一种优化的Hadoop数据放置策略
2023-07-12吴岳
吴 岳
(国家林业和草原局产业发展规划院,北京 100010)
0 引言(Introduction)
大数据系统的作用是存储和分析大量的数据,同时确保数据的安全性和可访问性。大数据系统将数据存储管理委托给分布式文件系统(DFS)执行,例如Apache Hadoop的数据存储基于Hadoop分布式文件系统(HDFS)[1]。Hadoop可以实现扩展集群上的复杂计算,它的工作原理是将复杂的计算分布在多台机器上,并且使计算靠近数据,而不是将数据送至计算,最大限度地减少对网络带宽的占用,从而提高全局性能[2]。
HDFS的数据放置策略会将数据块分条和复制,可在发生故障时尽可能地保护数据。该策略的数据保护原则是为相同数据创建多个副本,并将副本分布放置在多个机架的多台计算机上。然而,该策略放置副本时没有考虑到随着时间变化,每个数据的被需求程度也会变化,有可能导致没有发挥集群的最优性能。本文通过深入研究Hadoop和HDFS的整体工作机制,提出一种综合考虑需求和处理性能实现重新放置副本的算法,并通过实验证明,该算法可以将集群的处理性能提高20%以上。
1 Hadoop分布式文件系统(Hadoop Distributed File System)
1.1 HDFS的架构
HDFS的架构由单个活动的Master(Name Node)和多个Slave(Data Node)组成[3]。Name Node负责管理集群中Data Node的状态,并处理整个集群中的存储分布。用户的每次读写操作都从向NameNode发起请求开始[4]。文件系统元信息(包含数据块定位)与数据块分别存储在NameNode和Data Node上,Name Node只是将用户查询的Data Node列表作为元数据块传输给用户,之后用户在不重复读取NameNode的情况下与Data Node通信。Name Node不参与用户和Data Node之间的数据传输,这种方法简化了HDFS 的架构,避免了NameNode成为瓶颈[5]。
1.2 HDFS的复制
HDFS在复制过程中,将文件分成几个大小相等的数据块,这个操作称为数据条带化[6]。HDFS通过将这些数据块存储在不同DataNode上实现并行化数据访问,从而缩短响应时间。将每个数据块复制成多个副本(默认是3个,可修改配置),并将每个副本存放在根据预定义策略确定的Data Node上[7]。这样可以降低由于硬件发生故障导致数据丢失的风险。Data Node能通过心跳机制向NameNode汇报状态信息,当某个DataNode发生故障时,NameNode可在其他DataNode上重构该DataNode上的数据块,保持每个数据块的副本数量正常[8]。
