基于深度强化学习的空战机动决策试验
2023-06-27章胜周攀何扬黄江涛刘刚唐骥罡贾怀智杜昕
章胜,周攀,何扬,黄江涛,,刘刚,唐骥罡,贾怀智,杜昕
1.中国空气动力研究与发展中心 空天技术研究所,绵阳 621000
2.中国空气动力研究与发展中心,绵阳 621000
3.西北工业大学 航空学院,西安 710000
空战智能决策将极大改变未来战争的形态与模式,对战争发展有着颠覆性的影响,随着人工智能技术的快速进步,智能为王的空战时代已然呼之欲出[1]。空战智能决策模拟作战飞行员在各种空战态势下对飞行器操纵的决策,它是智能作战飞行器的“灵魂”和“大脑”。具有自主决策能力的飞行器在反应速度上完胜人类,同时不用考虑飞行中人类的生理极限,其超算能力能更加准确地预测战斗的发展以取得对抗的主动权,但是飞行器空战对抗问题十分复杂,具有高动态、强实时的特征与更大规模的解空间,这给空战智能决策实现带来了巨大的挑战[2]。根据交战范围,空战可划分为近距空战、中距空战和远距空战。虽然随着空基武器的发展,空战战场已从近距拓展到中远距,但是近距空战不仅没有被忽视,而且相关技术得到了迅猛发展[3],研究表明:由于隐身以及电子对抗技术的进步,未来仍有25%~40%的空战会在近距离展开,因此近距空战研究仍具有重要的现实意义[4]。近距空战中,飞行器需要做大量战术机动以规避敌机并构成武器发射条件,因此机动决策是近距空战决策的基础,也是近距空战智能决策研究中需要解决的关键问题[5]。
国内外学者针对近距空战机动智能决策开展了大量研究,相关研究可以追溯到20世纪60年代美国航空航天局(National Aeronautics and Space Administration,NASA)兰利研究中心的自适应机动逻辑(Adaptive Maneuvering Logic,AML)系统[6]。传统的空战机动决策方法一般可以分为基于博弈理论的方法[7]、基于优化理论的方法[8]和基于专家系统的方法[9]。在历经专家机动逻辑、自动规则生成与规则演进阶段后,空战机动智能决策取得了长足的进步与发展[2]。2016年6月,美国辛辛那提大学与空军研究实验室发展了基于模糊树的“Alpha空战”系统,该系统在模拟空战中成功击败了拥有丰富经验的退役美国空军上校基恩·李[10]。随着深度学习的兴起,目前人工智能(Artificial Intelligence,AI)已经迈入深度学习时代,基于深度强化学习的智能决策研究取得了实质性进展[11-12],在2020年8月美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)举办的“AlphaDogfight”人机空战对抗赛中,苍鹭公司设计的基于深度强化学习的空战智能决策机以5∶0的比分完胜人类飞行员,引起了全球各国的密切关注[13-14]。国内学者也开展了基于深度强化学习的空战机动智能决策研究,将包括启发式强化学习[15]、Q网络强化学习[16]、深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法[17]、多智能体近端策略优化(Multi-agent Proximal Policy Optimization MAPPO)算法[18]、极大极小深度Q网络(Minimax Deep Q Network,Minimax DQN)算法[19]、双延迟深度确定性策略梯度(Twin Delayed Deep Deterministic Policy Gradient,TD3)算法[20]、多智能体TD3(Multi-agent TD3,MATD3)算法[21]在内的各种先进强化学习方法应用于空战决策背景问题并进行了数值仿真验证,其中文献[20]基于人机对抗仿真平台开展了模拟空战,仿真结果表明智能决策机能够在近距空战过程中压制人类“飞行员”。
