折扣{0-1}背包问题之分段排序贪心核算法研究
2023-03-10代祖华刘园园狄世龙樊琦
代祖华,刘园园,狄世龙,樊琦
西北师范大学 计算机科学与工程学院,兰州730070
{0-1}背包问题({0-1} knapsack problem,{0-1}KP)是计算机科学一个重要的NP Complete 问题,也是一类经典组合优化问题,在商业、经济、管理、安全等领域有着广泛的应用背景。{0-1}KP 自被提出后的几十年里被反复地研究,衍生出精确算法、非精确算法两大类算法。精确算法有动态规划、回溯法和分支限界法等;非精确算法主要有随机算法、近似算法、生物算法等。在目前求解{0-1}KP 的各类算法中,基于核概念[1]的算法被认为是处理大规模{0-1}KP 的有效算法[2]。2005 年,由Guder 首次提出的折扣{0-1}背包问题[3-4](discounted {0-1} knapsack problem,D{0-1}KP)是{0-1}背包问题的拓展形式,作为刻画折扣销售、捆绑销售等商业活动现象的经典数学模型,是商家设计商业营销方案、消费者购买商品决策的科学计算依据。
D{0-1}KP 实例由一组项集组成,每个项集有3项物品可供背包装入选择,其中第三项物品价值是前两项之和,第三项物品重量小于其他两项之和,算法求解中如果选择了某个项集,则需要确定选择项集的哪个项。因此,D{0-1}KP 的项集有4 种选择状态。另外,如果背包的容量和项的价值系数取值范围很大,则不选择某个项集的约束条件较难确定,这意味D{0-1}KP 的算法难度要大于{0-1}KP[5]。以{0-1}KP 研究成果为基础,学者们进一步研究了D{0-1}KP 的各类算法。其中基础动态规划算法(basic dynamic programming,BDP)[4]是处理小规模数据的精确解算法,由于动态规划算法是伪多项式时间复杂度,一般不适用于大规模D{0-1}KP 实例的求解;2016 年,He 等人[6]以“所选择项的价值系数之和使总重量最小”原则构造动态规划目标函数,提出一种新动态规划算法(new exact algorithm for D{0-1}KP,NEDKP)。当背包容量大于项集第三项价值累加和时,新算法性能好于BDP。粒子群算法[6]、遗传算法[7-8]、猴群算法[9]、教与学优化算法[10]是近年来提出求解D{0-1}KP 的群智能算法,作为启发式算法,需要通过数据仿真实验调控算法参数,求解结果具有不确定性。2012 年,Rong等人[5]以{0-1}KP 核概念[1]为基础研究了D{0-1}KP 的核(Core)问题,基于核区间将原问题划分为3 个约简子问题,提出一种基于核区间划分的D{0-1}KP 分治算法。研究结果表明,对于多数类型的D{0-1}KP 数据,采用分治求解策略的动态规划算法效率要高于对原问题直接求解。