副本的数量也称为复制因子,由NameNode管理,可以随时针对每个文件进行单独更改[9]。创建文件时,NameNode会向用户提供可以存储该数据的Data Node列表,该列表包含N个DataNode,其中N是复制因子。用户先将数据块传输到第一个本地的Data Node,之后该Data Node将数据块副本传输到列表中的第二个Data Node,第二个Data Node继续传输副本,直到第N个Data Node,数据就像在一个管道中传递。
1.3 HDFS默认的副本放置策略
HDFS通常被配置为由多个机架组成的集群,每个机架装配有多个DataNode。不同机架之间的节点通信需要依靠交换机等网络设备,所以同一机架节点之间的数据交换速度会快于不同机架中的节点。如果只考虑网络带宽的占用和数据访问时间,可以从同一个机架上选择几个Data Node存储所有数据块的副本,但是这样的系统是脆弱的,如果该机架出现故障,则数据将会全部丢失。
HDFS在执行数据块写入操作时,应用了一种平衡故障风险和访问速度的策略。如果复制因子为3,第一个副本放置在与客户端相同节点的Data Node上,第二个副本放置在同一个机架的另一个Data Node上,第三个副本放置在不同机架的DataNode上。如果复制因子大于3,第四个及后续的副本都随机放置在集群中。这种策略可以在网络、机架或交换机出现故障时提供更好的数据健壮性,并且优化了写入时间,因为2/3的数据量是在同一机架间交换的(复制因子为3时)。
这种策略存在一个问题,它在确定放置副本的Data Node时,没有考虑对副本的访问需求,事实上在创建数据块时,第一个副本总是放置在靠近“写入者”的Data Node上。这种副本放置策略可能会因集群上数据分布不均而影响处理性能。本文提出一种分析副本需求的方法,并开发一种综合考虑需求和处理性能实现重新放置副本的算法。通过模拟实验表明,通过对集群操作中对副本的需求进行分析后,将请求量最多的数据转移到能够最快处理它们的节点上,可以将处理性能显著提高[10]。
2 算法设计(Algorithm design)
2.1 评估数据块需求
在HDFS管理的数据块元数据中增加2个元数据C和T C。在一段可配置时间(比如一个月)内,C是数据块被查询率,即某数据块被下载的次数;T C是该数据块在这段时间内的平均读取时间。T C的计算公式参见公式(1)。其中,C是数据块被查询次数,t i是数据块第i次被查询时的读取时间。
