基于云边协同的决策树并行化设计
2023-06-15姚跃
姚跃


摘要:随着海量数据的分析任务越来越重,数据挖掘工作需要进一步推进和优化。文章首先提出了基于云边协同的决策树并行化设计,根据连续属性离散化判断分裂属性,在属性确认之后建立决策树;其次对并行化设计内的数据进行预处理,构建决策树整体并行流程;最终实现数据的实时分析与智能处理。对比试验表明,基于云边协同的决策树算法连续属性离散化的优化,在保证准确率的基础上,能有效地缩短运算时间,提高算法的运算速度。
关键词:云边协同;决策树;并行化;边缘算法;属性相似度;数据处理
中图分类号:TP3 文献标志码:A
0 引言
网络的数据挖掘一般使用决策树算法进行数据处理,传统的决策树算法在连续属性离散化和属性选择中存在效果偏弱,算法低效,因此决策树算法需要进行并行化的设计及优化[1]。云边协议的优势在于拥有更为高效的任务分配模式,将“云计算”和“边缘计算”进行互补,强大的调度机制可以增强决策树算法在处理各项数据时的性能和效率[2]。根据连续属性离散化判断分裂属性,在属性确认之后建立决策树[3]。之后再根据相似度进行决策树并行化计算,数据需要在初次预处理后实现决策树的并行化,最后确定基于云边协作的决策树并行化算法的流程[4]。在此基础上,以试验数据为研究对象,实现决策树算法数据的实时分析与智能处理,提高了数据处理的效率和安全性。
1 基于云边协同的决策树属性相似度
1.1 连续属性离散化
在决策树算法的测试属性选取中,将信息理论内的信息增益加以引入;随即递归每个分支下的训练事例,利用这种层层递进的方法可构造出层次逻辑清晰的决策树分支,直至所有子集的实例数据属性都显示相同的状态。为了解决决策树算法中存在的多值偏好问题,本文将属性相似性作为判断属性选取的准则。解决连续属性的离散化问题,因遵循的定义如下所示。
定义1:属性相似性代表用不同的测试属性来替代决策的结果。
定义2:在完整的电子计算机信息构架中,L=(U,Q)内的U为论域范围,Q为条件属性集C和决策属性集D所构成的集合,定义特性A∈C,与其相似程度用式(1)表示。
S(D,A)=|D∪{A}||D|*|{A}|(1)
式(1)中,S为相似度,D为决策属性,A为定义属性。相似度S越大,则定义属性A与决策属性 D越接近,尤其在S=1时,A和D就会非常接近;反之,S愈低,A就愈不接近D。按照知识的粒度,可以知道,在完整的电子计算机信息构架中L=(U,Q)内的U为论域范围,Q为条件属性集C和决策属性D所构成的集合,定义属性A∈C与D的相似度可用粒度来表示,即式(2)所示。
S(D,A)=GD|D∪{A}|GD(D)*GD({A})(2)
GD(D)表示D的粒度值为式(3)所示。
GD(D)=∑ni=1|Di|2(3)
根据上述方程,可以得到条件属性A和判定属性D的属性相似性公式(4)。
S(D,A)=∑ni=1∑mj=1ai,j2∑ni=1ai,m+12∑mj=1an+1,j2(4)
其中:ai,j表示在属性A中,取ai记录下属于类Di的记数式,式(3)对判定属性D与A的相似度进行了测度,其数值愈大,属性相似度愈高。在决策树算法中,属性相似性是判断属性选择的准则,而与决策属性越相近则是越好的选择。从理论上可以看出,这种决策树并行方法能有效地解决多值倾向问题,且分类的正确性也较高。
1.2 分裂属性选择
连续属性离散化的下一步数据处理需在云边协作中完成,边缘算法主要针对需要进行实时处理的数据为云边协同做出服务;而云技术主要负责数据的非实时、长周期数据的采集,以及对边缘应用进行全周期的管理。在基于边缘协作的基础上,建立基于云边协作的信息增益率,以此来选取最优的特征。设A为训练样本合集,此合集包含Ai元组,i={1,2,3...m},则期望信息为式(5)所示。
I(A1,A2...Am)=-∑mi=1AiAlog2AiA(5)
式中,Ai为包含i个对象的样本集。设Aj为包含j个对象的样本集,根据划分的期望信息计算A的熵为下列式(6)所示。
