基于姿态交换图像生成的行人重识别
2023-07-12沈江霖罗一平
沈江霖,魏 丹,罗一平
(上海工程技术大学机械与汽车工程学院,上海 201620)
0 引言(Introduction)
行人重识别是指利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术[1]。行人姿态训练鲁棒性是行人重识别模型中的关键问题之一[2]。现有方法仅包含有限数量的姿态变化,因此在训练过程中ReID模型容易出现过拟合的情况。与此同时,生成对抗网络在图像生成、图像编辑方面都取得了令人印象深刻的成果。在文献[3]中,生成对抗网络用于生成具有不同背景的样本以增强ReID模型,但该工作未考虑各种行人姿态。ZHENG等[4]使用生成的未标记样本改进生成对抗网络的性能,但是生成样本的严重失真限制了性能改进效果。本文提出了一种姿态可交换行人重识别框架(PSGNet),该框架将样本中的每一个人编码为姿态代码和视觉代码;通过切换姿态代码,生成高质量的姿态合成图像。在相关数据集上的实验结果表明,本文方法实现了性能改进,并优于大多数先进的方法。
1 姿态交换图像生成模型(Pose-switched image generation model)
姿态交换图像生成模型主要由生成模块、增强模块、判别模块三个部分组成,如图1所示。
1.1 生成模块
生成模块包括两个部分:自我ID生成和交叉ID生成。自我ID生成表示生成模块学习如何从自身重构图像。不同于以相同身份进行图像重建的自我ID生成,交叉ID生成侧重于以不同身份进行图像生成。
1.1.1 自我ID生成
输入两幅不同身份的图像x i和x j,基于生成模块中的编码器将每个行人图像分解成两个潜在空间:姿态空间和视觉空间。前者编码姿态(骨架)和骨架关节点位置相关结构信息,后者编码除姿态信息之外的其他身份相关语义信息。由此,行人图像被编码为姿态掩码p i、p j和视觉掩码v i、v j,通过交换姿态掩码p i和p j,利用解码器将视觉掩码和交换后的姿态掩码生成高质量的姿态合成图像x ij和x ji。采用L rec表示自我重建图像损失:
其中,E表示期望,G表示生成器,v i表示视觉空间编码得到的视觉特征,p i表示姿态空间编码得到的姿态特征。