Data Node在每次读取操作后计算这些元数据,并随数据块报告传输给Master。每当一个数据块被查询时,它相应的C和T C都会更新。NameNode使用一个包含所有数据块合并排序的数据表维护这两个元数据值,示例详见表1。
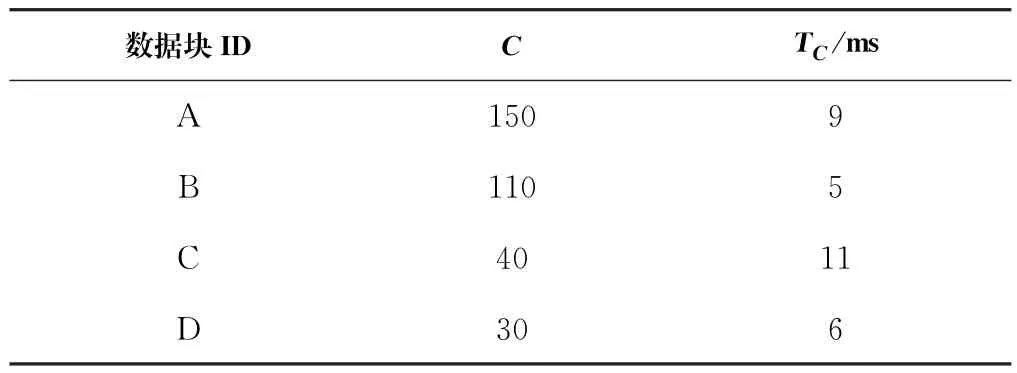
表1 数据块需求统计示例表Tab.1 Sample table of data chunk requirement statistics
理想状态下,统计表的每行应该是按照最大的请求数C对应最小的响应时间T C有序排列的。然而,通过对从模拟集群中回调的数据进行分析发现,高请求率的数据块响应时间相对较长。本文的目标是将请求最多的数据块移动到能提供最优读取时间的节点中。利用元数据计算每个节点平均性能的方法详见公式(2)。其中,P n是节点n的平均性能;k是节点n中数据块的数量;Ci是节点n中第i个数据块的被查询次数;是节点n中查询第i个数据块的平均读取时间。
将数据块移动到具有更快读取时间的位置,并不代表该数据块的响应时间会提高,因为平均响应时间还取决于客户端请求的性质(如发起读取请求的位置、数据处理性能等),但评估算法将继续收集被移动的数据块在其新位置上的响应时间,并重新评估是否需要将其移动到更好的位置。在数据块迭代进行几次移动后,平均查询时间会明显提高或者停滞在其最小值,这表示数据块在响应时间方面已处于最佳位置。数据块的移动操作应该在数据访问较少或没有的时候进行,这样网络带宽就不会被该操作过度占用。
2.2 算法设计
优化放置算法的流程:函数从最大查询次数开始扫描数据块,查询次数统计表,检索出请求数量最多的数据块。算法同时尝试检索具有最佳性能P n的可用节点,在理想情况下,具有最高被查询数C的数据块将被移动到具有最优平均性能P n的节点上。
优化放置算法步骤如下。第1步:读取数据块需求统计表chunks_Table(ChunkId,T C,C);第2步:按照C值对统计表进行降序排序,得到表chunks_Ordred Table;第3步:按顺序读取chunks_Ordred Table中ChunkId;第4步:当ChunkId不为空时,循环执行第5步,否则,执行第6步;第5步:移动数据块至节点(ChunkId,Get Best Node(ChunkId));第6 步:返回null。
上述算法中调用了获取最佳节点(Get Best Node)算法。这个算法可以为选定数据块建议一个能够提供最佳平均性能P n的节点。遍历表中数据块的平均查询时间,为统计表中的每个节点计算P n值,并根据P n值升序排序,检查每个节点是否与待放置数据块的参数匹配。
