基于注意力机制与邻域几何特征的点云语义分割
2023-03-10刘勇江史健芳袁晓辉
刘勇江,史健芳,袁晓辉
(太原理工大学信息与计算机学院,山西晋中 030600)
点云数据由众多点坐标构成用以反映真实物体的几何信息,点云的语义分割作为点云数据的一种处理技术在3D 场景理解、城市规划、基础设施维护等[1-3]领域发挥着重要作用,具有很高的理论意义与应用价值。
深度学习算法中基于体素表示的算法[4]将点云转换为规则的三维体素表示具有立方复杂度,导致网络在处理中等规模点云时所需要的内存消耗和计算资源急剧增加,而将点云投影为多视图的预处理方法[5-6]通常会导致几何信息的严重丢失。
随着深度学习的发展,文献[7]基础网络PointNet直接输入点云数据进行分类与分割,避免了数据转变带来的信息丢失。该网络采用单独提取点特征的方式使得网络缺乏对局部特征的学习,从而导致模型泛化能力有限。文献[8]使用的基础网络PointNet++在PointNet 的基础上对点云进行区域采样,再多层次递归应用PointNet 提取局部特征,增强了网络在细分场景和复杂场景中的分类能力。PointNet++在特征提取过程中仍然单独处理局部区域内的点,忽略了邻域点之间的关系。PointSIFT[11]将2D 图像中的尺度不变特征进行变换后引入点云数据处理中,通过方向编码和尺度感知提取各个方向特征,以提高对局部特征的描述。尽管现有直接处理点云的方法[9-18]取得了较好的分割性能,但忽略了点云中点之间的邻域关系与拓扑结构信息。
该文算法为了避免数据几何信息的丢失,将点云数据作为PointNet++网络结构网络的输入,在其局部特征提取过程中引入注意力机制对邻域点空间位置信息等进行自适应学习;其次采用多尺度局部特征提取策略达到多尺度特征互补,并设计了多尺度交叉熵损失函数进行网络训练。
1 算法原理
1.1 降采样局部邻域构建
由于LiRAR 或者深度相机产生的点云数据量过大,且不同点云数据间的点数量不相等导致训练过程中批量训练难以进行,所以该文算法采用最远点采样算法(Farthest Point Sampling,FPS)实现对原始点云的降采样操作,以确定局部邻域中心点,降低数据冗余度与模型输入大小。最远点采样算法具体流程如下:
1)随机选择一个初始点作为已选采样点;
2)计算未选采样点集中每个点与已选采样点之间的距离,将距离最大点添加到已选采样点集;
3)循环迭代更新,直至获得目标数量采样点。
以通过降采样获取的点为中心划定半径,使用球查询(Ball query)的方式找出在该半径球内固定规模N的点作为该点的相邻点,降采样中心点pi与其相邻点pj∈N(pi)共同完成局部邻域的构建。
1.2 局部特征提取层
该文算法采用邻域注意力机制获取每个点邻域注意力系数,同时使用中心点与邻域点空间位置信息、欧式距离、角度信息作为特征提取输入,以增强点集语义表达。具体方法为:首先在以某一点pi为中心点的局部区域内对pi和其相邻点pj∈N(pi)构建向量λi,j∈R13:
其中,xi与xj分别表示pi和pj的坐标信息;xj-xi表示pj相对于中心点pi的坐标;||·||表示pi和pj的欧式距离;aj表示pj在三个坐标轴方向上相对于pi的角度信息,计算过程如下:
向量λi,j∈R13包含了中心点pi与pj的空间位置和几何信息。利用多层感知机分别将局部邻域内的λi,j∈R13经式(3)隐式编码映射得到高维特征:
