基于Raft算法改进的实用拜占庭容错共识算法
2023-02-03王谨东
王谨东,李 强
(四川大学 计算机学院,成都 610065)
0 引言
区块链作为以比特币[1]为代表的众多数字货币的底层技术支撑,近年来受到广泛关注并逐渐应用到众多领域。区块链的本质是网络中的各个节点在分布式的环境下,借助密码学、共识算法、利用智能合约操作数据的一种链式数据结构。作为一种全新的分布式计算范式,区块链提供了去中心化、不可篡改、透明、可溯源的分布式数据库解决方案[2]。
根据节点准入机制的不同,可将区块链分为公有链(Public blockchain)、联盟链(Consortium blockchain)、私有链(Private blockchain)三类[3]。其中,联盟链具有一定的准入门槛,节点需要授权才能加入区块链网络,是多中心化的区块链,也是未来区块链发展的重要方向[4]。联盟链目前在数据存储[5]、版权管理[6]、隐私保护[7]、数据溯源[8]等方面已有众多的应用。在大多数情况下,联盟链不需要设计激励层来推动“挖矿”和智能合约的执行,降低了系统部署和维护的成本;同时,以Hyperledger Fabric[9]为代表的众多企业级区块链平台支持可插拔的共识算法、多种语言编写智能合约,进一步推动了大量基于联盟链的应用落地。然而,联盟链仍然面临可扩展性差的问题。目前在联盟链应用广泛的实用拜占庭容错(Practical Byzantine Fault Tolerance,PBFT)[10]共识算法虽然不需要消耗大量算力,但随着节点数量的增长,其通信开销会呈平方级增长,导致共识效率较低。在金融、智慧城市、供应链管理等领域对区块链的性能与可扩展性要求较高,通常要求单链到达万级吞吐量、千级节点组网能力、秒级交易确认时延,PBFT 算法难以满足这些领域的需求[11]。同时,PBFT 算法的网络结构相对静态,动态添加节点时必须重启整个系统[12],严重影响系统的可用性。不难发现,PBFT 算法目前已不能满足部分应用场景的需求,一定程度限制了联盟链的进一步发展。共识算法作为区块链的核心技术,对区块链的交易确认时延、吞吐量、可扩展性有着决定性的影响,对PBFT 算法进行改进能够有效解决上述问题。
针对PBFT 共识算法存在的问题,文献[13]提出了一种基于协调器的共识算法,通过协调器将交易分类处理,并只对异常交易执行完整的共识,将该算法应用于PBFT 后,获得了使共识时延缩短为原来的21%;但可能会面临协调器单点故障导致系统失效的问题。文献[14]将区块链分片,在分片内部与分片之间分别执行PBFT 算法,使共识效率提升了20%,提升了系统的可扩展性;但是这种算法可能导致整个区块链网络中的数据不一致。文献[15]提出了一种基于特定硬件的PBFT 共识算法,所有节点使用硬件芯片(如Intel SGX)构建可信执行环境(Trusted Execution Environment,TEE),并利用消息聚合技术使算法的通信开销大幅降低;虽然这种算法提升了PBFT 算法的可扩展性,但需要所有节点都具备相同的硬件环境,在实际应用中具有一定的局限性。文献[16]提出了一种基于EigenTrust 信任模型的PBFT 算法,通过各节点的行为来评估节点的信任度,选择高质量的节点构建共识组以降低视图切换概率;但这种算法在共识中的通信复杂度与PBFT 算法相同,难以显著地提升PBFT 算法的可扩展性。文献[17]提出了一种基于分片型区块链的共识算法RapidChain,其Decentralized Bootstrapping 阶段将参与共识的节点划分为多个共识委员会。RapidChain 改进了PBFT 算法,将PBFT 算法与ErasureCode、IDA-Gossip 消息传递协议结合,原消息被分割为若干个片段在网络中传播,各节点收到消息后通过ErasureCode 恢复原消息以减少通信量。
仅对PBFT 算法进行改进并不能从根本上解决PBFT 算法存在的问题,当节点数量增加时,三阶段提交过程会使其性能大幅降低。因此,本文提出了一种基于Raft 算法改进的实用拜占庭容错共识算法K-RPBFT(K-medoids Raft based Practical Byzantine Fault Tolerance)。首先,以节点之间的通信时延作为欧氏距离,利用K-medoids 聚类算法将区块链分片;其次,每个分片的主节点之间使用PBFT 算法进行共识,在分片内部使用基于监督节点改进的Raft 算法进行共识。该算法大幅降低了PBFT 算法的通信开销与共识时延,提升了吞吐量,并且使系统拥有动态的网络结构。本文的主要工作如下:
1)提出了一种带监督节点的拜占庭容错共识算法K-RPBFT,阐述了K-RPBFT 算法的分片策略、监督机制、共识流程。
2)对K-RPBFT 算法的安全性、一致性、活性进行了分析,以证明K-RPBFT 算法的有效性。
3)通过实验对K-RPBFT 算法进行了评估,与PBFT 算法、Raft 算法在单次共识通信次数、共识时延、吞吐量等方面进行了对比。
1 相关背景
1.1 PBFT算法
PBFT 算法由Castro 等[10]于1999 年提出,最初被用于构建支持拜占庭容错的分布式系统,能够在系统内拜占庭节点数量(n为节点总量)的情况下保证系统的可用性。随着区块链技术的不断发展,PBFT 算法常被用于联盟链中节点的共识过程。
PBFT 算法的共识过程包含请求(request)、预准备(preprepare)、准备(prepare)、提交(commit)、回复(reply)等阶段。主节点(Leader)在收到客户端的请求消息后,将会生成预准备消息并广播给所有从节点(replica)。从节点在收到预准备消息并且通过验证后,将向所有节点发送准备消息。当从节点收到2f个不同节点(不包括自己)的有效准备消息时,将会向其他节点广播确认消息。此时节点将会收集所有的确认消息,当收到2f+1 个来自不同节点的有效确认消息时,此请求消息将会被提交,同时向客户端发送回复消息。当客户端收到f+1 个不同节点的有效回复消息后,会认为一次共识成功。PBFT 算法的共识流程如图1 所示。

