一种基于邻域信息的多信道自适应建网算法
2022-12-26赵海涛刘松旺魏急波
刘 琰 赵海涛 李 卫 张 姣 刘松旺 魏急波
(1.国防科技大学电子科学学院,湖南长沙 410073;2.中国人民解放军31401部队,黑龙江哈尔滨 150090;3.中国人民解放军75835部队,广东广州 510000)
1 引言
无线自组网(Wireless Ad Hoc Networks)凭借无中心节点、自组织且不需要任何基础通信设备支持的特点,使其具有较强的灵活性、抗毁性以及可扩展的能力,可以运用于紧急救援、环境监测、战场通信等领域[1-3]。在许多无线自组网的应用场景,比如无线传感器网络、物联网等系统中,为提高网络构建的鲁棒性和带宽利用率,网络中的频谱资源通常是多信道的。但是在频谱竞争激烈或者存在恶意干扰的情况下,各节点的实际可用信道并不相同,具有非均匀的信道可用性。这种非均匀的信道可用性严重影响了自组网的建网过程。对于无线自组网来说,依靠可用网络资源构建稳健、连通的网络是一个非常重要的过程,是拓扑管理、路由寻址、性能优化等一切后续行为的基础。
无线自组网的建网过程通常可以分为两个阶段:邻居发现阶段和网络形成阶段。节点在邻居发现前不知道其他节点是否存在以及可接入哪些信道。传统的邻居发现机制依靠一个网络中所有用户都可以使用的公共控制信道[4],它便于协调相邻节点之间交换感知信息(如信道和路由信息),以建立相邻节点间的通信链路。许多研究假设网络中始终存在预先分配的公共控制信道[5-6],但是在实际的复杂频谱环境中,找到对全网节点都可用的公共控制信道频段是非常困难的。文献[7]提出利用多跳聚类的方法进行公共控制信道的最优分配,文献[8]提出使用全双工设备建立公共控制信道,但是这两种算法只能建立部分节点共用的公共控制信道,需要多条公共控制信道才能控制整个网络。值得注意的是,公共控制信道很容易成为被干扰和攻击的对象,公共控制信道一旦被干扰将造成网络的瘫痪。针对没有公共控制信道的邻居发现问题,目前主要利用基于信道跳变的盲交汇算法解决[9-11],节点根据自己的信道跳变序列在不同的时隙切换到不同的信道,一旦两个节点在同一时隙切换到同一可用信道,它们就可以交换信息。文献[12]通过分析时隙重叠和信道确定性,提出一种多素数扩展的盲交汇算法,用于提高节点之间交汇的速度和稳定性。文献[13]提出了一种多无线电的盲交汇算法,给节点统一分配不同的跳变序列,有效减少了节点的交汇时间。文献[14]的盲交汇算法能够应用两种信道跳变序列,成功缩小了信道跳变序列的渐近逼近比。现有的盲交汇算法虽然在两个或多个节点的交汇问题上取得了不错的效果,但是不考虑整个网络的形成,如果单纯使用信道跳变算法进行建网,所有节点在多个信道之间频繁地进行信道感知、接入与建链,尤其是网络规模较大时,将造成严重的竞争冲突,大大延长建网时间。
