基于机器学习的大学生家教适配系统的设计与实现
2023-04-27高晨昊何谦胡梓
高晨昊 何谦 胡梓

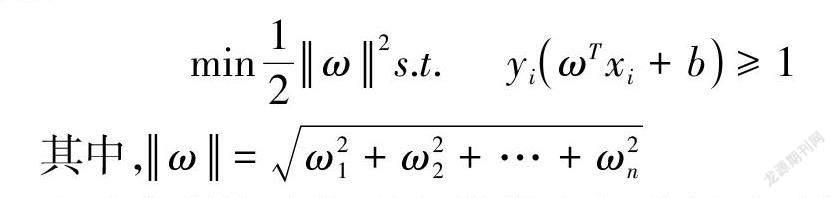


关键词:大学生家教;机器学习;SVM支持向量机;家教系統;App
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)08-0005-04
0 背景概述
当下,“互联网+教育”已经融入学生的方方面面,在“互联网+”背景下,学生借助互联网浏览教育信息,实现个性化教学目的。家教行业也借助这一背景,涌现出部分个性化教育平台[1]。家教群体中有这么一个群体,占据家教市场近4成,和学生沟通强,物美价廉,这便是大学生家教。
有学者曾调研过辽宁省的大学生家教市场。调研指出,有85%的家长会选择为孩子报名课后辅导班;所调查的近300家教育机构中,参与过家教兼职人员多达1万人,目标学生群体约60万人,学生平均年消费达2500 元[2]。据项目组成员调查,在一二线城市,约每10个学生中有8个学生上过课外补习班。因此,只要大学生有兼职意向,只要中小学生有补课需求,那么大学生家长市场将持续存在,并且会随着人数、教育发展、教育需求提高而持续扩大,线上家教匹配系统的未来前景仍是一片光明。
但是,大学生家教市场也存在着诸多问题。最主要的是大学生家教市场信息闭塞,大学生寻找家教系统途径单一[3]。
根据项目组成员考察调研,将目前市场上的家教平台分成以下三类:
1) 综合性兼职平台分属家教模块(如58同城、BOSS直聘);
2) 专职线下家教平台(如学而思,学大教育);
3) 较强地域性的家教小网站和小平台(如知善师家教)。
三种模式各有利弊,本项目设计为第三类家教平台。
