基于机器学习的抑郁症预测模型研究
2023-05-30廖欣怡李雨珂
廖欣怡 李雨珂
摘要:大量研究表明,抑郁症与甲状腺激素在人体内的含量水平存在一定的相关性。通过甲状腺激素水平与是否患有抑郁症的关系建立C4.5决策树、KNN、二元logistic回归等三种预测模型,可实现对是否患有抑郁症的简单预测。利用混淆矩阵进行模型评价,分别得到三种模型的召回率、精确率以及准确率,加以比较判断,最终选出预测效果最为良好的模型,即KNN模型,其准确率0.72,为抑郁症预测及诊断提供参考。
关键词:抑郁症预测;甲状腺激素;C4.5决策树;KNN;二元logistic回归模型
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2023)01-0016-04
1 研究背景与意义
1.1 抑郁症研究现状
抑郁症是常见的情感障碍,对个人、家庭乃至整个社会都产生重大影响,抑郁症已经成为亟须解决的公共健康问题之一。目前,针对抑郁症的诊断大多数是通过医生患者之间的沟通交流以及填写相关的问卷量(SDS) 综合评定,确诊过程中易受主观因素的影响,易造成误诊。同时,越来越多的研究表明抑郁症发病与内环境激素水平的变化存有关联:倪敏[1]等探讨抑郁症患者体内甲状腺激素的变化规律,结果反映出抑郁症患者的甲状腺功能存在问题并且其抑郁严重程度与激素水平具有相关性。崔伟[2]等对照分析抑郁症患者与健康对照者的血清甲状腺激素水平,表示抑郁症患者的激素水平与抑郁症状严重程度相关。石楠楠[3]等临床检测抑郁症患者甲状腺激素,得出病患之间、患者与健康对照者之间的甲状腺激素水平存在差异的结论。多项实验结果表明抑郁症与甲状腺激素有一定的相关性,并且甲状腺激素水平在不同抑程度的患者体内具有差异,因此,基于甲状腺激素水平实现抑郁症的预测模型的研究具有一定的作用。
1.2 机器学习的应用
机器学习是人工智能的核心,在大数据时代备受关注。机器学习涉及多领域、交叉学科,当今时代,机器学习已经广泛应用于医学领域,并对抑郁症的预测有着很重要的贡献。
1) 胶囊网络模型
胶囊网络模型是集卷积神经网络(CNN) 的优点于一身,同时考虑CNN高层特征与低层特征之间位置模糊的缺点而提出的一种对于图像处理更加有效的网络模型。查猛[4]在其研究中,提出了一种融合文本局部和整体特征的胶囊模型,该模型能够有效地发现微博用户中潜在的抑郁症患者。
2) 逻辑回归(LR)
Logistic回归常用来处理、描述自变量同因变量之间的因果关系,多用于解决二分类问题,在疾病的预测应用中具有很大的作用。潘玮[5]等人采用自然情景访谈与实验室语言收集方式,通过对高维抑郁数据建立是否抑郁的二分类的预测模型,从多角度考察了不同任务下的语音特征是否抑郁的预测效果。