图1 PBFT算法的共识流程Fig.1 Consensus flow of PBFT algorithm
当从节点检测到主节点失效或为拜占庭节点时,将触发视图切换(view-change)协议重新选举主节点。在PBFT 算法中,主节点按照编号轮流当选。视图切换协议保证了即使主节点为拜占庭节点,系统仍能正常工作。
PBFT 是一个三阶段提交算法,从节点之间的相互验证导致PBFT 的通信复杂度为O(N2),使得算法的可扩展性不强,在具有大规模节点的区块链系统下,可能会导致网络风暴。
1.2 Raft算法
Raft 算法由Ongaro 等[18]于2014 年提出,是一种相较于Paxos[19]更易理解与实现的共识算法。Raft 的核心由日志复制与领导者选举两部分构成,节点的状态将会根据不同的条件在领导者(Leader)、跟随者(Follower)、候选者(Candidate)之间变迁。系统在任意时刻只拥有1 个领导者,并与所有跟随者之间维持周期性的心跳消息。当跟随者超时仍未收到领导者的心跳消息时,将会转变为候选者状态。候选者将会向其他节点发送投票请求消息,申请成为新的领导者,如果此候选者在超时前收到超过半数节点的确认消息,则转换为领导者。节点状态的详细变迁过程如图2 所示。
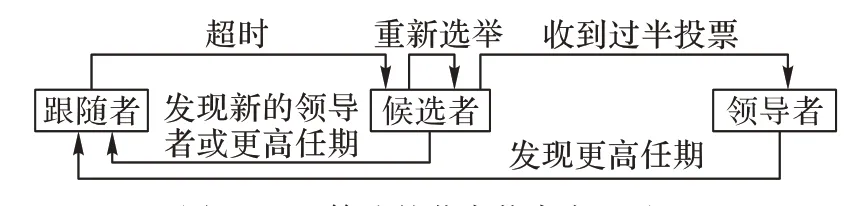
图2 Raft算法的节点状态变迁过程Fig.2 Node state transition process of Raft algorithm
在日志复制阶段,所有的交易均由领导者打包生成区块并向所有的跟随者广播,在收到超过一半的跟随者回复后,领导者将会向所有节点发送确认信息,此时该区块将会被提交上链。
Raft 算法的通信复杂度为O(N),共识效率较高,具有良好的扩展性。Raft 算法在系统内不超过一半的节点宕机时仍能正常工作,但是不支持拜占庭容错,因此通常应用于节点完全可信的私有链中。
2 K-RPBFT算法模型
本文结合PBFT 算法的拜占庭容错特性与Raft 算法的高效性,提出一种带监督节点的分片区块链共识算法K-RPBFT。在区块链中引入若干监督节点,基于K-medoids聚类算法将区块链分片,令分片数量K等于监督节点数量,并为每个分片分配一个监督节点。在分片内部使用改进的Raft 算法进行共识,在每个分片的Raft 领导者之间使用PBFT算法进行共识。
2.1 K-RPBFT分片策略
K-medoids 算法是一种常见的无监督聚类算法,初始的聚类中心点限定在样本点中,且K-medoids 对于样本中噪声的鲁棒性相较于K-means 等算法更好[20],因此基于K-medoids 算法对区块链网络进行分片,具体过程如下。
1)节点探测。
定义区块链网络中的节点集合V={v1,v2,…,vn},对于∀vi∈V,在初始分片时向节点集合V中的所有节点发送探测消息PING,vi,timestampi,signi,其中PING 为探测消息标识,vi为节点编号,timestampi为探测消息发送时的时间戳,signi为消息签名。∀vj∈V(i≠j),收到此探测消息后将会记录时间戳timestampji,并验证消息的合法性,通过验证后则由式(1)计算出节点vi到vj的单向距离。