网络的形成阶段主要关注网络结构的选择。无线自组网的网络结构可以分为平面结构和分簇结构,在分簇结构中,网络节点组织成若干个称为簇的逻辑集群,每个簇群中的节点具有不同的身份,如簇首、网关节点或普通簇成员。与平面结构相比,分簇结构能够减轻网络局部的拓扑结构变化对整个网络的影响,比较适用于需要动态变化的无线自组网[15]。近年来,国内外学者从不同的应用需求出发对分簇算法进行设计[16-18]。文献[19]提出了基于距离能量评估的分簇算法,该算法能够有效提高无线传感器网络的网络寿命,但是没有考虑节点的最大通信距离的限制,无法应用在部署范围较大的实际通信场景中。文献[20]利用灰狼优化算法进行网络的分簇,考虑吞吐量、延迟和通信开销等因素,以保证网络的服务质量,但是算法需要掌握网络的全局信息,在没有中心控制器的自组网中无法保证全局信息的有效获取。文献[21]通过对无人机的轨迹和分簇进行研究,提高了网络的抗干扰能力,然而算法针对的是单信道网络,不适用于存在非均匀信道可用性的多信道网络。综上所述,在每个节点无法感知全网拓扑、其他所有节点的可用频谱,以及无法获得同步信息的实际场景中,无线自组网的建网问题没有很好的解决办法。
本文主要针对实际场景中多信道自组网的建网问题进行研究,既不是节能部署问题[22-23],也不是拓扑维护问题[24-25]。本文研究的重点是在实际应用场景的限定条件下,节点以较小的通信开销建立完整的多信道网络,提出了一种多信道自适应建网算法(Multi-channel Adaptive Network Establishment,MANE)。设计了一个基于邻域信息的建网策略,并且针对建网过程中节点对信道和簇首选择问题,分别提出了信道质量评价算法和邻居簇首评价算法。仿真结果表明,所提算法能够利用有限的邻域信息建立分簇结构的网络。
2 系统模型
假设在一个部署范围内,存在N(N≥3)个节点,且节点被编号为1,2,…,N,用U={U1,U2,…,UN}表示。将网络中的频谱划分为M(M≥2)个非重叠的信道,总信道用C={C1,C2,…,CM}表示。考虑到非均匀的信道可用性,定义节点Ui∈U感知到的可用信道集合为CUi∈C。关于节点通信功能的假设是:
(1)每个节点都具备一个半双工的收发器,可以实现频谱感知,发现其可用信道并自由切换到任意一个信道进行数据通信;
(2)如果一个节点位于另一个节点的通信范围内,则两个节点可以在相同的可用信道上通信;
(3)所有节点可以获取自身的地理位置信息(利用北斗卫星导航系统或者全球定位系统获取)。
考虑在节点启动或网络遭受攻击等实际应用场景中,网络中没有中心控制器的协调和可用的公共控制信道,所有节点无法感知全局信息,且无法与其他节点保持精确的时间同步,无线自组网构建困难。针对以上问题,本文设计了多信道自适应建网方法,网络中的每个节点可以在任何时隙激活,然后开始进行自适应建网,最终建立一个分簇结构的网络。典型的分簇结构网络如图1 所示,其中簇首负责维持簇群,网关节点负责连接两个相邻的簇群,同一簇群内的节点使用一条主用信道进行通信。

图1 典型的分簇结构网络Fig.1 A typical clustered network
3 多信道自适应建网算法
3.1 基本思路
