基于高光谱技术的黑果腺肋花楸成熟度判别及多酚含量检测模型构建
2023-08-15南希骏周泉城李娅婕厉佳怡王红磊徐文慧刘依诺倪乙丹郭婷婷盛桂华
南希骏,周泉城,李娅婕,厉佳怡,王红磊,徐文慧,刘依诺,倪乙丹,郭婷婷,嵇 威,盛桂华
(山东理工大学农业工程与食品科学学院食品科学系,山东淄博 255049)
黑果腺肋花楸(Aronia melanocarpa,AM,简称黑果)果实含有丰富的营养物质,是多酚含量最高的植物之一[1]。黑果多酚可以清除自由基、减少脂质过氧化并增强抗氧化酶活力等,具有抗炎、抗癌、降血糖、降血压、调节心血管疾病以及改善肠道菌群[2−7]等作用。近年来,黑果的营养价值与功能性得到越来越多的认可,市场需求不断扩大。而黑果多酚含量是评价黑果品质的关键。黑果的成熟度判别,可以快速的识别黑果所处时期的成熟度,可为黑果的适时采摘提供依据,并可以结合黑果多酚含量检测结果,为黑果产品生产提供优质原料和数据支持。但是黑果成熟度判别方法报道较少,且传统的破坏性检测黑果多酚的福林酚法[8]耗时费力,满足不了快速检测的需求,因此,建立一种高效、快速、可靠且对黑果后续的生产及加工影响小的判别和检测方法对黑果相关产业的发展具有重要意义。
近年来,具有实时监测能力的无损光学技术引起了人们的兴趣,高光谱成像(Hyperspectral imaging,HSI)技术可以获得样品的全部光谱信息,并与图像信息相结合,可以判别外部特征和测定内部成分[9],具有快速、无损、识别精度高等诸多优点。国内外许多学者利用HSI 技术对果蔬的成熟度判别进行了研究,李军宇等[10]通过HSI 技术结合可溶性固形物和硬度值建立了不同成熟度李果实的偏最小二乘法(Partial least square,PLS)判别模型,准确度达91.25%,证明利用HSI 技术对不同成熟度李果实进行判别是可行的。国内外许多学者还利用HSI 技术对果蔬内部品质方面进行了检测研究,杨晓玉等[11]使用化学方法测定了灵武长枣维生素C 含量,并与高光谱信息结合,建立了支持向量机(Support vector machine,SVM)高光谱检测模型,可以满足HSI 技术对灵武长枣维生素C 含量的无损检测。Yang 等[12]采用化学方法提取并测定荔枝果皮花青素含量,利用HSI 技术并采用径向基函数神经网络算法与花青素含量建立融合模型,并进行了可视化,可以显示荔枝果皮内花青素的分布。以上研究表明,HSI 技术在果蔬快速、无损成熟度判别及内部品质检测方面具有一定的研究基础和广阔的应用前景。目前,关于黑果的成熟度判别以及黑果多酚的无损快速检测的研究未见报道,这限制了黑果的高值化应用及黑果多酚的功能性开发。
基于上,本研究拟利用高光谱成像技术对黑果进行扫描得到光谱数据,并采样化学法测定其多酚含量,将光谱信息与多酚含量数据通过Unscrambler X进行预处理及建立模型,采用MATLAB 提取特征波长并优化模型,构建基于高光谱的黑果成熟度判别以及多酚含量检测的最优模型,以达到对黑果的成熟度判别以及多酚含量无损检测的目的,从而为黑果的适时采摘、品质评价及相关产品的深度开发和高值化应用提供理论基础和技术支持,促进黑果产业的发展。
1 材料与方法
1.1 材料与仪器
富康源1 号黑果腺肋花楸果实 由山东省淄博市林业保护发展中心种植并提供;没食子酸标准品、乙醇、盐酸等其它常用试剂 购自上海爱纯生物科技有限公司。
HSI-eswir-400-2500 高光谱农业物料分选仪五铃光学股份有限公司;UV759CRT 型扫描型紫外可见分光光度计 青岛聚创环保集团有限公司;AL-1D4 精密分析天平 梅特勒-托利多仪器(上海)有限公司;TDL-40B 低速离心机 上海安亭科学仪器厂。
1.2 实验方法
1.2.1 黑果的采集 根据文献报道,黑果进入成熟期后,随着成熟度的增加,其果实从红色变为紫色,最终变为黑色,多酚含量也随着成熟度的变化发生改变[13−14]。山东省淄博市林业保护发展中心种植的黑果,7 月下旬开始变红,8 月上旬变为紫色,8 月中旬逐渐由紫色变为黑色。因此,选择2018 年8 月5 日~9 月4 日期间,每天采摘黑果果实,采摘后的果实立即用自封袋封闭,在−40 ℃冰箱中冷冻保存,用于化学法多酚含量测定和高光谱信息采集,以监测多酚含量随成熟度变化的变化规律,并建立基于高光谱的黑果成熟度判别以及多酚含量检测模型。
1.2.2 多酚含量测试
1.2.2.1 黑果多酚的提取 参考丛龙娇等[15]的方法并稍加修改。将黑果置于烘箱中60 ℃下烘干至恒重,用研钵研磨,加入65.00%乙醇—2.00%盐酸加速研磨,黑果与65.00%乙醇—2.00%盐酸料液比为1:50 g/mL。在设定温度40 ℃、超声功率500 W 超声波条件下提取多酚类物质60 min。3000 r/min 下离心10 min,取上清液贮藏备用。
1.2.2.2 总酚含量的测定 多酚标准曲线的测定采用福林酚比色法,参考丛龙娇等[15]的方法并稍加修改。紫外分光光度计765 nm 下测定溶液的吸光度。得到线性回归方程:y=0.008x+0.0025,回归系数:R²=0.9954。取黑果多酚提取液代替没食子酸标准溶液,测定其在765 nm 下吸光度,重复三次。
1.2.3 黑果高光谱信息采集 采用HSI 系统(见图1)对黑果进行光谱信息采集。