3) 卷积神经网络(CNN)
卷积神经网络包含卷积计算且具有深度结构与表征学习能力,按其阶层结构对输入信息进行平移不变分类。赵盛杰[6]基于便携式脑电传感器构建了普适化EEG(脑电图)信号的跟踪采集和实时量化评估框架,利用CNN对普适化EEG构建抑郁分类模型,从而实现抑郁风险预测。
综上,对于抑郁症的预测模型大多数是基于患者的文本、语音、脑电这三个方面,基于患者的激素水平的预测模型仍旧很少。激素水平是最能直接反映机体身体状况的指标之一,基于激素水平建立疾病预测模型可以在一定程度,或者一定可能性上实现对于疾病的准确预测,为疾病的诊治提供支持。
以“抑郁症与甲状腺激素”为主题,通过研究大量相关论文,从中收集有效数据并进行处理,使用SPSS 25软件对数据进行降噪处理,用平均值替代异常值,通过计算spearman相关系数的相关性研究,所得结果同抑郁症与甲状腺激素关系研究中的数据描述关系一致并且有效,故可利用该数据进行预测模型的研究与实现。
使用Python 3.9.7,实现模型的搭建与可视化。
项目中属性与标签如表1。
2 模型介紹
2.1 机器学习
机器学习(Machine Learning) 是大数据时代的一大产物,是将人类从繁杂、庞大的数据中解救出来的重要工具。大数据环境下的数据具有典型的冗余、繁杂、量大的特点,如何从数据中提出想要的且有效的数据是每个程序员所追求的。机器学习就是在大量数据里面提取有效信息的解决办法。计算机通过对已有的数据进行分类、训练、学习、特征提取,总结出数据的规律与特点,再针对这些数据建立模型,不仅可以通过模型将数据可视化,还可以在学习的基础上实现“举一反三”,对新数据进行分类、预测等操作。随着大数据时代的发展,人类对于数据的处理有更高的追求,机器学习如今已经深刻融入了社会的各个行业领域,基于C4.5决策树算法、KNN算法以及回归算法建立抑郁症预测模型,是机器学习在医学领域的有效应用。
K-折交叉验证,即将样本集数据随机分成K份,按照1:(K-1) 的比例划分测试集与训练集并进行交叉验证。K-折交叉验证法有利于得到可靠稳定的模型,有效提高模型的学习能力,合适的K值能够有效避免过拟合,同时该方法对于数据量小的样本集友好,提供了有效的解决过拟合现象的方法。
混淆矩阵是对模型的预测结果状况的直观表示,可通过混淆矩阵对模型的准确度、精确度、召回度、特异性以及灵敏度等评估。混淆矩阵以列表示预测结果,以行表示真实类别,从典型的二元混淆矩阵中可以得出四种情况:
测试集中,预测与真实一致为真的类别,即TP(true positive) 类;预测为假而真实为真的类别,即FN(false negative) 类;预测为真而真实为假的类别,即FP(false positive) 类;预测与真实一致为假的类别,即TN(true negative) 类,如表2表示。