基于以下四个标准判断节点是否匹配,这些标准均符合Hadoop的基本策略,即同一机架中的副本不超过两个。①该节点与待放置数据块所在节点不是同一个;②该节点有充足的可用空间;③该节点尚未存储待放置数据块的副本;④该节点与待放置数据块的其他两个副本都不在同一个机架中。
Get Best Node算法步骤如下。第1步:读取待放置数据块C m;第2步:读取数据块需求统计表chunks_Table(ChunkId,T C,C);第3步:计算chunks_Table中每个数据块的P n值;第4步:按照P n值对统计表进行升序排序得到表chunks_Ordred Table;第5 步:按顺序读取chunks_Ordred Table中ChunkId;第6步:循环选择chunks_Ordred Table中下一个数据块所在节点N;第7步:当节点N的P n值小于C m的T C值且符合4个判断标准,返回节点N;第8步:循环结束。
3 实验与结果(Experiments and results)
3.1 实验设置
实验中模拟了一个由12个节点组成的集群,结构详见图1。使用Hadoop版本为2.5.0,Hadoop的数据块配置为64 MB,复制因子为3。实验中使用12个大小为64 MB的文件模拟待处理数据。该集群由3个机架组成,每个机架由4个节点组成,每个节点的存储容量等于数据块的3倍,即192 MB。每个节点的性能是不同的,每个机架上4个节点的配置见表2。同一机架内的带宽设为1 GB/s,机架之间的带宽配置见图1。
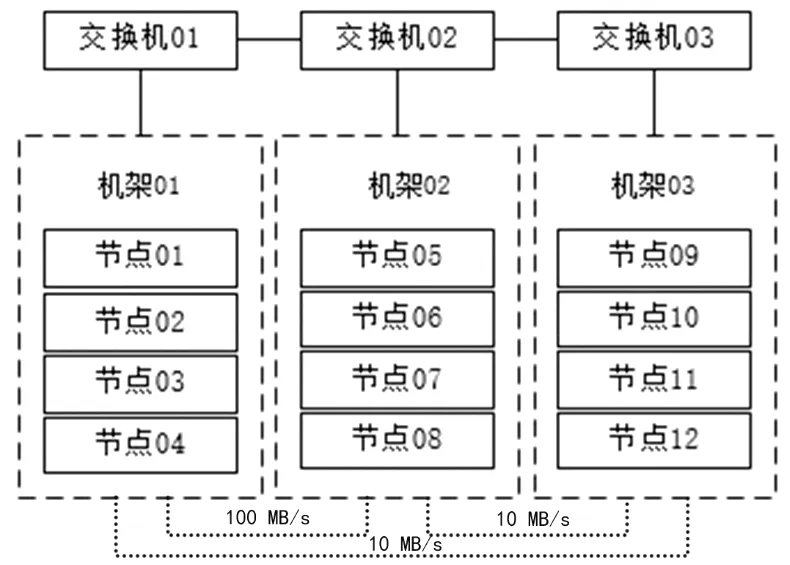
图1 实验模拟集群结构图Fig.1 Cluster structure in experiment
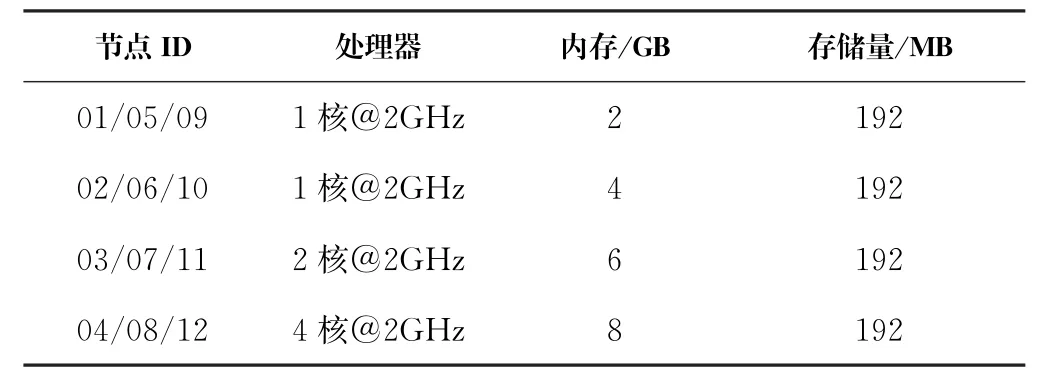
表2 节点配置表Tab.2 Nodes configuration table
由于每个节点最多只能存储三个数据块,所以在实验中可以迅速使节点存储达到饱和,便于更加准确地测试算法的性能。
测试作业为集群中的12个节点对每一个均匀分布存储在集群上的文件执行不同数量的Map任务。每个作业只调用一个文件,因此被请求数C等于执行的作业数。
实验步骤如下。第1步:在集群中按照Hadoop默认放置策略存储12个文件;第2步:运行测试作业;第3步:收集执行时间,并创建/更新统计表;第4步:计算平均性能值P;第5步:如果P值不理想,使用算法找出数据块的建议放置点,否则,实验结束;第6步:移动数据块至建议放置点,并由第2步开始重新执行。