图1 感兴趣区域采集Fig.1 Area of interest acquisition
在进行实验前,高光谱系统需先预热半小时。由于光照分布不均匀以及存在暗电流噪音,所以在要对采集的光谱信息进行黑白标定[16]。
式中:R 为经过校正后的光谱图像;Iλ为直接由高光谱采集设备获取的漫反射光谱图像;Bλ为关闭光源拧紧镜头盖后采集的暗参考图像;Wλ为采集的标准白板的漫反射图像。
样品扫描时,确定最佳曝光时间2.9 ms,平台位移速度15.34 mm·s−1,焦距30.7 mm,相机分辨率384×288,光入射角度45°[17]。采集到光谱信息后,利用ENVI 4.8 软件在原始数据中选取1521 像素矩形感兴趣区域(见图1),获得原始光谱信息。
1.2.4 模型建立及评价
1.2.4.1 判别模型的建立 判别分析模型参考李佛琳等[18]的方法,使用SPSS 23 中Discriminate 程序运算。首先对原始数据进行剔除异常值和预处理,选择最佳的预处理下光谱数据,用光谱-理化值共生距(Sample set partitioning based on joint x-y distance,SPXY)法进行样本划分,用竞争性自适应重加权算法(Competitive adaptive reweighted sampling,CARS)和无信息变量消除法(Uninformative variable elimination,UVE)提取特征波长,根据标准成熟度级别组成的校正集样本光谱数据分别建立高光谱—黑果成熟度PLS 判别模型和高光谱—黑果成熟度SVM判别模型,再以此判断需预测的样本成熟度级别。选择效果最好的PLS 模型和SVM 模型,运用Fisher判别法,根据建立的判别方程对光谱数据做逐一回代重判别,校验方程精度。
1.2.4.2 多酚-高光谱模型的建立及可视化 同“1.2.4.1”,原始数据经剔除异常值、预处理、SPXY法样本划分后,采用CARS 和UVE 法提取特征波长,分别构建特征波长与多酚含量、全波长与多酚含量的PLS 检测模型和SVM 检测模型,最终建立检测模型并进行验证[11]。
比较建立的检测模型,选择最适合的预测模型来可视化黑果多酚含量[19]。具体来说,将每个像素的光谱输入到所建立的模型中,预测该特定点的多酚含量,对高光谱图像中的所有像素重复这一过程。其中背景分割采用阈值为0.2。用不同的颜色显示不同的预测多酚值,生成伪彩色图像。所得到的图有助于可视化单个样本内和样本间多酚空间分布的差异。MATLAB 2018a 用于可视化任务。
1.2.4.3 模型评价指标 模型的可靠性和精度可以通过一些参数指标进行评价[20]。在本研究中,模型的评价指标选择建模集决定系数(Rc2)和预测集决定系数(Rp2),建模集均方根误差(Root mean squared error of calibration,RMSEC)和预测集均方根误差(Root mean squared error of prediction,RMSEP)来进行分析定量。计算公式分别如下所示:
建模集决定系数:
式中:nc为建模集样本数量;为第i 个样本的预测值;yi为第i 个样本的实测值;为建模集样本的平均值。
预测集决定系数:
式中:np为预测集样本数量;为第i 个样本的预测值;yi为第i 个样本的实测值;为建模集样本的平均值。
建模集均方根误差:
式中:nc为建模集样本数量;为第i 个样本的预测值;yi为第i 个样本的实测值。
预测集均方根误差:
式中:np为预测集样本数量;为第i 个样本的预测值;yi为第i 个样本的实测值。
1.3 数据处理
高光谱图像处理软件为ENVI 5.3,剔除异常值、SPXY 样本划分、提取特征波长、可视化软件为MATLAB 2018a,预处理及建模软件为The Unscrambler X 10.4,软件绘图软件为Origin 2018 9.5。
2 结果与分析
2.1 黑果果实多酚含量变化规律
8 月5 日~9 月4 日,每天随机采摘黑果果实并测量其多酚含量,根据果实颜色和测得的多酚含量,分析多酚含量变化规律,对其成熟度划分级别,见表1 和图2。
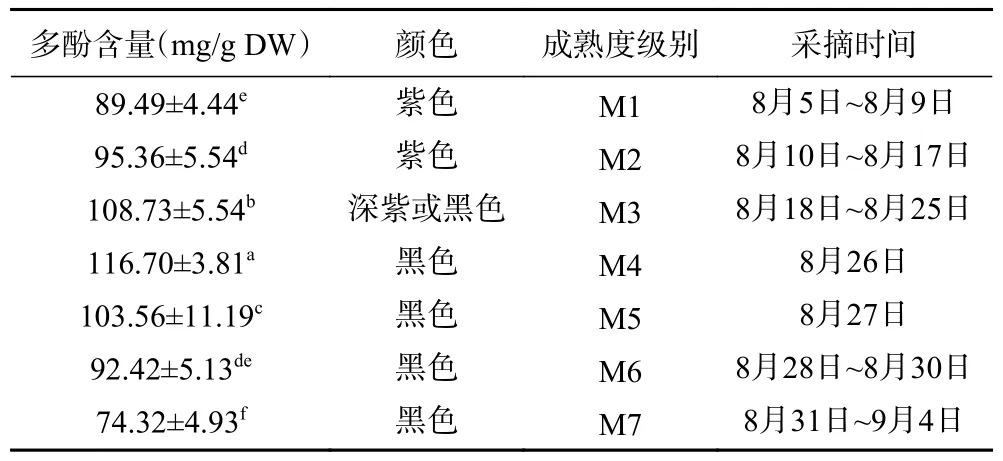
表1 黑果多酚含量变化规律及成熟度划分Table 1 Variation of polyphenol content and division of maturity in AM

