集成强化学习算法的柔性作业车间调度问题研究
2023-02-17焦小刚
张 凯 毕 利 焦小刚
宁夏大学信息工程学院,银川,750021
0 引言
柔性作业车间调度问题(flexible job-shop scheduling problem,FJSP)自提出以来已被广泛研究[1-2],共有三类求解方式:基于规则、基于元启发式[3-7]和基于强化学习[8]。
基于规则的方法无法保证最优解,基于元启发式的方法计算量大且易于陷入局部最优解。为提出更好的解决方案,近年来,学者使用强化学习(reinforcement learning,RL)求解FJSP。XUE等[9]指出,基于强化学习求解调度问题需要解决2个问题:如何将调度问题转化为强化学习问题,如何保证强化学习能得到调度问题合适的解。基于Q-learning 的遗传算法的参数调整方法可自动调参并找到最优参数[10]。LUO[11]利用深度Q网络算法解决了有随机任务插入的动态柔性车间调度问题。ZHANG等[12]使用析取图表示车间调度的状态,通过 PPO(proximal policy optimization)算法同时训练智能体的策略和析取图组成的图神经网络,实验结果表明该方法优于传统方法。
目前,采用强化学习主流算法求解FJSP存在两个问题:①将FJSP转换为马尔可夫决策过程(Markov decision process,MDP)时,针对不同求解目标构建不同的状态特征、动作空间、奖励函数,状态中的一些隐性关系难以获得;②使用强化学习算法训练求解时,只用到单一算法,不能充分体现和利用算法的改进、优化、融合。针对上述两个问题,笔者在求解目标为最大完工最小化时构建一种新的MDP,并提出D5QN算法进行求解。实验结果表明该方法可使最大完工时间最小化的指标进一步提高。
1 问题建模
FJSP描述为n个工件{J1,J2,…,Jn}在m台机器{M1,M2,…,Mm}上加工。每个工件包含一道或多道工序。工序是预先确定的,每道工序可以在不同加工机器上完成,工序的加工时间随加工机器的不同而不同。
1.1 目标
标为最小化最大完工时间,即
(1)
式中,i为工件号;Ci为工件i的完工时间。
1.2 符号表示
FJSP的符号和决策变量的说明见表1。

表1 FJSP符号描述Tab.1 FJSP symbol description
1.3 约束表示
问题模型共有6个约束条件:①1台机器一次只能加工1个工件;②工件的一道工序只能由1台机器完成;③工序开始后,加工不能中断;④工件的优先级相同;⑤不同工件的工序没有先后约束,每个工件的工序有先后约束;⑥所有工件在零时刻都可被加工。FJSP约束的公式描述和含义如表2所示。

