粗精选策略二进制灰狼优化算法用于红外光谱特征选择
2023-10-09李忠兵蒋川东梁海波段洪名
李忠兵,蒋川东,梁海波,段洪名,庞 微
1. 油气藏地质及开发工程国家重点实验室(西南石油大学),四川 成都 610500 2. 西南石油大学电气信息学院,四川 成都 610500 3. 西南石油大学机电工程学院,四川 成都 610500
引 言
红外光谱作为一种无损、低成本、快捷的分析检测技术,已被广泛用于食品检测、生物制药及油气勘探光谱等领域[1]。红外光谱中包含有大量冗余信息[2],在建立定量或定性分析模型之前,需要进行一定的光谱预处理以及特征提取,提高模型的预测能力和稳健性[3]。
随着化学计量学的不断发展完善,以自然界生物的一些生活习性为参考的算法,如遗传算法(GA)[4]、粒子群优化算法(PSO)[5]、灰狼优化算法(GWO)[6-7]等,已成为目前特征提取研究的热点。此类算法的最大特点是通过生物的遗传、信息共享、等级制度等手段来较好地保留变量间的组合优势,但计算量大,模型易受到适应度函数的影响。
群体智能优化算法中的灰狼优化(grey wolf optimizer,GWO)是Mirjalili受大灰狼捕食策略的启发,于2014年提出的一种元启发式算法[8],主要模拟了自然界中灰狼搜索、包围和攻击猎物的习性以及群狼作战的能力。相比于其他启发式算法过多的参数设置,GWO算法只需要预设狼群数量和迭代次数两个参数,并且模型结构简单,收敛较快,在求解优化问题上具有很好的局部搜索能力和求解精度,受到研究者的广泛关注[9-12]。但是原始的GWO算法适用于连续的目标函数,对于特征提取的离散应用不足,因此Emary等[13]于2016年提出一种二进制灰狼优化(bGWO)算法,使其能够满足二进制空间上的特征提取要求。卞希慧等[14]将灰狼优化算法用于玉米光谱的特征提取,实验论证了模型受狼群数量和迭代次数的影响,并验证了模型的有效性与推广的可能;江潇潇[6]等提出了非线性自适应收敛因子提高bGWO算法的全局和局部搜索能力,与二进制粒子群算法(bPSO)做了对比,仿真验证了模型对于目标跟踪节点选择任务的精度和实时性;Sallam等[15]提出了新的变异策略改进灰狼优化算法,并与模拟退火算法结合,在32个数据集上验证了所提算法分类的准确率;El-Shahat等[16]提出了两阶段变异的思想改进灰狼优化算法的迭代过程,命名为TMGWO,在35个数据集上与其他智能算法作了比较,验证了模型的优越性。