本文所提多信道自适应建网算法(MANE)的建网策略将邻居发现阶段和网络形成阶段融合在一起,使节点能够以自身信息为基础,通过可用信道情况、邻居簇首情况等有限的邻域信息确定自身身份(簇首、网关节点或普通簇成员),从而完成自适应建网,具体的建网策略如图2 所示。当一个节点上电激活后将进行以下步骤:
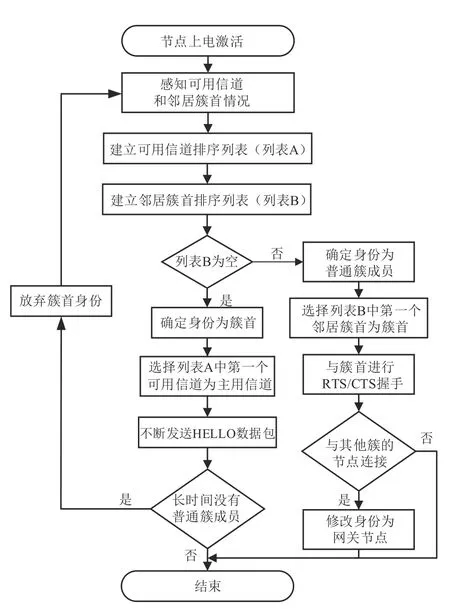
图2 建网策略流程图Fig.2 Flow chart of network establishment strategy
步骤1节点对其可用信道情况和邻居簇首情况进行感知。节点依次在其可用信道上进行切换,在每个可用信道上停留一段时间,检测信道参数并接收邻居簇首发出的HELLO数据包,完成一次所有信道切换的时间为一个搜索周期。信道参数是指带宽、信干噪比、相干带宽、相干时间等。HELLO 数据包中含有节点ID、可用信道、簇规模、地理位置等信息。
步骤2建立可用信道排序列表和邻居簇首排序列表。节点使用信道质量评价算法得到可用信道排序列表(设为列表A),使用邻居簇首评价算法得到邻居簇首排序列表(设为列表B)。两种评价算法将分别在第3.2节、第3.3节进行讨论。
步骤3确定节点身份。情况1:如果节点的邻居簇首排序列表为空,则节点确定其身份为簇首,选择节点的可用信道排序列表中第一个可用信道作为簇内主用信道,并在该信道上发送HELLO数据包。情况2:如果邻居簇首排序列表不为空,则节点确定身份为普通簇成员,选择邻居簇首排序列表中第一个邻居簇首作为其簇首,然后以RTS/CTS 握手的方式与簇首建立连接。
步骤4如果节点身份为普通簇成员,并且能够与另一个簇的任何节点建立连接,则节点修改其身份为网关节点。
步骤5如果节点身份为簇首,但是长时间没有任何普通簇成员,则放弃其簇首身份,返回步骤1。
节点根据感知到的HELLO 数据包判断周围是否存在邻居簇首,从而确定其身份。这种方式不依靠邻居节点之间频繁的信息交互,能够减少建网开销和建网时间,但具有一定的随机性。为了保证构成网络的性能,需要重视两个关键问题。一是簇首需要选择一个最合适的可用信道作为主用信道。同一簇内的节点依靠主用信道进行通信,因此需要对节点可用信道的信道质量进行评价,将评价结果作为簇首选择主用信道的依据;二是普通簇成员需要选择一个最合适的邻居簇首作为其簇首。邻居簇首在各自的主用信道上发送HELLO 数据包来等待普通簇成员的加入,导致普通簇成员周围可能存在多个邻居簇首,因此需要一个能够综合评价邻居簇首的算法,指导普通簇成员对于簇首的选择。目前已有的一些关于信道质量评价[26]和簇首质量评价[27]的研究,都只是单独考虑信道质量或者簇首质量,并没有自组网节点快速建网的需求。因此本文结合建网过程,根据感知到的邻域信息,提出了信道质量评价算法和邻居簇首评价算法。
3.2 信道质量评价算法
首先利用节点可用信道的信道参数构成线性加权的信道质量评价函数,其中各信道参数的权重值还未确定。然后根据最大熵原理[28]建立多目标规划模型,解出权重的表达式。最后根据实际网络需求设定主观约束条件,得到满足主观约束条件的权重值,进而求出节点可用信道的信道质量评价函数值。