1.1.2 交叉ID生成
自我身份图像生成以同一身份编码v i、p i进行图像重建,交叉身份图像生成侧重于以不同身份编码v i、p j进行图像生成。学习过程中姿态编码p i和p j可以交换信息。采用L cr-id表示交叉生成图像损失:
其中,E表示期望,G表示生成器,E v是视觉特征的解码器,v i是视觉空间编码x i得到的视觉特征,p j是姿态空间编码x j得到的姿态特征。利用解码器将视觉编码和交换后的姿态编码生成姿态合成图像x ij和x ji。
1.2 增强模块
由于生成模块已经生成一幅图像,虽然该图像比较粗糙,但是在姿态和基本颜色上与目标图像接近,因此在增强阶段,模型将通过纠正初始结果中的错误或缺失,专注于生成更多的细节,并且更好地引导图像的生成。增强模块包括图像的细化部分(增强器B1)和引导部分(增强器B2)。
1.2.1 图像细化(增强器B1)
第一阶段对生成具有交叉姿态的行人图像进行外观细节的填充和细化,其输入是生成模块中合成的粗糙图像x ij和x ji。考虑到粗糙图像x ij、x ji和目标图像在结构上相似,使用条件DCGAN的衍生模型作为基线。针对全连接层压缩输入中包含的大量信息,移除U-Net(U-网络)中的全连接层,使用U-Net生成一个外观差异映射,保留输入图像中更多的细节,使细化结果更接近目标图像[5]。
在传统的生成对抗网络(GAN)中,判别器负责区分真实图像和生成图像(由随机噪声生成)。然而,在本文的条件网络中,B1的输入不是随机噪声而是条件图像x ij、x i。因此,真实图像不仅是自然的,而且满足特定的要求。否则,B1将被误导为直接输出x i,x i本身是自然的,而不是细化第一阶段x ij的粗略结果。
与传统GAN的另一个不同之处在于,噪声不再是必要的。因此,增强器B1具有以下损失函数:
其中,L bce表示二进制交叉熵损失,D表示判别器,λ是生成器损失的权重。
1.2.2 图像引导(增强器B2)