目前应用二进制灰狼优化算法对红外光谱数据进行特征提取并实现定性分析的研究已有大量报道,而用于红外光谱定量分析的研究还相对较少,尤其是针对同系有机物气体的红外光谱。本研究使用粗精选策略及非线性收敛因子来改进二进制灰狼优化算法,以光谱定量分析模型返回的交叉验证均方根误差(RMSECV)平均值作为适应度函数,采用α狼设计了快速收敛策略,在所采集的烷烃气体红外光谱数据集上讨论了狼群数量对模型的影响以及模型的快速寻优能力,并与bGWO和bPSO算法作了比较验证了本研究中模型的精度。
1 实验部分
1.1 红外光谱数据集
待测实验样品由满足国家标准GB/T5274.1—2018浓度为5%的正丁烷、10%的异丁烷、4%的异戊烷和100%的甲烷、乙烷、丙烷、二氧化碳的标气(中国大连,大连大特)作为样气,以氮气作为背景气,输入到LFIX-7000混合配气系统(中国成都,莱峰,混合误差为标准气体浓度的±1%,1%=10 000 ppm)进行混合配比形成。混合配气系统输出的样品气体以1 000 mL·min-1的流量经MD-070-24F-4091119-02干燥管(Perma Pure-US)除湿后进入容积为400 mL、有效光程长为4.8 m的PMG10030光程池(中国上海,荧飒),光程池外部套有恒温装置,由温度控制单元控制该恒温装置使光程池内部温度恒定在27.5 ℃。通过计算机控制红外光谱仪Bruker ALPHA Ⅱ(德国)采集得到波数区间为2 000~6 500 cm-1,波数分辨率为1 cm-1的红外光谱数据,共359组数据,红外光谱曲线如图1所示。其中横轴表示波数,纵轴表示红外吸光度。
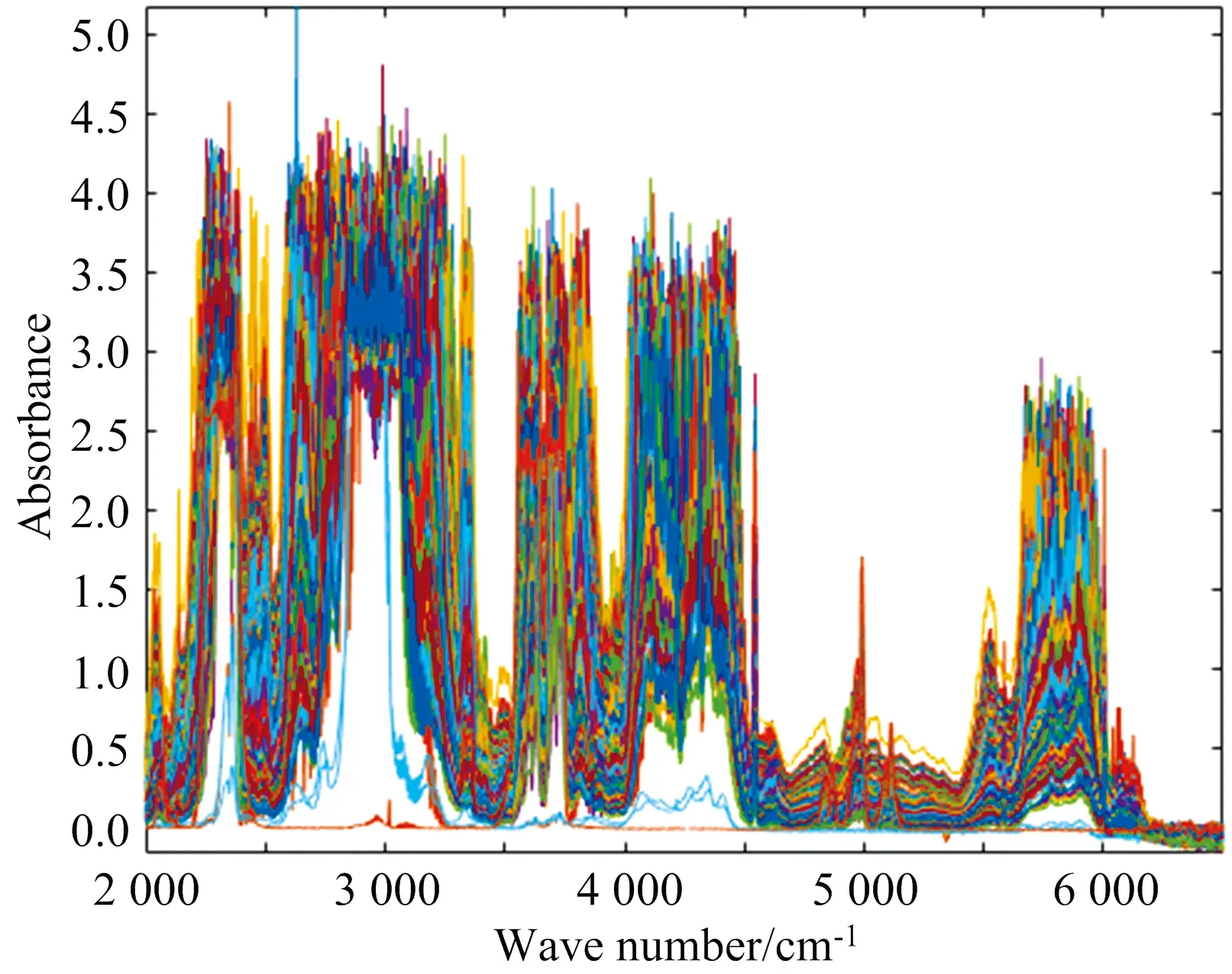
图1 七组分数据集中359个混合样品的原始红外光谱Fig.1 The original infrared spectra of 359 mixed samples in seven-component data set