其中,MLP(·) 为多层感知机。C1为特征维度数,点云数据包含颜色、反射光强度等信息,将局部邻域内提取到的高维特征与上述信息进行融合得到增强特征,其中,C2为附加特征维度。增强特征通过式(4)获得不同邻域点注意力系数:
注意力系数表示邻域点对于中心点的影响程度,注意力系数越大表明邻域点对中心点影响越大。将上述操作所得注意力系数通过softmax 操作进行归一化处理,使所有的注意力系数相加为1,计算公式如下所示:
将邻域点特征与注意力系数逐元素相乘得到重新分配的中心点特征,如式(6)所示:
其中,bi为偏置项。通过最大池化聚合邻域特征获得pi,输出局部特征,该特征包含局部区域内丰富的点之间的邻域关系和空间几何信息,池化操作使点云局部特征提取过程满足置换不变性,如图1所示。
图1 中,降采样局部邻域构建可得到局部邻域点,经过多层感知机映射得到特征向量,邻域点特征向量最大值聚合得到中心点特征向量,保证了不同输入邻域点顺序依然可以聚合得到相同中心点特征。
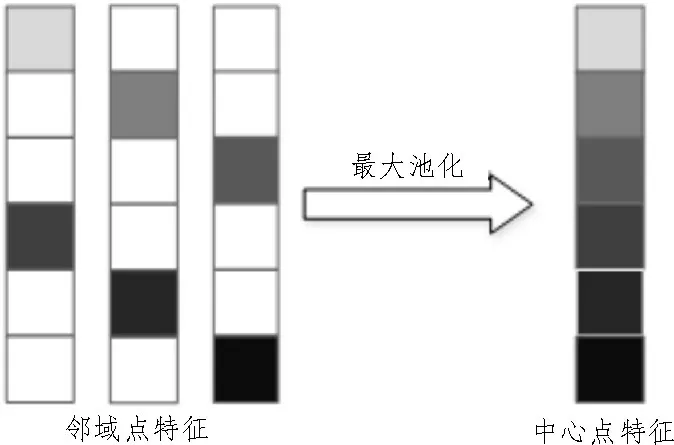
图1 池化操作过程
1.3 多尺度特征提取策略
为了获得足够的特征信息以及消除点云数据下采样过程中信息丢失的影响,该文采用多尺度局部特征提取策略,针对某一中心点pi,选取不同区域半径构建不同尺度的局部区域。将这些不同区域点分别送入基于注意力机制局部特征提取层,生成不同尺度语义特征,最后将所得特征拼接生成最终语义特征,以达到多尺度特征互补,特征拼接过程如式(7)所示:
为了使网络具有自适应探索语义关系和局部几何信息能力,该文利用多尺度交叉熵损失函数进行网络训练,损失函数定义如下:
其中,Li为第i个尺度上的交叉熵损失函数,λi为多尺度交叉熵损失因子,设置为1。
1.4 网络结构
该文算法利用PointNet++[9]分层提取特征结构,将点云数据作为网络输入进行降采样,相较以往基于体素与基于多视图转化方法,其最大程度地避免了数据几何信息丢失。该文所提语义分割整体网络结构如图2 所示。
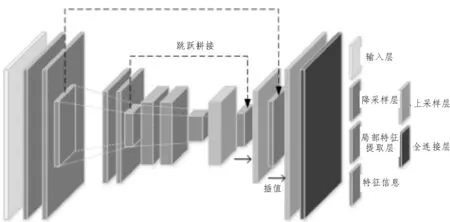
图2 整体网络结构图
图2 中,输入点集利用最远点采样算法完成降采样局部邻域的构建,利用注意力机制局部特征提取层提取邻域点特征、空间位置信息、几何距离与角度等基本几何特征,完成局部邻域点之间邻域关系与几何信息的学习。针对点云数据语义分割任务,在上采样层网络利用基于反距离加权平均插值法恢复点云数量,该方法的核心思想是通过衡量与关键点的距离确定权重值大小,距离关键点距离越大的点所求权重越小,反之权重值越大。同时利用跳跃拼接将点数相同的局部特征提取层与上采样层的特征信息进行拼接,使输出特征既包括局部特征也包括全局特征。将最终的特征信息输入全连接神经网络层,以输出点云数据中每个点的语义分割结果。
2 实验过程及结果分析
2.1 数据集
该文使用斯坦福大规模三维室内空间数据集S3DIS[19]作为实验数据集来评估所提算法语义场景分割任务性能,该数据集覆盖面积超过6 000 m2,包含来自三栋建筑物的六个不同大型室内场景中的272 个房间的3D 扫描点云数据,不同类型的场景可视化如图3 所示。该数据集分别对每个房间内天花板、地板、墙面、房梁、柱子等13 个类别物体进行了语义标注。每个数据中包含X、Y、Z坐标信息、标签信息和RGB 颜色信息,该文将X、Y、Z坐标信息和标签信息作为网络输入进行实验。