针对第一阶段只考虑生成行人样本的视觉真实性,无法保证生成样本能够增强行人重识别模型训练。为此,引出增强模块的第二阶段,即引导生成样本(具有交叉姿态的样本),使经过训练的生成模型更适应行人重识别问题,提高行人重识别的判别能力。增强模块中的引导模块是一个分类(即交叉熵损失)的子网络。将第一阶段生成的图像输入引导模块B2中进行训练。引导模块在目标行人重识别数据集上进行预训练,并进行监督和识别。在生成模块的训练过程中,引导模块传递有判别性的身份信息,并将监督信号从引导模块传递到生成模块。增强器第二部分利用监督信息使得细化后的图像接近生成模块生成的图像x ij。
其中,d t表示类t的标签,v t表示类t图像的视觉特征,p t表示t类图像的姿态,表示增强器B2的输出概率分布。经过细化和引导的生成图像是适应与行人重识别的具有辨识力的各种姿态的标签图像。
1.3 判别模块
通过交换姿态代码生成的图像,将生成的图像视为与现有工作类似的训练样本。为了更好地利用这些生成的图像,可以进行主要特征学习。由于生成模块交叉ID合成图像中的类间差异,因此本文采用师生式监督。其中,教师模型只是一个基线卷积神经网络(CNN),在原始训练集上进行识别丢失训练。为了训练用于主要特征学习的判别模块,将判别模块预测的概率分布l(xij)和教师模型预测的概率分布k(x ij)之间的KL散度最小化:
其中,N表示身份的数量。
因为生成器基于图像x i,这同文献[6]的研究结果类似,所以本文对判别器D提出以下损失函数:
1.4 优化
整个行人样本生成网络包含三个组件,即生成器、增强器和判别器,本文训练姿态和视觉编码器、解码器、判别器和增强器,用于训练该生成网络的综合损失函数是上述所有损失的加权和:
其中,α和β是控制相关损失项重要性的权重。在模型的训练过程中,增强器传递鉴别身份信息,并将该监督信号从增强器传播到生成器,从而形成更容易被分类到正确人物类别的行人样本。
2 实验与结果分析(Experiments and analysis of results)
为了验证模型的有效性,本文分别在三个公共行人重识别数据集上进行了实验,其中包括Duke MTMC-reID[4]、CUHK03[7]和Market1501[8]数据集。实验表明模型生成的图像更加逼真和多样,并且在所有基准测试中,行人重识别准确度优于大多数现有新算法。
2.1 数据集