图2 M1 至M7 成熟度级别的黑果Fig.2 AM at maturity level M1 to M7
有研究表明,黑果在较为温暖的长江流域里下河地区成熟时期为八月初[13],而在较为寒冷的东北、辽西等地黑果成熟时期为九月初[14]。目前没有关于鲁中地区黑果成熟期以及营养成分含量随时间变化规律的报道。理论上黄河流域的鲁中地区黑果成熟时期应为八月中旬到八月底。从表1 可以看出,鲁中地区的淄博,从8 月初到9 月初,黑果多酚含量呈现先增高后减少的趋势,进入8 月下旬后,黑果多酚含量最高,达到100 mg/g 以上,符合我们对鲁中地区黑果成熟时期的预判。
值得注意的是,进入8 月下旬后,黑果多酚含量变化比较大,本研究中,黑果多酚8 月26 日达到峰值、116.7±3.81 mg/g DW,之后多酚含量开始下降,8 月31日~9 月4 日的黑果多酚含量降到了74.32±4.93 mg/g DW,因此为提高黑果的收获质量,整个8 月下旬,应紧密监测其多酚含量,适时采收。
2.2 高光谱检测
采用HSI 系统对98 个黑果进行光谱信息采集,利用ENVI 4.8 软件在原始数据中选取1521 像素矩形感兴趣区域,未经预处理的原始光谱如图3 所示,为了消除噪音的影响[17],选取1000~2200 nm 的光谱区间进行分析[21−22]。