团队利用机器学习算法库中的SVM算法,将中小学生在本平台的上课习惯、成绩、学习能力以及家教需求等个人数据作为输入,作为每个学生的学习模型,存储在数据库中,然后通过家教匹配系统,按需匹配最适合中小学生的大学生教员。该平台依据个体学习模型提供更契合的教员,从而满足个性化需求,解决潜在的教员“讲授方式”和“能力不足”等问题,减少中小学生找家教的时间,同时也为大学生提供了兼职渠道,进一步提高平台的竞争力[4]。
App前端使用基于Vue.js所搭载的uniapp框架搭建,同时利用MySQL数据库进行信息整合与存放,借助node.js搭建后端、调用数据,实现了教员信息展示、学生信息展示、喜欢教员、联络教员等诸多基础功能[5]。同时,使用Python 语言在jupyter notebook 中调用机器学习算法库中的SVM支持向量机,训练已获得的数据得到模型,模型实现了教员与中小学生匹配,减少了中小学生挑选联络教员以及与教员磨合的时间,并对教员的教学方式提供即时反馈。
本系统的主要目标是通过匹配中小学生与教员特点,满足不同学生的个性化需求,同时解决大学生家教市场信息闭塞的现实问题。
1 系统的需求分析与设计
1.1 需求分析
本系统解决的核心是完成满足学生和教员的相互匹配,找到合适的“最优”伙伴。系统主要分为两个角色:学生和教员。
学生端需要功能:注册登录、教师信息预览、收藏喜欢的教员、教员匹配、分数教学反馈。
教员端需要功能:注册登录、学生信息预览、学生匹配、学生反馈。
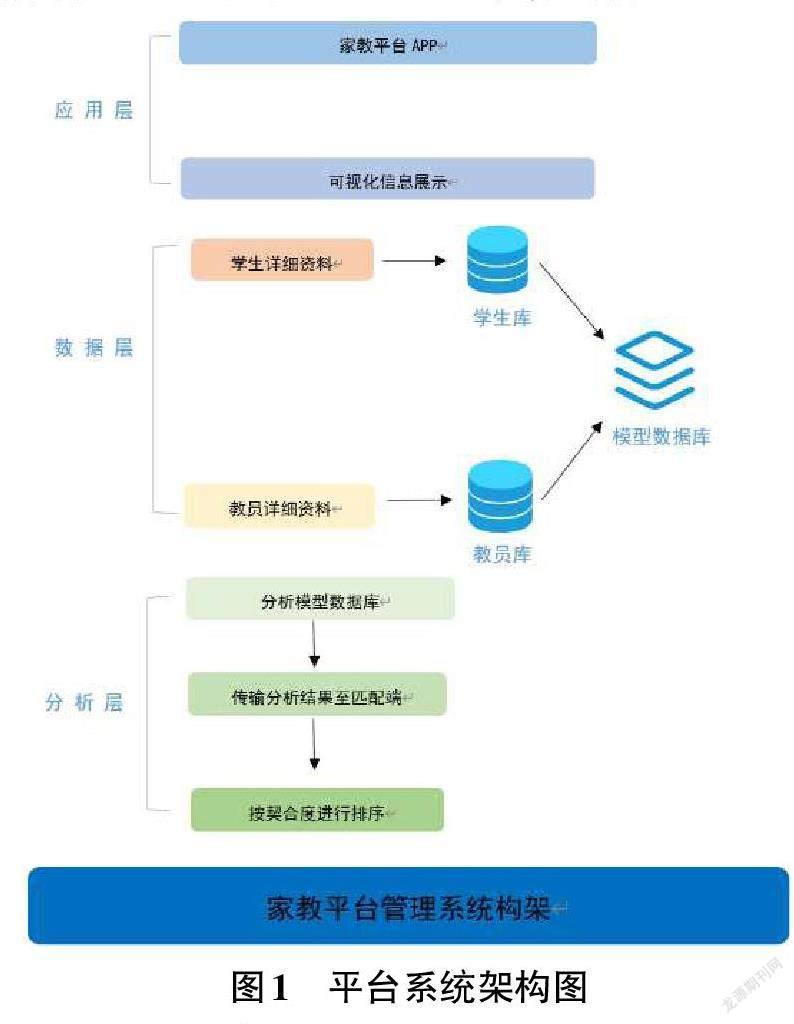
1.1.1 系统架构图
整个系统主要由三层组成:应用层,逻辑分析层,数据层。
数据层:底层数据库存储:1) 教员库:教员基本信息、教室模型;2) 学生库:学生基本信息、学生需求、成绩、课程记录反馈。学生库中的数据输入相关算法,抽象出特征模型后存储在模型数据库中。