设节点Up感知到其可用信道总数为n个,记为CUp={CUp(1),CUp(2),…,CUp(n)},CUp(i) 表示节点Up的第i个可用信道。可用信道的信道参数有m个,记为G={G1,G2,…,Gm}。CUp(i)的第j个信道参数Gj的值记为eij(i=1,2,…,n;j=1,2,…,m)。
节点Up感知到的n个可用信道共有n×m个信道参数值,构成评价矩阵E,即

为通过公式(2)对信道参数进行归一化处理,得到归一化评价矩阵F,即


设m个信道参数的权重值为wj,节点Up对其可用信道CUp(i)的线性加权的信道质量评价函数为:
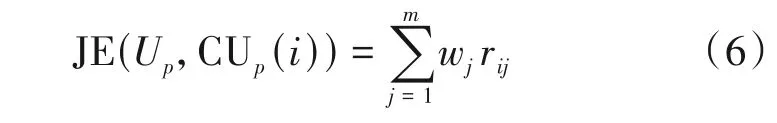
由于各指标的权重是具有不确定性的随机变量,可以利用最大熵原理保证各信道参数权重的公平性。同时,当满足各信道参数值与信道参数平均值的加权方差最小时,所求的权重才最合理。建立目标规划函数为:
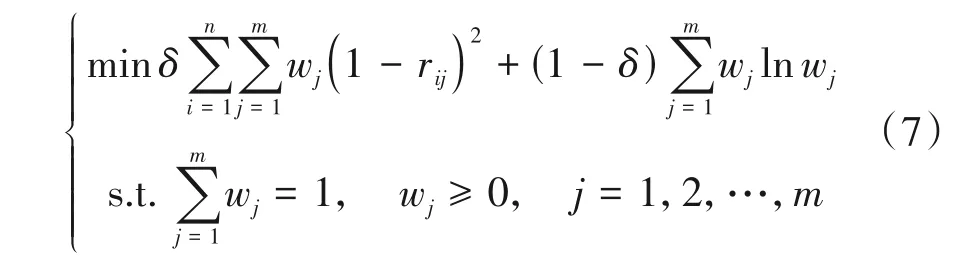
其中参数δ∈[0,1],求解目标规划函数得到权重wj:
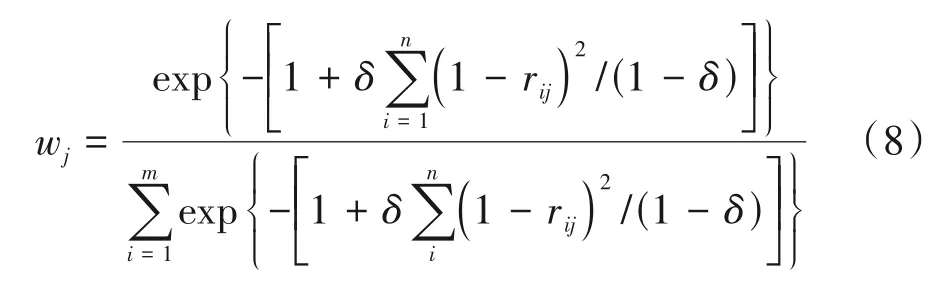
需要说明的是,公式(8)在求解权重wj时,需要根据实际情况确定参数δ。例如:在实际应用中将带宽、信干噪比作为最重要的指标,相干带宽、相干时间作为次要指标,则可以增加主观约束条件为w1≈w2>w3≈w4。通过改变参数δ的值,获取满足主观约束条件的权值解w1、w2、w3、w4。将权重解代入公式(6)即可求出节点Up可用信道的质量评价函数值JE(Up,CUp(i))。根据JE(Up,CUp(i))的大小即可实现对可用信道的信道质量从高至低排序,得到节点Up的可用信道排序列表。
3.3 邻居簇首评价算法
生物实验展示多头绒泡菌在觅食过程中能够自主寻找到迷宫的最短路径,形成的觅食网络可以和人工设计的铁道网络相媲美,说明多头绒泡菌具有良好的自组织、自优化等智能行为[29]。多头绒泡菌的菌丝可以抽象为有液体流动的导管,利用导管的半径和导管内部流体之间的反馈模拟多头绒泡菌的觅食行为,即流体通量高时导管半径增加,流体通量低时导管半径减小[30]。流体通量表示为:
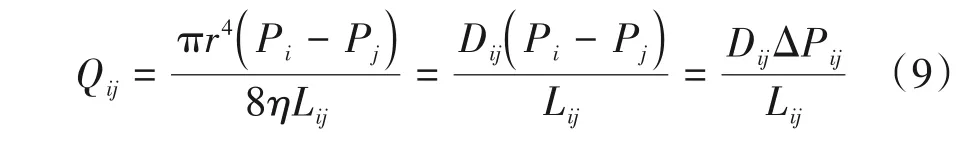
其中,Qij是通过i、j两点之间导管的流体通量,Dij=是导管传输率,r是导管的半径;η是导管内流体的黏度。ΔPij=Pi-Pj是导管两端点的压力差,Lij是导管的长度。
由于多头绒泡菌通过扩张和收缩导管来寻找食物,其调节函数表示为为导管的衰减率。f(Q)=Qu(u>0)为常用函数形式,可以得到调节函数:
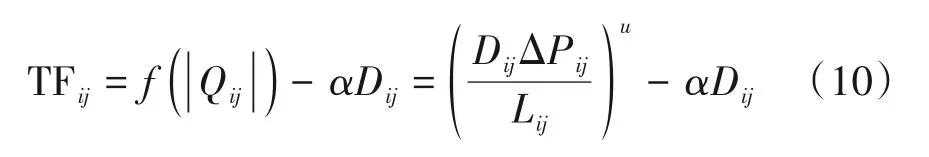
本文将多头绒泡菌模型引入到节点对于邻居簇首评价中,建立了邻居簇首评价映射模型,如图3所示。将多头绒泡菌的菌群映射为节点,食物映射为邻居簇首,菌群觅食过程中发散的导管映射为节点与多个邻居簇首之间的虚拟连接。