E(A)=∑vj=1AjSI(A1j+...+Amj)(6)
由试验属性A进行分割的信息增益是以下公式(7)。
Gain(A)=I(A1,A2...Am)-E(A)(7)
对应于属性A划分的训练集合S的信息量是公式(8)。
SplitInfo(A)=I|a1||a|,|a2||a|...|ay||a|(8)
式中,{a1,a2...ay}是按照A的值将S分开而得到的所有子集合,而A的属性所对应的信息增值是決定分裂属性的重要因素。对符合要求的分裂属性进行计算后,便可以开始决策树的整体建立过程。
1.3 决策树并行化实现
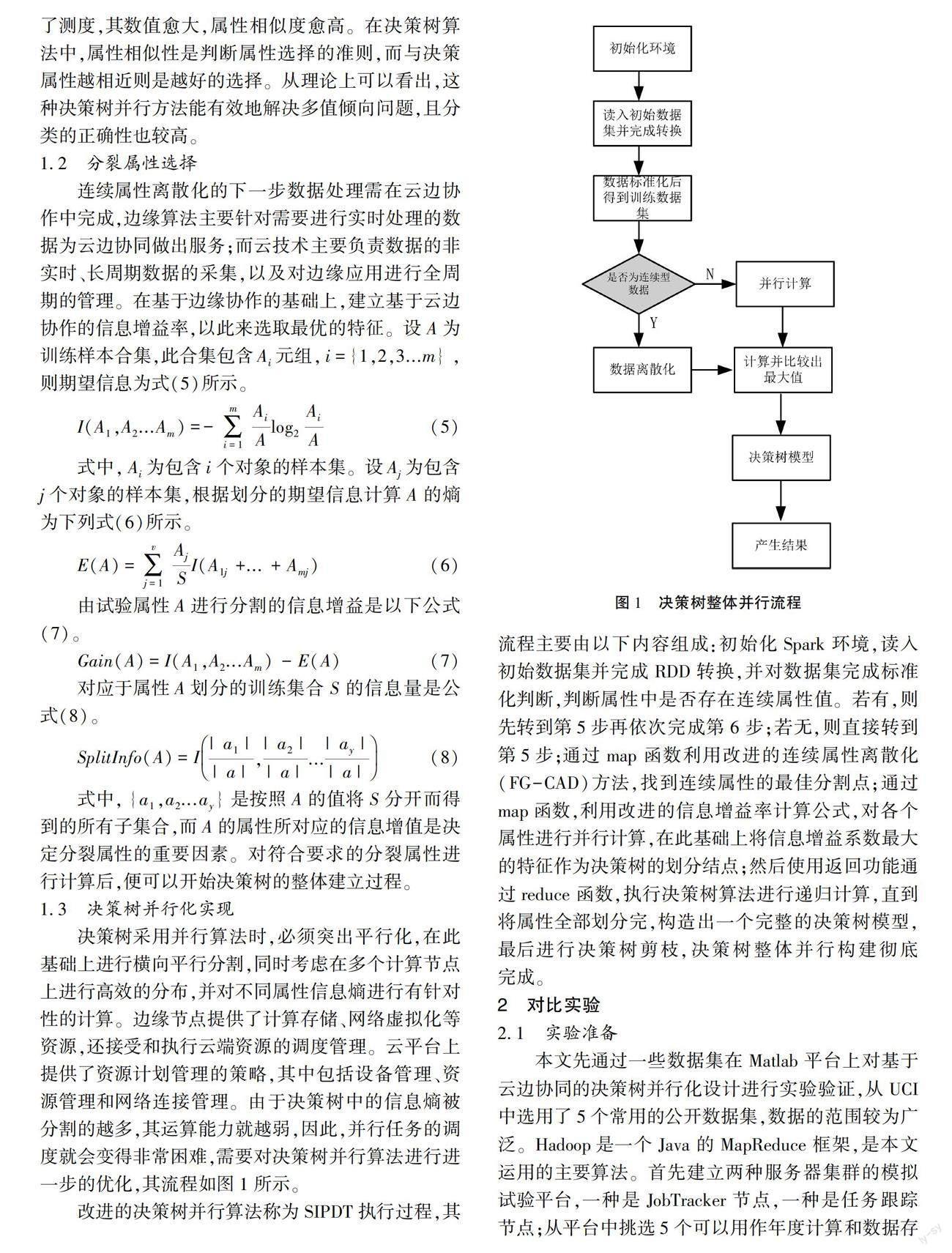
决策树采用并行算法时,必须突出平行化,在此基础上进行横向平行分割,同时考虑在多个计算节点上进行高效的分布,并对不同属性信息熵进行有针对性的计算。边缘节点提供了计算存储、网络虚拟化等资源,还接受和执行云端资源的调度管理。云平台上提供了资源计划管理的策略,其中包括设备管理、资源管理和网络连接管理。由于决策树中的信息熵被分割的越多,其运算能力就越弱,因此,并行任务的调度就会变得非常困难,需要对决策树并行算法进行进一步的优化,其流程如图1所示。
改进的决策树并行算法称为SIPDT执行过程,其流程主要由以下内容组成:初始化Spark环境,读入初始数据集并完成RDD转换,并对数据集完成标准化判断,判断属性中是否存在连续属性值。若有,则先转到第5步再依次完成第6步;若无,则直接转到第5步;通过map函数利用改进的连续属性离散化(FG-CAD)方法,找到连续属性的最佳分割点;通过map函数,利用改进的信息增益率计算公式,对各个属性进行并行计算,在此基础上将信息增益系数最大的特征作为决策树的划分结点;然后使用返回功能通过reduce函数,执行决策树算法进行递归计算,直到将属性全部划分完,构造出一个完整的决策树模型,最后进行决策树剪枝,决策树整体并行构建彻底完成。
2 對比实验
2.1 实验准备
本文先通过一些数据集在Matlab平台上对基于云边协同的决策树并行化设计进行实验验证,从UCI中选用了5个常用的公开数据集,数据的范围较为广泛。Hadoop是一个Java的MapReduce框架,是本文运用的主要算法。首先建立两种服务器集群的模拟试验平台,一种是JobTracker节点,一种是任务跟踪节点;从平台中挑选5个可以用作年度计算和数据存储的结点作为实验对象。同时,采用Xen的虚拟化技术,实现多个MapReduce的并行运行。其次,将Hadoop-0.20.0和JDK安装在服务器上,在Eclipse的集成开发环境下,实现该平台的程序运行。最后,与传统的决策树算法作对比,比较基于云边缘协同和串行特征相似度的决策树算法在计算精度、效率等方面的应用,具体实验数据集如表1所示。
由表1可以计算出5个数据集在连续型属性数中占总属性数的比值,A=1,B=0.7,C=0.36,D=0.6,E=1;从大到小进行排序,得到数据集A=数据集E>数据集B>数据集D>数据集C。
2.2 实验结果
2.2.1 有效性
根据实验准备中表1的数据可以得知,其连续属性离散化改进决策树算法的运行时间如图2所示。
在运行时间上,本文对决策树算法在连续属性离散化的改进与传统算法对比,运行时间显著缩短,减少程度几乎与数据集的连续属性占总属性比值的大小趋势保持一致。同时,算法的准确率在一个稳定的范围内波动。由此可知连续属性占总属性比值越大则减少的时间越多,且本文在保证准确率的基础上对连续属性离散化进行优化,结果表明,该方法能有效地缩短运算时间,提高算法的运算速度。
2.2.2 准确性
为了验证基于云边协同的决策树并行优化设计准确性,对采集到的数据集A重新进行数据节点的划分,其中60%为训练数据集,40%为测试数据集,其实验结果如表2所示。