节点vj将d(vi,vj) 记录到本地并构造回复消息REPLY,vj,d(vi,vj),signj发送给vi,其中REPLY 为回复消息标识,vj为节点编号,d(vi,vj)为单向距离,signj为消息签名。
当探测结束后,所有节点将会计算出一个全局一致的距离矩阵:

其中dij(1 ≤i≤n,1 ≤j≤n)由式(3)计算:

2)初始分片。
使用K-medoids 算法将节点聚类为K个簇,并使K等于区块链网络中监督节点的数量。用Ci表示每个簇,在每一轮迭代过程中,Ci都有一个当前聚类的簇中心节点ni,定义所有的簇中心节点集合N={n1,n2,…,nK}。根据距离矩阵D,构建节点vi的隶属函数:
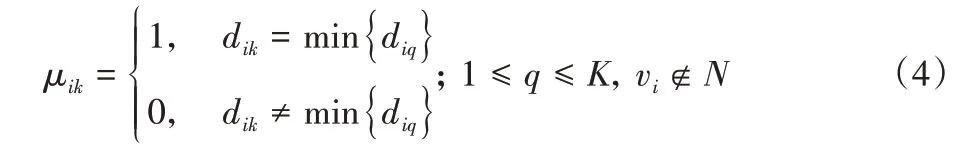
根据隶属函数可以得到迭代的目标函数:

根据K-medoids 算法流程,在节点集合V中随机选取K个节点作为初始聚类中心节点。根据式(4)将剩余节点分配到相应的簇中心。在每个簇中,计算每个节点对应的准则函数,选择准则函数最小时的节点作为新的簇中心。重复迭代上述过程直至所有的簇中心不再发生变化。
当K-medoids 算法迭代收敛后,此时的目标函数值最小。按照迭代生成的聚类结果将区块链划分为K个分片,簇中心节点作为分片的领导者,其余的节点作为跟随者,并为每个分片分配监督节点。在所有的簇中心节点之间执行“片间共识”,在每个簇内部执行“片内共识”。此时分片区块链的模型结构如图3 所示。