表2 FJSP约束表示Tab.2 FJSP constraint representation
2 强化学习和D5QN
2.1 强化学习
强化学习表述为一个智能体如何在一个复杂不确定的环境里面最大化它能获得的奖励,如图1所示,其中,下标t表示当前时间步,t+1表示下一时间步。
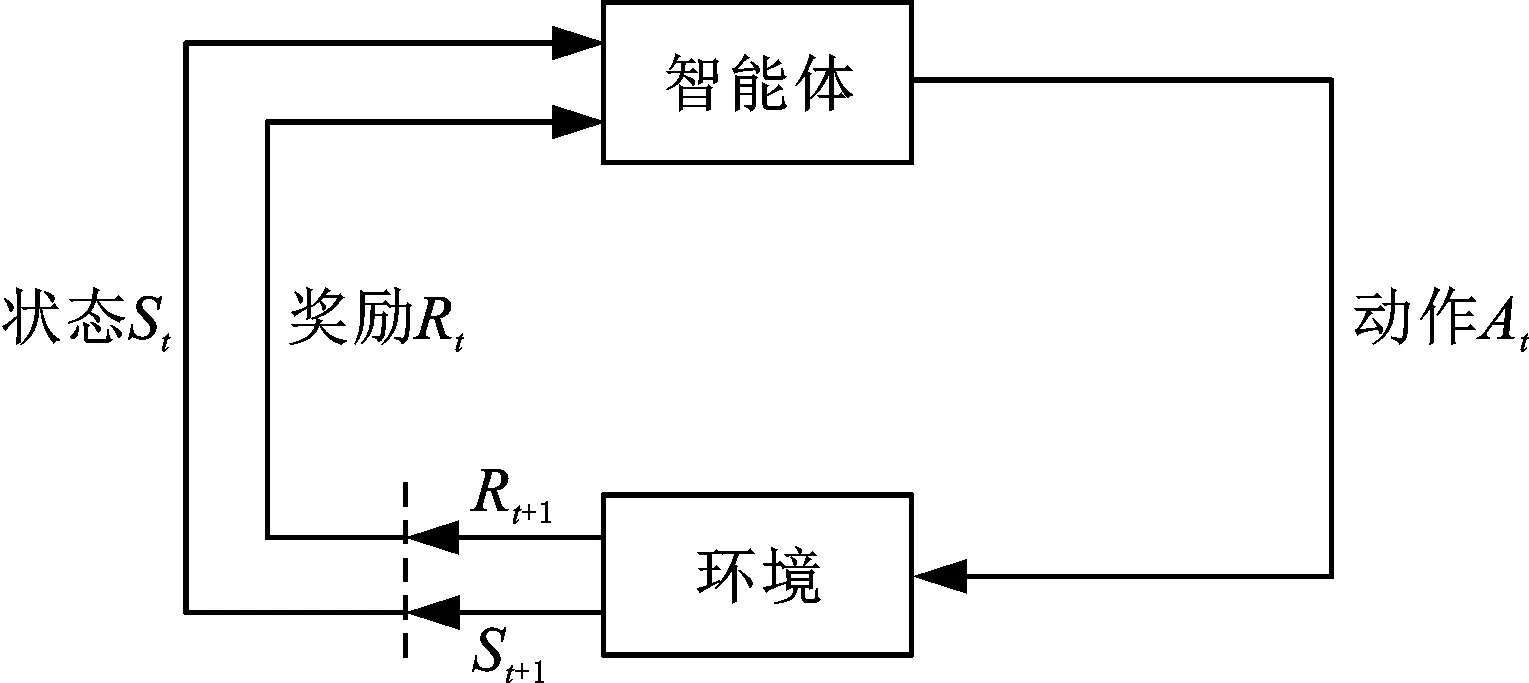
图1 强化学习Fig.1 Reinforcement learning
强化学习过程可以被建模为一个由5元组(S,A,P,γ,R)表示的马尔可夫决策过程。其中,S表示环境目前的状态;A表示智能体采取的动作;P表示从一个状态转移到下一个状态的概率;γ为折扣因子,取值区间为(0,1);R表示智能体采取一个动作后给予的奖励。智能体根据特定的策略与周围的环境进行交互,通过当前状态st(st∈S),下标t表示当前时间点,根据策略π(S→A)执行动作at(at∈A),得到一个新的状态st+1和转移概率p(st+1|st,at)∈P(S×A→S),并得到奖励rt(rt∈R)。智能体的目标是找到最优策略π*,使动作在状态预期的长期回报总和最大。选取动作的价值函数为
qπ*(s,a)=maxqπ(s,a)
(2)
2.2 DQN及其优化
(1)深度Q网络(deep Q-network,DQN)结合强化学习和深度学习,提出经验回放和目标网络两个技巧,针对传统Q-Learning方式无法处理连续价值函数的问题,通过函数qφ(s,a)来表示近似状态价值函数:
qφ(s,a)≈qπ(s,a)
(3)
(2)双深度Q网络(double DQN,DQN)用来解决DQN算法在训练时函数q值往往被高估的问题,即同时存在两个网络:网络Q决定的哪一个动作的q值最大,网络Q′计算q值。q值更新的方式为
(4)


(5)
(4)优先级经验回放(prioritized experience replay,PER)指的是以一定的优先级进行经验回放,即增大重要数据的采样几率,以达到更好的训练效果,在DQN中添加优先经验回放后表现为图2。

图2 优先经验回放机制Fig.2 Priority experience playback mechanism
(5)竞争深度Q网络(dueling DQN)在DQN的基础上,将深度Q网络的计算过程分为两步。第一步计算一个与输入有关的标量V(s);第二步会计算向量A(s,a),最后的网络是将两步的结果组合,网络结构如图3所示。