逻辑分析层:对模型数据库进行分析,将分析结果发送到匹配端,库中模拟匹配出若干结果按契合度从高到低排序
应用层:利用下层的算法接口,将匹配的最优信息用前端页面可视化地展示出来,具体如图1所示。
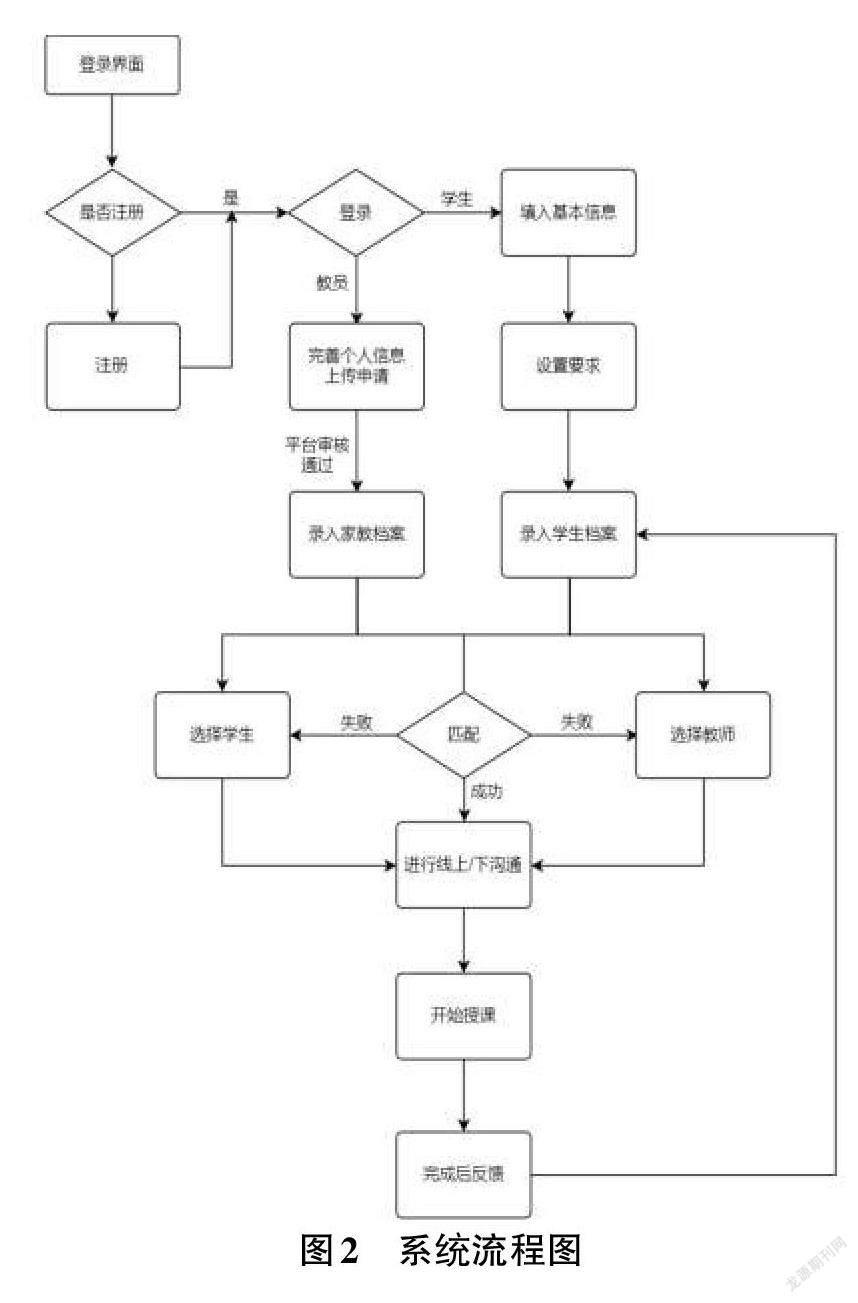
1.1.2 系统流程图设计
图2为系统流程图。
1.2 系统数据库设计
1.2.1 数据库设计的原则
在创建数据库之前,根据系统的数据需求和处理需求,设定以下建表要求:具有同一主题的数据应尽量存储在同一个表中,减少不必要的字段出现,也要根据存储数据的实际情况确定字段类型,提高后端查询数据的工作效率;建立表与表之间的关系时,表的主键及外键关系要尽量少,降低联合查询的复杂度;表的安全性和保密性要强,不能将系统关键字设置在表中,防止SQL注入攻击,对如用户账号密码此类信息不能采用明文形式储存,要对其进行加密后再储存;表与表间的管理要合理化,减少SQL查询带来的系统性能下降。
1.2.2 数据库表的设计
(1) 教员信息表:字段包括:photo、id、username、name、age、sex、phone、grade、location、score、school、所在地、subject、characteristics。
(2) 学生信息表:字段包括:id、sname、sage、ssex、sgrade、slocation、sscore、sschool、schara、sneed。表1为学生信息表样例。
2 基于支持向量机的教员和学生数据匹配
为了实现教员和学生之间的最优匹配,本文拟使用支持向量机SVM进行模型构建与训练,以达到教员和学生的最佳数据匹配。
2.1 支持向量机