图3 分片区块链模型Fig.3 Model of sharding-based blockchain
3)重分片。
区块链网络的运行过程中,可能会存在节点动态加入或退出的情况。K-RPBFT 分片模型所使用的节点探测与K-medoids 算法的迭代过程均需要消耗资源。为了更好地控制分片过程的资源消耗,引入重分片上限阈值与重分片下限阈值参数。节点动态加入区块链时,将直接加入节点数量最少的分片中,当有节点加入或退出区块链网络时,都会对每个分片的节点数量进行检查,若某一分片的节点数量大于重分片上限阈值或者小于重分片下限阈值时,将会按照分片模型重新进行区块链分片。定义稳定系数S为重分片上限阈值与重分片下限阈值之差:当S较大时,区块链的各节点结构较为稳定,不会频繁发生重分片,但随着节点地不断加入或退出,可能会导致区块链的分片方式与理论最优分片方式出现一定偏差;当S较小时,区块链的结构更容易反映真实的聚类情况,但资源消耗较高。在实际应用中,可设置不同的稳定系数以满足算法在不同场景下的需求;同时,传统的PBFT 算法并不支持节点动态加入,新的节点加入时系统必须重启,而每个分片内部使用的Raft 算法赋予了系统动态添加或删除节点的能力,提高了系统的灵活性,使系统具有动态的网络结构。
2.2 片内共识与监督机制
在分片内部,如果进行Raft 共识的领导者为拜占庭节点,向分片中的跟随者发送错误的数据,将会导致此分片与系统中其他分片的数据不一致。为了预防“单片接管攻击(Single-shard takeover attack)”,监督节点将会参与片内共识,并在适当的时机触发Raft 算法的Leader election 协议,赋予了Raft 算法一定的拜占庭容错的能力。片内共识的详细过程如下:
1)领导者广播区块。
领导者将区块、领导者编号、消息签名等信息写入AppendEntries RPC 的entries 域中,向分片内所有节点广播。
2)监督节点收集区块。
与传统的Raft算法不同的是,分片内的跟随者收到领导者的同步请求后不会立即响应,而是将收到的消息发送给监督节点,等待监督节点的确认消息。监督节点收到领导者的数据后将会检查区块中的交易集是否一致,当在超时时间内收到超过3n/4(n为分片内节点数量)个交易集一致的区块并且与领导者发送的区块中的交易集一致,则进入监督节点验证环节,否则触发执行Leader election协议,并重新执行片内共识。
3)监督节点验证。
监督节点通过安全散列算法(Secure Hash Algorithm,SHA)[21]计算区块中交易集的信息摘要,向所有分片的监督节点广播验证消息,其 中CHECK 为验证消息标识,ci为监督节点编号,digi为当前区块的交易集信息摘要,timestampi为时间戳,termi为当前分片的领导者节点任期。
当前监督节点也会相应地收到来自其他监督节点的验证消息。监督节点将检查收到的验证消息的合法性,并判断其中的信息摘要与当前分片领导者广播的区块交易集的信息摘要是否相等。若相等,则说明这两个监督节点所管理分片的领导者下发了一致的数据,当前监督节点维护的有效验证消息数量加1;若监督节点在超时时间内收到超过K/2 个有效的验证消息,则向当前分片的所有跟随者发送确认消息,否则发送领导者重选消息;若监督节点发现此分片的领导者下发的数据与其他大多数分片的领导者不一致时,将向分片内的所有节点发送领导者重选消息。
4)区块提交。
若分片内的节点收到了监督节点的确认消息,则继续执行Raft 算法的余下流程,收到领导者的commit 消息时提交日志并将区块上链,否则将会执行Leader election 协议,并重新执行片内共识。片内共识流程如图4 所示。