Duke MTMC-reID数据集是Duke MTMC数据集的一个子集,用于图像的重识别,它的训练组包含702个身份的16 522张图像。CUHK03数据集包含1 467个身份的14 096张照片,这些照片是由香港中文大学的两台摄像机拍摄的。Market1501是一个基于图像的ReID数据集,它由12 936张用于训练的图像组成,每个人在训练集中平均有17.2张图像。本文使用两个评估指标评估ReID算法的性能,即rank-1识别率和均值平均精度(mAP)。
2.2 实施细节
本文使用通道×高度×宽度表示特征图的大小。编码器E p是一个由4个卷积层和4个残差块组成浅层网络,输出的是128×64×32的姿态代码p。编码器E v是基于ImageNet上预训练的Res Net-50,移除其全局平均池化层和全连接层,然后附加自适应最大池化层以输出2 048×4×1的视觉代码v。解码器G由4个残差块和4个卷积层组成,每个残差块包含两个自适应实例归一化层,它们集成在一个尺度和偏差参数中。增强器B1包括N-2个卷积块的全卷积架构,其中N取决于输入的大小。每个残差块由两个步幅为1的卷积层和1个步幅为2的子采样卷积层组成。所有卷积层由3×3个滤波器组成,滤波器的数量随每个块线性增加。本文将线性修正单元激活函数(ReLU)应用于除全连接层和输出卷积层之外的每一层。增强器B2采用与文献[9]相同的网络架构,鉴别器D与文献[10]相同,鉴别器具有简单的堆叠结构。
对于Duke MTMC-reID和Market1501数据集,使用Adam优化器,β1=0.4,β2=0.999。初始学习率设置为e-2。在Duke MTMC-reID上,将卷积块的数量设置为N=4,分别用8个小批量的模型训练10k次迭代。在Market-1501数据集上,将卷积块的数量设为N=4,用14个小批量进行12k次迭代训练。对于CUHK03数据集,使用交叉熵损失训练Res Net-50。
生成器的输入大小调整为256×256,并重新缩放为[-1,1],它们来自目标数据集。生成器的输出被发送到鉴别器和引导器。在本文所有实验中,α和β分别设置为3.0和5.0。
2.3 比较结果和讨论
2.3.1 消融研究
首先研究增强器B1和增强器B2的贡献,将提出的方法与Res Net-50基线进行比较,结果如表1所示。可以观察到,在基线上的性能得到显著改进,主要特征在基线上有很大的改善。除此之外,增强器B2在基线性能上的提升比增强器B1显著,三个数据集上的rank-1平均提升11.9%,mAP平均提升14.9%,结果详见表1和表2。
