面向汽车金融的行为评分卡设计与实现
2023-07-10水新莹
水新莹
关键词:汽车金融;行为评分卡;GPS 轨迹;数据质量;滚动率分析
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)14-0001-05
0 引言
近年来,随着汽车消费金融政策陆续出台,越来越多的车主通过汽车金融公司申请贷款购车。在市场竞争日趋激烈的背景下,为了获取更多的市场份额,一些汽车金融公司往往会降低对客户的审核标准,导致信用风险频发,业务逾期率逐年攀升,给汽车金融公司造成严重损失[1]。为有效降低信用风险,越来越多的汽车金融公司研发信用评分卡。通常而言,信用评分卡包括申请评分卡(发放贷款前对客户进行信用评价)、行为评分卡(发放贷款后对客户进行信用评价)和催收评分卡(产生逾期后对客户进行信用评价)[2]。目前,产业界和学术界的研究成果大多集中在申请评分卡,关于行为评分卡的研究较少。行为评分通过观测客户贷后行为特征,预测客户未来一定时间内变成“坏客户”的可能性,并对高风险客户实时预警。行为评分卡利用已有客户样本训练行为特征和风险的关联性,利用机器学习算法尽可能挖掘风险出现、发展和分布的规律,辅助汽车金融机构风险管理决策。
传统的信用风险评分卡模型多采用专家评分或回归算法,变量少,特征维数有限,非线性规律覆盖率低,难以挖掘客户与风险客户之间的相关性,难以适应当前消费贷款业务的快速发展[3]。统计方法中的线性判别分析[4]和逻辑回归[5],因易理解和易于实现,而被经常使用。机器学习方法中比较有代表性的包括决策树[6]、神经网络[7]、支持向量机[8]等。然而上述研究成果都是基于贷款静态信息的申请评分卡,很难直接用于行为评分卡。GPS定位器成为汽车金融风险管理的重要手段,在信用风险监控中应发挥作用。GPS 轨迹数据是基于时间和空间对车辆的移动过程进行采用并记录获得的数据,包含了车辆移动的经纬度、时间、车速、方向等信息。GPS数据蕴含了客户丰富的出行特征,对这些特征进行分析提取,对行为评分卡建模有重要作用。本文提出了一种融合客户GPS 轨迹数据和还款信息的行为评分卡,该模型在对客户贷/还款相关数据和GPS数据质量评价的基础上进行特征挖掘与衍生,并通过滚动率分析对好坏客户进行定义,最终通过模型融合的方法构建行为评分卡。
1 数据分析与处理
1.1 数据质量评价