上述步骤会迭代几次,在每次迭代后都会计算集群的整体性能P n值。通过比较默认副本放置策略和优化后的放置算法的P值评估优化算法的有效性。
3.2 试验结果
测试作业第一次运行后收集的结果见表3。
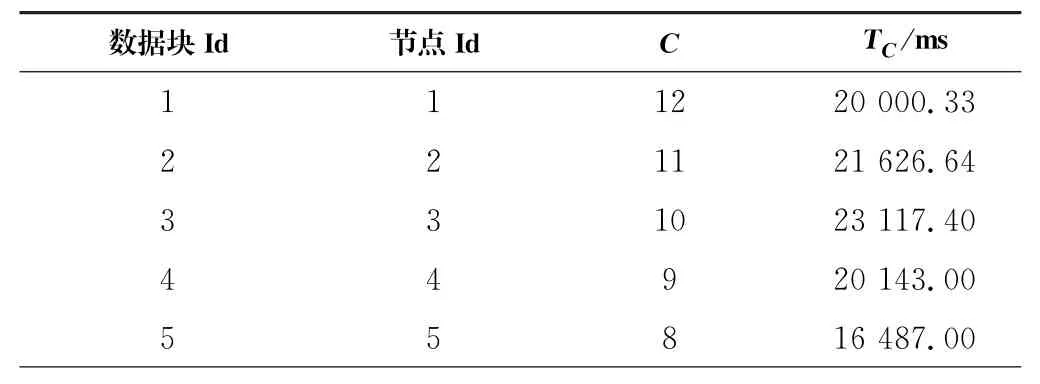
表3 数据块初始统计表Tab.3 Initial statistics table of data chunk
由于实验选用文件的大小与Hadoop数据块配置相同,一个文件对应一个数据块,所以每个作业只调用一个文件,C是执行作业的次数,也就等于数据块被请求数。将表4的数值代入公式(2)可以计算出集群的整体性能P1为25 594.86 ms,其中的T C值反映了Hadoop默认放置策略下的平均读取时间。
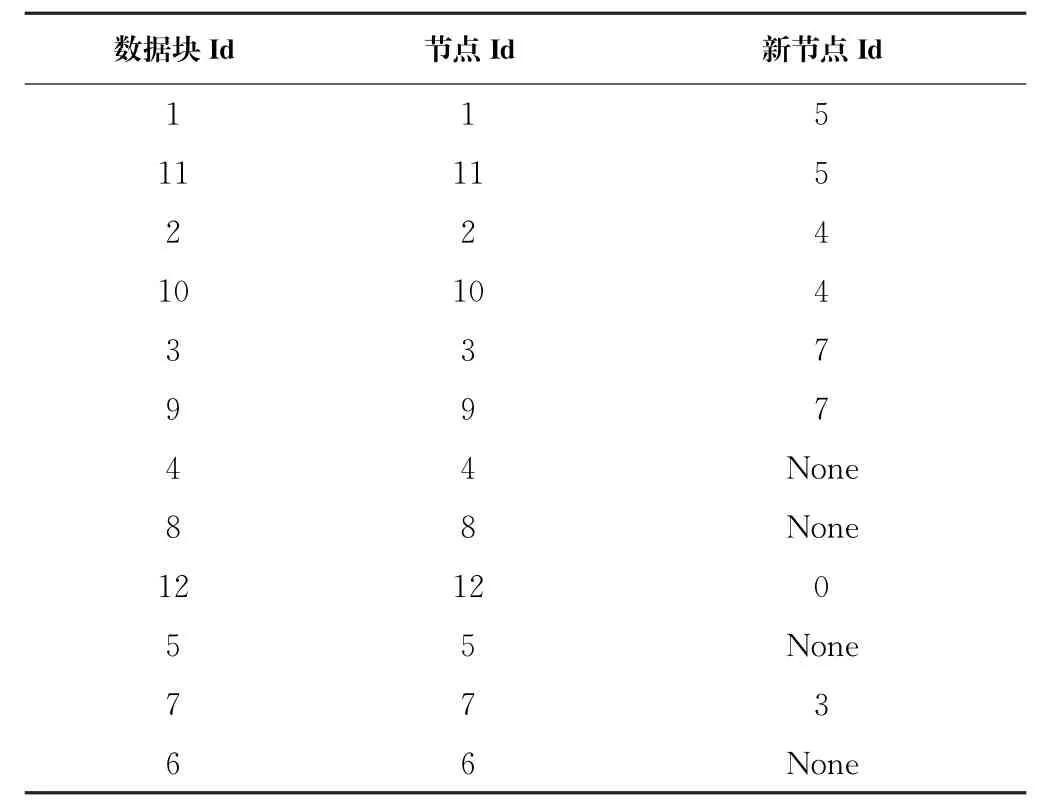
表4 数据块建议放置位置表Tab.4 Recommended placement table of data chunks
应用优化的数据放置算法后,得到的数据块放置建议见表4。算法建议将其中8个数据块放置到新的位置,剩下的4个数据块没有建议新位置,因为将它们放置到当前集群中的任何可用节点都不会缩短任务执行时间。
按照算法建议位置移动数据块后,再次运行相同的测试任务,重新计算的响应时间T C,结果见表5。
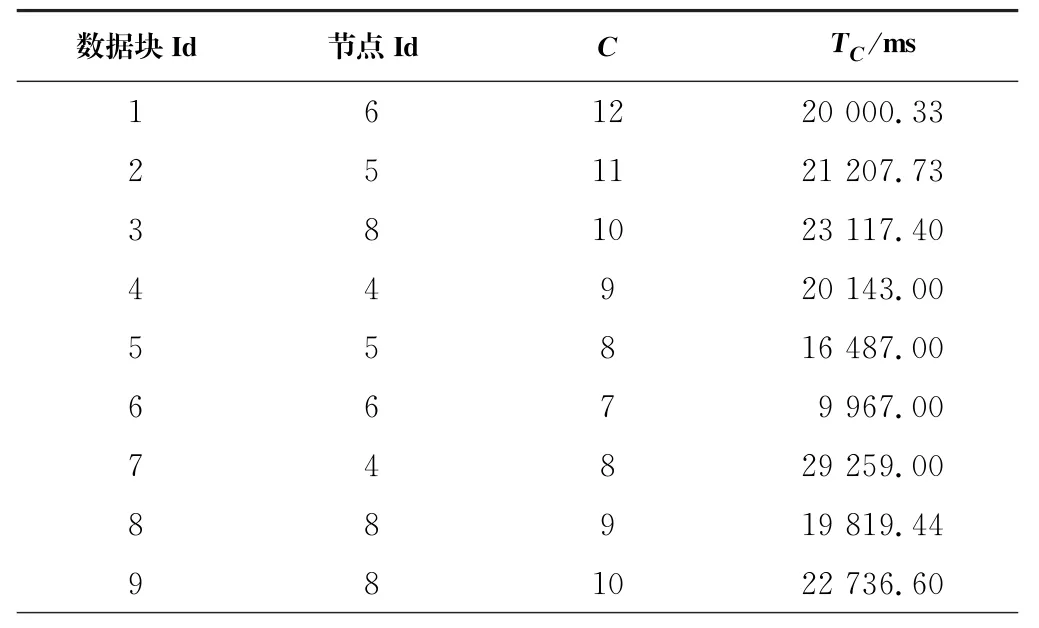
表5 第一次重新放置后数据块统计表Tab.5 Data chunks statistics table after the first replacement
将表5的数值代入公式(2)可以计算出集群的整体性能P2为20 125.21 ms,与集群初始整体性能P1相比,提高了21.37%。在执行5次测试任务后,后4次的集群整体性能P值依次为20 125.21 ms、20 098.96 ms、20 964.57 ms、20 732.94 ms。由此可看出,在第一次执行测试任务后,P值处于稳定状态,之后的数据块位置改变几乎不会再影响集群的整体性能,那么,可以认为数据块在第一次执行优化算法后就被放置在了最佳位置。
4 结论(Conclusion)
实验数据证明,在符合HDFS默认数据放置算法基本规则的前提下,提出的优化的数据放置策略算法,可以使集群的整体性能提高20%以上。并且,该算法执行一次即可使集群整体性能接近最优值,不会因为数据块频繁移动而过多占用集群的网络带宽。实验结果符合预期,优化后的数据块放置算法能够有效优化集群整体性能。