图3 Dueling DQN网络结构图Fig.3 Dueling DQN network structure diagram
2.3 D5QN算法
在DQN算法的基础上,集成DQN、noisy DQN、PER DQN和dueling DQN,提出D5QN算法。D5QN可有效利用每种算法的优点,即使用神经网络拟合状态,使用DQN避免过度估计,加入噪声增加探索多样性,使用优先经验回放加快训练,使用竞争网络提高训练q值,并且每种优化方式不会相互产生负影响,达到取长补短的效果。D5QN算法流程伪代码如下,其中,yi为当前网络要求解的目标值。

伪代码1:D5QN算法流程初始化缓冲池D大小为N初始化当前网络Q权重为θ初始化目标网络Q^权重θ-=θ对于每一个回合episode=1:L 初始化状态s1中的n个特征表述为向量φ1 为Q网络添加一个新的高斯噪声 对于每一个时间步t(T为回合中的最大时间步数,T=p) 以一定的概率ε选择一个随机的动作at 否则动作at=argmaxaq~(s,a) 执行动作at,观察下一个状态st+1,计算奖励rt 获得新的特征向量φt+1 存储四元组(φt,at,rt,φt+1)到缓冲池D,且为该四元组添加优先级 在D中以权重概率的方式选择一个batch_size (φj,aj,rj,φj+1) yj=rj当前步数调度结束rj+γQ^(φj+1,argmaxa'Q(φj+1,a';θ);θ-)其他 通过目标与当前Q网络差值(yj-Q(φj,aj;θ))2执行梯度下降,从而更新Q网络中的参数θC步更新Q^=Q(将目标网络更新为当前网络,C为所经历的时间步数)
3 模型求解
求解FJSP时,首先将FJSP转化为MDP,然后通过D5QN算法求解。本章依次描述状态、动作、奖励、求解过程。
3.1 状态描述
通过提取调度过程的重要特征来近似描述某一时刻的调度状态。调度环境在某一时刻的状态由一组向量表示。每个值或每组值(用向量表示)描述如表3所示。

表3 MDP状态描述Tab.3 MDP status description
表3描述调度过程中的状态表示的一系列指标。每个量和向量元素的值都在0~1之间,且每个指标在0时刻的初始值均为0。调度过程中某时刻的状态可表示为
φ=(Mr1,Mr2,…,Mrm,Mw1,Mw2,…,Mwm,
Jr1,Jr2,…,Jrn,Mr,Mrr,Mw,Mww,Jr,Jrr,Or)
(6)
3.2 动作设计
针对所要求解的目标——最大完工时间最小化,设计出映射目标的三组动作。每组动作包含
m个动作(与机器总数相同),具体描述见表4,其中,Ωt为t时刻可调度的(机器、工件)列表(随机打乱);Ωj为第j(j=1,2,3)组动作的可加工(机器,工件)列表(按照特定指标排序);Aj为第j组动作的可选动作集合;aj为第j组动作中选取的具体动作标号;Mk、Ji分别为最终选取的机器和工件的编号。

表4 动作表述Tab.4 Action statement
每组可用的动作少于m个即Ωt的大小小于m(多数情况下如此)时,采取循环队列的方式继续从头选取。
该动作表述方式有三个优点:①可以选取的动作均与求解的目标紧密关联,即通过加工时间、机器利用率、工件完成率来反映最大完工时间;②确保动作多样化,即每组动作的可选择数量为机器数量(每一个动作中包含对应一个机器),保证某一时刻下选取动作时每个机器均可能被选择;③循环队列方式可使队列中队首的元素(对应的动作)被采用的概率增大。例如:当前空闲机器数量为3,总机器数量为5,如果当前选择的动作编号4对应第4个机器,该机器不可用,则最终选取编号为1,即该机器编号对可用机器总数取余数。
3.3 奖励设计
奖励的设计直接影响训练的最终效果,是最为关键的步骤之一。最大完工时间最小化求解目标在MDP中属于“奖励罕见”的情况,最后一步操作完成时才知道最终完工时间。所以在非终止步骤,需要对问题求解进行转换,即对奖励进行间接映射,从而更好地完成训练。
考虑到最大完工时间最小可以间接反映为每个机器的利用率和每个工件的完成率尽可能均衡,所以每一步尽最大可能均衡机器的使用率和工件完成率。
单一规则调度后,可以估算出完工时间的范围,如果完成调度时时间超出预设的完工时间(超参数)Cbest,则产生很大的负奖励,否则产生正奖励。强化学习中,奖励有正有负才能达到更好的训练结果。奖励的描述如伪代码2所示。其中,reward表示每一次调度完成时的及时奖励。