图3 不同室内场景可视化
2.2 预处理
点云是众多反映三维场景或物体几何信息的点坐标集合,一个真实场景通常包含了大量点云数据。S3DIS 数据集点云总数量超过了2 亿,受限于该文实验条件,网络在训练过程中使用全部数据点会导致计算量过大。因此,该文在网络训练阶段采用数据规约对数据集进行预处理,将每个室内场景分为1 m×1 m 的块,采用随机采样对每个块取n个样本点,实验中的n取4 096,网络测试阶段使用每个块中的全部样本点。
2.3 实验环境与设置
该文实验硬件配置为Intel(R) Xeon(R) Gold 5120 CPU@2.20 GHz处理器,显卡为NVIDIA Tesla P4(8G)。操作系统采用Linux Ubuntu20.04,运算平台为CUDA-Toolkit 11.2,CUDNN 7.6.5 作为GPU 加速器。
该文算法在Pytorch 1.6.0 框架下进行实验,网络参数设置如表1-2 所示。

表1 网络参数设置(1)

表2 网络参数设置(2)
2.4 网络性能评价指标
实验中选取总体准确度oAcc、类别交并比IoU以及平均类别交并比mIoU 作为语义分割评估指标。总体准确度oAcc:预测正确的点云数量与总体点云数量的比值,计算过程如式(9)所示:
其中,设点云数据中共有N+1 个类别,Pij表示第i类类别被预测分类为第j类类别的点,Pii表示第i类类别被预测为第i类类别的点。
类别交并比IoU 是每种类别预测值与标签值交集和并集的比值,而平均类别交并比mIoU 是利用上述所有类别交并比求平均值,具体计算公式如式(10)所示:
其中,N+1 在实验中取室内数据集所包含的13 个类别,Pji表示第j类类别被预测分为第i类类别的点,其他变量所代表的意义与式(9)相同。
2.5 实验结果与分析
为了验证该文算法在三维点云语义分割任务中的有效性,在S3DIS 数据集上进行网络的训练与测试,实验中S3DIS 数据集分为6 个区域:Area_1、Area_2、Area_3、Area_4、Area_5、Area_6。其中,Area_5 包含了该数据集中的全部建筑物与物体类别,并且与其他区域中的物体在外观上存在一定差异,因此,使用Area_5 作为算法的测试集,其他区域作为训练集,可以评估网络的泛化性能。
表3 为该文算法在测试集Area_5 上的分割结果,评价指标分别是总体准确度oAcc、平均类别交并比mIoU 以及13 个类别物体的交并比IoU。将结果与已有算法PointNet、PointNet++、PointConv 进行对比,其中,该文算法的oAcc 较PointNet++提高了6.18%,mIoU 提高了5.96%,墙面、窗户、门、黑板这几类几何结构为平面体的物体类别IoU 分别提高了7.4%、1.02%、10.73%、3.96%,由此可见,该文算法依据局部邻域点的空间位置信息、几何距离信息以及角度信息分配邻域点注意力系数,以聚合中心点局部特征信息的方式充分利用了点之间的邻域关系与几何信息,在一些空间几何结构相似的语义场景下依然可以得到较好的分割效果。但是,在对横梁与柱体的分割中所达到的IoU依然分别只有0.00%与9.43%,这是由于这两类类别在数据集中占据的数量比较少,因此算法能够学习到的特征有限,不容易正确分割,导致分割精度较低。

表3 测试集Area_5评估的语义分割结果
图4 进一步给出了该文算法的语义分割效果图,图中第1 列为真实场景,第2 列为点云分割真实值,第3 列为对比算法PointNet++分割预测值,第4 列为该文算法的分割结果预测值,从分割效果图也可以看出该文算法在复杂场景中对几何结构相似类别的分割效果要优于原始网络结构,解决了原网络结构部分错分割与漏分割问题。

图4 不同场景语义分割效果对比
3 结论
针对当前点云语义分割网络结构在局部区域中单独提取点特征,缺乏点之间邻域关系及几何信息学习和复杂场景分割能力较弱的问题,该文算法融合注意力机制与PointNet++网络结构,使模型自适应学习邻域点的空间位置等信息。此外,采用多尺度局部特征提取策略抵消点云数据下采样中的信息丢失,设计了多尺度交叉熵损失函数进行网络训练。该文算法在S3DIS 上相较于原始网络结构oAcc 与mIoU 分别提高了6.18%、5.96%,然而对于横梁与柱体两类数据量占比非常小的物体测试效果仍存在提升空间,之后将在较少点云数据下进行实验,进一步完善算法以提升模型的分割精度。