实验得到的红外光谱数据集是在氮气(N2)背景下,由甲烷(C1)、乙烷(C2)、丙烷(C3)、正丁烷(nC4)、异丁烷(iC4)、异戊烷(iC5)和二氧化碳(CO2)七组分气体采用随机方式按式(1)要求配比的混合气体的实验数据集。其中C1、C2、C3、CO2浓度范围为0~100%,nC4、iC4、iC5浓度范围为0~3%。
(1)
式(1)中,n为组分个数,ci为目标浓度,λi为标气浓度。
1.2 评价指标
定量分析模型均采用均方根误差(RMSEP)、决定系数(R2)和相对预测偏差(RPD)作为评价指标,计算公式分别如式(2)、式(3)和式(4)所示
(2)
(3)
(4)
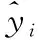
2 算法原理
2.1 灰狼优化算法
灰狼优化算法借鉴了狼群的金字塔等级制度和捕食猎物的生活习性。其中第一层头狼为α狼,被视为优化问题的最优解;第二和第三层为β狼和δ狼,起到承上启下的作用,被视为次优解;最底层的是ω狼,必须听命于前三层狼群的引导,完成靠近、包围和猎食等行为,最终达到捕食猎物的目的,即找到全局最优解。根据灰狼靠近猎物的行为建立的数学模型为式(5)和式(6)
(5)
(6)
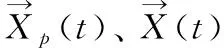
(7)
(8)
(9)
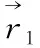
然而,由于未知的环境下不可能事先知道猎物的位置信息,因此建立数学模型时认为α狼、β狼和δ狼对猎物位置有更好的判断,以这三头狼的位置信息来引导剩余狼群的位置更新,进而完成包围和猎食的行为,其公式表示为
(10)
(11)
(12)
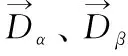
2.2 粗精选策略二进制灰狼优化算法
在二进制空间中,灰狼状态只能选择或不选择特征之间相互转化,因此需要可行的映射函数将其转化到二进制空间。采用式(13)和式(14)将sigmoid函数的连续搜索空间转换为二进制搜索空间,来确定最终是否选择该波长位置作为特征波长,见式(13)和式(14):
(13)
(14)
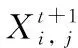