伪代码2:奖励描述if调度尚未结束 if调度已用时间≥Cbest 终止调度,reward=-100 else if Mr增大 and Jr增大 reward=1 else reward=-1 end if end ifelse if完工时间≥Cbest reward=-100 else reward=(Cbest-完工时间)*10+0.01 end ifend if
3.4 算法流程实现
状态、动作、奖励设计完成之后,采用D5QN算法求解,利用全连接网络描述Q网络的网络结构。图4反映了FJSP转化为MDP以及通过D5QN算法求解的过程。

图4 D5QN算法求解FJSPFig.4 D5QN algorithm to solve FJSP
4 实验
程序在Windows10 64bit的个人电脑(CPU I7-7700、内存8GB)上运行。语言环境基于python 3.9.12、conda 4.12.0,问题环境基于OpenAIGym编写,深度网络基于torch 1.11.0和numpy 1.21.5编写。
为验证所提出方法的优越性,首先将D5QN与其他单一优化DQN算法进行对比。其次,在相同数据集下与文献[13-14]的方法,以及与基于规则和元启发式的方法进行对比。
4.1 D5QN与单一优化DQN的对比
将D5QN算法与其他单一优化DQN算法对比,Mk算例集上各个算法求解的最优结果如表5所示,加粗数字为所有算法求出的最好解。Mk算例集在提出之时,规定最优解是一个范围。
表5表明,相同的MDP下,某些单一优化DQN算法在某些算例下可以取得最优解,但D5QN算法最优解不劣于其他DQN优化算法的最优解。
D5QN在Mk09上求解时,迭代次数和完工时间如图5所示。由于noisy DQN、PER DQN和dueling DQN效果相似,故将DQN、dueling DQN、D5QN三种算法作对比,3种算法求解的迭代次数和平均完工时间的关系如图6所示,由图6可以得出D5QN算法的收敛速度和最终收敛效果优于其他算法。