2018 年,杨洋等人将贪心核区间算法与遗传算法进行融合,提出求解D{0-1}KP 的核加速遗传算法(core acceleration genetic algorithm,CEGA)[8]。2019 年,史文旭等人将模糊核区间算法与动态规划算法相结合,提出了贪心核加速动态规划算法(greedy core acceleration dynamic programming,GCADP)[11]。与启发式算法相比,基于核区间估计的D{0-1}KP 近似算法求解结果稳定,算法需要调控参数较少,值得进一步优化与改进。
求解D{0-1}KP 问题的精确核区间是一个NPC问题,现有文献[5,8,11]研究了D{0-1}KP 基于近似核区间的求解算法,思路是:首先按物品价值密度对数据进行非递增排序,然后利用贪心算法选取不完整项集b,以b为中心估算近似核区间[s,t]。不同于{0-1}KP,D{0-1}KP 的核区间以b为中心非对称分布,且分布区间与数据实例类型相关[5]。本文发现:近似核区间算法需按物品价值密度进行非递增排序,{0-1}KP 只有一种排序方案,而D{0-1}KP 每个项集有3项,故存在多种排序方案。文献[5]认为项集的第三项比其他两项更有优势,故选择第三项价值密度作为项集排序数据,不打乱项集的项次序;文献[6-8,11-12]则将所有项按项价值密度非递增排序,并利用项集排序序号数组转录源数据,算法需处理一个项集中多个项被选取的非正常情况。本文在研究{0-1}KP核概念基础上,修正了文献[5]的D{0-1}KP 核区间定义,提出一种可显著缩减核区间规模的分段排序策略和贪心核算法,设计了D{0-1}KP 基于分段排序贪心核的动态规划核加速算法。
1 D{0-1}KP 数学模型与算法
1.1 D{0-1}KP 数学模型
D{0-1}KP 是一个特殊整数规划问题,定义决策变量xj=1(0 ≤j≤3n-1)表示项j装入背包,xj=0 表示项j未装入背包,对于决策向量(x0,x1,…,x3n-1),D{0-1}KP 的整数规划模型为:
1.2 D{0-1}KP 问题的核算法
定义2(D{0-1}KP 不完整项集b)对D{0-1}KP的n个项集,按其第三项价值密度以非递增序列排序,贪心选择每个项集第三项装入背包,直至装入背包的累计重量超出背包容量C的首个项集序号即为b,b满足:
D{0-1}KP 每个项集有4 个选择,导致{0-1}KP 的核区间定义不能直接应用于D{0-1}KP。文献[5]专门研究了D{0-1}KP 的核划分方案。具体做法是:对所有项集按第三项价值密度以非递增序列排序后,若x*是给定D{0-1}KP 的最优解,定义D{0-1}KP 的核区间为CI=[g1,g2],其中:
D{0-1}KP 核区间位置通常在不完整项集序号b附近,核区间规模与数据实例类型相关。利用式(2)定义核区间可将原问题划分为式(3)所示区间上的三个子问题。