图4 片内共识流程Fig.4 Flow of intra-shard consensus
2.3 K-RPBFT共识流程
客户端发送至主节点的若干交易被打包成一个区块,等待完成共识后上链。
定义分片数量为K=3f+1,PBFT 主节点编号为p,PBFT 从节点编号为i,当前视图编号为vId,请求编号为rId,客户端请求消息为msg,dig(msg)为请求消息msg的摘要,为节点p对msg进行数字签名,timestamp为时间戳,client为客户端编号,res为请求的执行结果。
K-RPBFT 算法的共识流程如下:
1)区块链分片。按照2.1 节中的分片策略将区块链分为K个片,开始等待共识。
2)客户端请求阶段。客户端发送msg到聚类中心节点的主节点(即PBFT 共识集群的主节点),开始进行片间共识。
3)PBFT 预准备阶段。PBFT 共识集群的主节点向PBFT从节点广播预准备消息
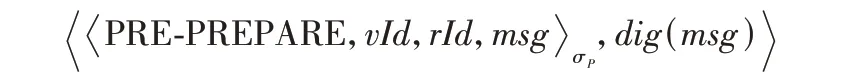
4)PBFT 准备阶段。PBFT 从节点会对收到的预准备消息进行检查,若预准备消息不合法则丢弃。通过检查后,从节点向其他 PBFT 共识节点广播准备消息,当节点收到至少2f个不同的PBFT 共识节点的准备消息,且通过合法性检查后,执行PBFT 确认阶段。
5)PBFT 确认阶段。当前节点向所有PBFT 共识节点广播确认消息,同时此节点将会收到其他节点的确认消息,检查消息签名、视图编号、消息序号合法并收到至少2f+1 个不同节点的有效确认消息时,片间共识完成,开始进行片内共识。
6)片内共识阶段。此时PBFT 共识节点将作为分片的领导者,执行基于Raft 算法改进的片内共识算法,片内的共识流程见2.2 节。跟随者完成共识后,向领导者反馈消息,当领导者收到超过一半的跟随者节点反馈后,确认片内达成共识,此领导者进入PBFT 提交阶段。
7)PBFT 提交阶段。当PBFT 节点所属的分片内部共识完成后,此节点向客户端发送回复消息
K-RPBFT 算法共识的完整流程如图5 所示。
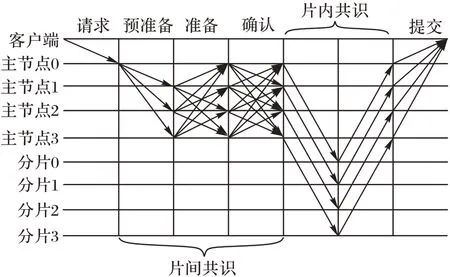
图5 K-RPBFT算法的共识流程Fig.5 Consensus flow of K-RPBFT algorithm
3 算法分析
K-RPBFT 算法作为一种面向联盟链的共识算法,需要在系统具有少量拜占庭节点的情况下工作。本章对算法的安全性、一致性、活性进行了分析,并对K-RPBFT 算法、PBFT 算法、Raft 算法的通信次数进行了分析与对比。K-RPBFT 算法一定程度上继承了PBFT 算法与Raft 算法的安全性、一致性与活性;同时,监督节点的引入进一步增强了K-RPBFT 算法的安全性与活性。
3.1 安全性
在片间共识中,PBFT 算法自身的三阶段提交过程保证了在拜占庭节点数量小于2/3 时的安全性。如果PBFT 从节点在共识过程中检测到主节点异常(不响应客户端请求、故意发送错误的请求)时,将会执行视图切换协议重新选择主节点。
在片内共识中,监督节点保证了Raft 算法在系统中含有拜占庭节点时的安全性。由于监督节点将会与其他分片的监督节点进行相互验证,如果分片的领导者向整个分片广播了错误的消息,监督节点将不会向分片中的跟随者发送确认消息,同时罢免当前领导者并触发Leader election 协议以确保链上信息的正确性;如果领导者向分片发起了一个并不存在的区块同步请求,监督节点在发出验证消息后,经过超时时间仍未收到足够的由其他监督节点发出的验证消息时,将重置超时时间并触发Leader election 协议重选领导者;如果Raft 主节点故意拦截区块同步请求,监督节点在陆续收到其他监督节点的验证消息时,会感知到主节点异常,进而触发Leader election 协议重新选举领导者。
这里对片内共识的拜占庭容错性进行讨论。设分片内的节点数量为n,拜占庭节点数量为f。拜占庭节点在收到领导者的消息m后,可能对其作出错误的共识(不处理m或将m替换为伪造消息m′),并且向监督节点发送含有正确消息m的区块以欺骗监督节点。因此监督节点收到的x个交易集一致的区块中可能含有f个拜占庭节点发送的区块,为了确保超过一半的诚实节点收到正确消息m,则x应满足:

由前文可知,x=3n/4,即:

因此,监督节点的存在能保证分片内拜占庭节点数量小于n/4 时共识的正常进行。
对于监督节点自身而言,由于不能动态加入区块链,且由上层监督者进行指定,因而只存在监督宕机的情况。分片内的从节点将与监督节点之间保持定期的心跳消息以确认监督节点存活,当超时无响应时会触发重分片,缩减分片数量以保证每个分片至少有一个可用的监督节点。同时,监督节点之间的通信以及监督节点与片内节点之间的通信均采用数字签名技术[22]以防止消息伪造。
3.2 一致性
根据CAP 定理[23],在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容忍性(Partition tolerance)最多只能同时满足其中两项。而为了保证系统的高可用,通常根据BASE(Basically Available,Soft state,Eventually consistent)即(基本可用、软状态、最终一致性)理论[24]来构建分布式系统。这里的一致性即指最终一致性而并非强一致性。
在片间共识中,PBFT 算法保证了在拜占庭节点数量小于节点总量1/3 时的一致性。在分片内部,Raft 算法的Log Replication 过程保证了片内共识的最终一致性,领导者将通过AppendEntries RPC 将日志同步到跟随者,并在收到大多数跟随者的反馈后提交日志。即使有部分节点宕机,在恢复后通过日志复制也能保证所有节点数据的最终一致性。
3.3 活性
PBFT 算法的view-change 协议提供了保证了K-RPBFT 片间共识的活性。当PBFT 主节点无法响应客户端请求时,会通过p=vIdmodK确定新的主节点编号以推动共识的继续进行,其中vId为当前视图编号,K为PBFT 共识节点数量。此外,进行PBFT共识的节点将同时作为片间Raft共识的领导者,而Raft跟随者会与领导者之间通过心跳消息保持联系,若超时未响应将触发Leader election 协议进行领导者重选,新的领导者将替换失效的领导者参加PBFT 共识,加快了PBFT 算法对失效节点的检测与替换,增强了PBFT 算法的活性。
Raft 算法的Leader election 协议保证了片内共识算法的活性,当跟随者超时仍未收到领导者的心跳消息时,将转变为候选者状态以进行新的领导者选举,新的领导者将替换原有已失效的领导者,保证共识的继续进行。
3.4 通信开销分析
本节对K-RPBFT 算法单次共识所需的通信次数与传统的PBFT 算法和Raft 算法进行对比。为便于分析,假设区块链的分片数量为K(K≥4),每个分片的节点数量为n(n≥3),可得系统中的总节点数:

