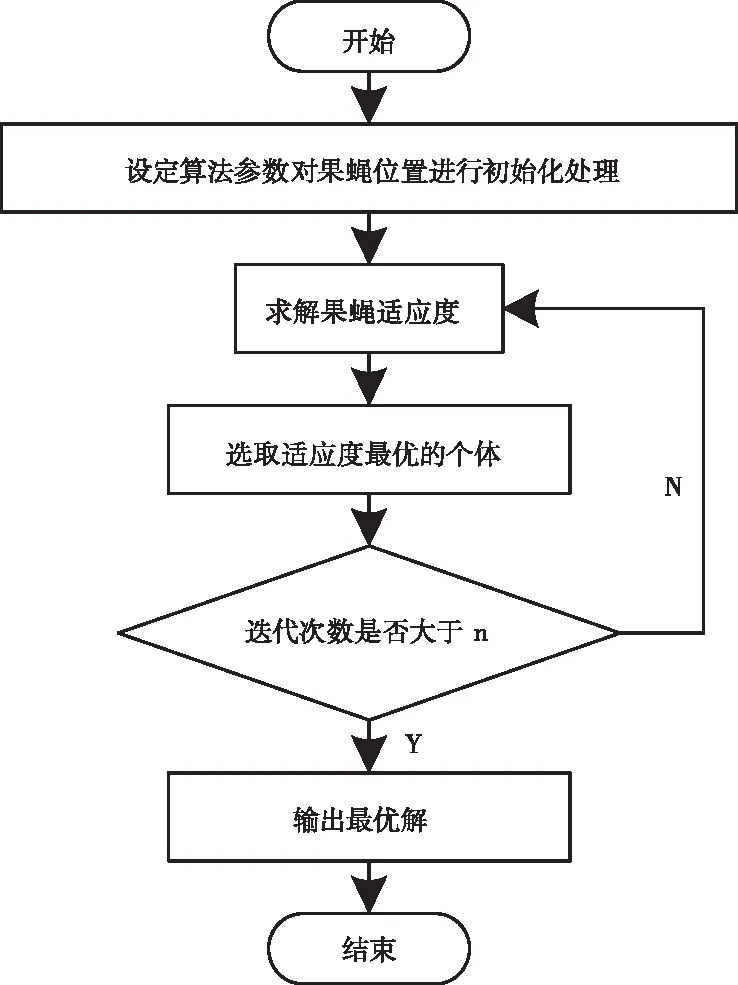
图2 自适应混沌果蝇优化算法操作流程图
1)对算法中的各个参数进行设定,同时群体中不同果蝇个体位置进行初始化处理,则果蝇的初始位置如式(16)所示
c(i,j)=rand(up)
(16)
式中,c(i,j)代表果蝇的初始坐标位置;rand(up)代表果蝇的坐标位置范围。
2)给定群体中各个果蝇的飞行方位以及具体间距,则果蝇个体的最新位置可以表示为式(17)的形式
Xin=c(i,j)*rand(up)*w
(17)
式中,w代表果蝇个体的权重值。
3)计算不同群体中不同果蝇个体的味道浓度。
4)选取群体中最佳味道浓度个体的果蝇个体,同时保存并记录果蝇的浓度取值以及对应的坐标位置,如式(18)所示
pbest=min(pi)
(18)
式中,pbest代表最佳果蝇味道浓度。
5)持续保持最佳浓度值以及果蝇的坐标位置,果蝇群体通过视觉搜索向目标位置飞行。
6)将多个种群的最优解进行对比,进而获取此次迭代的最优解,同时和前一次的最优解进行对比,最终得到全局最优解,实现虚假数据注入攻击深度识别模型参数优化处理。
当完成识别模型的参数优化后,进行虚假数据注入攻击深度识别,详细的操作步骤为:
1)将经过预处理的虚假数据注入攻击输入到模型中,提取虚假数据注入攻击的主要特征,同时进行映射处理。
2)将经过模型处理的结果输入到池化层中,同时将数据划分为多个不同重复的区域,将各个区域的虚假数据进行聚合[15]。
3)重复上述操作步骤,同时将步骤2)中获取的聚合结果输入到网络结构中,通过虚拟数据的更新门以及重置门得到全新的虚假数据注入攻击训练数据集。
4)根据输出的识别结果,完成虚假数据注入攻击深度识别。
3 仿真研究
为验证所提网络实验室虚假数据注入攻击深度识别方法的有效性,设计仿真实现方法的性能测试。
1)存储开销测试
在网络实验室运行阶段,会进行数据存储,以下实验测试主要分析不同方法的节点存储开销,详细的实验测试结果如表1所示。