1.3 D{0-1}KP 动态规划算法
动态规划算法(dynamic programming,DP)是Bellman 提出的一种多阶段决策最优化求解算法,也是求解各类{0-1}KP 问题的经典算法[16]。文献[5]提出求解D{0-1}KP 的标准动态规划算法(BDP):定义阶段变量i∈[0,n-1]对应BDP 求解过程中项集的选择编号范围上界;定义状态变量j∈[0,C]对应BDP 求解中背包可能的剩余载重量,v(i,j)表示算法在第i阶段背包剩余载重量为j的状态下可装入背包的最大价值,则v(0,j)保存v(i,j)的初始值,表示可选择项集为第一个项集的局部最优值,可按照式(7)赋值。计算其余v(i,j) 的决策状态转移方程如式(8),最终,D{0-1}KP 的最优价值可从v(n-1,C)中获取,不难推断BDP 算法时间复杂度为O(nC)。
BDP 算法的小规模D{0-1}KP 数据集最优解表明:项集的第三个项占背包装入必选项的大部分,按项集第三项价值密度对数据非递增排序后,BDP 算法得到的最优解x*和贪心算法得到的不完整解x′仅在不完整项b附近的少量项集取值上有差异,这些项集即为核区间覆盖项集。D{0-1}KP 的核区间算法方案是:贪心选择项集第三项确定不完整项位置b,然后以b为中心非对称扩展核区间项集,确保核区间覆盖项集可以获得较优解项集。
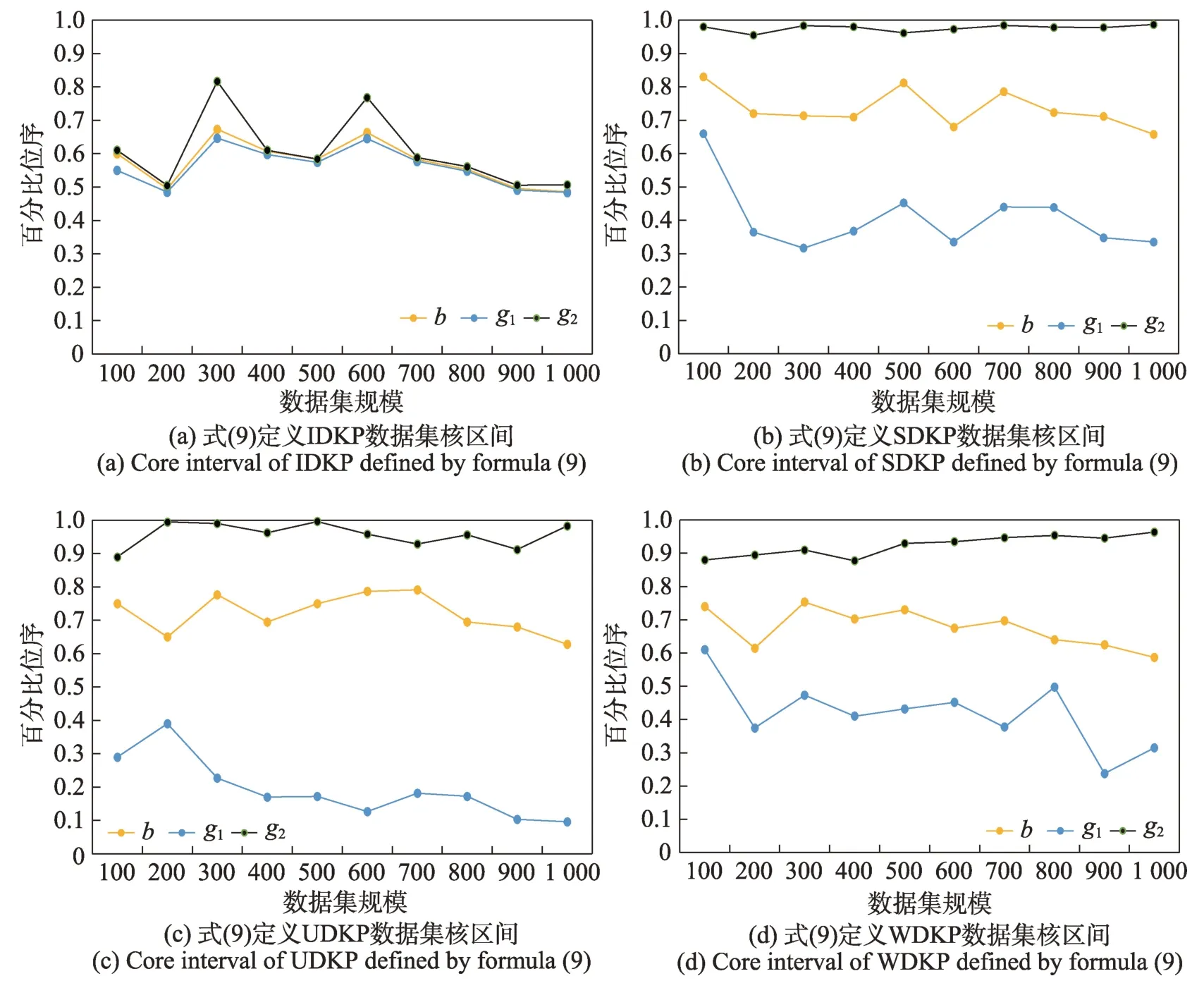
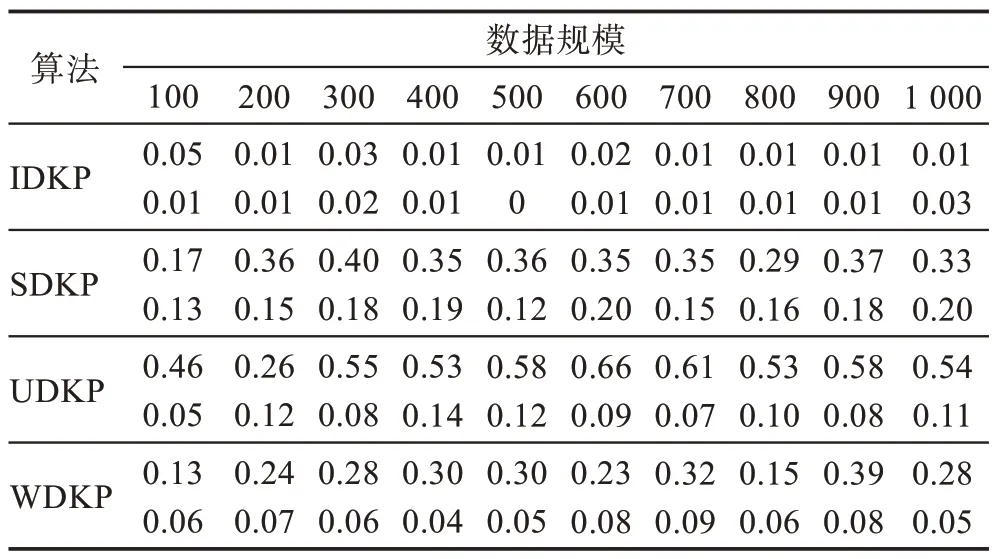
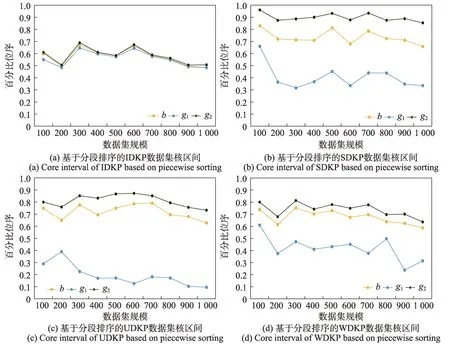
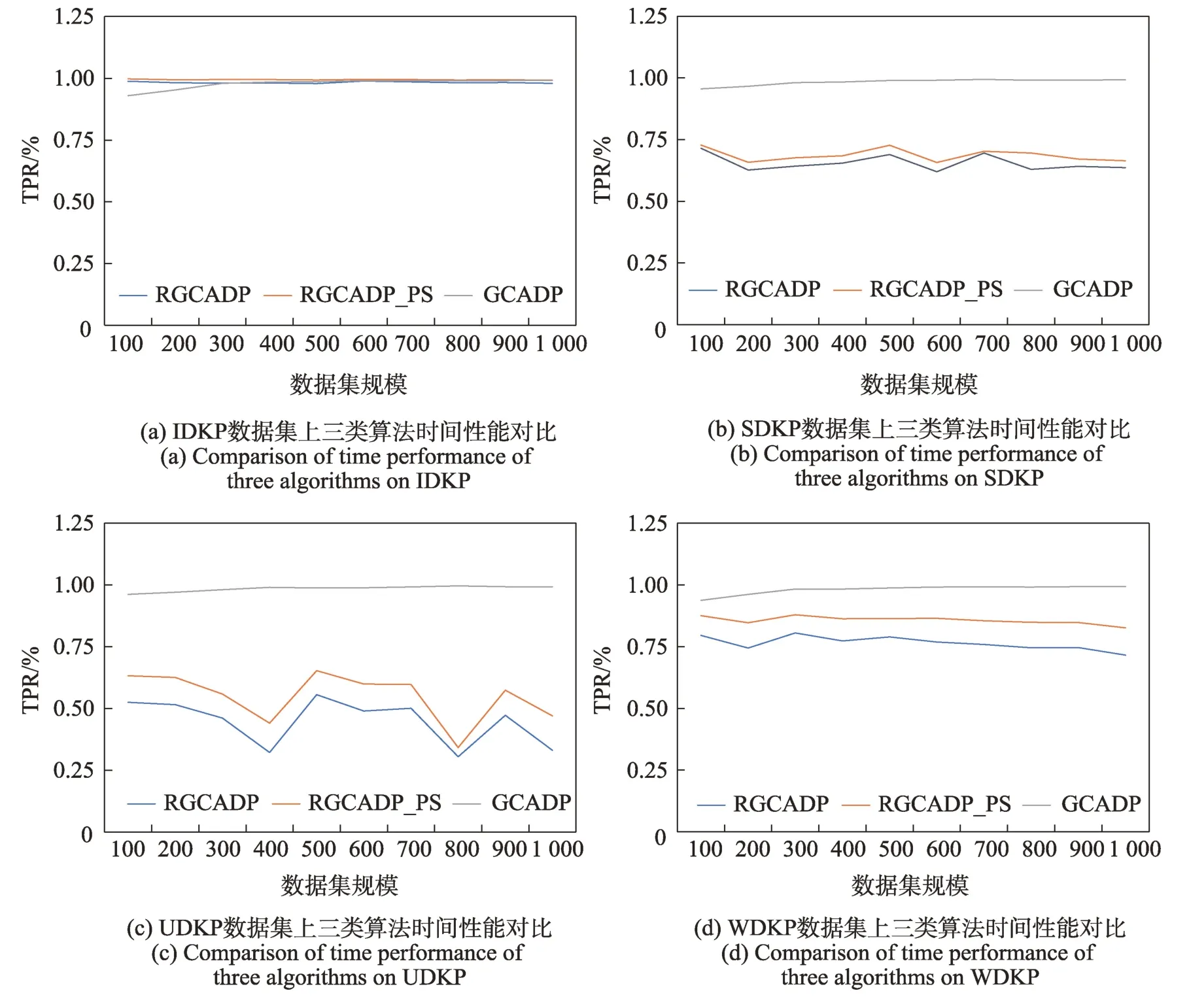
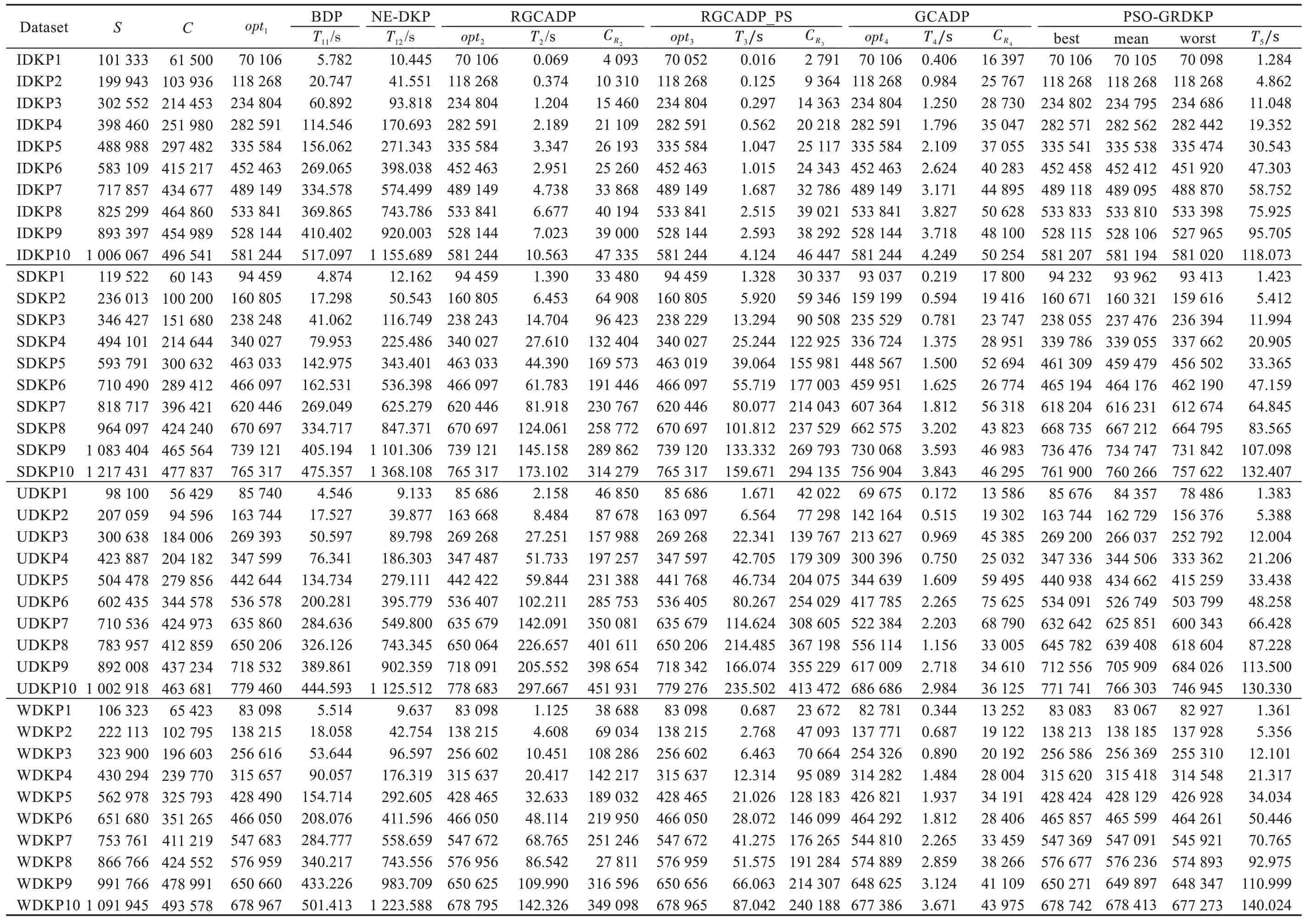
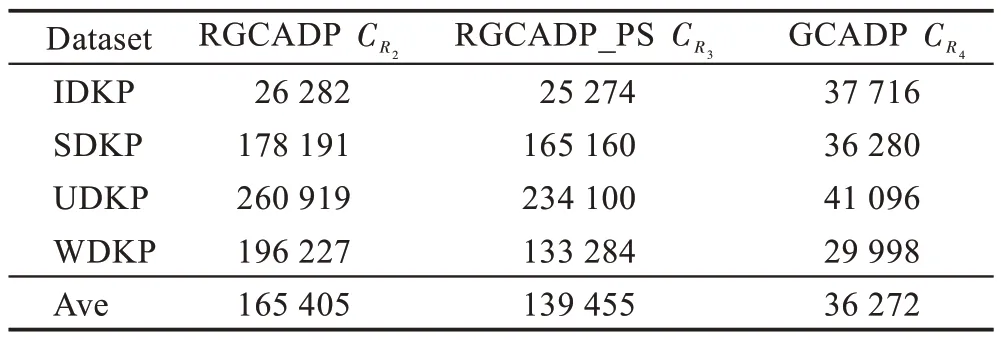
定义3(受控状态)用sα(t)表示动态规划α阶段中重量-价值对(t,gα(t)) 对应的状态,若有t1 根据受控状态的定义,BDP 算法在求解各个阶段有许多冗余状态组成,这些状态对于计算最优解无用,稀疏点动态规划算法(sparse node DP,SDP)通过丢弃受控状态来减少冗余状态,SDP 算法的状态数与物品重量与价值的数据分布有关。为减少SDP 算法处理丢弃受控状态的算法耗费,LDP 算法减少了SDP 算法中受控状态的丢弃数量,LDP 算法的状态数只与物品的重量分布有关。文献[5]的数据实验结果表明,核区间加速算法SDP、LDP 算法由于筛选丢弃动态规划过程冗余状态的计算耗费过大,在大规模数据情况下性能比BDP 算法更差。 