图3 光谱反射曲线Fig.3 Spectral reflection curve
2.3 判别模型的建立
2.3.1 剔除异常值 蒙特卡洛交叉验证法可以挑选可能存在异常的值并进行选择性剔除,通过计算得到效果更佳的模型[11]。具体操作如下:将采集后的光谱值与黑果成熟度级别进行分析建模,交互验证误差均方根(Root mean square error of cross validation,RMSECV)最小的即为最佳主成分数;通过蒙特卡洛交叉验证法后得到各样本的预测误差均值和预测误差标准差并绘制散点图。如图4 所示,以预测误差均值和预测误差标准差的平均值的2.50 倍为界限(图中虚线),超出界限即为可能存在异常的值。将每个可能存在异常的值删除并建模,R2增大即判定为异常值并剔除,R2减小即不是异常值并保留。

图4 蒙特卡洛检测Fig.4 Monte Carlo detection
如图4 所示,预测误差标准差和预测误差均值超出界限值的需要依次剔除。剔除异常值2、12、59、66、70 号样本剔除后,R2从0.8686 升高至0.8974,因此判定为异常值并剔除。67、91 号样本不是异常值。
2.3.2 SPXY 样本划分 SPXY 法按3:1 将样本分为校正集和预测集(见表2)。

表2 不同预处理方法的黑果成熟度PLS 模型Table 2 PLS models for maturity of AM based on different pretreatment methods
在对黑果的成熟度级别进行分类判别前,首先分别给每一成熟度级别的样本假设一个值作为判别标志,分别将M1、M2、M3、M4、M5、M6、M7 成熟度级别黑果赋值为1、2、3、4、5、6、7,然后建立PLS判别模型。
PLS 是比较常用的化学计量学方法,可以用于定性分析和定量分析。采用Unscrambler X10.1 软件建立PLS 模型。由于建立的判别模型在进行分类判别时,其模型预测类别值非整数,所以在判断类别时设定一个阈值,认为预测类别值与假设类别值之间的差值大于等于0.5 的样本认定为非此类别样本[21]。本研究中设定黑果的M1 级别的正确预测类别值在0.5~1.5 之间,M2 级别的正确预测类别值在1.5~2.5之间,M3 级别的正确预测类别值在2.5~3.5 之间,M4 级别的正确预测类别值在3.5~4.5 之间,M5 级别的正确预测类别值在4.5~5.5 之间,M6 级别的正确预测类别值在5.5~6.5 之间,M7 级别的正确预测类别值在6.5~7.5 之间。
2.3.3 原光谱与预处理光谱的PLS 模型比较 建立未经过光谱预处理和经预处理后的黑果成熟度PLS 模型并进行综合比较。如表2 所示,与其他预处理建立的模型相比,经过多元散射校正(Multiple scattering correction,MSC)预处理后的模型RMSECV最低,为0.7360;R2最高,为0.8977。说明经MSC 预处理后建立的判别模型最稳定,效果最好。因此选用经MSC 预处理后所得到的光谱数据进行后续的研究分析。
2.3.4 提取特征波长
2.3.4.1 CARS 由于CARS 的随机性和不确定性,因此经过50 次试验选取波长数量较少的,RMSECV最低的特征波长[23]。如图5 所示,图5a 为波长数量的变化趋势:随着试验次数的增加,波长变量逐渐减少;图5b 为迭代次数与RMSECV 之间的关系,RMSECV 在32 处达到最低后逐渐升高,说明选择过程剔除了与黑果成熟度检测有关的重要变量;图5c 为参与PLS 建模的特征波长的回归系数值,其中“*”对应位置为32 次的采样。选择RMSECV 值最低的为最佳的迭代次数,即第32 次。第32 次采样所得特征波长为55、104、109、156、173、194、195、202 nm 共11 个光谱波长,占总光谱波长的5.44%。