通过混淆矩阵可评估所建立的预测模型分类效果,准确度可以反映正确的预测在总样本里的占比,用ACC表示,计算公式如(1) 所示:
2.2 C4.5决策树算法
C4.5是一种经典的一系列决策树算法,基于信息增益率实现的C4.5决策树算法拥有优越的分类效果。在分类问题中,决策树表示对数据进行分类的过程。决策树中有两种结点,其中内部结点表示对属性的一个测试,另外一种是叶节点,每个叶结点代表了一个类别,连接这些结点的分支即为输出测试,选择对应类别的过程。相较于其他几种模型,决策树的优点是不需要设置任何参数或者获取领域知识才能进行进行分类,适合于独立预测甲状腺激素与抑郁症的关系。
C4.5在ID3的基础上被提出,改进了处理连续值、缺失值、划分属性值、剪枝等方面,可以通过不断学习来发现并寻找一个从属性到类别的映射关系,且这个映射关系能够对新出现的类别和未知实体进行分类。
2.3 K-邻近算法(KNN)
最邻近分类算法(KNN) ,是典型的“少数服从多数”的数据挖掘分类算法。KNN算法对训练集中的数据进行学习,并且训练集中的数据已划分好其归属类别。将未知样本归类于所有已知样本中同其距离最近的K个样本里占比最大的样本群,由此实现最邻近分类。KNN算法具有易实现、简单易懂、无须估计参数和无须训练的特点。
2.4 基于二元Logistic回归的抑郁症预测模型
logistic回归分析又称逻辑回归分析,多用来研究变量间的数据关系。如果因变量Y为二分的情况,即Y只有是与否两个选项,此时的回归模型即为二元逻辑回归模型。Python自带sklearn库中的 Logistic Regression可以实现逻辑回归模型的建立,并作进一步优化。
3 基于机器学习的抑郁症预测研究
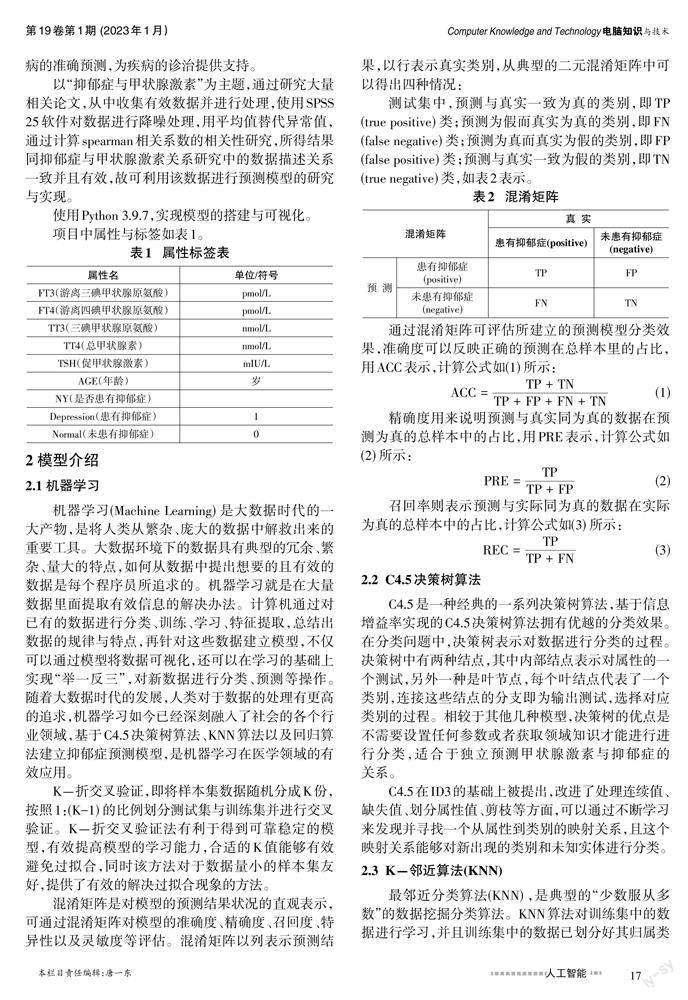
3.1 基于C4.5决策树算法的预测
给定准备好的甲状腺激素水平的数据集J,数据集中的每一个元组都属于一个互斥的类别(患有抑郁症、未患有抑郁症)中的一类,可以分别用一组属性值来描述。对于甲状腺激素的连续属性值需要进行离散化处理,采用二分法处理数据,具体方法如下:提供样本集的属性有212个不同的取值,按照从小到大的顺序对212个取值排序。把每个取值区间的中位点作为备选划分点,即得到含有211个元素的划分点集合Ta:
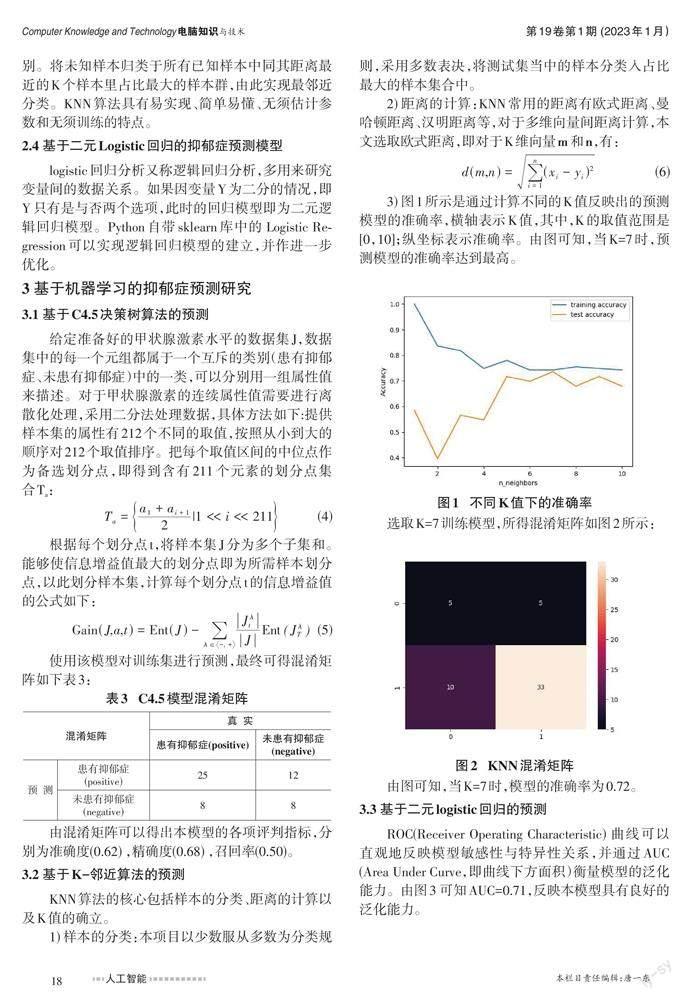
3.2 基于K-邻近算法的预测
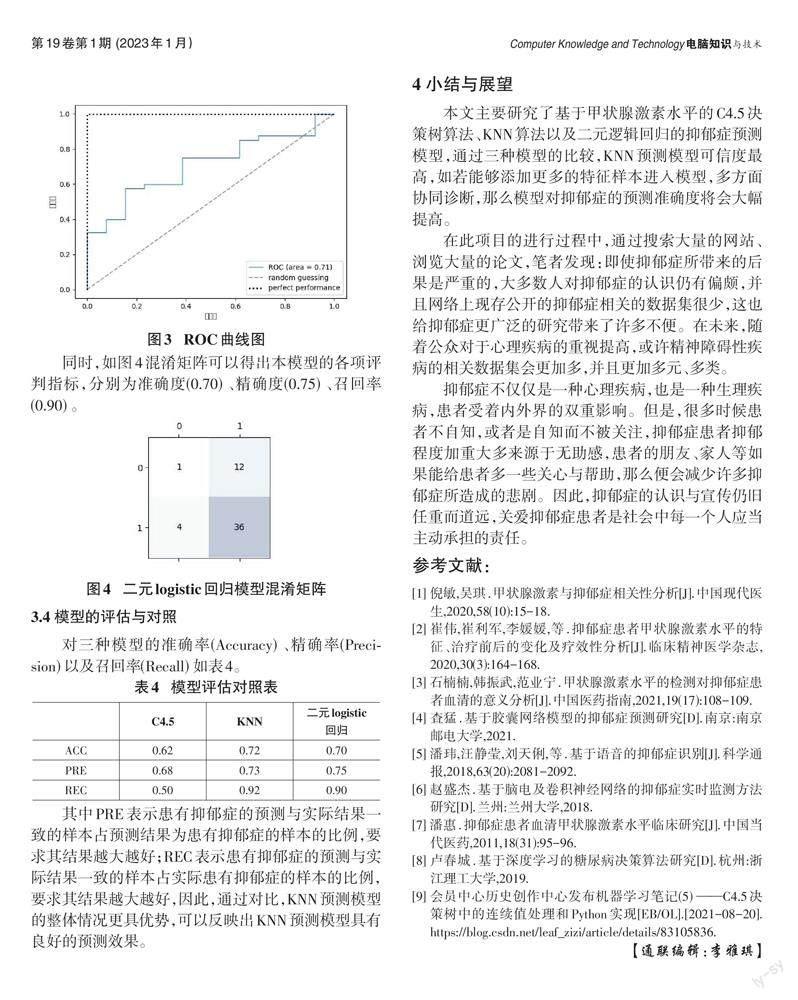
3.3 基于二元logistic回归的预测
3.4 模型的评估与对照