为解决式(2)核区间定义存在的问题,本文提出D{0-1}KP 的修正核区间CI定义,如式(9)所示: 易见式(9)确定的CI=CI12∪CI2∪CI31,采用分治策略求解时,原问题可分为三个子问题:第一个子问题由选择第三项的必选项集组成;第二个子问题是背包容量减小的原问题;第三个子问题由不选择项集组成。与式(2)核区间定义相比,式(9)定义的核区间扩增了CI12与CI31,但可有效解决式(2)对部分数据实例的可能存在的核区间划分不合理问题,故基于式(9)核区间的分治求解算法较之文献[5]更为简单,易于将原问题约简为一个小规模子问题求解,有效提升近似算法性能。 为验证两种核区间定义的差异,本文构造四种类型的D{0-1}KP 小规模数据实例,每个数据实例包括10 个规模不等的数据集,背包容量满足,按项集第三项价值密度对项集非递增排序,项集内各项保持原有次序。即若用di表示项集i的价值密度有di=e3i+2,若i 数据排序后应用贪心算法计算每个数据实例满足式(1)的不完整项集编号b,用BDP 算法计算最优解向量x*,分别按照式(2)和式(9)计算CI=[g1,g2],为去除数据规模对实验结果的影响,计算数据实例的b、g1、g2在排序数据的百分位序,如图1、图2所示。 图1 的实验结果验证了文献[5]核区间定义存在以下问题:数据实例的核区间边界值可能出现g1>g2情况,例如图1(c)在200、600、700 处的数据集蓝色线条位于黑色线条上方;有些数据实例的核区间不包含不完整项b,如图1(b)黄色线条未落在黑色、蓝色线条之间。这些问题影响D{0-1}KP 的贪心核区间相关算法性能。从图2 实验结果看出,修正核区间从不完整项b开始向两侧扩展,符合文献[1]关于{0-1}KP 核区间定义基本要求,核区间呈非对称分布;IDKP 类型数据实例的核区间规模最小,SDKP、WDKP 类型数据实例的核右侧边界g2近似为n,UDKP 类型数据实例的核区间接近原数据规模;核区间在不同规模数据集上跨度偏大,如图2(a)的300、600 位置处,图2(b)的300 位置处,图2(d)的900 位置处等。 图1 文献[5]核区间定义计算结果Fig.1 Calculation results of definition of core in ref.[5] 图2 修正核区间定义计算结果Fig.2 Calculation results of repaired core definition 与精确核区间记号[g1,g2]相区别,贪心核区间采用记号[s,t]表示。文献[5]按数据规模分段给出了不同类型数据实例的贪心核区间经验值,其值与文中定义的精确核无显著相关性。文献[11]的贪心核算法如下: 考虑到D{0-1}KP 的核区间规模与数据类型相关,分析四类D{0-1}KP 实例生成的参数设置[7]看出,四类D{0-1}KP 实例之间的差异主要体现在项重量和项价值的数量关系不同,为此引入如式(11)的相关系数统计量以区分不同的四类数据实例。 