图5 CARS 筛选过程Fig.5 CARS screening process
2.3.4.2 UVE 无信息变量消除方法的参数设置为随机噪声矩阵的变量数为202 个,与建模的光谱波长变量数一致,提取的最大主成分数为7。如图6 所示,竖虚线左侧为真实的波长变量,右侧为随机噪声变量;两水平虚线为UVE 稳定性的阈值,虚线之外的为要提取的特征波长,提取38、39、40、41、42、43、44、45、46、55、56、57、58、59、107、108、109、111、122、123、200、201 nm 共22 个波长,占总光谱波长的10.89%。
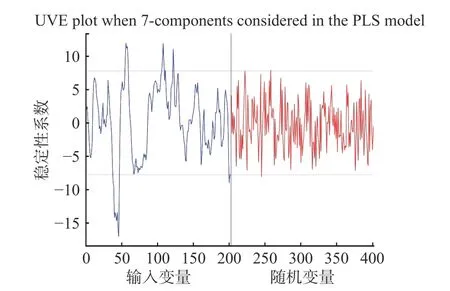
图6 UVE-PLS 模型的稳定性分布曲线Fig.6 Stability distribution curve of UVE-PLS model
2.3.5 PLS 模型和SVM 模型建立及验证
2.3.5.1 PLS 模型建立及验证 建立CARS、UVE和FS 的PLS 模型,并进行验证。如表3 所示,将各模型进行比较,其中CARS-PLS 的RMSECV 最小,为0.6221,Rc2和Rp2最大,分别为0.9233 和0.9169,具有最好的校正性能和交互验证性能。因此,CARSPLS 模型为最优的PLS 模型,模型预测理论上最准确。

表3 黑果成熟度级别的PLS 模型Table 3 PLS models for maturity level of AM
2.3.5.2 SVM 模型建立及验证 SVM 模型建立及验证如表4 所示,其中UVE-SVM 的RMSECV 最小,为0.6233,Rc2最大,为0.9712,校正效果和交互验证效果较好。因此,UVE-SVM 模型为最优的SVM 模型,模型预测理论上最准确。

表4 黑果成熟度级别的SVM 模型Table 4 SVM models for maturity level of AM
综上所述,CARS-PLS 与UVE-SVM 模型校正效果和交互验证效果较好,因此对CARS-PLS 与UVESVM 模型进行判别分析。
2.3.6 CARS-PLS 判别结果 由表5 可知,PLS 判别模型在校正集中误判样本数为10,识别率为85.71%;在预测集中误判样本数为4,识别率为82.61%,综合识别率为84.95%。
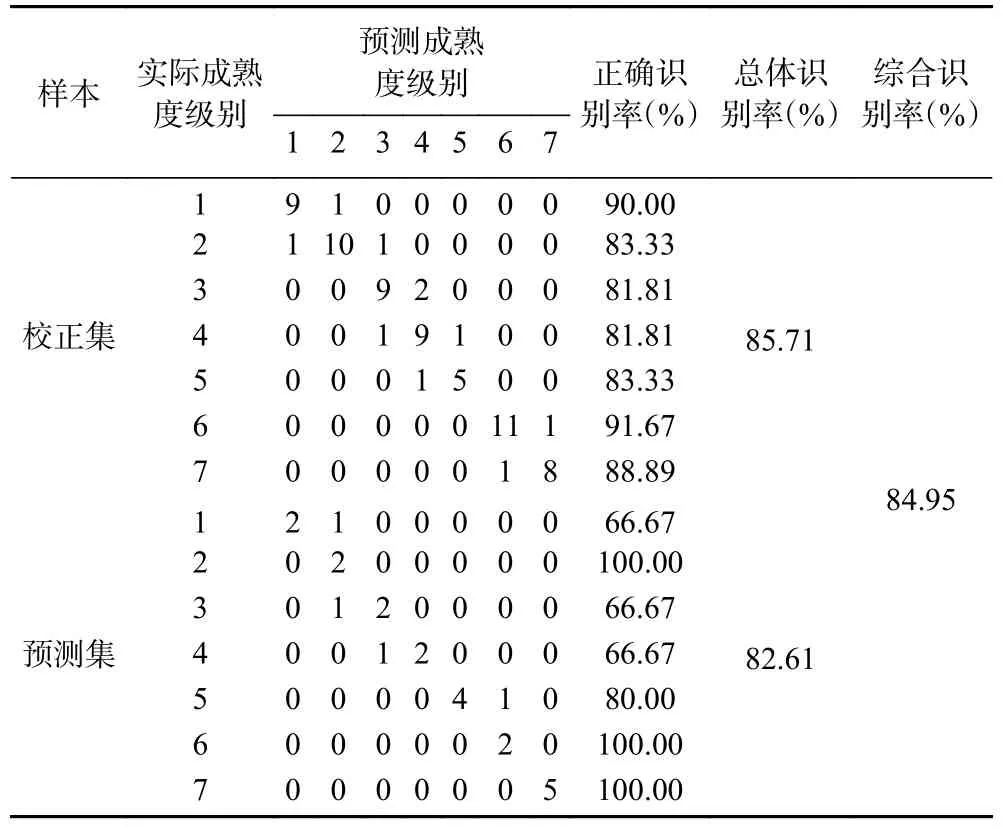
表5 CARS-PLS 模型判别结果Table 5 The discrimination results of CARS-PLS model
2.3.7 UVE-SVM 判别结果 结果如表6 所示,SVM判别模型在校正集中误判样本数为4 个,识别率为94.28%;在预测集中误判样本数为1 个,识别率为95.65%,综合识别率为94.62%。相较于CARS-PLS判别模型,UVE-SVM 判别模型效果更好,综合识别率更高。