其中PRE表示患有抑郁症的预测与实际结果一致的样本占预测结果为患有抑郁症的样本的比例,要求其结果越大越好;REC表示患有抑郁症的预测与实际结果一致的样本占实际患有抑郁症的样本的比例,要求其结果越大越好,因此,通过对比,KNN预测模型的整体情况更具优势,可以反映出KNN预测模型具有良好的预测效果。
4 小结与展望
本文主要研究了基于甲状腺激素水平的C4.5决策树算法、KNN算法以及二元逻辑回归的抑郁症预测模型,通过三种模型的比较,KNN预测模型可信度最高,如若能够添加更多的特征样本进入模型,多方面协同诊断,那么模型对抑郁症的预测准确度将会大幅提高。
在此项目的进行过程中,通过搜索大量的网站、浏览大量的论文,笔者发现:即使抑郁症所带来的后果是严重的,大多数人对抑郁症的认识仍有偏颇,并且网络上现存公开的抑郁症相关的数据集很少,这也给抑郁症更广泛的研究带来了许多不便。在未来,随着公众对于心理疾病的重视提高,或许精神障碍性疾病的相关数据集会更加多,并且更加多元、多类。
抑郁症不仅仅是一种心理疾病,也是一种生理疾病,患者受着内外界的双重影响。但是,很多时候患者不自知,或者是自知而不被关注,抑郁症患者抑郁程度加重大多来源于无助感,患者的朋友、家人等如果能给患者多一些關心与帮助,那么便会减少许多抑郁症所造成的悲剧。因此,抑郁症的认识与宣传仍旧任重而道远,关爱抑郁症患者是社会中每一个人应当主动承担的责任。
参考文献:
[1] 倪敏,吴琪.甲状腺激素与抑郁症相关性分析[J].中国现代医生,2020,58(10):15-18.
[2] 崔伟,崔利军,李媛媛,等.抑郁症患者甲状腺激素水平的特征、治疗前后的变化及疗效性分析[J].临床精神医学杂志,2020,30(3):164-168.
[3] 石楠楠,韩振武,范业宁.甲状腺激素水平的检测对抑郁症患者血清的意义分析[J].中国医药指南,2021,19(17):108-109.
[4] 査猛.基于胶囊网络模型的抑郁症预测研究[D].南京:南京邮电大学,2021.
[5] 潘玮,汪静莹,刘天俐,等.基于语音的抑郁症识别[J].科学通报,2018,63(20):2081-2092.
[6] 赵盛杰.基于脑电及卷积神经网络的抑郁症实时监测方法研究[D].兰州:兰州大学,2018.
[7] 潘惠.抑郁症患者血清甲状腺激素水平临床研究[J].中国当代医药,2011,18(31):95-96.
[8] 卢春城.基于深度学习的糖尿病决策算法研究[D].杭州:浙江理工大学,2019.
[9] 会员中心历史创作中心发布机器学习笔记(5) ——C4.5决策树中的连续值处理和Python实现[EB/OL].[2021-08-20].https://blog.csdn.net/leaf_zizi/article/details/83105836.
【通联编辑:李雅琪】