在算法研究蓬勃开展的同时,以美国为代表的西方国家还大力推进空战智能决策算法的落地应用。在空战演进(Air Combat Evolution,ACE)项目的支持下,苍鹭公司正在开展将AI系统整合到L-39“信天翁”喷气式飞机的研究,据报道目前已进行了70多次飞行试验[22]。此外,美国空军提出了天空博格人(Skyborg)AI空中对抗实验验证平台项目,大力推进从软件算法到硬件实现相关技术的发展。相较于空战智能决策算法的研究,目前国内在空战决策工程实现方面的研究相对较少,许多智能决策研究工作主要通过仿真进行验证,而在软硬件实现及飞行试验方面的工作鲜有报告。未来空战是智能为王的时代[23],智能决策需要处理复杂的态势信息并迅速实现空战观察-判断-决策-行动(Observation-Orientation-Decision-Action,OODA)环的闭环,其中存在的巨大计算量对相应的软硬件体系架构提出了特殊的要求。因此,发展满足智能决策需求的软硬件架构、将先进的理论算法研究与可靠的工程技术实现相结合,解决工程应用中的安全性、可靠性、迁移性等问题,是推进空战智能决策技术落地应用中十分重要的工作。
本文针对双机近距空战机动决策问题,开展机动智能决策的模型设计、算法实现、硬件开发与飞行试验研究。为了提高飞行器空战机动决策的可靠性,提出一种便于工程应用的飞行器近距空战智能机动决策实现方法,通过结合成熟的飞行控制技术,发展出基于航迹导引指令的空战机动决策与控制方案。为满足空战智能决策中深度神经网络巨大的计算量要求,设计一种将机动智能决策与飞行自动控制分离的硬件架构,以实现真实对抗环境下的在线智能决策计算。最后,开展将智能无人机与人类“飞行员”遥控无人机进行对抗的飞行试验。
1 双机近距空战对抗数学模型
1.1 飞机质心运动动力学模型
首先定义飞机机体坐标系b与地面坐标系g[24],如图1所示,体系b与飞机固连,原点ob位于飞机质心,obxb轴在飞机对称面内并指向机头,obyb轴垂直于飞机对称面指向机身右方,obzb轴在飞机对称面内指向机身下方。地面坐标系g采用北东地坐标系,其原点og位于地面某点,ogxg轴位于水平面,指向正北方向,ogyg轴指向正东方向,ogzg轴沿竖直方向,指向地心。由于地面坐标系ogzg轴指向朝下,飞行器的高度为h=-z。飞机在地面系中的位置矢量为r=[xy-h]T,x、y分别为飞行器在地面坐标系的横坐标与纵坐标;速度矢量为v。

图1 飞行器在地面坐标系下的位置与速度Fig.1 Aircraft’s position and velocity in ground coordinate frame
飞行器质心运动学方程为
飞机质心动力学方程为
式中:v=[VcosγcosχVcosγsinχ-Vsinγ]T;V为速度幅值;χ为航迹方位角;γ为航迹倾角;F为飞机上受到的所有外力,包括气动力、发动机推力与地球重力;m为飞机质量,通过运动学方程,动力学方程又可以写为
由于飞行器推力一般沿着机体系的x轴方向,在假设飞行器侧滑角为零的前提下,V、χ、γ的微分方程分别为
式中:α为迎角;μ为速度滚转角为发动机油门;T为发动机推力;Tmax为发动机最大推力,其一般为高度与马赫数的函数;D、L分别为飞机受到的阻力与升力;g为重力加速度。