在构建行为评分卡之前,需要对数据资源中涉及人、车、GPS等相关数据状况进行整体评价。本文根据《GB/T 36344-2018 信息技术数据质量评价指标》[9],选取完整性、准确性、冗余性和一致性来评价某汽车金融公司的数据质量。本文对某汽车金融公司311个数据项所产生的5 012 403条实体数据进行质量评价的结果如表1所示。
从表1可以看出:1)数据总体准确性得分较好,但客户基本信息表中多个字段缺失值严重,影响了准确性得分,需要进行数据的增强与填充,以达到构建行为评分卡模型的要求;2)GPS数据在时间、经纬度、速度、方向等方面数据缺失较少,有较高的利用价值,利用可视化这些轨迹信息,可以发现客户的日常活动范围与常去地点,从而获得用户的主要行为模式,这部分信息可作为后续入模时的衍生信息对客户进行建模。
1.2 数据探索性分析
数据探索性分析通过计算GPS经纬度数据及其他数据特征,并分析各特征变量的数据类型(数值型、日期型、文本型等)、分布特征(均值、方差、分位数、最大最小值)等,形成对数据初步的、轮廓性的认知。表2展示了GPS数值型数据探索性分析结果。结合数据质量评价结果,对GPS数据中每个数据字段进行统一筛查,检测每个数据字段的缺失值、重复值、离群点、错误数据等数据分布情况,结合业务和常识制定针对性的处理规则进行处理,如对缺失数据较多的字段进行删除。
从表2可以看出:经纬度数据存在明显的错误数值,最大最小值均存在超出范围的数值。因此,需要检查该数据精度是否符合要求,对不符合的数據要予以删除或修正。针对其他数据,对缺失的部分进行针对性的删除或填充,同时删除重复数据和错误数据,对离散数据进行分箱或归类操作。此外,对文本型数据进行编码处理,如归一化、标准化、onehot、word2vec?tor 处理。对日期型数据,进行年月日划分处理;对数值型数据,进行分类、分箱等处理。
2 滚动率分析
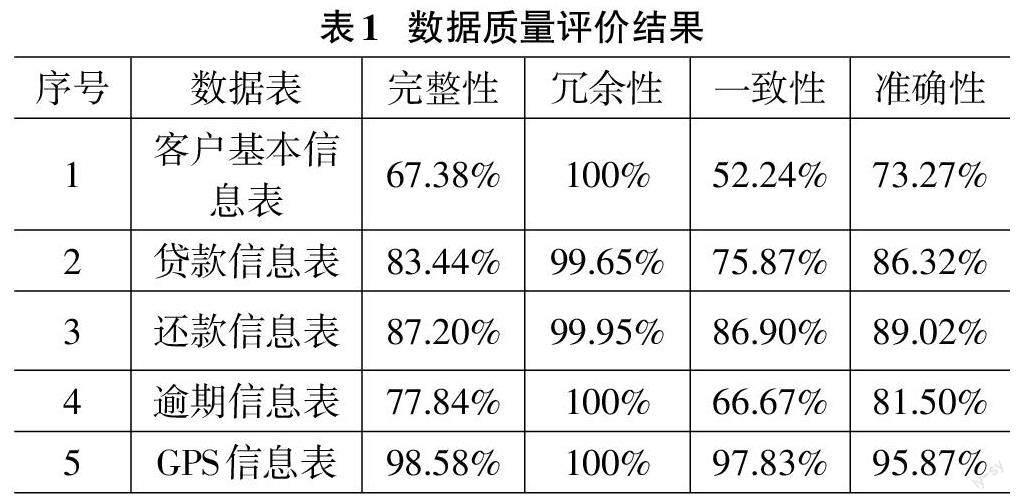
2.1 账龄分析
在表现期是在观察点之后对客户还款情况进行监测,着重监测客户的逾期情况。一般而言,表现期周期不应过短,而且应尽可能地将坏客户包括其中,从而保证在接下来能在这段时间内判定哪些是“好用户”、哪些是“坏用户”。本文统计了某汽车金融公司贷款客户的账龄(MOB,Month on Book)折线图,如图1 所示。可以看出,客户逾期率在16月之后上涨趋势趋于平缓,暴露比为67%。
2.2 好坏客户定义
在信贷风险管理资产质量分析中,通常使用滚动率分析来定义客户好坏程度[10]。通过统计样本在不同逾期状态中的递延状态,进而确定好坏样本的定义,运用滚动率分析观察客户在不同时间段内的滚动变化。