采用类似文献[5,11]的方法和图2 修正核区间特征构造D{0-1}KP 的贪心核区间(repaired greedy core interval,RGCI)[s,t]算法如式(12)~(15),式中常数为经验数值,b为不完整项序号,n表示数据规模,ρ为物品重量与价值的相关系数。 设计基于修正核区间定义的D{0-1}KP贪心核区间动态规划加速算法(repaired greedy core acceleration dynamic programming algorithm,RGCADP)如下: 算法1RGCADP 算法1第2 步按项集第三项价值密度对项集的价值向量P和重量向量W进行非递增排序,第3~5步在排序后的P、W上执行贪心算法计算b,第6 步按式(11)计算相关系数ρ,第7 步按项集类型type 选择式(12)~(15)计算贪心核区间[s,t],第8 步计算贪心核区间的剩余背包容量CR和[0,s-1]区间装入背包的价值maxV,第9、10 步对子问题X[0,3s-1]、X[3(t+1),3n-1]赋值;第11 步采用BDP 算法求解核区间[s,t]的决策向量X[3s:3t+2]和最优解maxVBDP,第12 步计算近似最优解opt2。RGCADP 是一个具有伪多项式时间的近似算法,时间复杂度为O(n+nlbn+,与BDP 算法时间复杂度O(nC)相比,当CR≪C时,RGCADP 可有效缩减算法输入数据规模而改善算法性能。 D{0-1}KP 核区间规模与数据排序算法密切相关,为解决式(9)在部分数据集上核区间规模较大问题,本文提出D{0-1}KP 分段排序算法。 算法2D{0-1}KP 分段排序算法(piecewise sort) 算法2第6 步对[b,n-1]区间的项集(数据包括价值和重量)按三项的最大价值密度值进行非递增排序,项集内各项保持原有次序。易见D{0-1}KP 分段排序算法的时间复杂度为O(n+nlbn)。 采用BDP 算法对排序后数据计算最优解向量x*,并按照式(9)计算CI=[g1,g2],如图3 所示。 对比图2、图3 实验结果看出,D{0-1}KP 数据采用分段排序算法处理后,核区间CI的子区间[b,g2]规模显著缩减。表1 给出采用分段排序算法的核区间CI数据规模占比率,表1 每类数据集有两行数据,上一行数据表示[g1,b]的数据规模占比率,下一行数据表示(b,g2]的数据规模占比率。 利用图3 和表1 的分段排序核区间特征,构造D{0-1}KP的分段排序贪心核区间(greedy core interval based on piecewise sorting,GCI_PS)[s,t] 算法如式(16)~(19),式中常数为经验数值,b为不完整项序号,n表示数据规模,ρ为物品重量与价值的相关系数。 