飞机气动力模型为
式中:S为飞机参考面积为动压;ρ为大气密度,为高度h的函数;CD、CL分别为飞行器的阻力系数与升力系数,不考虑舵面偏角与侧滑角的影响,其均为迎角的函数,可以写为CD=CD(α)、CL=CL(α)。
综上,飞行器航迹运动模型中,状态量可取为X=[xyhVγχ]T,控制量可取为U=[αημ]T。
1.2 双机空战对抗态势评估
双机近距空战场景如图2所示,红蓝双方飞行器在视距范围内进行对抗,其中红机的位置矢量表示为rR,速度矢量表示为vR,蓝机的位置矢量表示为rB,速度矢量表示为vB,以红机为参考,从红机指向蓝机的位置矢量为rRB=rB-rR,蓝机相对于红机的速度矢量为vRB=vB-vR。空战中,飞行器将综合敌我双方状态信息,通过机动获取有利态势,达到目标锁定与武器发射条件,实现有效消灭对方、同时保存自身的作战目的。

图2 双机近距空战对抗场景示意图Fig.2 Schematic diagram of one-to-one fighters’close-range air combat scene
近距空战中影响空战态势的因素包括2个方面:一是飞机静态性能因素,如飞机本体性能、机载设备性能;二是基于空间位置、速度关系的动态因素,包括角度、速度、高度、距离4个方面[25]。针对动态因素进行评估,通过考虑双方的位置与速度,建立自身相对于对方的攻击角度优势评估函数、速度优势评估函数、高度优势评估函数、距离优势评估函数,从而实现对态势的量化描述。下面以红机为例,给出红机相对于蓝机的态势优势评估函数。
1) 角度优势评估函数
如图2所示,基于红蓝双方的位置、速度信息,定义红机的攻击角φattR为
式中:VR=‖‖vR为红机的速度幅值。定义蓝机的逃逸角φescB为
式中:VB=‖vB‖为蓝机的速度幅值。根据红机的攻击角与蓝机的逃逸角,红机的角度优势评估函数定义为
显然,当红机对蓝机处于理想尾追状态时fφ=1,反之fφ=0。
2) 速度优势评估函数
速度优势主要基于双方的速度幅值进行定义,红机的速度优势评估函数公式[26]为
式中:Vopt为红机的最佳空战速度。
3) 高度优势评估函数
高度优势评估函数[20]为
式中:评估函数͂的计算公式[26]为
式中:hR、hB分别为红机和蓝机的高度;hopt为最佳空战高度。调整评估量Δfh为
式中:γR为红机的航迹倾角;Vopt为最佳空战速度;h0为一个常值参数。之所以引入Δfh是因为研究发现当对抗双方高度较低时,飞行器有较大概率在敌机的诱导下坠地,因此引入该项来评价飞机在高度过低时自主纠正高度对态势的影响[20]。当飞机高度较大时,Δfh较小,对高度优势评估函数fh影响较小;当飞机高度较小时,Δfh较大,此时高度评估函数对高度变化比较敏感,飞机增加高度可以获得更大的优势,避免坠地。4) 距离优势评估函数距离优势评估函数为
式中:‖rRB‖为双机之间的距离;dopt为红机的最佳空战距离;d0为一个常值参数。
综合上述4个评估函数,最终的态势优势评估函数为
式中:ωφ、ωV、ωh、ωd分别为角度优势、速度优势、高度优势、距离优势评估函数对应的权重参数。
2 空战机动深度强化学习决策机设计
决策机设计是飞行器近距空战机动决策飞行试验的基础。如图3所示方案,在针对具体飞行器建模构建仿真平台形成虚拟交互环境的基础上,综合强化学习的探索与利用、优先经验回放等机制,首先开展近距空战机动深度强化学习决策机设计,并通过数值仿真验证决策机的性能;然后进一步针对工程实现发展可行的空战机动决策及控制架构,进行相应的飞行硬件实现与机载算法开发;最后开展双机近距空战对抗飞行演示试验,验证智能决策技术。本节介绍深度强化学习智能决策机的具体设计。