在原始GWO中,位置更新方程中三只领头狼为每只狼生成一个新位置虽具有良好的搜索猎物能力,但由于一直基于全局进行寻优,导致这种方式的GWO算法收敛缓慢,并且迭代结束不一定能够获取到可行的解。因此提出粗精选策略二进制灰狼优化(RSBGWO)算法,并采用非线性收敛因子,以便加快收敛速度并保持优秀的全局寻优能力。粗精选策略二进制灰狼优化算法流程如图2所示。
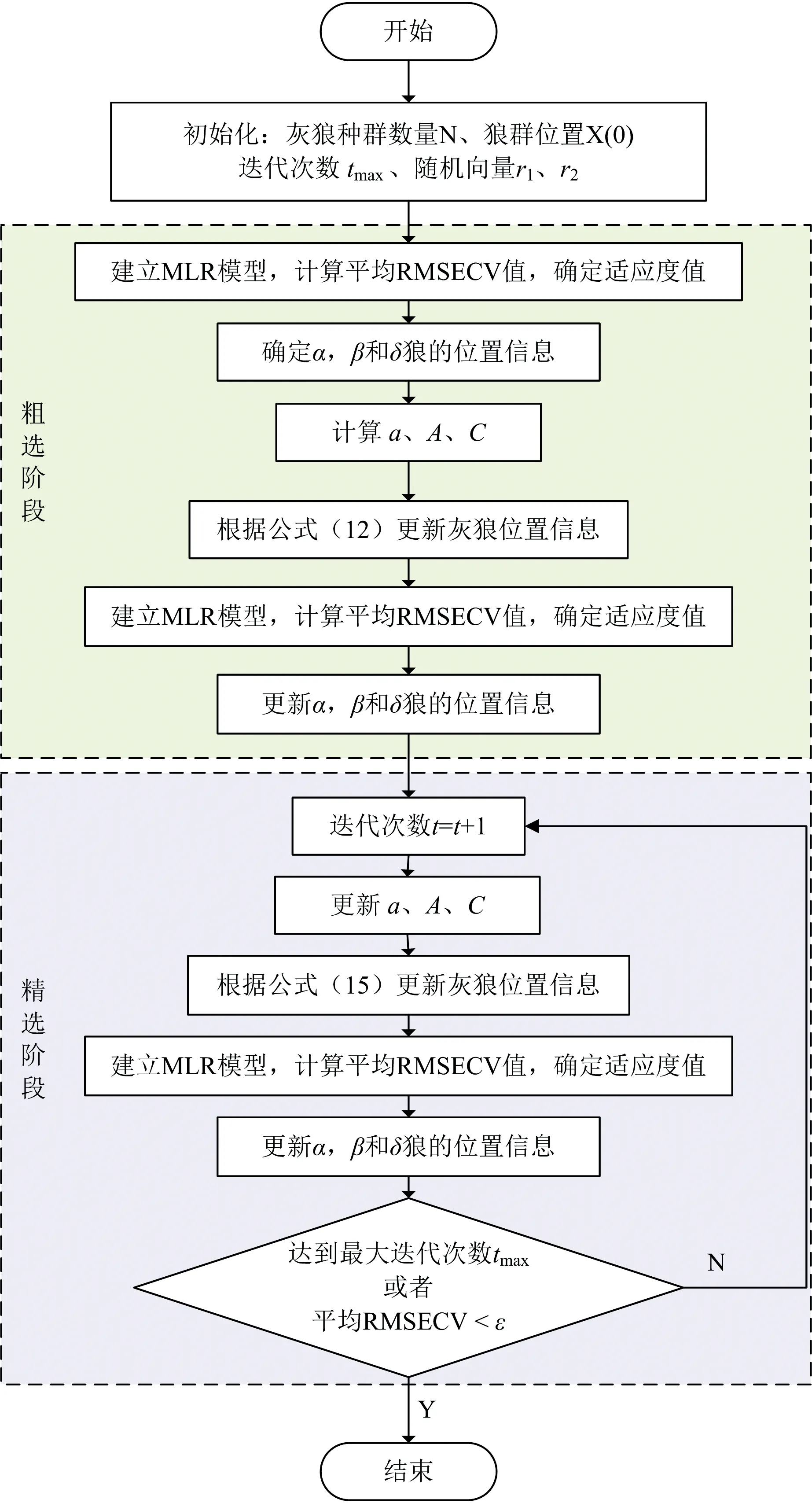
图2 粗精选策略二进制灰狼优化算法流程图Fig.2 Flow chart of binary grey wolf optimization algorithm for rough selection and fine selection strategy
首先,初始化灰狼数量为N,并为每只灰狼生成一个元素为0或1的随机向量用于确定每只狼的初始特征变量,以此来获得狼群对于全局探索更充分的位置信息。每只狼表示一个可能的解决方案,并且其维度等于原始数据的维度。粗选阶段,基于每只灰狼的初始特征变量建立相应的MLR模型,找到最小的三个RMSECV值所在的狼作为α、β、δ狼的初始位置。根据式(12)进行全局第一次迭代,更新所有灰狼的特征变量。根据各自新的特征变量建立MLR模型,同样找到最小的三个RMSECV值所在的狼更新α、β、δ狼的位置。
为了加快收敛速度,区别于原始GWO算法,使α狼未选中的特征变量不参与迭代更新过程,本文构造了式(15)进行狼群位置信息的更新:
(15)
式(15)中,S为α狼所选特征变量位置信息,由元素0、1组成,1表示该位置特征为α狼选中特征,0表示未选中。
精选阶段,只在α狼所选特征变量位置的基础上,结合β和δ狼对应α所选特征变量的位置信息,根据式(15)更新所有灰狼的特征变量,并根据各自新的特征变量建立的MLR模型,找到最小的三个RMSECV值。与更新前的三个RMSECV值进行比较,若更小,则更新α、β、δ狼的位置。重复上述过程直到迭代结束或者满足定量分析精度ε结束。
粗精选策略会使迭代中α狼选择的特征变量逐渐减少,所建立的新MLR模型返回的RMSECV值也逐渐减小,以此找到最合适的全局特征变量来建立最优的定量分析模型。