2.2.1 设定观察期和表现期
根据MOB分析,本文设定观察时点2021年1月1 日,观察点往前推m个月定义为观察期,观察点往后推n个月定义为表现期,初步设定m=12,n=12。对观察期和表现期逾期各个状态说明如表3所示。
2.2.2 构建转移矩阵
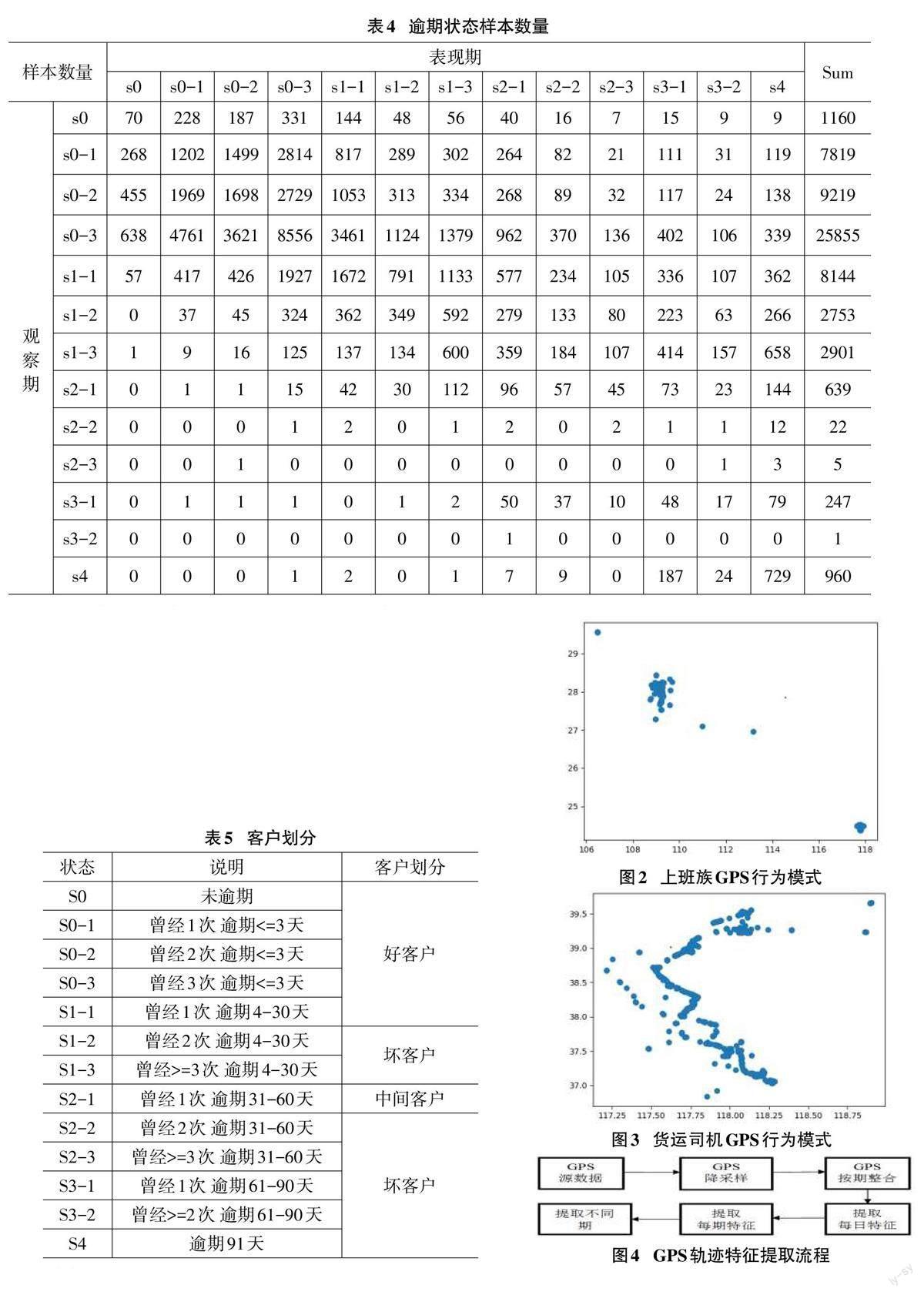
本文构建逾期情况矩阵,以观察期的逾期情况和表现期的逾期情况进行交叉统计,分别形成样本数量矩阵表和样本占比矩阵表(即滚动率分析表)。分别统计样本客户在观察期和表现期的最高逾期状态和样本数量分布,如表4所示。
2.2.3 客户定义
通常而言,可以根据逾期次数和天数衡量客户质量。在观察期最高逾期状态为S0、S0-1、S0-2和S0-3 的客户,状态保持S0之内均在70%左右,且向S4状态转移率均在1%左右,说明此类用户较多仍为“好客户”。S1-1状态保持率在44%左右,转好率在34%左右,转坏率为21%左右,因此也认定为“好客户”。S1-2状态保持率在47%左右,向坏转移率为38%,向好转移率为15%,因此认定为“坏客户”。S1-3用户向坏转移率为65%,向好转移率为5%,因此也认定为“坏客户”。S2-1状态保持率在30%左右,且向好和坏转移率均在30%左右,因此认定为“中间客户”。S2-2和S2-3的客户forward占比超过60%,且转好率较低,说明此类客户较多,仍为“坏客户”。根据汽车金融业务实际需求,S3-1、S3-2和S4必须被认定为“坏客户”。表5展示了客户划分的依据。
3 特征工程
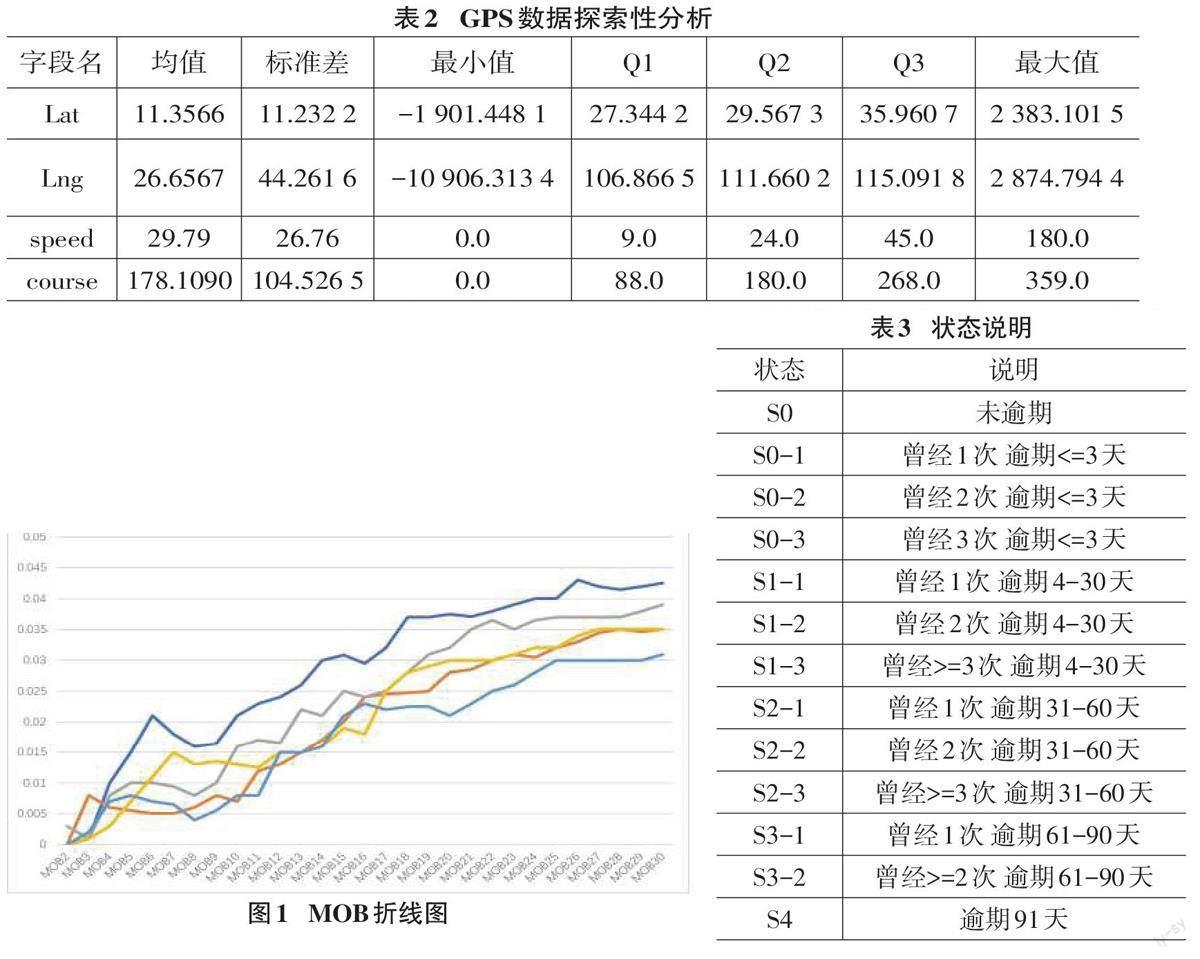
如1.1节分析,GPS数据在时间、经纬度、速度、方向等方面数据缺失较少,有较高的利用价值。经纬度数据精度较好,可以计算相邻经纬度之间的距离差,结合时间戳可以计算出客户在指定范围内的驾驶情况和停车情况。基于此,可以挖掘出客户日常出行规律,从而获得客户的主要行为模式,这部分信息可作为后续入模时的衍生信息进行建模。图2和图3分别展示了上班族和货运司机的行为模式。从图2和图3中可见:上班族停留点主要集中于两点,可能是家和公司;货运司机停留点存在较为连续的轨迹,说明其可能在固定线路上运载货物。由于本文构建的是行为评分卡,因此客户还款行为也是重要的特征来源。
3.1 基于GPS轨迹的特征挖掘