图3 飞行器近距空战机动决策飞行试验研究方案Fig.3 Research scheme for the flight test of maneuver decision-making in aircraft close-range air combat
深度强化学习结合了强化学习的决策能力与深度学习的特征提取能力[27],是实现AI的重要途径,AlphaGo之父Silver[28]甚至提出“AI=强化学习+深度学习”。深度强化学习与空战问题的交叉融合,为空战智能决策的实现提供了新的途径。空战中,飞行器将在机载雷达等传感器设备与后端指挥控制系统的信息支援下展开作战,为简化问题,本文假设对抗时飞行器可以通过本体及支援信息系统获得对方的航迹运动信息,包括位置信息与速度信息。结合飞行器自身的状态数据,双机空战机动智能决策问题中的状态信息可设定为确定维数的矢量,由于“全连接”前馈型多隐层深度神经网络适合于该类输入下决策机的建模,因此本文采用该种神经网络模型进行建模。训练方面,综合目前解决“连续状态、连续动作”类型问题的主流深度强化学习算法,本文选择TD3方法进行智能决策机的训练,它采用Actor-Critic架构,具有良好的数据利用效率与收敛性[29]。
针对Defender 180模型飞机(见图4)开展研究,飞机质量为m=2.8 kg,翼展为180 cm,参考面积为S=0.456 m2,最大推力为Tmax=13.2 N,飞机气动力模型采用计算流体动力学(Computational Fluid Dynamics,CFD)数值软件进行计算,图5给出了相关结果,图中方格点代表CFD计算的状态点。

图4 Defender 180模型飞机Fig.4 Defender 180 model aircraft

图5 Defender 180飞机气动力模型Fig.5 Aerodynamic model of Defender 180 aircraft
神经网络决策机的特征输入量选择中,理论上能完全表征敌我状态的数据都可以用作神经网络的输入,但在实践中特征量的具体选取对决策机的训练效率以及后续应用影响很大。参考文献[20],输入量包括对抗双方的相对位置rRB、相对速度vRB等信息。虽然rRB、vRB采用机体视角下的描述更易于强化学习的定解与收敛,但对工程实现而言,采用地面系下描述的rRB、vRB可以避免工程实现中将位速信息转化为体系下的描述时引入的误差,具有更好的实用性能。
采用Pytorch进行智能决策机建模,Actor神经网络模型包含7层,其中输出层有3个输出单元,代表飞行器质心运动模型的3个控制量:迎角α、油门η、速度滚转角μ,模型中5个隐藏层的单元数均取为256,采用ReLU(Recified Linear Unit)激活函数,输出层为Tanh激活函数。由于动作价值函数更为复杂,Critic网络模型为11层结构,除输入层与输出层外,还有9个隐藏层,隐藏层单元数均取为256,激活函数为ReLu函数,输出层为线性输出。
飞行器空战的目的是消灭对方、保存自身,其本质上是零和博弈问题,理论上只有对抗结束后才能给出最终的确切奖励,但是由于动态对抗态势对飞行器空战博弈十分重要,本文利用奖励重塑技术[20],通过将态势评估函数值作为奖励引导飞行器占据对抗优势,从而避免稀疏奖励带来的训练难以收敛的问题,因此,奖励函数构造为