1)PBFT 单次共识的通信次数。
若系统中的节点使用PBFT 算法进行一次共识,在预准备阶段主节点将向所有从节点发送预准备消息,此过程的通信次数为(N-1)。在准备阶段,每一个从节点将向其余节点发送准备消息,此过程的通信次数为(N-1)*(N-1);在确认阶段,所有节点将向其他节点发送确认消息,此过程的通信次数为N*(N-1);在回复阶段,参与共识的节点将向客户端发送回复消息,此过程的通信次数为N。因此可以得到PBFT 单次共识的通信次数:

2)Raft 单次共识的通信次数。
若系统中的节点使用Raft 算法进行一次共识,在Log Replication 阶段,领导者向所有跟随者发送包含一个区块的日志记录,此过程的通信次数为N-1。跟随者在收到领导者的日志记录后,向领导者发送回复消息,此过程的通信次数为N-1;领导者在收到超过一半的跟随者的回复消息后,向发送客户端回复消息,并向所有跟随者发送确认消息以将此区块提交上链,此过程的通信次数为N。因此可以得到Raft 单次共识的通信次数:

3)K-RPBFT 单次共识的通信次数。
若系统中的节点使用K-RPBFT 算法进行一次共识,在片间进行PBFT 共识的通信次数为2K2-K。对于单个分片内部,领导者首先向所有跟随者以及监督节点广播区块,此过程的通信次数为n;然后监督节点将收集所有跟随者的区块,此过程的通信次数为(n-1)。在监督节点验证阶段,监督节点将向其余分片的监督节点广播验证消息,此过程的通信次数为(K-1);在提交阶段,监督节点将向所有跟随者发送确认消息,然后跟随者向领导者发送消息,此过程的通信次数为2(n-1)。因此可以得到K-RPBFT 单次共识的通信次数:
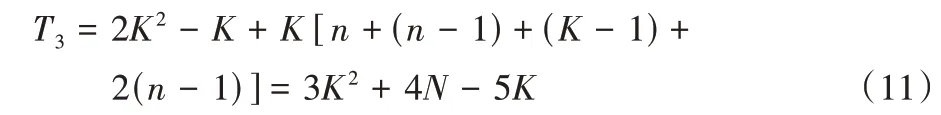
由分析可知,相较于PBFT 单次共识O(N2)的通信复杂度,K-RPBFT 的通信复杂度仅为O(N+K2)。图6 为不同节点数量下算法的单次共识通信次数对比。可以看出,随着节点数量的增加,PBFT 算法的单次共识通信次数将大幅增加,当节点数量为40 时,需要进行超过3 000 次通信才能达成共识。K-RPBFT 的单次共识通信次数与Raft 算法非常相近,远小于PBFT 算法且增长十分缓慢。