图3 邻居簇首评价映射模型Fig.3 Neighbor cluster head evaluation mapping model
导管的两个端点i、j映射为节点Ui和一个邻居簇首Uj。采用无量纲分析法进行变量的替换,首先,Dij是导管传输率,是由导管半径和流体黏度决定的固有属性,因此用公式(6)中的信道质量评价函数值代替Dij,其中为邻居簇首Uj的主用信道;其次,Lij表示管状体的长度,其数值越大越不利,在无线自组网中,两个节点的距离越大越不利,因此用两个节点间的距离代替导管长度Lij;ΔPij表示导管两端流体的压力,是判断连接两点的导管是否存在的关键,其数值越大越有利。在分簇结构的网络中,节点连接簇规模大的簇首,有利于减少簇间信道协商的信令开销,同时节点连接与其相同可用信道数量多的簇首,有利于连接稳定。公式(10)可以转化为公式(11):
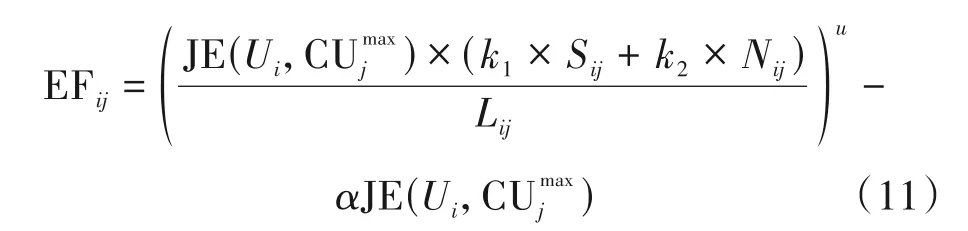
其中,EFij是节点Ui对于邻居簇首Uj的评价函数值。是节点Ui对于邻居簇首Uj的主用信道的信道质量评价函数值,由可用信道排序列表给出。Sij表示邻居簇首Uj的簇规模的归一化值。Nij是节点Ui与邻居簇首Uj的相同可用信道数量的归一化值。k1、k2为权重系数,满足k1+k2=1。将节点Ui的邻居簇首按照评价函数值EFij的大小进行排序,得到节点Ui的邻居簇首排序列表。
4 仿真分析
4.1 仿真参数设置
利用MATLAB仿真软件对所提MANE算法的性能进行实验评估。网络部署范围是1000 m×1000 m的矩形区域,将网络的初始状态设置为节点相互之间完全失联。各节点的最大通信距离均为300 m,其可用信道是从总信道中随机选取的部分信道。RTS/CTS握手机制和信道情况的参数设置如表1所示,其中退避时隙时长、短帧间隔和分布式帧间隔按照802.11 协议的标准进行设置[31],信噪比、带宽、相干带宽、相干时间的范围依据相关文献设计[32-33]。
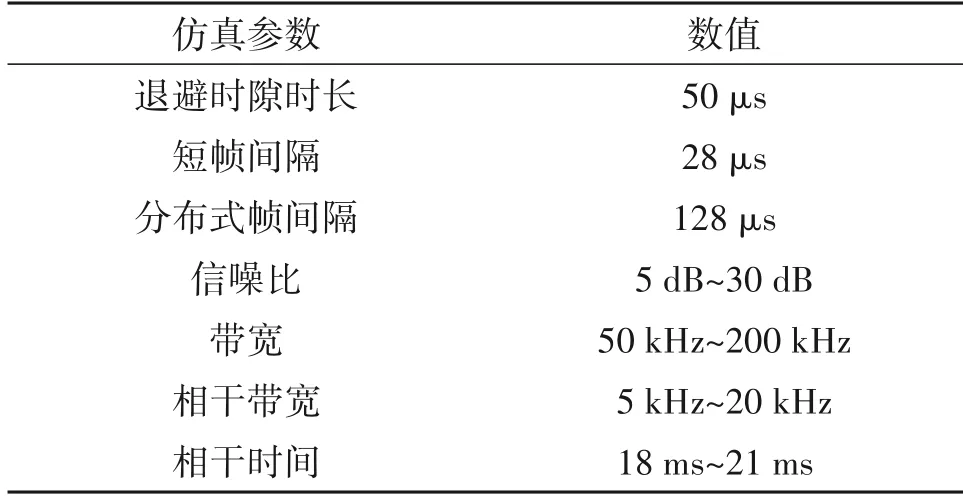
表1 主要的仿真参数和数值Tab.1 Main simulation parameters and values
4.2 仿真场景示例
为便于直观展示仿真结果,示例中设置20个节点与6 个总信道,图4 给出了在节点随机部署情况下MANE 的建网过程,图中节点编号用数字1 至20表示,节点下方的括号内标有其可用信道的编号,簇内连接和簇间连接分别用实线和虚线表示,连线的权值表示节点之间连接所使用的信道编号。图4(a)是节点完全失联的初始状态,各节点的可用信道随机。图4(b)至图4(e)是节点正在建网的中间状态,图4(f)是节点完成建网的最终状态。由图4 可以看出,节点利用感知到的邻域信息,自适应判断自身角色,选择可用信道和邻居簇首,逐步建成了图4(f)所示的6个簇群(如节点13为簇首,节点9为普通簇成员,节点4、节点8 和节点11 为网关节点)。为显示MANE 算法的适用性,图5 给出了算法在“均匀部署”、“带状部署”和“随机部署”三种典型部署情况下的最终建网结果,可以看到MANE 都能完成快速建网任务。