本文基于GPS 轨迹的特征提取流程如图4所示。首先,利用降采样得到车辆GPS轨迹数据。其次,根据不同客户放款时间拆分源GPS数据。最后,获取得到基于GPS的轨迹特征,包含基于GPS的驾驶特征、基于GPS的出行规律特征、基于GPS的异常信息特征、基于GPS的驾驶行为变化特征等几个维度对GPS数据进行特征提取。
3.1.1 基于GPS 经纬度数据的降采样
本文通过对GPS经纬度数据进行数据降采样,剔除GPS数据中的冗余数据,从原始数据中提炼出有价值的数据,在保证数据正确性的情况下,减少冗余数据对特征挖掘的影响,同时提高特征提取的效率。数据降采样的主要过程:首先对不同月份的GPS数据进行分批处理,采用数据预处理技术,剔除GPS数据中的错误数据,同时对待提取数据字段进行数据整合,包括数据类型统一和数据格式的确定,从而为下一步的数据降采样提供可靠的GPS基础数据。然后,采用Douglas-Peucker算法对待处理数据进行降采样操作,其中,针对相邻GPS数据频率不一致的情况,对待处理数据进行随机抽样,同时结合数据可视化技术,计算出在不同步长的情况下,使用Douglas–Peucker算法的最优参数,进而实现在保证GPS数据准确性的情况下,提高数据降采样的精度。
3.3.2 基于GPS 数据的驾驶习惯特征挖掘
本文通过对海量的GPS经纬度数据进行分析,从中提取出用户在不同时间的驾驶习惯特征,如白天驾驶行为特征和夜间驾驶时间特征。首先,采用日期转换方法对日期数据进行处理,统一日期数据格式,同时,根据不同模型的表现期和用户的月还款日期,提取出对应的GPS数据。然后,针对不同用户的GPS经纬度数据进行分批处理,采用统计学技术,计算车辆静止的时长和与其相邻GPS数据之间的距离,结合数据可视化技术,分析出车辆静止和运动之间的规律,进而得出车辆静止或运动的相关条件。然后,融合日期数据处理技术和经纬度距离计算技术,在划定不同时间区间的情况下,完成指定时间内的驾驶时长、驾驶里程以及停车时长等特征的提取。接着,通过计算每个特征的信息增量值,提取出信息增量值较大的特征,结合业务规则,利用统计学的方法分析其对模型效果提升的深层次因素,并在其基础进行时间区间的修改,完成相关特征变量的衍生,进而挖掘出更有价值的特征。
图5展示了本文基于GPS经纬度数据的特征挖掘框架,主要包括驾驶行为特征、出行规律特征、轨迹异常点特征和与上月出行变化特征。
3.2 基于还款行为的特征挖掘