图6 通信次数对比Fig.6 Comparison of communication times
表1 为节点数量N为100 时K-RPBFT 的通信次数,当分片数量为4 时取得最小通信次数428,而此时PBFT 算法完成一次共识需要进行19 900 次通信。随着分片数量的增多,片间参与PBFT 共识的节点数量将会相应增多,导致K-RPBFT算法单次共识的通信次数上升,但仍远小于PBFT 算法。
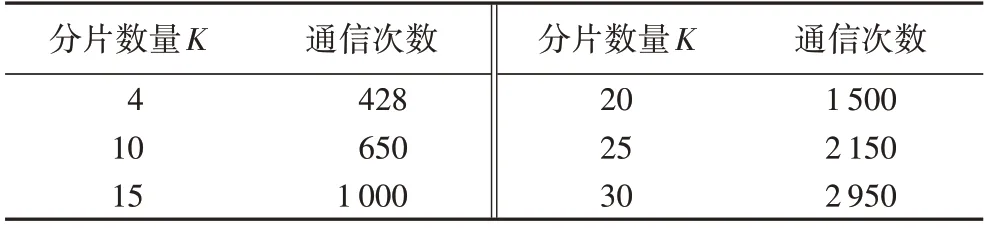
表1 节点数量为100时K-RPBFT算法的通信次数Tab.1 Communication times of K-RPBFT algorithm when the number of nodes is 100
因此,K-RPBFT 显著降低了单次共识的通信次数,当系统中具有100 个节点时,相较于PBFT 算法,K-RPBFT 能使通信次数降低两个数量级,且随着节点总量的增加,这种优势将更加明显。
4 仿真实验
为了验证K-RPBFT 算法的有效性,本文使用Netty 4.1.42 作为网络通信组件,Java 作为编程语言实现了本算法,通过在同一设备上监听多个不同的TCP 端口模拟多节点环境。本章从共识时延、吞吐量等方面与PBFT 算法、Raft 算法进行了比较。此外,由于RapidChain 共识算法在性能和安全性上已经达到了较好的效果,因此本章对K-RPBFT 与Rapidchain 进行了对比。
4.1 共识时延测试
共识时延是衡量算法性能的重要指标,指客户端发起请求到区块被确认上链所需的时间。在实验中K-RPBFT 共识时延的计算公式为:
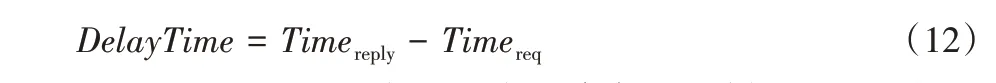
式中:Timereq表示客户端发起共识请求的时刻,Timereply表示客户端收到足够的PBFT 回复消息的时刻。
取多次实验数据的平均值作为共识时延,并与PBFT 算法、Raft 算法进行对比。算法的共识时延对比测试结果如图7 所示。由图7 可知,三种算法的共识时延随着节点数量的增加均逐渐增大,但K-RPBFT 与Raft 的时延增加较为缓慢,PBFT 的时延增加较为剧烈。K-PBFT 算法的共识时延与Raft相近,当节点数量为12 时,PBFT 的共识时延约为K-RPBFT的2.5 倍,而当节点数量增加到40 时,PBFT 的共识时延超过了K-RPBFT 的4.5 倍。因此K-RPBFT 算法在大规模节点的环境下能显著降低共识时延。

图7 共识时延对比Fig.7 Comparison of consensus latency
4.2 吞吐量测试
吞吐量指系统在单位时间内处理的事务数量,在区块链领域中通常用每秒完成的交易数量(Transactions Per Second,TPS)来计算,即:

其中:Δt为出块时间,TransactionΔt为出块时间内处理的交易总量。吞吐量不仅与节点数量有关,还与区块中包含的交易数量有关,因此进行两组不同的实验对算法的吞吐量进行验证。
实验一 将每个区块中包含的交易数量固定为1 000,将系统中参加共识的节点设置为12~36,取多次实验数据的平均值作为吞吐量实验结果,并与PBFT 算法、Raft 算法进行对比,实验结果如图8 所示。由图8 可以看出,算法的吞吐量均随着节点数量的增加而呈下降趋势,但K-RPBFT 算法的吞吐量仍然远高于PBFT 算法,且与Raft 算法相近。