图4 MANE的建网过程Fig.4 Network establishment process of MANE
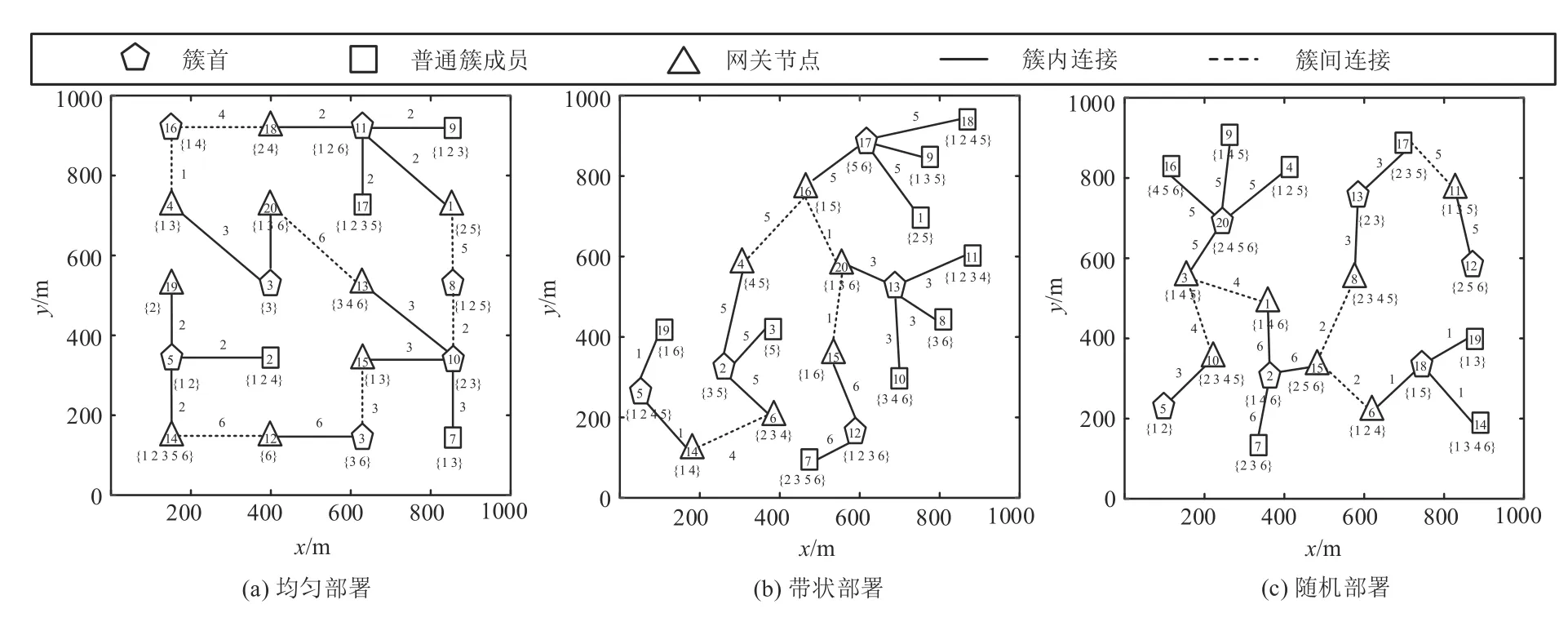
图5 不同情况下的建网结果Fig.5 Network construction results in different situations
4.3 系统性能分析
为了有效评价本文所构建的无线自组网的系统性能,分别采用平均信息交互次数、平均簇内公共信道数量以及平均簇规模作为主要评估指标。
(1)平均信息交互次数是在建网过程中节点之间信息交互的平均次数,平均信息交互次数越小,代表建网开销越小、建网时间越短。
(2)平均簇内公共信道数量是各簇群中所有节点的相同可用信道数量的均值,平均簇内公共信道数量越大,代表网络拓扑结构越稳定。
(3)簇规模指的是一个簇群所包含的节点数量,平均簇规模是整个部署范围内各簇群规模的均值[34-35]。需要注意的是,本文研究的场景中每个簇群都是由簇首及其一跳范围内的节点构成的,只有在簇首最大通信距离内的节点才有可能入簇,不考虑利用网关节点和普通簇成员不断扩大簇规模,并且各节点的实际可用信道并不相同,因此簇规模一般是比较有限的。虽然网络的部署范围和节点的通信距离不可避免地会对平均簇规模造成影响,部署范围越大、通信距离越小,平均簇规模就越小,但是在部署范围和通信距离确定的情况下,总是希望平均簇规模尽量大。平均簇规模能够一定程度上代表网络拓扑结构的高效性,因为平均簇规模过小,将导致大量开销用于簇间通信,严重影响网络传输性能。
4.3.1 评价算法对MANE性能的影响
MANE利用信道质量评价算法和邻居簇首评价算法指导节点进行信道和簇首的选择。为方便研究两种评价算法对MANE 性能的影响,将使用建网策略但不使用两种评价算法的MANE 命名为LMANE。具体来说,L-MANE 不使用评价算法,其可用信道排序列表和邻居簇首排序列表是不依据评价函数值的随机排序。由于使用评价算法不增加建网开销,所以重点研究评价算法在平均簇内公共信道数量和平均簇规模方面对MANE性能的影响。
(1)评价算法对平均簇内公共信道数量的影响。
图6(a)显示,对于MANE 和L-MANE,当总信道数量M一定时,平均簇内公共信道数量随着节点数量的增加而减少。当节点数量一定时,平均簇内公共信道数量随着总信道数量的增加而增加。在相同的条件下,MANE 的平均簇内公共信道数量高于L-MANE。图6(b)显示,相较于L-MANE,使用了评价算法的MANE 在平均簇内公共信道数量上增加了18.20 %。由此可见,评价算法能够明显增加平均簇内公共信道数量,提高网络拓扑结构的稳定性。
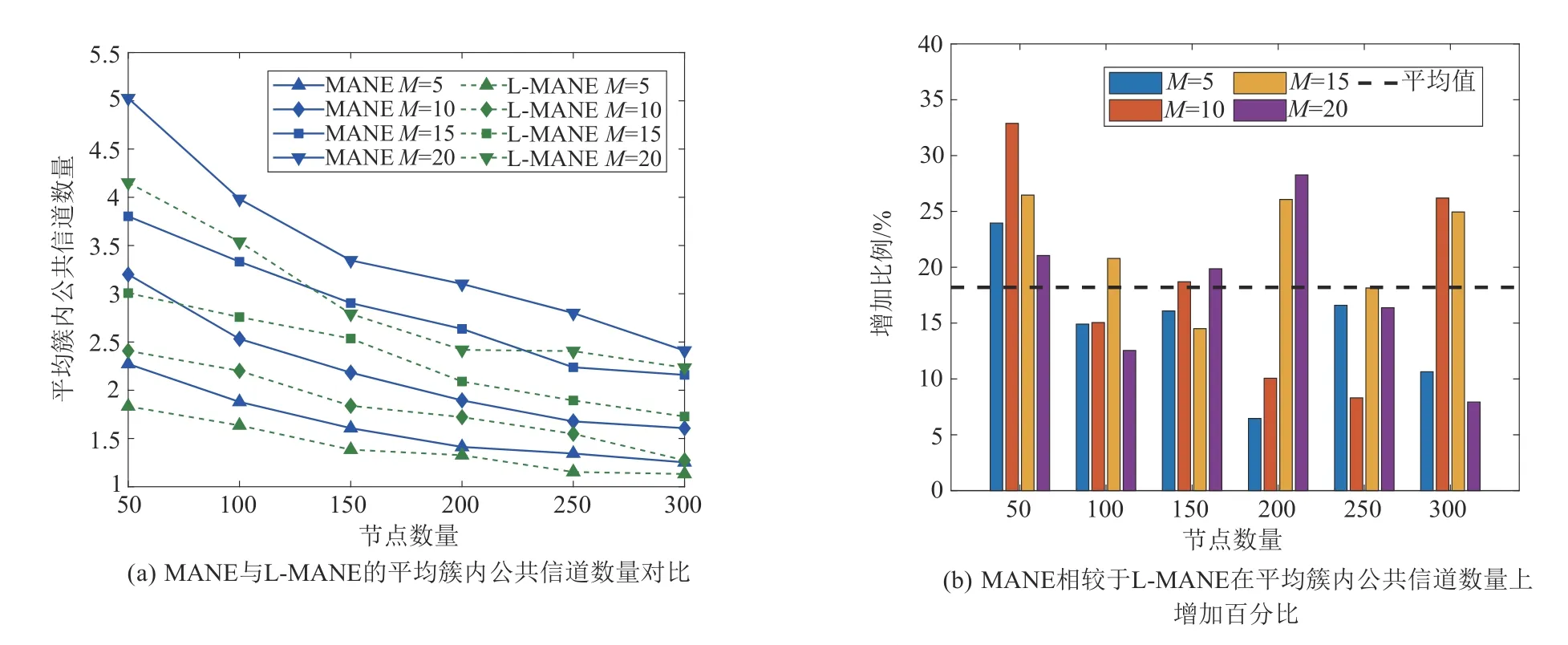
图6 评价算法对平均簇内公共信道数量的影响Fig.6 The effect of evaluation algorithms on the average number of common channels within the cluster