本文基于還款信息行为的变量衍生如图6所示。通过数据探索性分析完成对还款行为数据的分析,并将其归类成数值型数据和字符型数据。首先,针对数值型数据,采用数据挖掘中的分箱技术对其进行分箱操作,完成特征变量的衍生。同时,针对字符型数据,采用字符串拼接技术对其进行数据拼接。然后采用信息增量的计算方法计算衍生特征对模型预测效果的强度,进而筛选出有价值的衍生特征。
本文通过分析客户逾期信息表,对逾期行为进行统计,得到逾期天数和次数等特征。结合客户还款和逾期行为,构建基于还款行为的特征衍生,对近一月、近两月和近三月的逾期情况分别统计,得到逾期天数、逾期<=3天次数以及逾期4~30天次数等特征。
4 模型训练
4.1 模型融合
在模型训练方面,本文采用基于逻辑回归、XG?Boost 和LightGBM 模型作为基分类器的模型融合方法。首先,根据滚动率分析,结合历史贷款用户的贷款情况、还款情况、逾期情况、曾经造成相关损失情况等,对贷款客户进行风险分类。其次,通过设置初始化模型参数,将筛选后的特征数据输入逻辑回归、XG?Boost和LightGBM模型中。然后,比对和分析上述三个模型的预测结果和预测性能,结合Voting融合算法对基分类器的输出结果进行加权集成,实现多模型的融合,最终训练出行为评分卡模型。考虑到本文中模型预测的结果为客户处于风险状态的概率情况,本文中使用soft-voting软投票机制,根据各个分类器分类的概率之和作为最终分类依据。相比于硬投票取各个投票器投票结果的多数作为最终分类结果,软投法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果:
其中,hji( x ) 是基分类器hi在类别标记cj上的输出结果,wi是hi的权重,H(x)为输出的类别标记。模型融合过程如图7所示。
4.2 超参调整
本文采用贝叶斯搜索对模型的超参数进行调整优化,利用已搜索的超参数组合信息形成的模型结果来指导新的超参数组合搜索信息,从而提升选择的下一组超参对应的模型质量以及模型整体优化速度。该方法主要由代理函数与构造采集函数构成:代理函数对目标函数进行建模,计算每一组超参对应点计算得到的函数值均值和方差;构造采集函数决定下一轮迭代时超参的选择方向。通过组合模型结果、代理函数结果与构造采集函数结果,对超参数的采样方向进行优化。
5 实验分析
5.1 实验环境
本文使用操作系统为Ubuntu 22.10,内存128GB,CPU为Intel i9-12900KF,GPU为NVIDIA Tesla A100。
5.2 数据集