图8 不同节点数量下的吞吐量对比Fig.8 Comparison of throughput under different node numbers
实验二 将系统中参加共识的节点固定为12 个,将每个区块中包含的交易数量设置为1 000~4 000,取多次实验数据的平均值作为吞吐量实验结果,并与PBFT 算法、Raft 算法进行对比,实验结果如图9 所示。由图9 可以看出,K-RPBFT算法的吞吐量与Raft 算法较为接近。当区块中的交易数量没有超过节点的处理能力时,各算法的吞吐量均随着交易量的增加而提升。交易数量为1 000,K-RPBFT 算法相较于PBFT 算法能够提升700 左右的吞吐量,且随着交易数量的增加,吞吐量的提升更加明显。吞吐量的最大值在交易量为3 000 左右时取得,此时K-RPBFT 的吞吐量约为PBFT 的3.5倍。受限于实验设备的处理能力,当区块中的交易数量超过3 000 时,此时继续向区块中增加交易将会使算法的吞吐量均有所下降,但K-RPBFT 算法的吞吐量仍然高于PBFT算法。
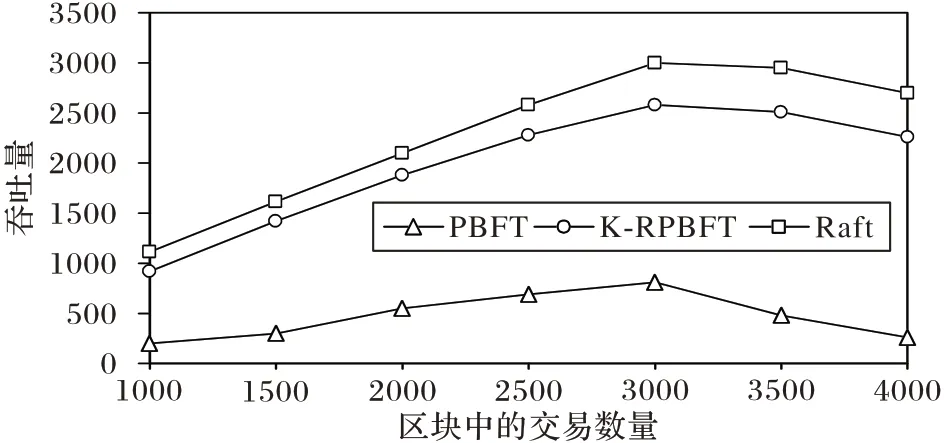
图9 不同交易数量下的吞吐量对比Fig.9 Comparison of throughput under different transaction numbers
因此,K-RPBFT 算法拥有比PBFT 更大的吞吐量,能够在单位时间内处理更多的事务,适用于对吞吐量要求较高的联盟链环境。
4.3 K-RPBFT与RapidChain的对比
RapidChain 是 由Zamani 等[17]于2018 年提出的共识算法,对比的数据来自于文献[17]中所给出的实验数据。
两种算法的吞吐量与共识时延对比结果如图10 所示。在吞吐量方面,K-RPBFT 的吞吐量整体上大于RapidChain 的吞吐量,两者吞吐量差值的最大值在区块大小为512 KB 时取得,此时RapidChain 的吞吐量仅为K-RPBFT 的70%,随着区块的增大,两者的差距有所减小,但K-RPBFT 的吞吐量仍大于RapidChain 的吞吐量;在共识时延方面,K-RPBFT 的共识时延整体上小于RapidChain 的共识时延,RapidChain 的共识时延是K-RPBFT 的1.4~1.7 倍。

图10 两种算法的吞吐量与共识时延对比Fig.10 Comparison of throughput and consensus latency between two algorithms
在容错性方面,由于RapidChain 的委员会内部共识本质上还是基于PBFT 算法,因此RapidChain 的容错率为N/3(N为参与共识的节点数量),与PBFT 算法的容错率一致。由于K-RPBFT 算法在片内共识引入了Raft 算法,尽管对Raft 算法的共识过程进行了改进,但K-RPBFT 算法的容错性仍然小于PBFT 算法。通过第3 章的算法分析可知,K-RPBFT 的片内容错率为n/4(n为片内节点数量)。因此,K-RPBFT 算法的容错性弱于RapidChain 算法。
通过以上分析可以发现,K-RPBFT 算法首先通过K-medoids 算法将区块链分片,并且在片内共识中引入基于监督节点改进的Raft 算法,使K-RPBFT 算法在性能方面优于RapidChain 算法,但是安全性低于RapidChain 算法。
5 结语
本文提出了一种基于PBFT 与Raft 算法改进的共识算法模型K-RPBFT,该算法较好地结合了PBFT 算法支持拜占庭容错与Raft 算法共识效率较高的特性,并使用K-medoids 算法将全局共识改进为多中心化的两层共识。实验结果表明,K-RPBFT 算法的单次共识通信次数与共识时延均小于PBFT算法,且具有更高的吞吐量,更适用于拥有大规模网络节点的区块链环境,能够有效解决现有联盟链共识算法可扩展性不足的问题。
目前K-RPBFT 算法仍处于实验阶段,未来将进一步完善算法细节与性能,并将该算法应用到某一具体的区块链系统中,同时也会考虑将多中心两层次的K-RPBFT 算法衍进为多中心多层次化的结构,进一步提升在大规模节点下区块链的共识效率,以推动区块链技术的不断发展。