(2)评价算法对平均簇规模的影响。
图7(a)显示,随着节点数量的增加,MANE 和L-MANE 的平均簇规模会随之增加,但是MANE 的平均簇规模明显高于L-MANE。图7(b)显示,使用了评价算法的MANE在相对于L-MANE的平均簇规模增加了77.28 %。由此可见,评价算法能够明显增加平均簇规模,使网络拓扑结构更加高效。
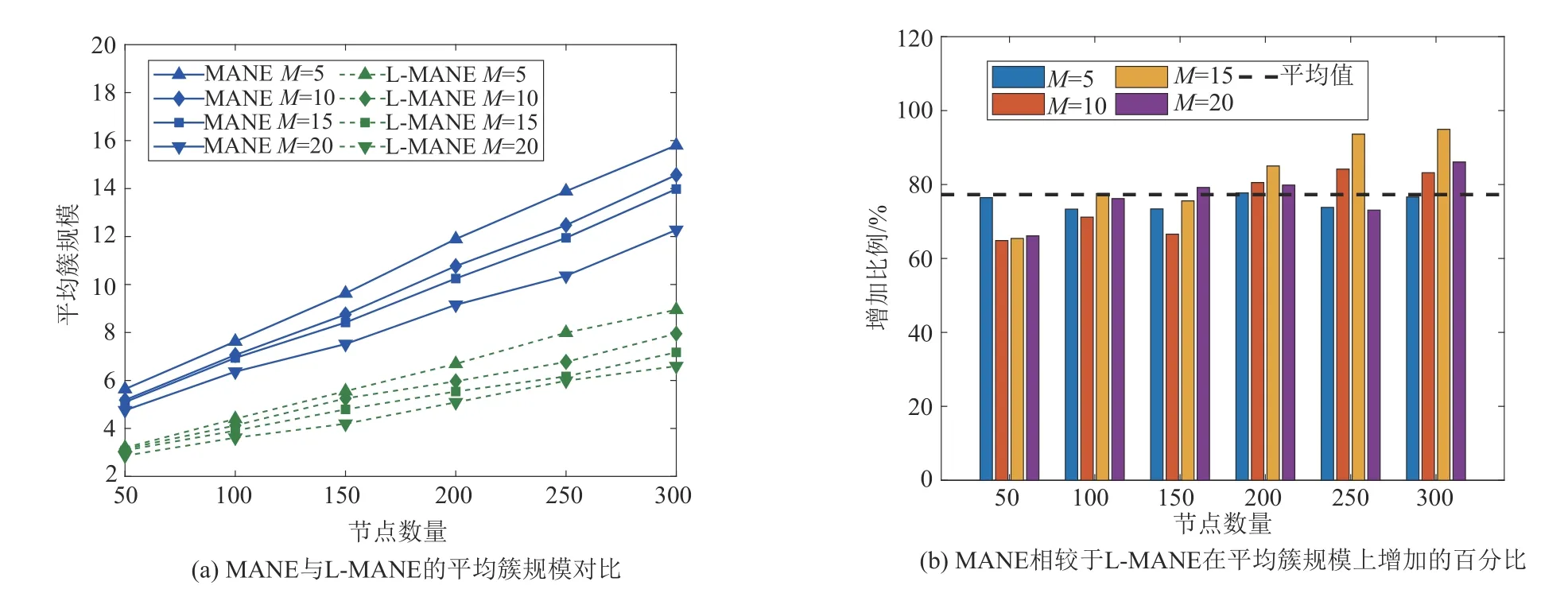
图7 评价算法对平均簇规模的影响Fig.7 The effect of evaluation algorithms on the average cluster size
4.3.2 搜索周期对整体网络性能的影响
为验证搜索周期对整体网络性能的影响,本文在不同信道停留时间下进行建网实验,并且采用多独立样本Kruskal-Wallis 秩和检验分析网络性能之间是否存在显著性差异[36]。首先随机生成100种初始部署,分别设置信道停留时间为1 s、2 s、3 s、4 s,通过MANE 进行建网,得到A、B、C、D 共4 组建网结果。然后,针对每组的100个建网结果,分别计算平均簇内公共信道数量和平均簇规模的指标值。最后,对各组的指标值进行秩和检验,得到渐进显著性p值。秩和检验的原假设H0是建网结果的指标值不存在显著性差异,在显著性水平为0.05 情况下,当p<0.05 时拒绝H0,说明建网结果的指标值存在显著性差异,当p>0.05 时接受H0,说明建网结果的指标值不存在显著性差异。实验过程的示意图如图8所示,通过改变节点数量和总信道数量,能够进行不同初始部署条件下的实验。
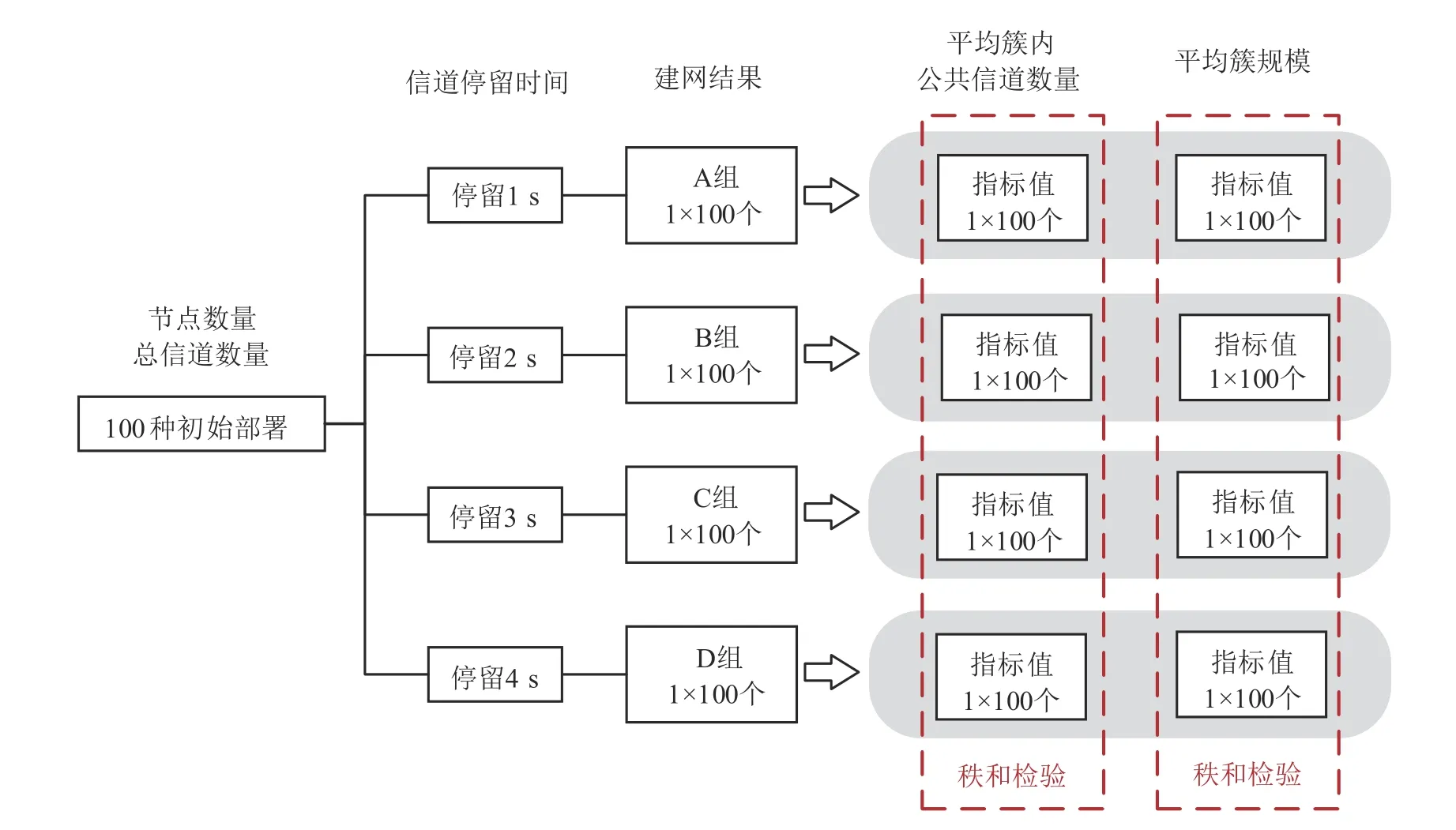
图8 实验过程示意图Fig.8 Schematic diagram of the experimental process
表2 给出了秩和检验的具体结果,在相同的初始部署下,不同信道停留时间的建网结果在两个评估指标上的p值均大于0.05,说明各建网结果的性能指标值不存在显著性差异。从统计的角度分析,搜索周期对整体网络性能的影响是可控的。
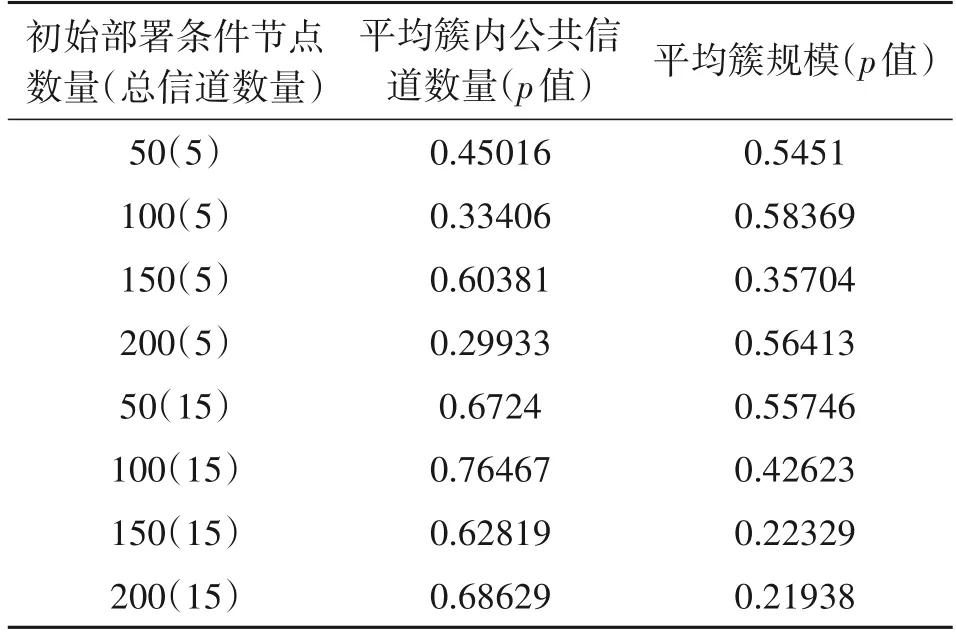
表2 秩和检验结果Tab.2 The result of the rank sum test
4.3.3 MANE与其他算法的性能比较
本文考虑的是每个节点无法感知全网拓扑、其他所有节点的频谱,以及无法获得同步信息的实际场景,但是集中控制算法、信道跳变算法和分簇算法等现有的研究,不能完全满足上述条件的限制。为了衡量本文所提MANE 算法的性能,对两种现有算法进行了改进。第一种是最小ID 算法(Lowest ID),在该算法中ID 最低的节点优先成为簇首。第二种是最大节点度算法(Max Degree),在该算法中节点度(邻居节点数量)最大的节点优先成为簇首。考虑实际场景的限制,设置两种算法的邻居节点通过收发数据包交互信息。