表1 分段排序算法的核区间数据规模占比率Table 1 Proportion of core interval data size based on piecewise sorting 图3 基于分段排序的核区间Fig.3 Core interval based on piecewise sorting 应用分段排序策略构造D{0-1}KP 贪心核区间动态规划加速算法(RGCADP based on piecewise sort,RGCADP_PS)如下: 算法3RGCADP_PS 算法3第1 步采用算法2 对项集分段排序,计算b,第6 步按项集类型type 选择式(16)~(19)计算贪心核区间[s,t]。RGCADP_PS 与RGCADP 算法的时间复杂度均为,其中n是项集规模,[s,t]是贪心核区间,C是背包容量,w3i+2是项集第三项重量。与RGCADP 算法相比,RGCADP_PS 在项集的不完整项b处先后采用两种排序策略而获得更小规模贪心核和剩余背包容量而改善算法性能。 D{0-1}KP 数据集是评测和观察算法性能的标准数据集[7],由IDKP、SDKP、WDKP 和UDKP 四类数据组成,每类数据包含10 个项集规模不同的实例,按类型分别命名为IDKP1~IDKP10、SDKP1~SDKP10、UDKP1~UDKP10、WDKP1~WDKP10,10 个数据实例的项集规模n∈{100,200,…,1 000}。为验证D{0-1}KP 分段排序贪心核算法性能,本文采用BDP[5]、NEDKP[6]、RGCADP、RGCADP_PS、GCADP[11]、PSOGRDKP(particle swarm optimization based greedy repair algorithm for D{0-1}KP)[6,10]6 种算法求解D{0-1}KP 标准数据集,比较求解时间和解计算结果以分析RGCADP_PS 的性能。其中BDP 与NE-DKP 是精确解算法,RGCADP、RGCADP_PS、GCADP 是近似解算法,PSO-GRDKP 是启发式算法。所有实验均在ThinkStation P330 计算机上进行,电脑配置Intel®Core™i7-8700 CPU-3.2 GHz、16 GB DDR4 内存、NVIDIA P2200 显卡,操作系统是Microsoft Windows 10 教育版,算法均使用Python3.6 编码。 与近似解算法和启发式算法相比,BDP 与NEDKP 算法可以获得最优解,但其算法时间性能最差。BDP 与NE-DKP 作为伪多项式时间复杂度算法,时间复杂度分别O(nC)、O(nS),影响算法性能的输入数据规模分别是C、S。从表2 看出,四类数据实例的所有数据集有S>C,因此,D{0-1}KP 标准数据集上NE-DKP 算法时间性能劣于BDP,即T12>T11。 与BDP、NE-DKP 精确解算法相比,近似解算法和启发式算法均大幅度提升了求解时间性能,但各个算法的解误差率和时间性能提升率各不相同。