根据具体研究对象以及近距空战中不同优势评估函数的重要程度,奖励计算中相关参数的取值如表1所示。

表1 态势评估函数中的参数取值Table 1 Value of parameters in situation assessment function
双机近距空战机动决策机训练中,红蓝双方飞机均为Defender 180,红机(智能体)的初始位置坐标为rR=[00hR]T,其中hR服从[10,200]m区间的均匀分布,速度指向正东,蓝机(敌方)在以红机为中心的立方体空间位置区域中随机出现,速度方向及大小随机。决策机训练中一个周期(episode)长度为1 000 ΔT,其中ΔT=0.1 s。在一个周期结束后对Critic网络与Actor网络参数同时进行训练,mini-batch大小取为N=128,为提升训练效率,训练中采用了基于价值的优先经验样本回访技术[30],利用Adam优化方法更新参数,Critic网络、Actor网络的学习率分别取为2×10-4、1×10-4。图6给出了训练过程中智能体的奖励曲线,从图中可以看到,随着训练次数的增加,智能体的平均奖励稳步上升,当训练轮数达到20 990次时,智能体的平均奖励达到峰值,随后趋于稳定。

图6 空战机动智能决策机训练曲线Fig.6 Training profile of intelligent decision-making machine for air combat maneuver
为验证训练得到的智能决策机的性能,将其与由专家系统驱动的蓝机进行三自由度空战对抗仿真[31],红蓝双方从相同高度、相同速度、距离200 m相向飞行开始,图7给出三维空间中红蓝双机对抗的场景,从图中可以看到双方为夺取态势优势进行了缠斗,蓝机希望通过转弯机动,摆脱红机的追逐,而红机则利用更强的决策能力,在对抗中占据对抗优势,将蓝机置于自身的有效攻击范围之内。图8给出了双方对抗过程中的态势评估函数,可以看到红机在对抗期间的大部分时间内占据了对抗优势,说明智能决策机的设计是有效的。

图7 红蓝双机近距空战对抗仿真空间三维航迹Fig.7 Simulated 3D trajectories of close-range air combat between red and blue aircraft

图8 红蓝双机近距空战对抗仿真态势评估结果Fig.8 Simulated situation assessment results for closerange air combat between red and blue aircraft
3 空战机动决策实现
从虚拟仿真到真实飞行的迁移是智能空战中需要解决的关键问题[2]。由于虚拟仿真环境相对于真实物理环境始终存在误差,导致在虚拟仿真环境中习得的最优策略难以直接应用于真实物理环境,因此,发展可靠的机动决策及控制实现框架对智能空战工程实践十分重要。第2节设计的决策机处理特征输入后最终输出的是迎角等指令信息,而迎角指令的准确性依赖于气动模型的准确性,同时飞行中如果直接对迎角进行控制,则需要昂贵的迎角传感器提供迎角信息。尤其需要指出的是,不同的决策机可能给出不同的决策指令,如不同于本文神经网络决策机给出的是迎角、油门和速度滚转角决策指令,专家系统可能给出的是标准机动动作模板[31],这会导致不同决策系统间无法兼容,而系统架构实现的灵活性与通用性也是工程应用中关注的重点之一。