为了评估行为评分卡模型的有效性,本文构建了一个由23 243个贷款客户从2020年1月到2021年12月的数据集,其中“坏客户”占比约为6.1%。数据集包含静态数据和动态数据:静态数据主要是客户基本信息和贷后还款信息;动态数据主要是客户每月GPS轨迹数据。本文从中選取了20 000数据作为训练集,2 000条数据作为验证集,1 243条数据作为测试集。
5.3 实验结果
本文采用准确率(ACC)、精确率(Precision)、召回率(Recall)和F1值作为行为评分卡评价指标。为了验证本文预测模型的性能,将本文模型与逻辑回归、XGBoost、LightGBM三个子模型进行对比,同时对比了使用硬投票(Hard Voting)机制进行融合的模型,具体实验结果如表6所示。由表可知,本文基于模型融合构建的行为评分卡在各项评价指标上均超过了其他模型的预测效果,因此证明了本文所提模型的有效性。具体来说,由于XGBoost和LightGBM均是在梯度提升迭代决策树(Gradient Boosting Decision Tree)的基础上进行优化,基于预测和实际值的残差进行训练,可以有效提升模型性能,因此取得了相较于逻辑回归更优的模型效果;而Hard Voting Model采用硬投票机制融合了三个模型的预测结果,因此取得了相较于单个模型最优的效果;硬投票机制只融合了模型分类结果,会导致预测信息的丢失,因此本文模型使用软投票(soft vot?ing)的方式融合了逻辑回归、XGBoost和LightGBM三个模型的预测结果,并取得了最优的模型性能,这也说明了软投票机制在本文模型中的有效性。
为了证明本文使用GPS作为模型特征的有效性,本文进行了消融实验。在消融实验中,采用去除GPS特征后的行为评分卡模型作为消融实验模型,实验结果表7所示。根据表中结果可以看出,本文使用GPS 特征作为模型特征可以有效提升模型预测效果,各项指标均有超过两个百分点的提升,这说明了GPS数据对于衡量客户风险也起到了非常重要的作用。
6 结束语
在多源异构数据融合的技术背景下,单纯依靠客户静态信息进行行为评分卡建模难以获得较好的性能。为此,本文提出了一种融合车辆GPS数据和客户还款信息的行为评分卡模型。该模型的创新点在于基于GPS数据的驾驶习惯特征挖掘,包括驾驶行为特征、出行规律特征、轨迹异常点特征和与上月出行变化特征。GPS衍生特征结合基于还款行为的特征衍生能够更好地捕获客户在贷款后的行为表现,对于预测客户放款后是否发生逾期风险有着较好的预测效果。未来,将知识图谱技术引入行为评分卡模型,通过图计算方式提取客户网络特征,进一步提示模型效果。