图5 D5QN算法在Mk09上的迭代次数和完工时间图Fig.5 The number of iterations and completion time of the D5QN algorithm on Mk09
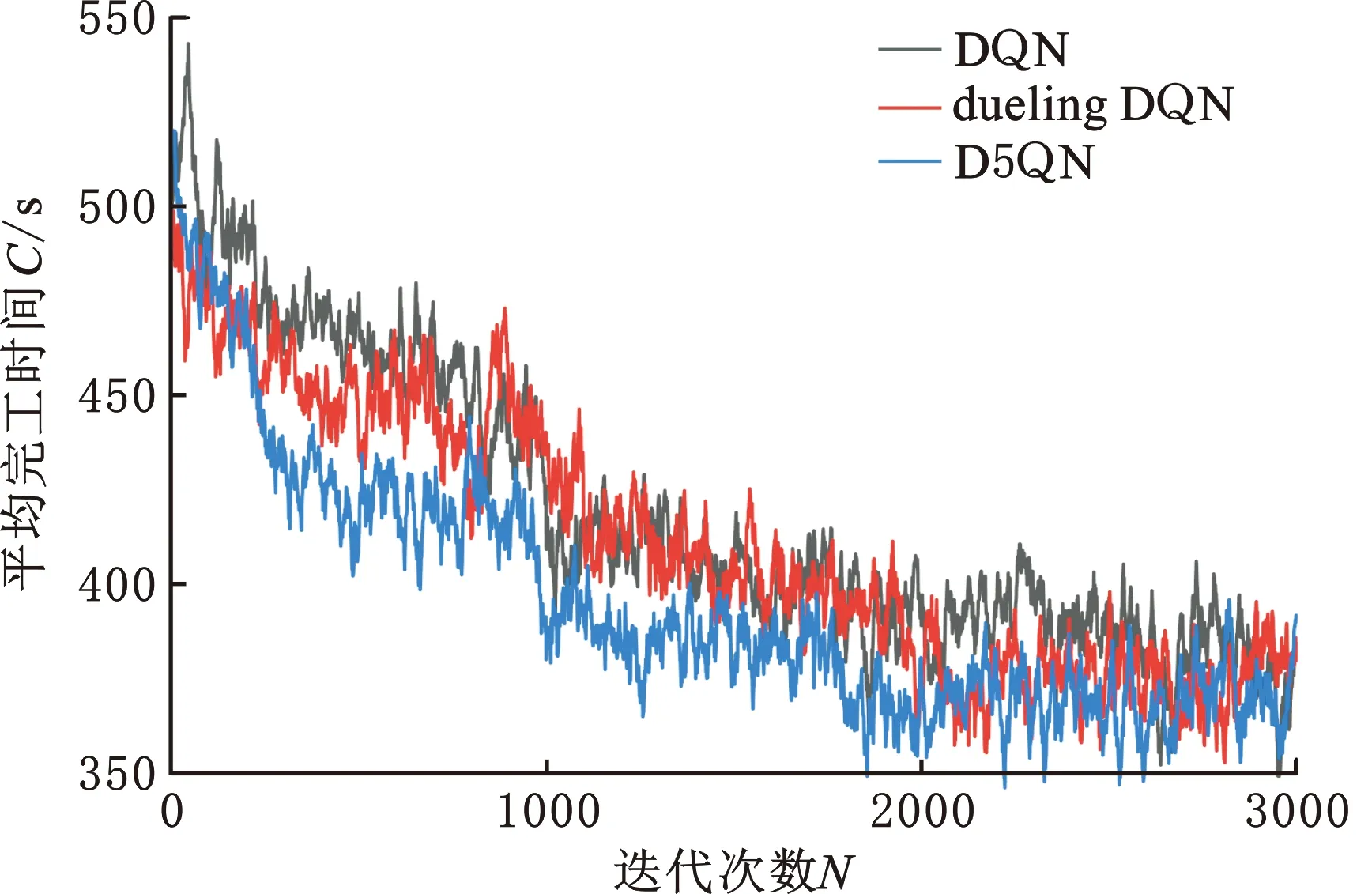
图6 DQN、dueling DQN、D5QN在Mk09训练集上平均完工时间Fig.6 Average completion time of DQN,dueling DQN,D5QN on Mk09 training set
4.2 D5QN与其他算法对比
表6所示为基于规则组合的三种方式(SPT+EF[13]、SRPT+EF[13]、SRPT+SPT[13])、遗传算法(genetic algorithm,GA[13])、其他强化学习算法(AC-SD[14]、PPO[13])和D5QN算法的最优结果。遗传算法和其他强化学习算法可以在某些算例下取得与D5QN相同的结果,但D5QN在每种算例下均可以取得最优解(加粗数值)。

表6 D5QN和其他方式求解FJSP最短完工时间Tab.6 D5QN and other ways to solve FJSP minimum makepan
图7、图8中,GA、AC-SD(actor critic-SD)、PPO和D5QN在求解出的最优解上优于基于规则组合的方式,且D5QN在求出的最优解(指标:最大完工时间最小)上比GA和PPO、AC-SD算法效果更好。

图7 不同方式求解Mk01~Mk10平均最短完工时间Fig.7 Different ways to solve Mk01~Mk10 average shortest completion time

图8 不同方式求解Mk01~Mk10总最小完工时间对比Fig.8 Comparison of total minimum completion time for solving Mk01~Mk10 in different ways
实验结果均表明D5QN在求解Mk01~Mk10时均可取得最优解,优于单一优化DQN算法、基于规则方法、遗传算法和其他强化学习算法。
5 结论
为了求得FJSP的更优解,将FJSP转换为马尔可夫决策过程,并通过集成了DQN、DDQN、noisy DQN、PER DQN和dueling DQN 5种算法的D5QN算法进行求解。
FJSP中的经典问题集Mk01~Mk10的求解结果验证了D5QN算法的可行性和有效性。未来针对多目标、动态环境下的FJSP,尝试使用更多方式构建MDP并通过其他强化学习改进算法,继而进一步提高求解质量。