为了消除由于实际对象与理论模型间误差引起的决策品质降低,提高机动控制的可靠性,本文发展了基于航迹导引指令的机动实现方案,具体将迎角等指令转换为航迹指令后再利用通用控制系统进行跟踪。图9给出了飞行器近距空战机动决策及控制系统架构,其中包括3个层次:在确定近距空战对抗任务后,无人机将根据近距空战机动决策机,综合敌我双方状态信息,通过一定的决策模型或算法,输出飞行器机动的航迹导引指令;而后无人机跟踪控制器将实现决策机给出的航迹指令,通过一定的控制方法进行解算,输出气动舵面与发动机油门控制指令;无人机接收控制指令进行机动,夺取对抗态势优势。
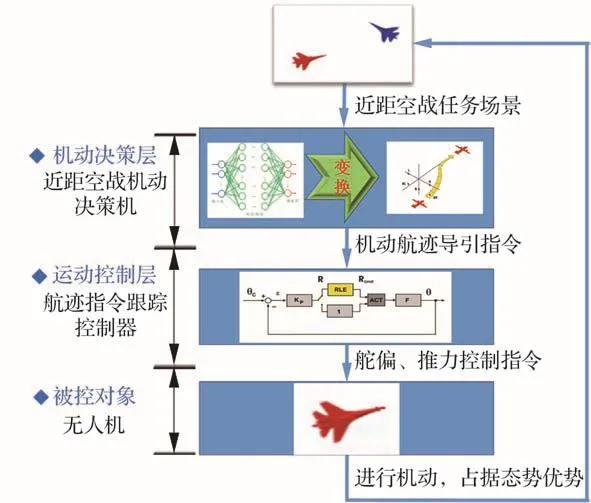
图9 飞行器近距空战机动决策及控制系统架构Fig.9 Decision-making and control system architecture for close-range air combat maneuver of aircraft
1) 机动航迹导引指令计算
不同的决策系统可能给出不同的决策指令,但无论何种动作决策,其目的仍然是飞行器达到有利的对抗态势,而态势优势体现在良好的位置与速度优势,因此,空战机动的核心与关键是在空间中取得占优的位速。为了提高机动动作实现的可靠性以及控制实现的通用性,消除诸如气动模型误差带来的不利影响,在第2节强化学习决策机给出的决策指令Uc=[αcηcμc]T中,将迎角指令αc与油门指令ηc转换为航迹高度指令hc与速度幅值指令Vc,具体通过数值积分计算为
式中:Δt为积分步长分别为当前t时刻红机的速度幅值、航迹倾角、高度分别为预测的红机下一步时刻t+Δt的速度幅值、航迹倾角、高度。通过式(19)~式(21),决策机最终给出的机动航迹导引指令为
2) 导引指令跟踪控制
针对机动航迹导引指令,采用成熟的比例-积分-微分(Proportional-Integral-Derivative,PID)控制律进行跟踪[32],得到相应的气动舵面与发动机油门控制指令。
对于高度指令hc,通过升降舵δe进行调节,控制律为
式中:q为飞行器俯仰角速度;θ为俯仰角;θc为俯仰角指令;kq、kθ分别为俯仰角速度与俯仰角误差的比例控制增益,俯仰角指令θc计算为
式中:Vz为飞行器纵向速度;kh、kVz分别为高度控制与速度控制的比例增益;kih为高度控制的积分增益。
对于速度指令Vc,通过油门η进行控制,控制律为
式中:V为飞行器速度幅值;kpV、kiV分别为速度误差比例项与速度误差积分项的控制增益。
在侧滑角β很小的情况下,飞行器的滚转角ϕ与速度滚转角μ差别很小。因此,对于速度滚转角指令μc,采用直接对滚转角ϕ进行控制的方式实现,取滚转角指令为ϕc=μc,通过副翼δa进行控制,飞行器滚转角控制律为
式中:p为飞行器滚转角速度;kp、kpϕ分别为滚转角速度和滚转角误差的比例控制增益;kiϕ为滚转角误差的积分控制增益。
此外,将方向舵δr用于偏航速率阻尼、侧滑消除与协调转弯,其控制律形式为
式中:r为飞行器偏航角速度;kr、kβ、krϕ分别为偏航角速度误差、侧滑角、滚转角的比例控制增益;rc为通过配合滚转角实现协调转弯求得的指令偏航角速度。由于目前飞机中没有安装侧滑角传感器,因此控制增益kβ置为0。
4 飞行硬件及机载算法实现
针对飞行试验,将设计的决策机及控制器进行工程实现。飞行器近距空战对抗飞行试验方案如图10所示,试验中,红机为智能无人机,采用本文发展的方法进行机动决策,蓝机由人类“飞行员”进行遥控操纵,双方在视距范围内进行对抗,飞行器状态通过地面站进行监控。决策算法工程实现包括硬件方案及软件架构的确定,其中的重点是进行决策机软硬件的开发、调试,解决深度神经网络的在线实时决策计算问题与将Python决策机模型“翻译”为控制计算机硬件支持的程序格式问题。