迭代过程中,为了提高算法的搜索速度,在有限次数迭代中找到最优解,以非线性自适应收敛因子来替代原算法中的线性收敛因子,如式(16)所示:
(16)
3 结果与讨论
首先对原始数据进行预处理并剔除部分异常数据,采用KS算法[17]先将数据集按照9∶1的比例划分为初始训练集和测试集。使用K-fold交叉验证[18]将初始训练集进一步分为训练集和验证集,循环建模10次并以10次定量分析模型的RMSECV平均值作为适应度函数值进行模型迭代,选取具有最小RMSECV值的特征波长,建立最优定量分析模型。所有实验只对混合气体中的C1、C2、C3、CO2组分进行了建模分析,均视nC4、iC4、iC5为干扰组分。
3.1 RSBGWO模型训练
当光谱数据维度较大时,直接进行定量建模需要很长的时间,对模型精度也有很大影响。采用RSBGWO算法降低光谱数据的维度,并合理地选择狼群数量,可以有效提高建模速度。
图3为不同狼群数量对于甲烷寻优过程及结果的影响。可以看出狼群数量对算法的寻优能力有很大影响,对于C1,在相同的迭代次数下达到最小的RMSECV值与设置的狼群数量多或少并非正相关关系,较少的狼群数量反而可能会达到最小的RMSECV值。当狼群中灰狼数量为20时,对应的RMSECV值已经低于混合配气系统误差(标准气体浓度的±1%)。当迭代次数超过200,灰狼数量为20时,MLR模型获得了最小的RMSECV值。因此,C1灰狼数量可以设置为20。通过实验,C2、C3和CO2的灰狼数量分别设置为20、40、20。
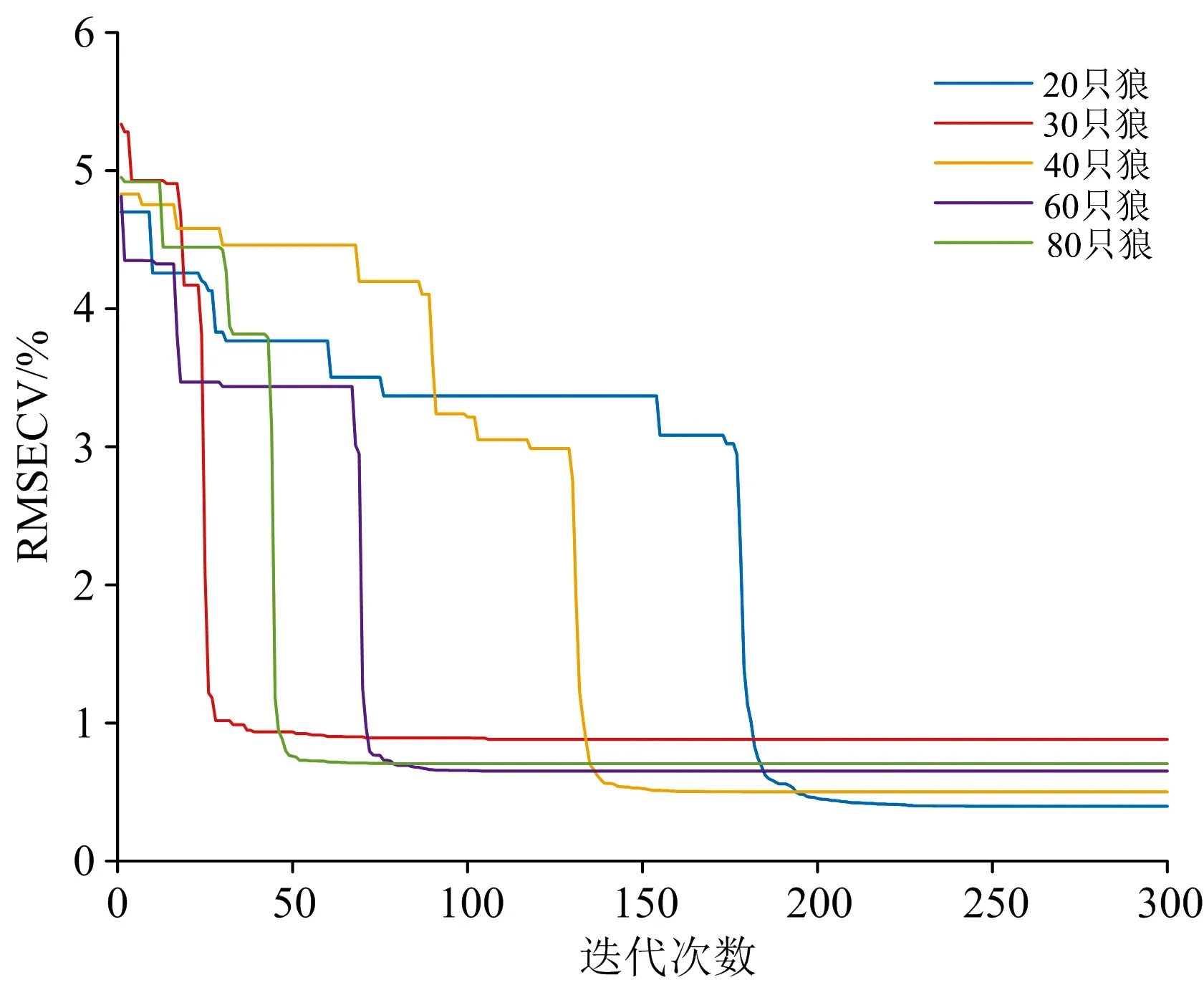
图3 不同狼群数量对于甲烷寻优过程及结果的影响Fig.3 Effects of different wolf populations on optimization process and results
为了验证模型的稳定性,对各物质在最优狼群数量下分别做了10次重复实验,图4为C1的10次重复实验迭代寻优结果。
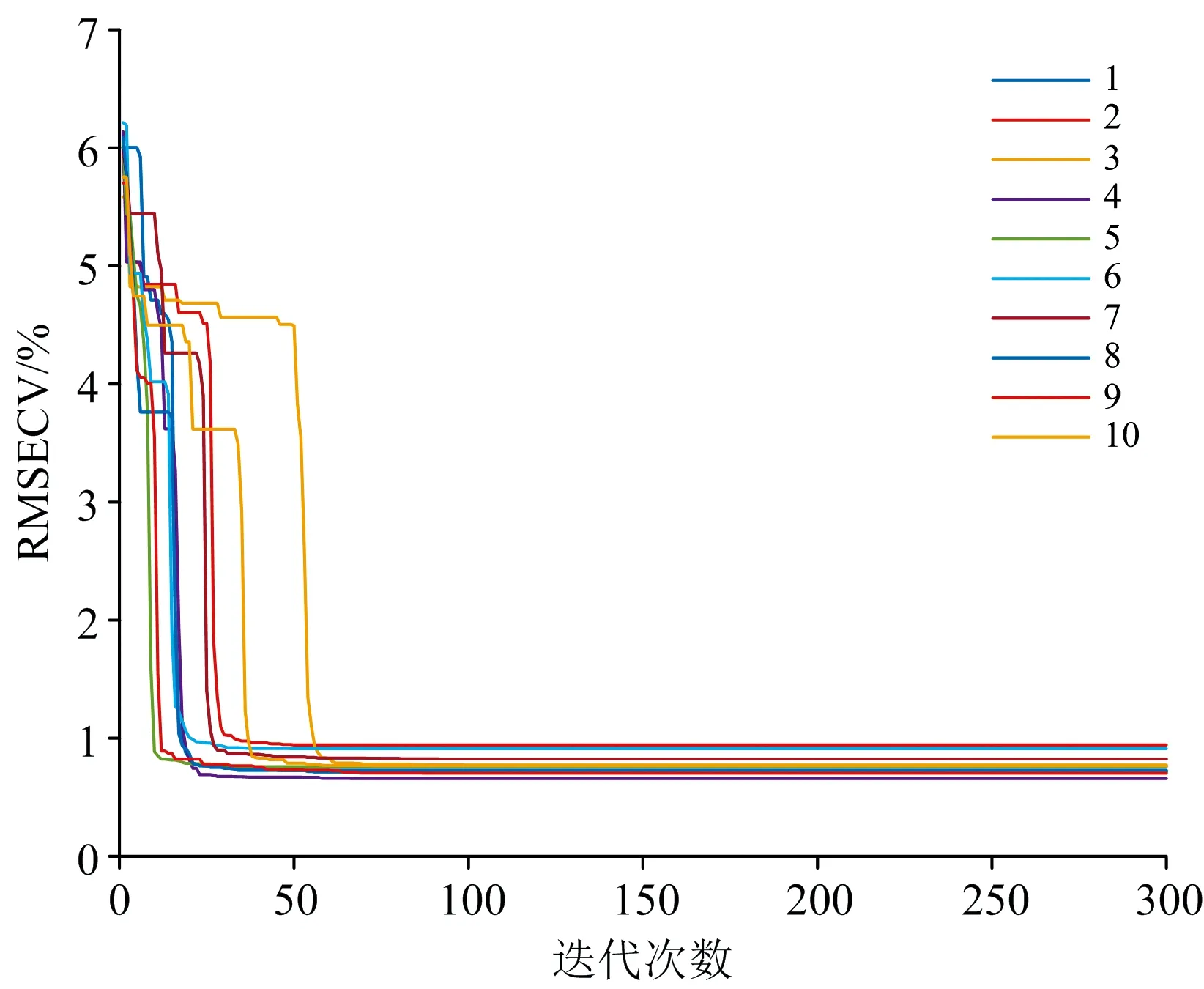
图4 最优狼群数量进行的10次重复实验Fig.4 10 repeated experiments with the optimal number of wolves