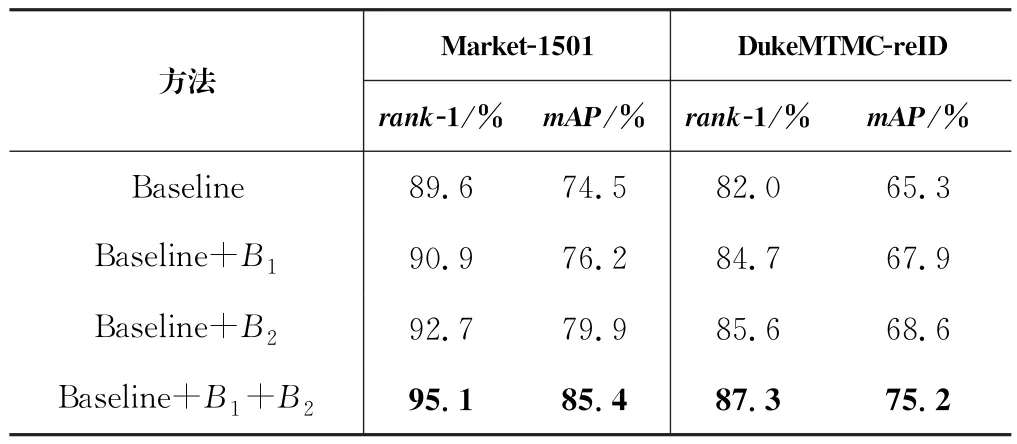
表1 基线、增强器在Market1501与Duke MTMC-reID数据集上的组合的比较Tab.1 Comparison of baseline and booster on Market1501 and DukeMTMC-reID datasets
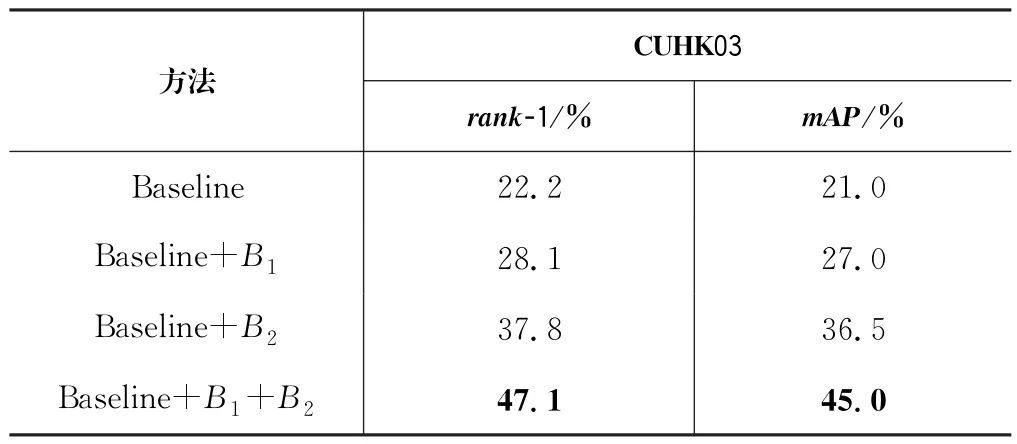
表2 基线、增强器在CUHK03数据集上的组合的比较Tab.2 Comparison of baseline and booster on CUHK03 dataset
2.3.2 与先进的方法进行比较
表3和表4中列出了姿态可交换行人重识别方法(PSGNet)与其他先进方法的比较结果。与使用单独生成的图像的方法相比,本文方法在Market-1501和Duke MTMC-reID数据集上的rank-1实现了明显增益,结果详见表3。
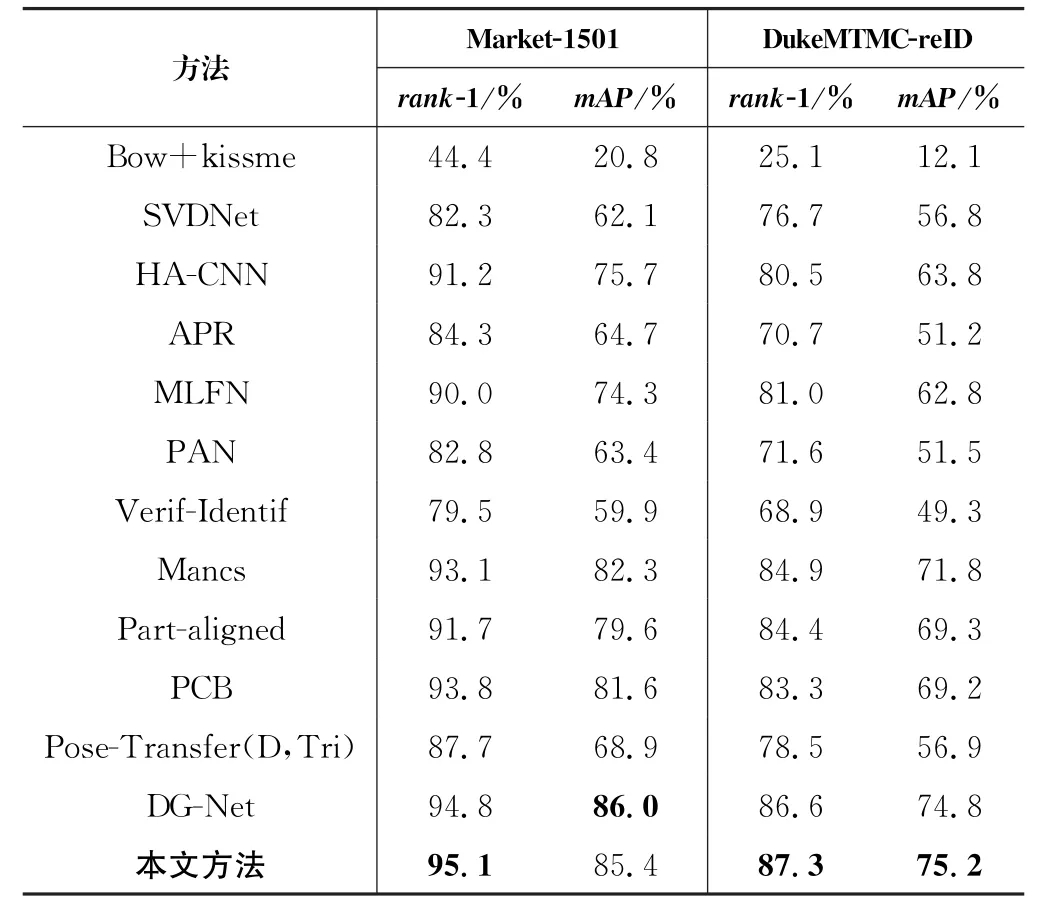
表3 将所提方法与Market1501和Duke MTMC-reID数据集上的最新技术进行比较Tab.3 Comparison of the proposed method with the state-o-f the-art technology on Market1501 and DukeMTMC-reID datasets
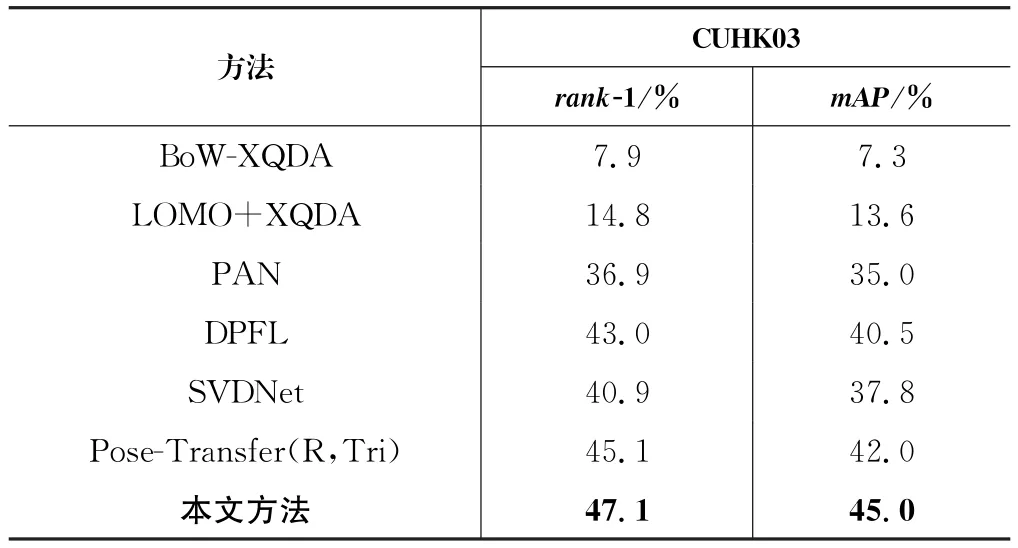
表4 将所提方法与CUHK03上的最新技术进行比较Tab.4 Comparison of the proposed method with the state-of-the-art technology on CUHK03
基于Res Net-50和交叉熵损失,PSG-Net优于大多数先进方法。对于数据集CUHK03,PSG-Net的性能在rank-1 和mAP两项指标上分别优于排第二的Pose-Transfer方法2.0%、3.0%,结果详见表4。
2.4 参数分析