图10 飞行器双机近距空战对抗飞行试验方案Fig.10 Flight test scheme for one-to-one close-range air combat
4.1 硬件方案
由于深度神经网络决策模型涉及到大量的循环计算,对计算资源消耗很大,传统飞控计算机的性能可能无法满足要求。同时,为了增强智能决策机功能实现的灵活性,对红机采用”飞控计算机+外置决策计算机”的双硬件方案,如图11所示,其中飞控计算机使用PixHawk雷迅V5+飞控硬件,决策机采用NVIDIA Jexton TX2嵌入式计算机。飞控计算机控制频率为100 Hz,决策计算机决策频率为25 Hz,两者之间通过串口进行通信。此外,全球定位系统(Global Positioning System,GPS)及罗盘模块安装在飞行器顶部前端,通过控制器局域网络(Controller Area Network,CAN)总线与飞控连接。雷迅P900数传天线安装在飞行器顶部,通过串口与飞控连接通信。对于人类“飞行员”遥控的蓝机,它采用PixHawk雷迅V5+飞控硬件,其余设备与红机一致。

图11 智能无人机的航电硬件架构Fig.11 Avionics hardware architecture for intelligent unmanned aircraft
试验中,为了使红机能实时获得蓝机的航迹数据,蓝机通过雷迅P900数传不断向红机发送自己的位置与速度信息,频率为25 Hz。红机数传天线接收到相关信息后,先发送到飞控计算机,然后再由飞控计算机转发到决策计算机,决策计算机计算得到机动航迹导引指令,最后再回传给飞控计算机。通过性能优化,该过程的数据传输时延小于14 ms。飞控计算机收到航迹导引指令后,通过飞行控制律实现相应指令,输出脉冲宽度调制(Pulse Width Modulation,PWM)信号格式的油门与舵偏控制指令,驱动无人机进行机动飞行。
4.2 算法架构
智能无人机的软件架构如图12所示,首先基于飞控等硬件设计驱动层,包括通信接口、外设、传感器等硬件驱动。在驱动层之上是设备抽象层,按功能划分为传感器、任务设备、动力和舵机、遥控遥测等类别,它将硬件设备进行抽象封装,为上层算法调用提供接口。飞行算法库封装和实现上层应用需要的算法,包括导航算法、控制算法。应用层针对近距空战机动任务,针对决策模型给出的机动航迹导引指令,通过航迹跟踪控制实现机动飞行,夺取对抗优势。

图12 智能无人机的飞行软件架构Fig.12 Flight software architecture for intelligent unmanned aircraft
对于决策机模型,使用C语言搭建与Python模型完全一致的神经网络框架,建立网络节点、前向计算、参数读取赋值、释放内存等函数,将Python决策机模型参数保存为.txt文件,然后用其对C语言神经网络模型的参数进行赋值。对于飞行器GPS传感器得到的经度、纬度、高度数据,将其转换为当地北东地坐标下的坐标数据,进而得到红蓝飞行器双方的相对位置rRB,利用GPS传感器给出的北东地速度数据,可以直接得到红蓝双机的相对速度vRB信息。将C程序在Linux环境下编译,生成excute文件执行,对于本文开发的深度神经网络决策机模型,一次决策计算耗时仅1 ms,满足在线应用需求。
5 飞行试验