由于寻优过程的随机性,尽管狼群数量相同,每次实验获得最小RMSECV值的迭代次数不尽相同,而且有一定程度的差异,而RMSECV和RMSEP的平均值都在配气系统的仪器误差(标准气体浓度的±1%)以内,均具有不错的定量分析效果。说明该算法能够稳定有效地提取光谱特征,进而建立定量分析模型。
图5为C1迭代过程中α狼所选特征变量数随着迭代次数改变的关系。迭代开始前的特征数量即初始化随机生成的α狼的特征数量,粗选阶段α狼所选特征数量变化不大,但该阶段α狼所选特征变量包含有更多光谱特征信息,减少了随机初始化生成的α狼中的干扰信息;进入精选阶段,α狼特征数量快速减少,且RMSECV值逐渐降低,并趋于稳定。由此说明,RSBGWO算法具有快速降低数据维度的能力,并选择最优波长点,用于建立高精度的定量分析模型。
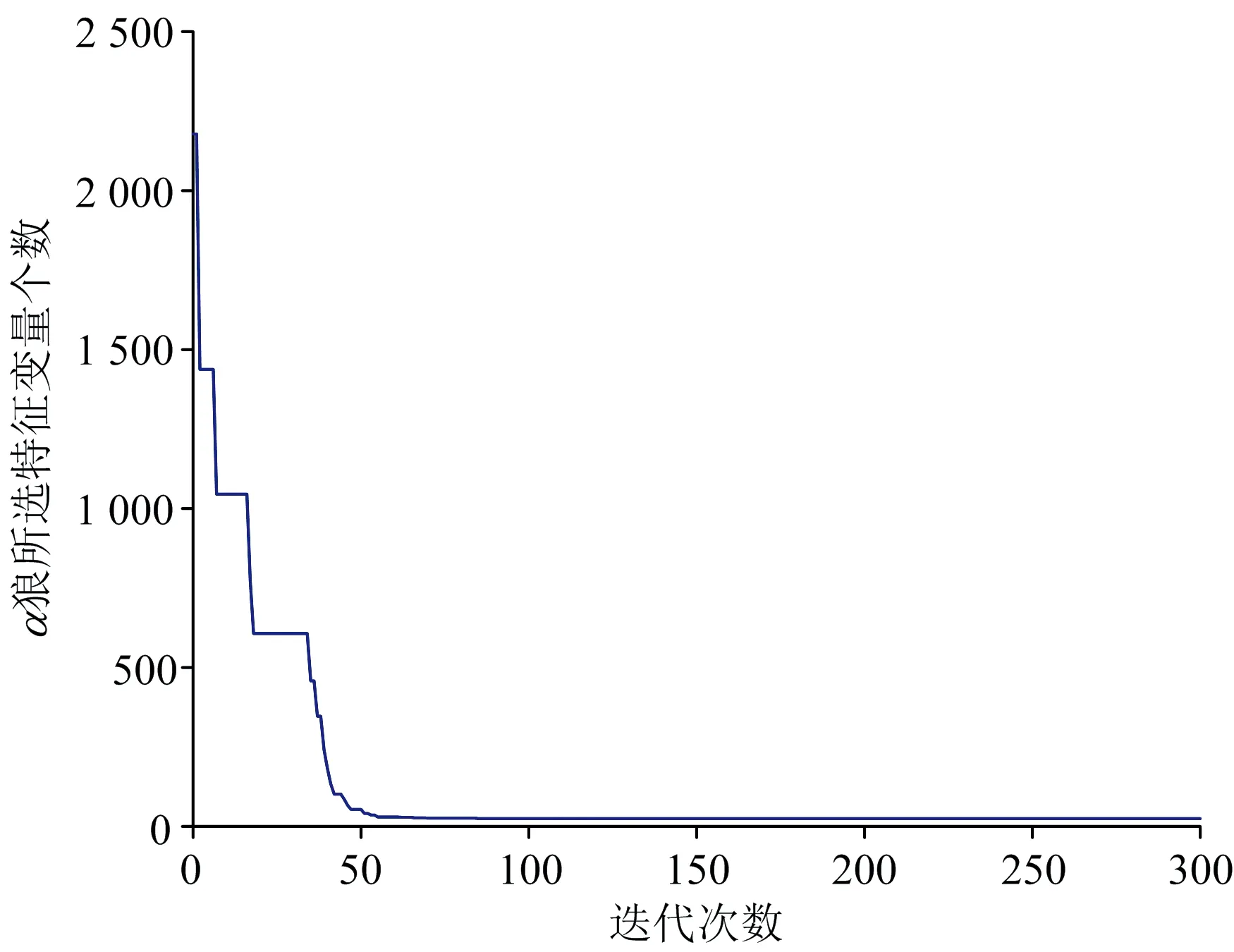
图5 迭代过程中α狼所选特征数量的变化曲线Fig.5 The change curve of the number of features selected by the alpha wolf in the iterative process
3.2 定量分析效果评价
为了分析RSBGWO算法的效果,分别建立了未经特征提取的MLR和PLS模型,三种不同特征提取方法(bGWO、bPSO、RSBGWO)下建立的MLR模型,以及结合RSBGWO算法建立的MLR和PLS定量分析模型。
表1统计了10次RSBGWO-MLR重复实验的RMSECV值及模型预测的R2、RMSEP和RPD的值。可以看出,10次重复实验建立的MLR模型均具有较好的预测效果,其中C1、C2、C3和CO2的平均R2均超过了0.996,平均RMSEP分别为8 266.575 9、3 896.020 2、8 770.961 2和7 546.636 8 ppm,平均RPD分别为17.522 8、28.758 2、19.484 8、35.283 2。但由于所选特征位置和特征数量不同,预测效果又各有不同,其预测效果表现为CO2>C2>C3>C1。
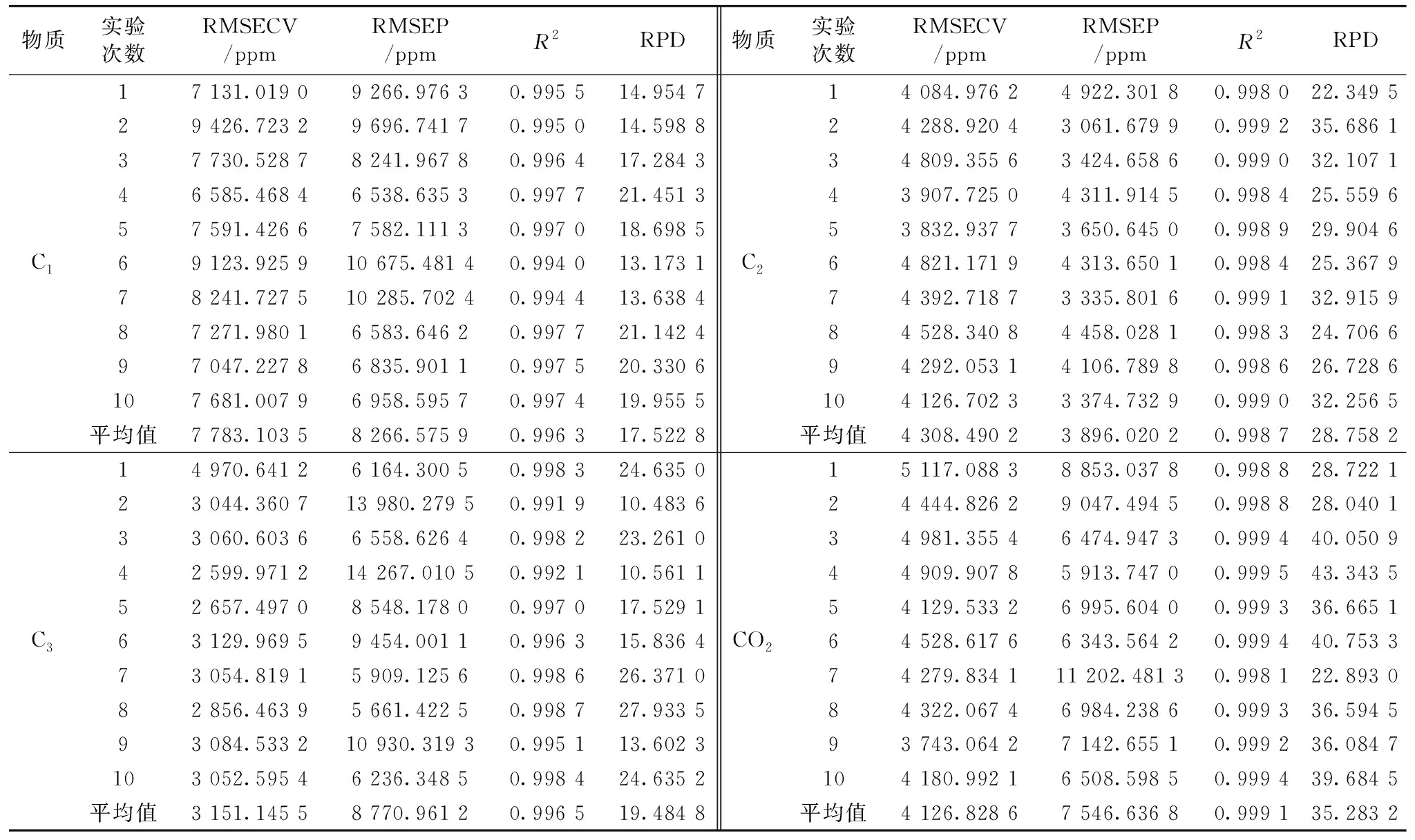