由表2、表3 看出,RGCADP、RGCADP_PS 的平均解误差率低于GCADP、PSO-GRDKP 分别达到4.7 个百分点、0.5 个百分点,GCADP 算法平均解误差率高于PSO-GRDKP 算法4.2 个百分点。以BDP 算法时间为基线,RGCADP、RGCADP_PS、GCADP、PSO-GRDKP四种算法在D{0-1}KP 标准数据集上时间性能提升率分别是71.3%、77.2%、98.2%、75.1%,即GCADP>RGCADP_PS>PSO-GRDKP>RGCADP。GCADP、PSOGRDKP 算法在四类数据实例上的时间性能提升率较稳定,GCADP 算法在0.979 至0.986 之间变动,PSO-GRDKP 算法在0.728 至0.798 之间变动。RGCADP、RGCADP_PS 算法在不同类型数据实例上时间性能提升率差异较大。在IDKP 数据实例上,RGCADP、RGCADP_PS 算法时间性能提升率显著高于GCADP、PSO-GRDKP 算法;在SDKP、UDKP 数据实例上,GCADP、PSO-GRDKP 算法较之RGCADP、RGCADP_PS 算法有较为显著的时间性能优势,但对应算法解误差率表现则相反;在WDKP 数据实例上,四类算法时间性能提升率依次有GCADP>RGCADP_PS>PSO-GRDKP>RGCADP,GCADP 算法时间性能最好但解误差率最高。 RGCADP、RGCADP_PS、GCADP 三类算法均是贪心核动态规划加速算法,当C≫n时,给定贪心核区间[s,t] 的算法时间复杂度是O((t-s+1)CR),其中,贪心核大小与贪心核上剩余背包容量是影响算法性能的关键因素。因此,贪心核算法优化是此类近似算法改进的主要途径。根据式(10),GCADP 采用的贪心核算法仅是n与b的函数,虽然算法时间性能提升率达到98.2%,在不同数据类型上算法运行时间偏差不大(如表3 所示)。平均值在三类算法最小(如表4 所示),但平均解误差率达到4.7%,远高于RGCADP、RGCADP_PS算法。RGCADP、RGCADP_PS 所采用的贪心核算法引入相关系数ρ区分数据类型,考虑了贪心核区间基于b非对称分布的特点,与GCADP 算法相比,算法时间性能提升率较低,但有效降低了解误差率。如表2 所示,在D{0-1}KP 标准数据集上两类算法在多数数据集上可获得最优解。如表2、表3 所示,RGCADP_PS与RGCADP 的求解误差率较为相近,RGCADP_PS的时间性能提升率高于RGCADP 算法达到5.9%。其原因是RGCADP_PS 采用分段排序算法对数据进行预处理,改进了贪心核区间算法,观察表4有>,说明RGCADP_PS 有效改善了RGCADP算法的时间复杂度。图4 给出了以BDP 算法时间(单位:s)为基线,三种算法在四种数据类型数据集上时间性能提升率与数据规模的关系。