用同一个数据集进行测试,采用云边协同策略的决策树并行化算法运算在相同的时间内,精确度得到了改善。同时,从并行化的角度来看,节点数量的增多,使得算法的计算复杂度降低,且保持一定的精度,从而证明了基于云边协同的决策树并行设计是切实可行的。
3 结语
本文讨论了基于云边协同的决策树并行化设计,为解决决策树算法中存在的多个偏倚问题,采用属性相似性作为判定属性选取的准则,将其离散化做出分裂属性选择。从边缘端和云端进行云边协作决策树构建,实现有效的决策树并行化设计。随着决策树算法的不断改进,其准确性和有效性越来越高,不断融入云边协同的方法使该算法的应用领域更加广泛,使设计切实可行。
参考文献
[1]招景明,张捷,宋鹏,等.一种高效的基于云边端协同的电力数据采集系统[J].电网与清洁能源,2022(5):49-55.
[2]郭祥富,刘昊,毛万登,等.面向云边协同的配变短期负荷集群预测[J].电力系统保护与控制,2022(9):84-92.
[3]聂丽霞,刘辉,邹凌.基于异构网络特征与梯度提升决策树的协同药物预测[J].计算机应用与软件,2020(4):48-52.
[4]常昊,杨盛泉.基于协同过滤决策树的商品推荐算法的研究[J].价值工程,2020(9):127-129.
(编辑 沈 强)
Parallel design of decision tree based on cloud side collaboration
Yao Yue
(Changsha Vocational &Technical College, Changsha 410217, China)
Abstract: With the increasingly heavy task of analyzing massive data, data mining needs to be further promoted and optimized. Therefore, this paper firstly proposes a parallel design of decision tree based on cloud edge collaboration; secondly, according to the discretization of continuous attributes, the split attributes are judged, and the decision tree is established after the attributes are confirmed. Preprocess the data in the parallel design, construct the overall parallel process of the decision tree, and finally realize the real-time analysis and intelligent processing of the data. Comparative experiments show that the optimization of continuous attribute discretization of decision tree algorithm based on cloud edge collaboration can effectively shorten the operation time and improve the operation speed of the algorithm on the basis of ensuring the accuracy.
Key words: cloud edge collaboration; decision tree; parallelization; edge algorithm; attribute similarity; data processing