表6 UVE-SVM 模型判别结果Table 6 The discrimination results of UVE-SVM model
黑果的成熟度判别模型研究较少,本研究建立的UVE-SVM 黑果成熟度判别模型综合识别率为94.62%,Rc2和Rp2分别为0.9712 和0.9708。李鑫等[24]建立的基于高光谱成像技术的烟叶田间成熟度的SVM 判别模型的总和识别率在87.19%~93.13%之间。相较于李鑫等建立的预测模型,该模型具有更好的判别效果。
2.3.8 SVM 模型的验证 将七个成熟度级别的黑果混合后随机选取20 个进行模型的验证,选取结果为M1 级别3 个样本,M2 级别2 个样本,M3 级别2 个样本,M4 级别2 个样本,M5 级别4 个样本,M6 级别2个样本,M7 级别5 个样本。将黑果的光谱值代入上述的UVE-SVM 模型,得到的黑果成熟度级别的预测值,并与实际级别构建的散点图(图7),R2=0.9793,判别结果为20 个样本结果正确率均为100.00%。结果表明该UVE-SVM 模型具有良好的预测性能。

图7 黑果成熟度级别的SVM 判别模型的实测级别和预测级别散点图Fig.7 Scatter plots of the measured level and predicted level of the SVM discriminant model for AM maturity level
2.4 多酚-高光谱建模
2.4.1 蒙特卡洛法剔除异常值 如图8 所示,预测误差标准差和预测误差均值超出界限值的需要依次剔除。剔除异常值2、59、66、91 号样本剔除后,Rc2从0.7686 升高至0.7845,因此判定为异常值并剔除。12、67 号样本不是异常值。

图8 蒙特卡洛检测Fig.8 Monte Carlo detection
2.4.2 SPXY 样本划分 采用蒙特卡洛交叉验证法剔除异常值后,采用SPXY 法按3:1 的比例将黑果多酚含量样本进行划分,并分别计算校正集、预测集多酚含量的最大值、最小值、平均值和标准偏差,结果如表7 所示。