空战对抗飞行试验中,红机代表AI智能体,蓝机代表人类“飞行员”。飞机起飞后,从大约36.5 s开始进行试验,如图13所示,在对抗初始阶段,红机与蓝机距离较远,双方均选择相向而行,迅速减小双方距离;当距离缩短后,对抗双方为形成有效攻击条件,分别进行协调转弯,智能机首先取得了对敌的有利攻击态势,此时人类“飞行员”为摆脱智能机的攻击范围,进行了俯冲机动和水平转弯,智能机针对敌机动作进行相应机动,为夺取态势优势,两机进行了类剪刀机动的动作,红机始终保持了对蓝机的追击态势,试验期间(大约[36.5, 122]s)人类“飞行员”总体处于劣势。

图13 红蓝双机近距空战对抗试验场景Fig.13 Snapshots of red and blue aircraft in closerange air combat flight test
图14~图16给出了试验结果曲线,其中图14给出了试验期间红蓝双机的高度曲线,从图中可以看到,在空战对抗试验大约85.5 s的时间段中,红方总体上占据了高度优势。图15给出了对抗期间红蓝双机的态势曲线,初始阶段蓝机稍占优势,但红机迅速进行了调整,夺得了对抗优势,试验中红机总体处于优势,它能够迅速做出有利于己方的动作决策,通过机动占据对抗优势。图16给出了对抗过程中红机决策机给出的机动航迹导引指令与飞行器的实际状态曲线,包括高度指令跟踪曲线(见图16(a))、速度指令跟踪曲线(见图16(b))、滚转角指令跟踪曲线(见图16(c)),注意其中滚转角指令限幅60°,从图中可以看到,一方面空战机动航迹导引决策指令光滑,连续性良好,另一方面,飞行控制律工作可靠,较好地实现了决策机给出的航迹导引指令。试验结果说明提出的决策及控制架构具有较好的性能。

图14 近距空战对抗试验中红蓝双机的高度曲线Fig.14 Height profiles of red and blue aircraft in closerange air combat flight test
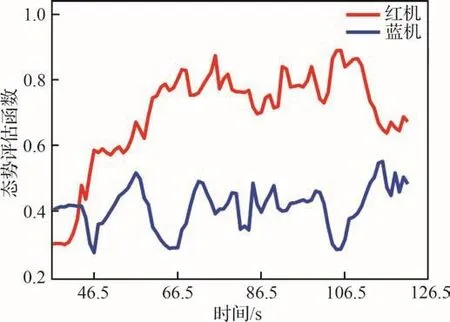
图15 近距空战对抗试验中双方的态势评估结果Fig.15 Situation assessment results of red and blue aircraft in close-range air combat flight test
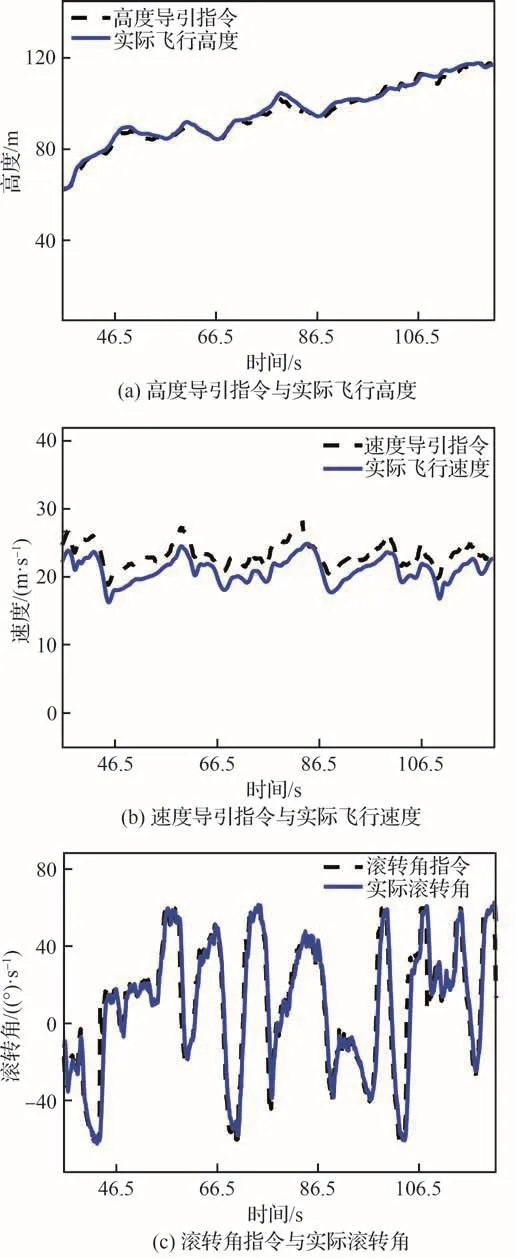
图16 红机航迹导引指令与实际飞行状态曲线Fig.16 Curves of trajectory guidance commands and actual flight states of red aircraft
6 结论
针对双机近距空战机动智能决策问题,进行了深度强化学习决策机的设计及其迁移实现研究,并进一步开展了智能无人机与人类“飞行员”对抗的飞行试验,主要结论如下:
1) 发展了一种便于工程应用的近距空战机动智能决策及控制实现方法,研究结果表明基于本文提出的方法,智能无人机能够迅速作出有利于己方的动作决策,在对抗中通过机动快速占据态势优势。
2) 相较于直接实现迎角等决策指令的控制方案,采用变换航迹导引指令的控制方案具有较高的可靠性与通用性,同时在工程实现方面具有一定的灵活性,可以支持具有相似功能的不同算法运行。
3) 本文工作验证了基于深度神经网络的近距空战机动决策技术及软硬件实现方案的可行性,为空战智能决策技术的工程实现提供了良好参考。但目前试验采用的神经网络决策机是离线习得,还不具备自适应学习能力,为了提高决策机的效能,未来将开展决策机在线自演进学习的研究工作。