不难看出,三类算法时间性能提升与数据规模无显著关系。 图4 三类算法时间性能提升率Fig.4 Time performance improvement rate of three algorithms 表2 D{0-1}KP 标准数据实例算法实验结果Table 2 Algorithm experimental results of D{0-1}KP standard dataset 表3 算法解误差率与时间提升率Table 3 Solution error rate and time promotion rate of algorithms 表4 贪心核算法背包剩余容量(CR)Table 4 Knapsack residual capacity(CR) of greedy core algorithms 本文在研究{0-1}KP 核概念基础上,对文献[5]的D{0-1}KP 核定义进行修正,通过拓展核区间方式,解决了文献[5]定义核区间在有些数据实例上出现的不包含不完整项和核区间边界值g1>g2情况。为进一步缩减D{0-1}KP 修正核区间规模,提出一种D{0-1}KP 实例的分段排序策略。改进了D{0-1}KP 的贪心核算法,引入项重量和项价值的相关系数统计量ρ以反映数据类型差异对核区间算法的影响。应用分治算法设计模式,构造了RGCADP、RGCADP_PS 两种贪心核动态规划加速求解算法。D{0-1}KP 四种类型数据实例上运行结果表明: (1)与精确解算法BDP相比,RGCADP、RGCADP_PS 算法平均求解时间提升率为71.3%、77.2%。 (2)RGCADP、RGCADP_PS 算法平均解误差率较之启发式算法PSO-GRDKP 低0.5 个百分点,平均求解时间提升率接近PSO-GRDKP 算法。 (3)与GCADP 算法相比,RGCADP、RGCADP_PS 算法时间性能提升率较低,但平均解误差率较之高4.7 个百分点。 (4)RGCADP_PS 与RGCADP 的求解误差率较为相近,但RGCADP_PS 的时间性能提升率较RGCADP 算法高5.9%。 以上结果表明,基于核区间修正定义和分段排序策略的贪心核算法较显著改善了D{0-1}KP 贪心核加速动态规划算法性能。为进一步验证本文所提出D{0-1}KP 贪心核定义采用不同核加速算法的性能表现,接下来考虑采用粒子群算法计算贪心核解向量,设计RGCAPSO、RGCAPSO_PS 两种算法,并与本文提出算法进行性能对比研究。2 D{0-1}KP 之分段排序贪心核算法
2.1 D{0-1}KP 核区间修正定义

2.2 D{0-1}KP 修正贪心核算法
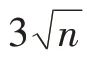
2.3 D{0-1}KP 的分段排序贪心核算法
3 算法实验分析与评价

4 结束语