表7 SPXY 法样本划分Table 7 Sample division by SPXY method
2.4.3 原光谱与预处理光谱的PLS 模型比较 建立未经过光谱预处理和经预处理后的黑果成熟度PLS 模型并进行综合比较。如表8 所示,与其他预处理建立的模型相比,经过中值滤波(Median Filter)预处理后的模型RMSECV 最低,为14.4182;R2较高,为0.7832。说明经Median Filter 预处理后建立的黑果多酚含量模型最稳定,效果最好。因此选用经Median Filter 预处理后所得到的光谱数据进行后续的研究分析。
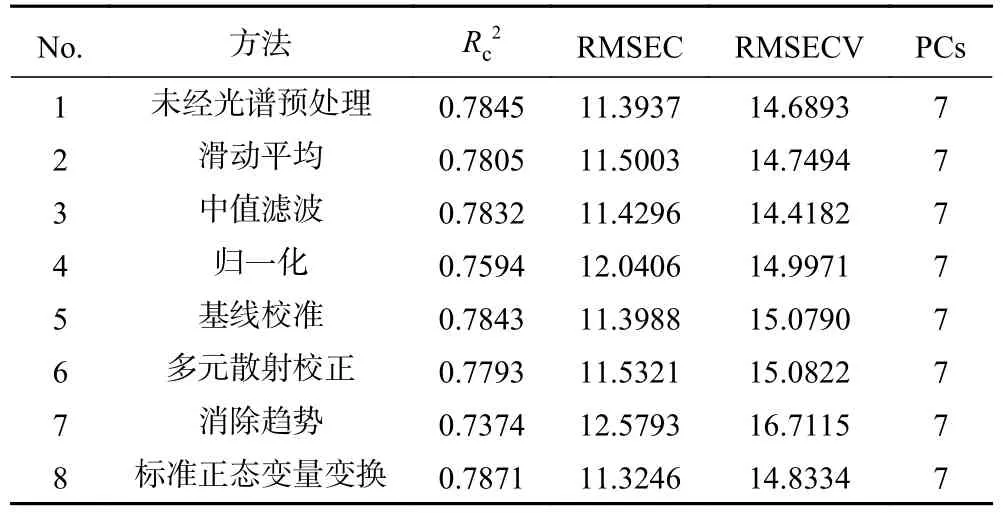
表8 不同预处理方法建立的PLS 预测模型Table 8 PLS models established by different pretreatment methods
2.4.4 特征波长的选取
2.4.4.1 竞争性自适应加权算法 如图9 所示,图9 a 为波长数量的变化趋势:随着试验次数的增加,波长变量逐渐减少;图9b 为迭代次数与RMSECV之间的关系,RMSECV 在19 处达到最低后逐渐升高,说明选择过程剔除了与黑果多酚含量检测有关的重要变量;图9c 为参与PLS 建模的特征波长的回归系数值,其中“*”对应位置为19 次的采样。选择RMSECV 值最低的为最佳的迭代次数,即第19 次。第19 次采样所得的特征波长为2、25、26、27、39、61、62、63、64、84、85、87、89、90、93、94、95、96、97、98、100、101、102、105、129、130、133、136、138、140、145、161、163、165、167、175、191 nm共37 个光谱波长,占总光谱波长的18.32%。
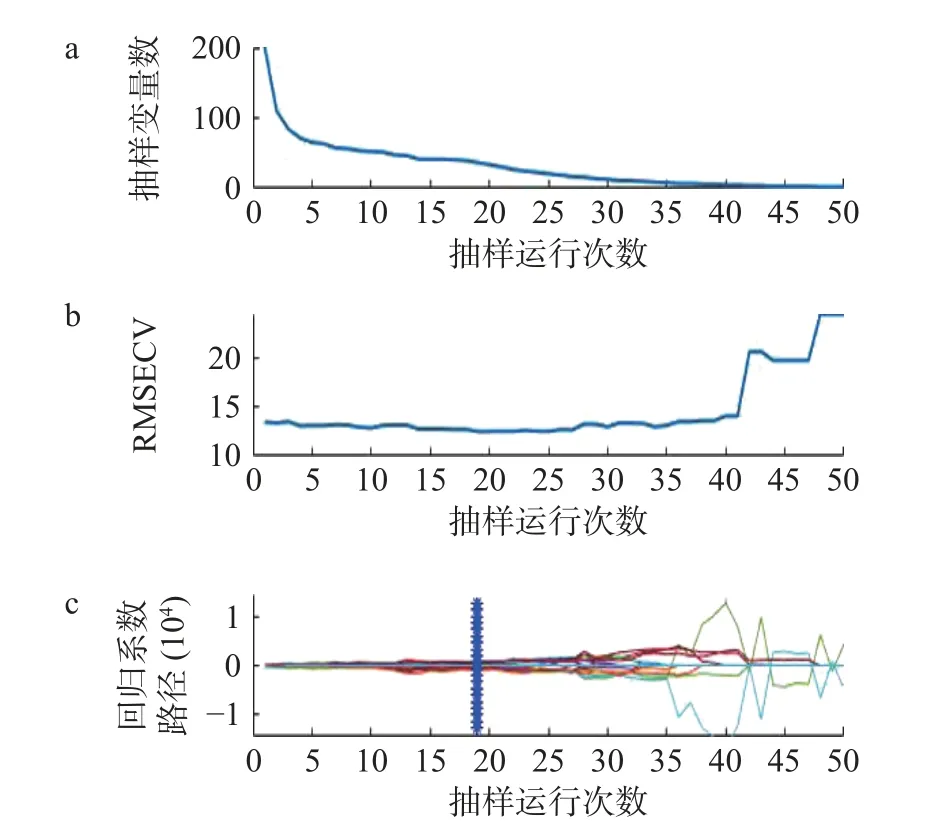
图9 CARS 筛选过程Fig.9 CARS screening process
2.4.4.2 UVE 无信息变量消除方法的参数设置为随机噪声矩阵的变量数为202 个,与建模的光谱波长变量数一致,提取的最大主成分数为7。如图10所示,竖虚线左侧为真实的波长变量,右侧为随机噪声变量;两水平虚线为UVE 稳定性的阈值,虚线之外的为要提取的特征波长,提取1、2、3、5、6、7、18、19、23、24、25、26、27、28、29、59、60、61、62、63、64、65、66、67、68、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、101、102、103、104、105、106、107、108、109、110、111、128、129、130、131、132、133、134、135、136、137、138、139、140、141、142 nm共75 个波长,占总光谱波长的37.13%。