表1 10次重复实验的RMSECV、RMSEP、R2和RPD的值Table 1 Values of RMSECV,RMSEP,R2 and RPD for 10 repetitions
其中,C1、C2、C3和CO2的最优预测效果分别为在第4、第2、第8、第4次实验中获得,图6(a—d)分别为C1、C2、C3和CO2的最优预测效果。
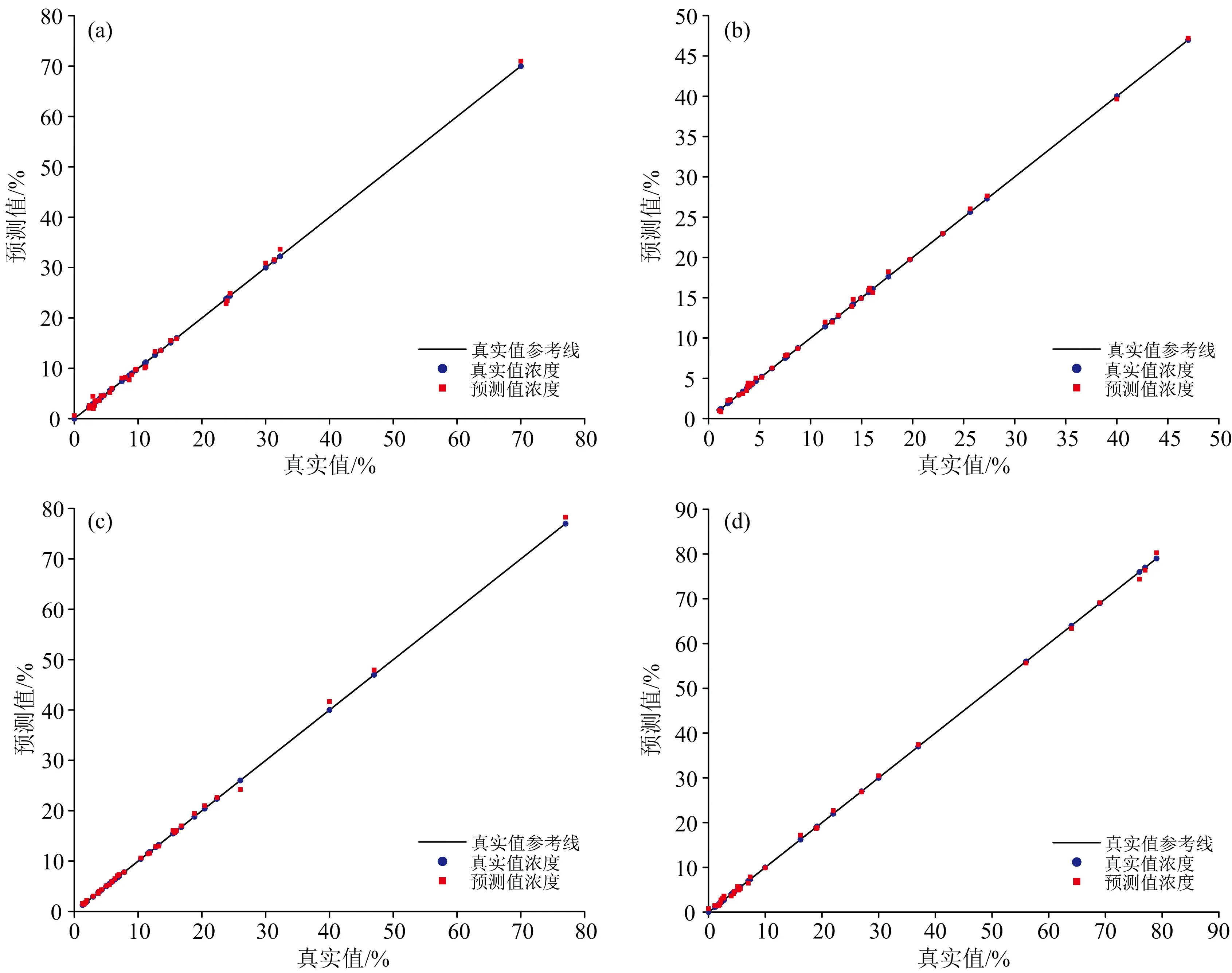
图6 各物质测试集预测结果(a):甲烷;(b):乙烷;(c):丙烷;(d):二氧化碳Fig.6 Prediction results of each substance test set(a):Methane;(b):Ethane;(c):Propane;(d):Carbon dioxide
研究表明,即使在nC4、iC4、iC5同系有机物组分的干扰作用下,其预测均方根误差均值均低于配气系统的固有误差10 000 ppm(标准气体浓度的±1%)。因此所提出的RSBGWO算法可以有效地提取红外光谱特征,用于建立高精度定量分析模型。
表2统计了不同定量分析模型的评价指标。
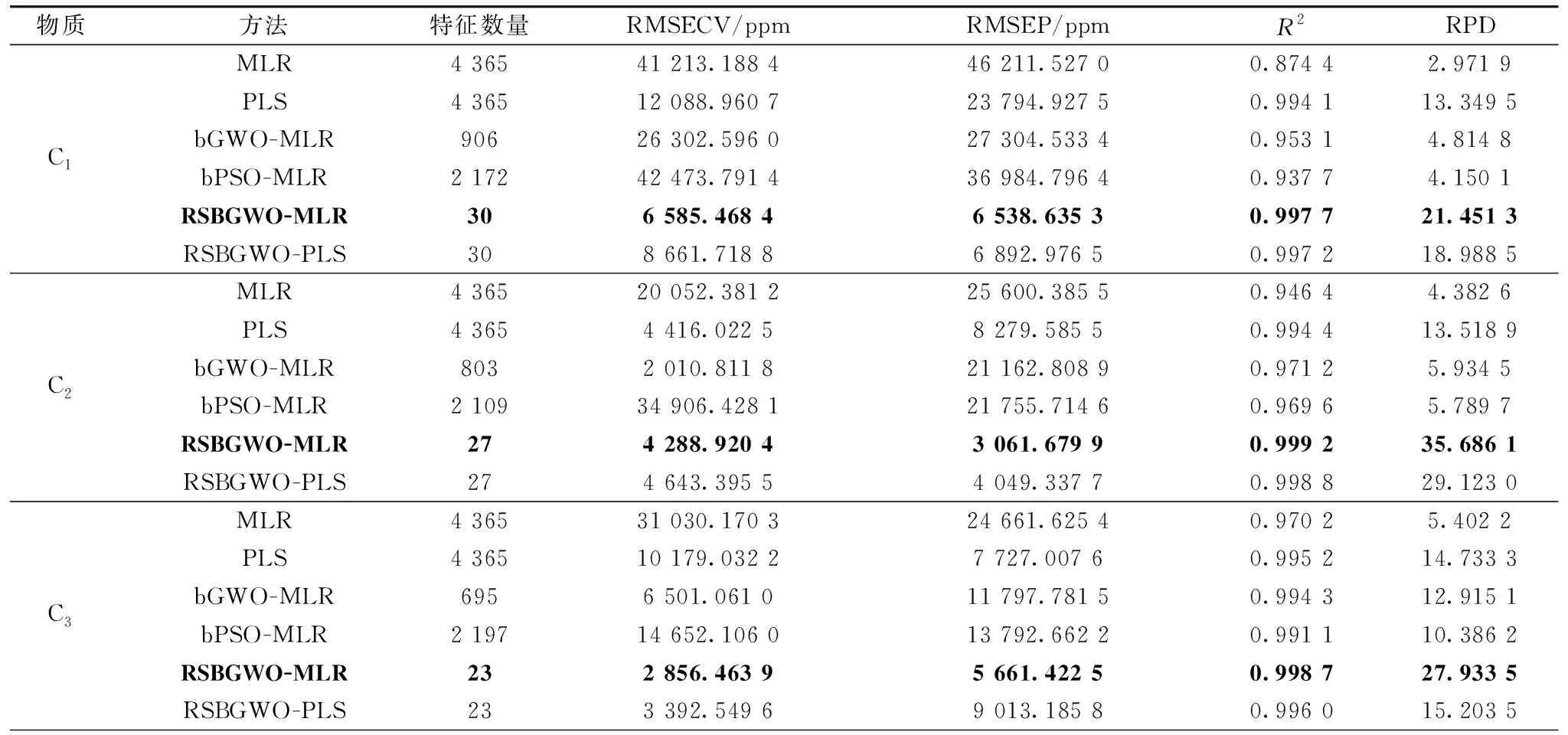
表2 不同算法下的模型评价指标Table 2 Model evaluation indexes under different algorithms

续表2
(1)比较MLR与RSBGWO-MLR分析结果可知,C1、C2、C3和CO2四种组分用于RSBGWO-MLR定量分析模型的特征数量分别为30、27、23、31,相较于MLR全谱建模,特征数量均降低了160倍以上,而且定量分析精度RMSEP值分别从46 211.527 0、25 600.385 5、24 661.625 4和26 934.704 1 ppm提高到6 538.635 3、3 061.679 9、5 661.422 5和5 913.747 0 ppm,RPD值则分别从2.971 9、4.382 6、5.402 2、9.637 9增加到21.451 3、35.686 1、27.933 5、43.343 5。结合本策略的RSBGWO-MLR具有优秀的特征提取能力,显著地提高了定量分析模型的预测精度。