1992年,Vapnik 对有限样本下的机器学习问题进行研究,提出一种小样本统计学习理论SLT。SLT为机器学习问题建立了理论框架,发展出一种新的学习算法:SVM-支持向量机[6]。支持向量机(SupportVector Machine, SVM) 是一类按监督学习(supervised
learning) 方式对数据进行二元分类的广义線性分类器(generalized linear classifier) ,其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyper⁃plane) [7-8]。
跳过理论证明,SVM 所处理的最优化解决问题为:
上述方程即为找到各类样本点到超平面的距离最远,也就是找到最大间隔超平面。也就是说,此方法的距离求解即为求解由学生和教师属性构成超平面,用得分来刻画该数据到超平面的距离。
2.2 基于SVM 的教员和学生的数据匹配
按需求来说,学生将自己的基本信息输入系统,然后根据算法推出一个最合适学生的教员。但是在实际操作上,只输入学生的信息给模型算法是不可以的。因为通过模型算法给出的y 值要么是一个数,要么是一个矩阵,性格相关均为并列关系,无法给出各项的准确分数的标准。比如算法给出教员的数据为:幽默18和严肃42,但是库中有一位教员A:幽默20,严肃40;教员B:幽默16,严肃44,没有办法比较哪一位是最匹配的教员。针对此问题,项目组提出的解决方案是对数据进行归并。
数据归并是指将学生希望教员的数据和库中所有教员的数据进行组合,得到若干条原始数据,得出的分数为系统给教员的评分,将评分从高到低排序,得到分数最高的ID,后台将该ID传送给后端,由前端进行数据渲染,完成教员的推送。
因此,在数据收集初期,让挑选出的大学生教员录制/线下试讲5分钟的习题,将录制的视频发至收集数据的中小学生,不告诉其教员的相关信息,由第一感觉评判该大学生教员是否符合自己的心意,并给这些教员打分,由此获得最初的完整数据集,从而完成教员和学生的匹配。