图10 UVE 模型的稳定性分布曲线Fig.10 stability distribution curve of UVE model
2.4.5 PLS 模型建立及验证 建立CARS、UVE 和FS 的PLS 模型,并进行验证。如表9 所示,CARS-PLS的RMSECV 最小,为13.4552,Rc2和Rp2最大,分别为0.7997 和0.7496,校正效果和交互验证效果较好。因此,CARS-PLS 模型为最优模型,理论上模型预测最准确。

表9 黑果多酚含量的PLS 模型Table 9 PLS models for polyphenol content of AM
2.4.6 SVM 模型建立 建立CARS、UVE 和FS 的SVM 模型,并进行验证。如表10 所示,CARS-SVM的RMSECV 最小,为16.4224;Rc2和Rp2最高,分别为0.8331 和0.7377,即校正效果和交互验证效果较好。因此,CARS-SVM 模型为最优模型,理论上模型预测最准确。

表10 黑果多酚含量的SVM 模型Table 10 SVM models for polyphenol content of AM
黑果多酚含量预测模型的相关研究较少,本研究建立的CARS-SVM 模型Rc2均高于其他模型的Rc2,为0.8331。张骁等[25]建立的水稻籽粒直链淀粉含量高光谱预测模型Rc2为0.74。李宗飞等[26]建立的甜菜叶片全氮含量高光谱预测模型Rc2为0.747,相较于张骁、李宗飞等建立的预测模型,本研究建立的模型具有更好的校正性能。
2.4.7 SVM 模型的验证 随机选取不同成熟度级别的20 个黑果验证模型,将黑果的光谱值代入上述的CARS-SVM 模型,得到的黑果多酚含量的预测值,并与实际值构建的散点图(图11),R2=0.8389,结果表明该CARS-SVM 模型具有较好的预测性能。

图11 黑果多酚含量的SVM 模型的实测值和预测值的散点图Fig.11 Scatter plot of measured and predicted values of SVM model for polyphenol content in AM
2.4.8 黑果多酚含量可视化模型 高光谱图像经校正后,提取黑果样本上每一像素点对应的光谱信息,用已建立的黑果多酚含量高光谱模型可有效预测各像素点的多酚含量[27]。以像素点空间位置及对应多酚含量绘制了伪彩色图像,如图12 所示,随机选取七个成熟度级别的黑果,得到颜色鲜明、可视化的伪彩色黑果多酚含量分布图像。分布图上黑果的背景为深蓝色,多酚含量显示为零;颜色越红表示多酚含量越高[28]。如图所示,各级别的黑果多酚含量比较均匀,内部深蓝色点可能是黑果籽,研究结果与前文测得的多酚含量一致,证明了采用高光谱图像信息建立黑果多酚含量可视化模型是可行的。

图12 黑果多酚含量空间分布图Fig.12 Spatial distribution for polyphenols of AM
3 结论
本研究对鲁中地区黑果进入成熟期后,多酚含量随时间和成熟度的变化规律进行了研究,发现鲁中地方黑果成熟期在8 月下旬,多酚含量达到峰值。构建了基于高光谱的黑果成熟度判别以及多酚含量检测的最优模型:黑果成熟度判别模型,效果最好的为MSC 预处理下的UVE-SVM 模型,综合识别率为94.62%,Rc2为0.9712,根据该模型验证的准确度为100%;多酚含量模型,效果最好的为Median Filter 预处理下的CARS-SVM 模型,Rc2为0.8331。特征波长的提取及建模对光谱进行了降维,简化了数据量。此外,本研究还表明黑果多酚含量的可视化是可行的。
本研究为黑果的适时采摘、品质评价及相关产品的深度开发和高值化应用提供理论基础和技术支持,拓展了黑果无损检测技术,为HSI 技术在浆果领域的应用提供了理论基础。对促进黑果产业的发展有一定的意义。目前,国内外对黑果多酚的功能特性已经有了较多的应用和研究,但是检测方法较为落后。后续研究可以围绕黑果多酚中花青素、类黄酮和酚酸等单体多酚以及原花青素等复合多酚的高光谱检测模型的构建。此外,可视化可以实现智慧化采摘果蔬,符合未来智能化发展的趋势,而国内外对果蔬的可视化研究也较少,后续研究可以围绕此研究方面进行。