(2)比较bGWO-MLR、bPSO-MLR与RSBGWO-MLR分析结果可知,相同实验条件下RSBGWO算法所提取的C1、C2、C3和CO2特征数量,相较于bGWO和bPSO算法分别降低了30、29、30和25倍以上;三种模型在测试集上的RMSEP值均表现为RSBGWO-MLR≪bGWO-MLR
(3)比较MLR与RSBGWO-MLR、PLS与RSBGWO-PLS的分析结果,C1、C2、C3和CO2四种组分RSBGWO-MLR与RSBGWO-PLS定量分析模型的RMSEP值分别为6 538.635 3与6 892.976 5 ppm、3 061.679 9与4 049.337 7 ppm、5 661.422 5与9 013.185 8、5 913.747 0与7 284.305 2 ppm,定量分析精度远高于全谱建模的MLR模型与PLS模型。在nC4、iC4、iC5组分的干扰作用下,采用RSBGWO算法提取的特征建立不同的定量分析模型,其预测均方根误差均低于配气系统的固有误差10 000 ppm(标准气体浓度的±1%)。本研究提出的RSBGWO算法可以有效地提取红外光谱特征,有助于提高不同定量分析模型的预测效果,降低对定量分析模型的依赖性。
4 结 论
为了提高烷烃红外光谱定量分析的性能,基于粗精选策略,引入了非线性迭代因子,并以平均交叉验证均方根误差(RMSECV)作为适应度评价指标改进了二进制灰狼优化算法,优化了其对原始红外光谱数据的特征提取能力。与元启发式算法中的bGWO和bPSO算法的对比实验结果表明,所提出的RSBGWO算法可以提取到更少、更有效的特征变量,进一步提高了定量分析模型的预测精度。应用所提算法建立的MLR和PLS模型尽管精度上有一定差异,但测试集的RMSEP值均低于烷烃气体红外光谱采集时所使用的配气系统的仪器误差,取得了不错的定量分析效果。
通过模拟灰狼种群在觅食过程中的位置更新策略来剔除干扰的光谱数据,从而寻找最优特征子集的方法能够有效应对烷烃类物质红外吸收交叉敏感性强导致的定量分析模型性能提升难的问题。对促进光谱检测技术在油气勘探、生物制药和食品化工等领域中的应用具有重要实际意义,对其他含同系物的红外光谱分析也具有一定的参考价值。