2.2.1 信息库的建立
本文使用jupyter notebook工具进行研究,首先导入学生教员信息库的csv文件。
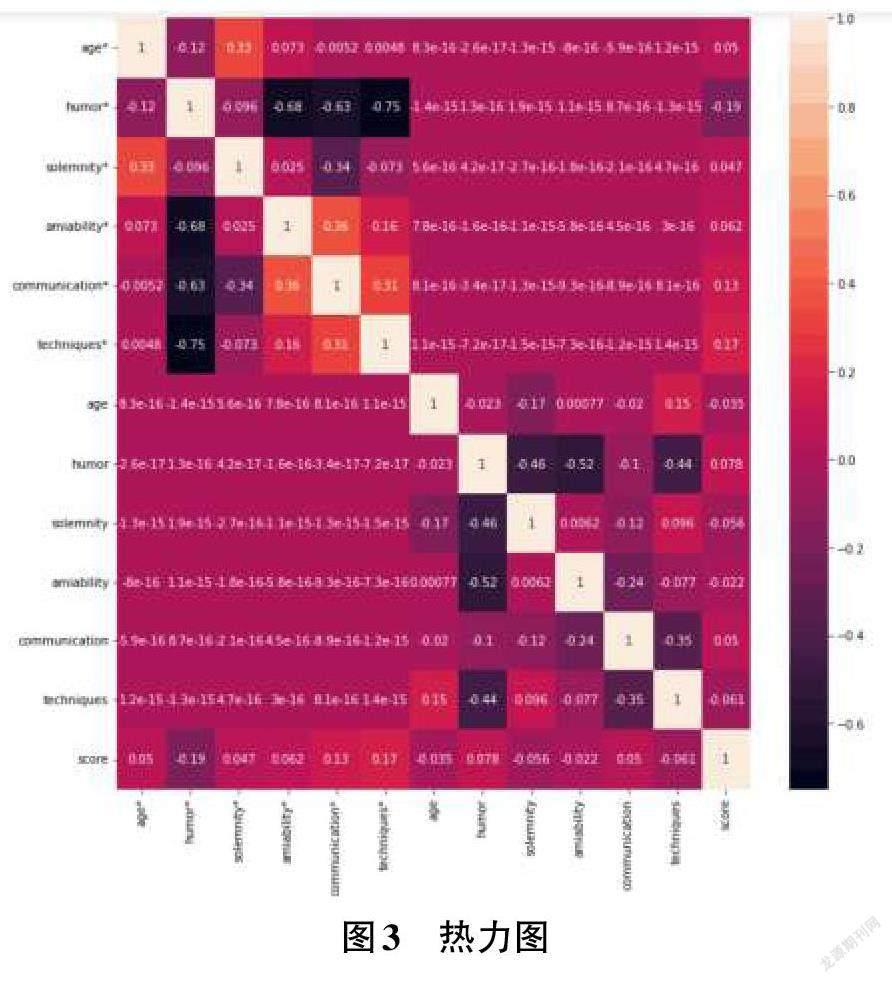
发现数据有分类类型与数值类型,首先需要进行数据的分析与统计,为了更好地展示数据信息,利用seaborn库中的绘图功能进行可视化地展示图片,根据绘制出的热力图,可以更好地查看各个属性之间的相关性,如图3所示。
2.2.2 数据标准化
接下来,需要对分类数据与数值数据分别进行处理,对于类别字段,采用OneHot进行数字编码,对于数值数据进行去均值和方差标准化,以此达到分离特征矩阵X和预估向量Y的目的。
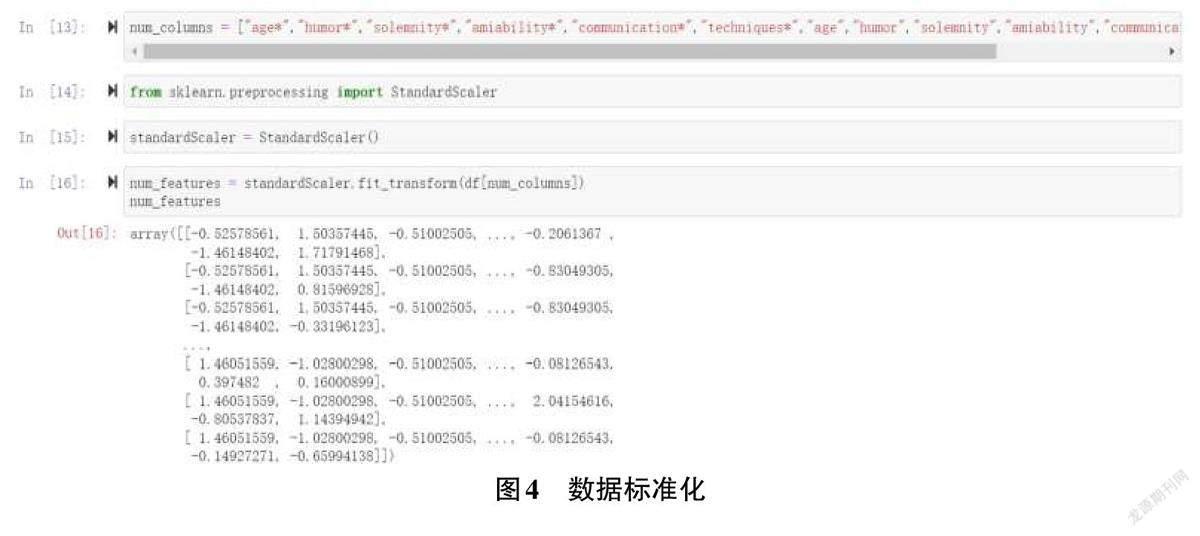
针对数值数据标准化,可以利用scikit-learn 中自带的preprocessing 库中Standard⁃Scaler 很快进行实现,如图4所示。
2.2.3 特征矩阵和预估向量的构建
处理好数据后,开始构建最终特征矩阵和最终预估的向量,特征矩阵是指分类特征数据和数值特征数据之间的拼接,利用numpy中的np.has⁃tack,将预估的向量转换成numpy数组,至此完成了特征矩阵和预估向量的构建。
2.3 模型训练
构建完成后,需要进行模型的训练。首先将数据集分为测试集和训练集,利用scikit-learn 中的model_selec⁃tion子包进行数据集的划分,本模型将80%的数据作为训练集,20% 的数据作为测试集,如图5所示。
使用SVM支持向量机进行模型的训练,在scikitlearn中引入SVM库,使用fit的方法进行训练,在fit中传入特征矩阵X-train和预估目标y-train,就可以很快完成训练。接着在测试集中进行预估,传入X-test,可以得到预估的匹配度,即y-predict,如图6所示。