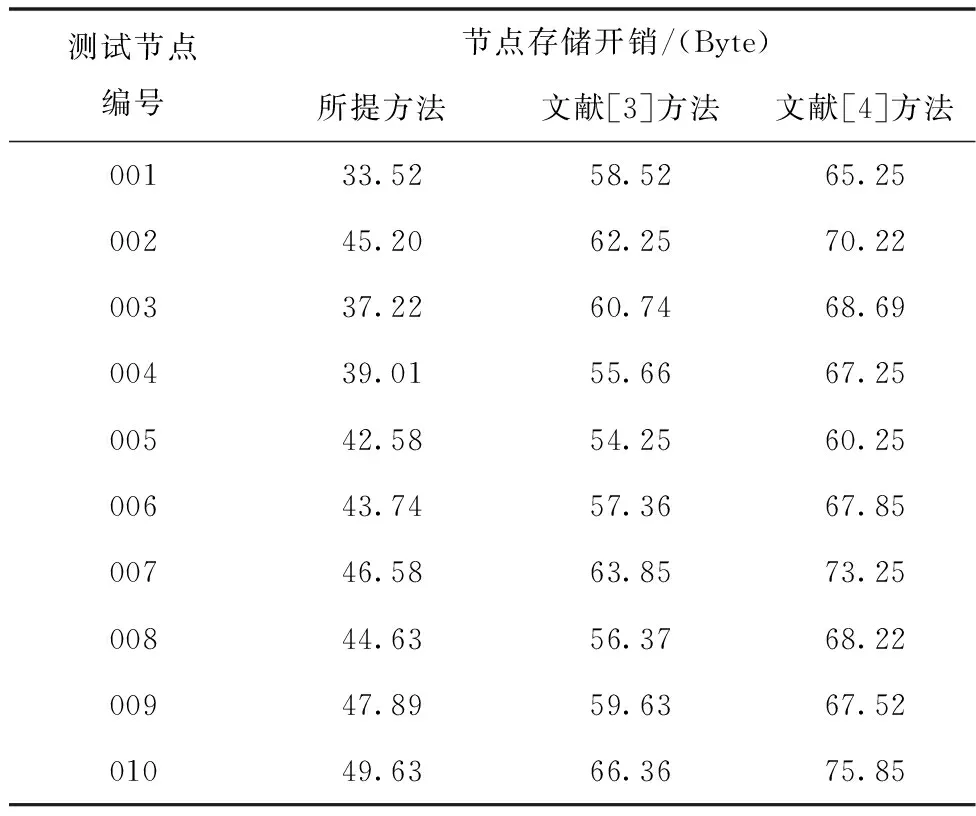
表1 不同方法的存储开销对比结果
由表1中的实验数据可知,相比另外两种方法,所提方法的存储开销明显更低一些。这主要是因为所提方法对网络实验室虚假数据注入攻击进行预处理,可以有效滤除数据中的噪声,同时简化操作流程,促使所提方法的存储开销得到有效降低。
2)计算开销测试
由于不同方法的操作步骤完全不同,导致方法的计算开销也存在十分明显的差异,以下实验测试进一步对比三种不同方法的计算开销,详细的实验测试结果如图3所示:
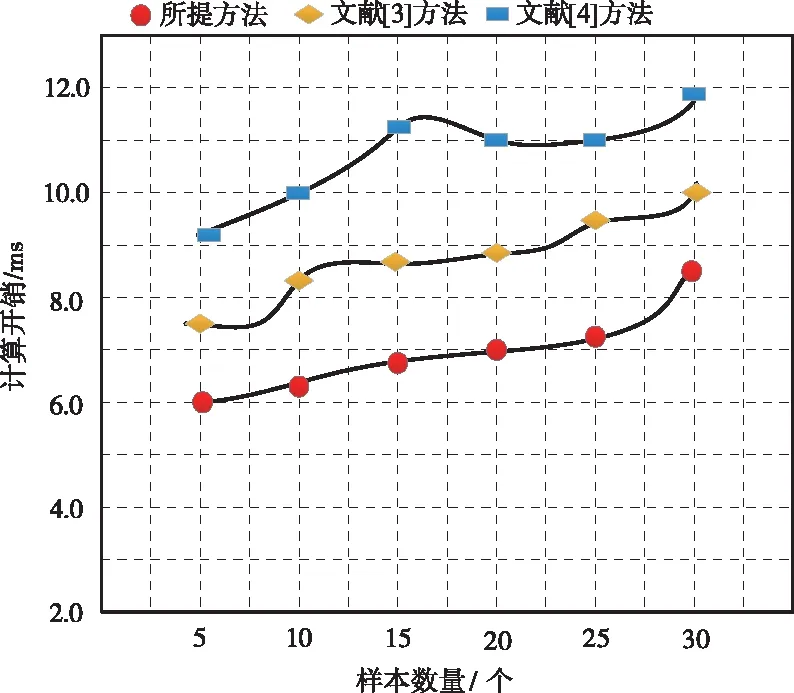
图3 不同方法的计算开销测试结果对比
分析图3中的实验数据可知,各个方法的计算开销会随着测试样本的增加而增加。其中,所提方法的计算开销在三种方法中为最低;文献[3]方法的计算开销次之;而文献[4]方法的计算开销最高。由此可见,所提方法可以以更快的速度完成网络实验室虚假数据注入攻击深度识别。
3)能量消耗测试
分析在不同虚假数据包数量持续增加情况下,三种方法的能量消耗情况,详细的实验测试结果如图4所示:

图4 不同方法的能量消耗情况测试结果对比
分析图4中的实验数据可知,当虚假数据包数量增加,各个方法的能量消耗也开始持续增加。但是相比另外两种方法,所提方法的能量消耗明显更低一些。
4)虚假数据注入攻击深度识别率测试
为了进一步验证所提方法的优越性,以下实验测试对比三种不同方法的虚假数据注入攻击深度识别率,如图5所示:

图5 不同方法的虚假数据注入攻击深度识别率测试结果对比
分析图5中的实验数据可知,所提方法可以以更大的率实现虚假数据注入攻击深度识别,全面验证了所提方法的优越性。
4 结束语
针对传统实验室网络攻击识别方法存在的一系列问题,设计并提出一种网络实验室虚假数据注入攻击深度识别方法。经实验测试证明,所提方法可以有效降低计算开销、存储开销和能量消耗,提升识别率,获取更加满意的识别结果。
在现有方法的基础上,后续将进一步对其进行完善,全面完善所提方法的各方面性能。