图9给出了平均信息交互次数对比情况。尽管三种算法在节点数量较少时的平均信息交互次数差距并不明显,但随着节点数量的增加,MANE的平均信息交互次数增加的速度比较缓慢,但其他两种算法的平均信息交互次数有明显的增加。在总信道数量M相同的情况下,不论节点数量如何变化,MANE一直保持着最低的平均信息交互次数。这主要是因为Lowest ID 和Max Degree 为了掌握全网信息需要节点之间进行全面的信息交互,节点数量增加,需要信息交互的次数相应越多,导致通信冲突越严重,信息重传次数越多。MANE 的建网策略中节点通过判断是否存在邻居簇首来确定身份,不需要掌握全网信息,所以信息交互次数少,受节点数量的影响更小。
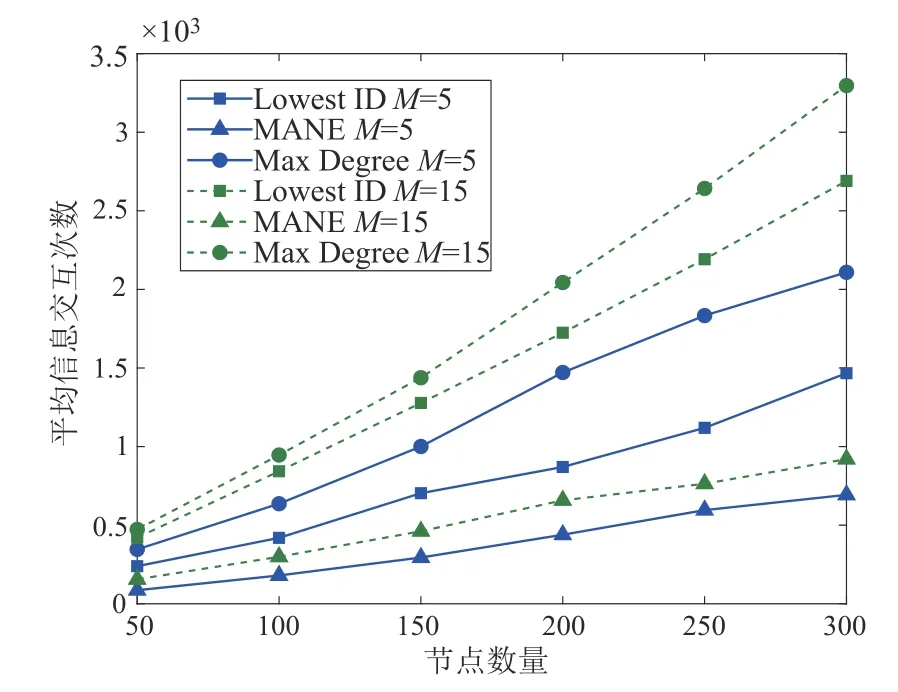
图9 平均信息交互次数对比Fig.9 Average number of information interactions
图10给出了平均簇内公共信道数量对比情况。Max Degree在建网过程中没有考虑公共信道这个因素,Lowest ID的性能完全取决于具有最小ID的节点所在位置,两种算法的平均簇内公共信道数量并不具备优越性。MANE 的平均簇内公共信道数量最多,因为邻居簇首排序时考虑了节点与邻居簇首之间的相同可用信道数量。
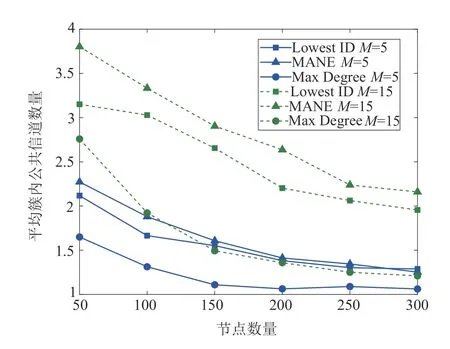
图10 平均簇内公共信道数量对比Fig.10 Average number of common channels within the cluster
图11给出了平均簇规模对比情况。图11(a)显示,当部署范围的边长固定设置为1000 m 时,各算法平均簇规模随着节点数量的增加而增加,这是由于节点数量增加会导致节点分布的密度增大。同时,总信道数量越多,平均簇规模越大,原因是总信道数量增多提高了节点之间存在相同可用信道的概率。图11(b)显示,当节点数量固定设置为300个时,随着部署范围增大,各算法的平均簇规模都有所减小,这是因为部署范围增大会使节点分布更加稀疏,进而导致簇首一跳范围内的节点数量减少。从整体来看,Lowest ID 不考虑拓扑结构和节点重要性,其获得的平均簇规模最小。Max Degree 在全面掌握全网信息的基础上选择邻居数量最多的节点作为簇首,所以平均簇规模最大。MANE 能够利用有限的邻域信息选择簇规模大的簇首,无论节点数量和部署范围如何变化,MANE 始终保持了较高的平均簇规模,性能优于Lowest ID,且接近于Max Degree。
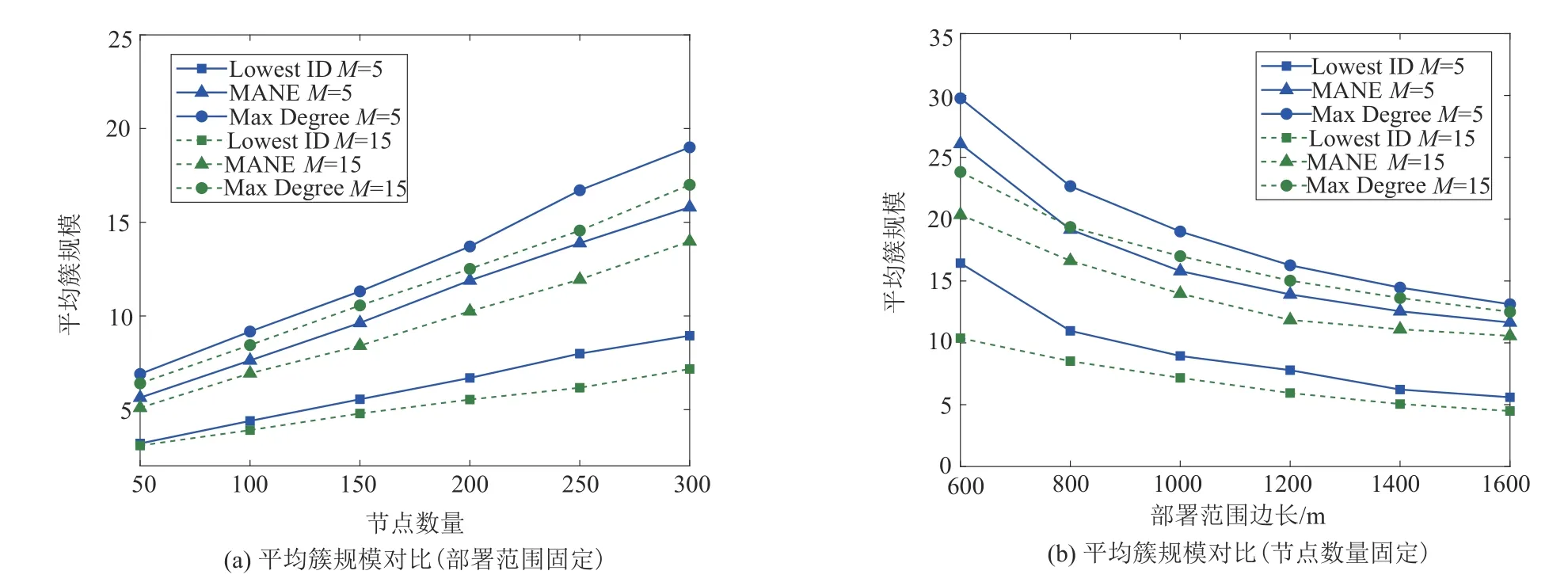
图11 平均簇规模对比Fig.11 Average cluster size
5 结论
本文针对无线自组网节点在实际场景中建网困难的问题,提出了一种基于邻域信息的多信道自适应建网算法(MANE)。仿真结果表明,MANE 能够以较少的建网开销,构建高效、稳定的网络拓扑结构,适用于频谱复杂变化的多信道无线自组网。下一步,将在此建网算法的基础上研究资源分配问题,即如何在建网的同时进行有效的信道分配和功率分配,提高网络的能效。