最后,模型在训练集上的分数为0.94,测试机上的结果为0.92,证明SVM算法和本文的要求有极高的匹配度。本文将该组数据采用KNN临近算法进行模型训练,在KNN回归模型中,结果如图7所示,训练集上的准确度是0.90,测试集上的准确度为0.86,将两者相比较,发现SVM模型比KNN模型有着更高的准确性,如图7所示。
3 系统实现以及介绍
3.1 部分页面功能实现
3.1.1 教员大厅、学生大厅页面的实现
学生用户登录成功后,系统将自动跳转到“教员大厅”页(如图),学生用户可使用顶部搜索栏进行关键词检索,寻找心仪的教员;通过首页轮播图点击进入“金牌名师”的课堂报名;通过首页展示的教员卡片阅读教员的生源地、高考成绩、教学科目、授课特点等信息,并根据自身需求选择心仪教员。
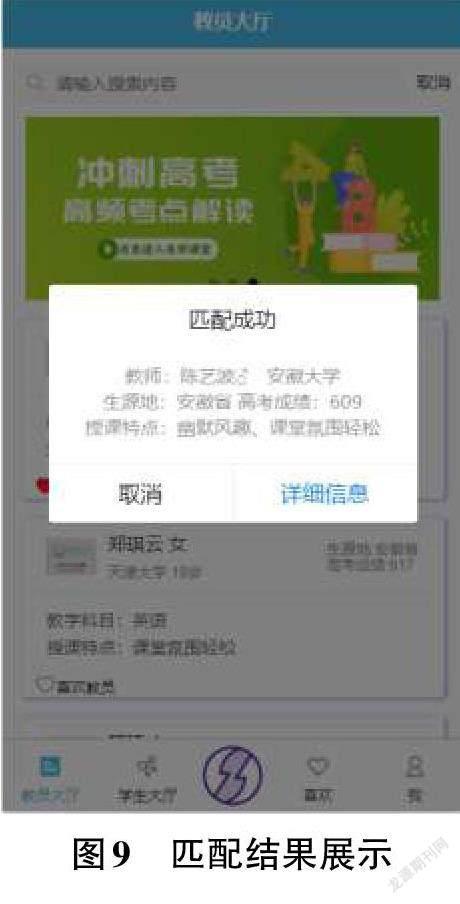
3.1.2 个性化匹配功能实现
点击“匹配”按钮,前端向后端发送匹配请求,后端将前端捕捉的数据传入后台模型,由模型得出各个教员的评分,在后台从高到低排序,将排名第一的教员ID传送给后端,由后端将该教员信息传送到前端渲染展示。
4 结束语
本文设计的基于机器学习的大学生家教适配系统,即利用SVM支持向量机算法对教员和学生数据进行机器学习,通过建立“评价反馈”机制为模型进行修正,训练完成的模型可以进行学生和教员的适配。通过实验验证,SVM支持向量机对于本项目来说优于其他算法。本文采用的:前端-后端-后台-后端-前端的数据传送模式也十分契合本项目。在前后端优化过程中,注重信息保护,信息推送的合理性。同时考虑到面向的用户为年轻群体,UI总体设计简约,配色清新活泼,符合系统用户的审美特点。