2.4.1 姿势交换样本数N 的分析
本文分析目标数据集中每个图像的生成样本数如何影响ReID模型的性能。使用经过交叉熵损失训练的Res Net-50作为增强器,并改进ReID模型。对于每个图像,PSG-Net分别测试1~10个姿势交换样本对性能的影响。三个数据集的实验结果如图2所示,可以观察到当N=4时,验证准确性最高。随着扩展样本的数量进一步增加,性能略有下降。
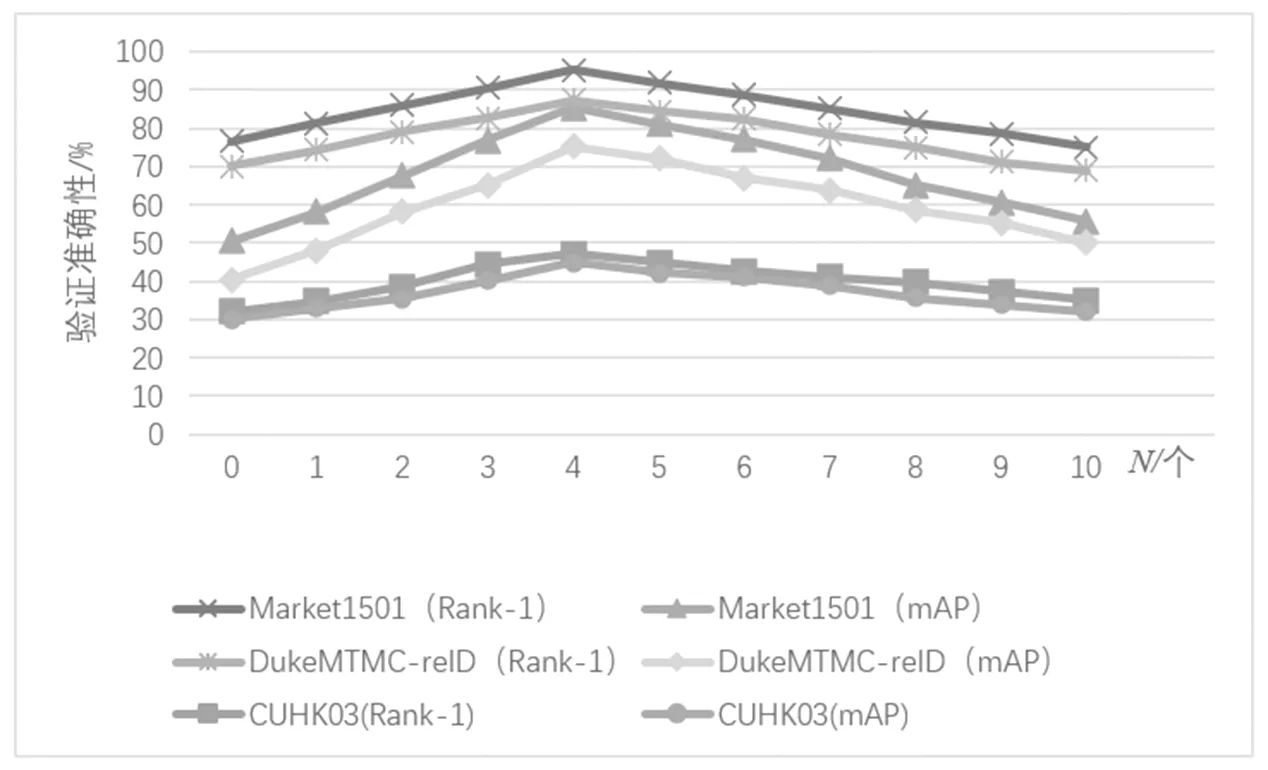
图2 参数N 对行人重识别模型性能的影响Fig.2 Theimpact of the parameter N on the performance of pedestrian re-identification models
2.4.2 超参数μ 的分析
这里的超参数μ,即α和β之间的比率,用来控制L B2-ce和L dis在训练中的重要性。从Duke MTMC-reID数据集的原始训练集中分离出来的验证集上验证参数μ。根据图3中的验证结果,本文在所有实验中选择μ=0.6。
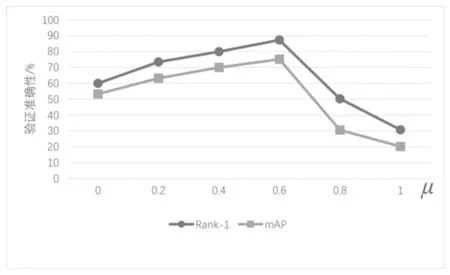
图3 重识别学习相关超参数μ 的分析Fig.3 Analysis of hyper-parametersμrelated to re-identification learning
2.5 可视化结果
本文在图4中演示了PSG-Net的生成结果,发现PSG-Net能够在Market-1501数据集中生成逼真和多样的图像。

图4 通过交换Market-1501数据集上的姿态代码生成的图像示例Fig.4 Examples of generated images by switching pose codes on the Market-1501 datasets
3 结论(Conclusion)
本文提出了一个姿态可交换行人重识别框架(PSG-Net),解决了现有基准不能提供足够的姿态覆盖训练鲁棒性行人重识别系统的问题。该框架将样本中的每个行人编码为姿态代码和视觉代码,通过切换姿态代码,生成高质量的姿态合成图像。在三个基准上的实验表明,本文提出的方法在图像生成质量和行人重识别精度方面有实质性的改进。
