LightGBM融合CFS的开发者感知代码异味强度预测模型研究
2022-12-06高建华
宇 通,高建华
(上海师范大学 计算机科学与技术系,上海 200234)
1 引 言
代码异味是程序源代码中任何可能表明问题更深层次的特征,通常由不合理的代码设计和不恰当的开发操作引起,即如果软件系统包含代码异味,则通常表明代码质量存在问题.传统的代码异味识别方法带有极大的主观性,并且因开发者、开发语言、开发方法的不同而异.
相关研究人员将常见的代码异味按照其不同特点进行了分类.Fowler等人[1]定义了22种发现的代码异味,针对如何检测代码异味,Moha等人[2]提出DéCOR的检测方法以及DETEX一种实例化该方法的检测技术,但该方法不能检测代码异味的强度.
代码异味作为软件技术债务[3]的直接体现,会随时间推移而在软件系统中堆积[4],因为软件在开发与使用阶段经常会因需求变更而进行扩展[5],增加新需求或修改原有需求.在此过程中由于开发时间或其他条件限制或通常会使源代码复杂度提高[6],从而降低了软件质量与可维护性.代码异味问题应尽快得到解决,正如Macia[7]在实证分析中得出的结论,如果开发早期阶段在代码中引入了异味,如不尽快消除便可能在代码和体系结构级别上导致更为严重的问题.
为了解决异味问题引入了重构[1],重构是在不改变软件外部行为的条件下,改善代码内部结构的技术.进行代码重构是提升软件质量的常用做法.
Zhang等人[8]对代码异味与重构相关的研究现状做了系统的阐述,他们发现现有的大多数研究集中于开发自动检测代码异味的工具或方法,而少有关于代码异味的实证性研究.
Basili等人[9]提出使用面向对象的一系列度量指标(CK)来预测软件项目是否存在缺陷,但并未对软件中存在的代码异味进行预测.
选择重构代码的顺序至关重要,Yamashita等人[10]发现并非所有代码异味的危害程度都相同.有些异味程度较轻而不会对软件质量造成缺陷,因此应优先重构异味较严重即异味强度大的代码.选择合适的方法对代码异味强度进行预测有利于对代码异味的处理进行优先级排序,可使异味强度大的代码得到优先处理,以节省人力物力成本.
在重构的先后顺序上,Zhang等人[11]提出重构优先级概念,即根据不同代码异味的严重性确定重构的先后次序,但只定性分析了软件缺陷与代码异味的关系,没有进行深入研究.
Ouni等人[12]利用软件开发历史信息,运用多目标优化的方法确定重构操作的最佳顺序以减少系统中的异味数量,提高了重构效率.Vidal等人[13]开发了SPIRIT工具,根据代码异味类型、过去做出的修改、系统修改可能性的评估,3个重要度量标准对代码异味进行排序.但此类方法均未综合考虑代码的各项度量指标.
在异味严重性检测方法上,Fontana等人[14]提出使用机器学习技术对代码异味严重性进行检测,运用了机器学习分类与回归模型,使用软件多种度量指标作为模型输入进行预测.
Pecorelli等人[15]在进行代码异味处理优先级排序时比较了RF、LR(逻辑回归)、朴素贝叶斯等机器学习算法,并验证了RF具有最佳效果,但未经特征筛选过程且模型精度与运行效率都有待提高.
在特征选择方面,通常原始数据集中存在着冗余和不相关特征,不经过处理可能会导致过拟合,引发“维度灾难”[16],Hall[17]提出使用相关性分析研究机器学习中的特征选择问题,以提高机器学习模型性能,取得了良好的效果.
Ke等人[18]提出了LightGBM,一种实现GBDT(梯度提升决策树)算法的框架,在保证高精度的同时具有更快的训练速度,也实现了更低的内存消耗.LightGBM已被运用在金融领域如加密货币价格趋势预测[19]以及医学领域如针对乳腺癌患者的miRNA分类[20],均取得了良好的效果,但目前还没有使用LightGBM进行代码异味强度预测的相关研究.
对此,本文提出了一种基于LightGBM融合CFS的开发者感知代码异味强度预测模型,该模型综合考虑代码产品与过程度量指标,使用经相关性分析筛选后的高相关特征,运用LightGBM算法对数据集中所考虑的4种代码异味实例进行异味强度预测.
本文的主要贡献有如下3个方面:
1)在统计层面分析了选取的代码度量指标与异味强度的相关关系,并选用软件代码的多个不同层面的度量指标,综合构建代码异味强度预测模型.
2)提出了一种基于LightGBM融合CFS的代码异味强度预测模型,结合相关性分析进行特征选择,并对LightGBM模型参数进行调整,根据模型评价指标对模型进行优化.
3)基于开发者感知的代码异味数据集,分别对软件项目中4种不同类型代码异味进行研究并将本文提出的基于LightGBM融合CFS模型与RF模型进行多方面对比,验证了本文提出的模型相比RF模型在预测精度以及效率等各方面性能上均有较大提升.
2 相关术语
2.1 代码异味
代码异味也称设计缺陷或设计异常,是代码在次优设计下的产物,其存在严重影响了软件系统的可靠性与可维护性,同一段代码可能会受多种代码异味影响.代码重构可以解决异味问题.本文聚焦以下4种代码异味,如表1所示.

表1 代码异味及其特征
选择以上4种类级别的代码异味进行研究,原因为:
Blob Class是内聚性较差的类所存在的代码异味,对代码质量造成了严重影响,且根据最近的研究,此种气味对软件项目及开发人员来说最为关键.
Complex Class表明类结构过于复杂,由此导致对这些类的测试工作较为困难,开发者通常能识别此种异味并对其严重性进行评估.
Spaghetti Code在过去研究中被深入调查,此种异味导致开发人员对源代码理解能力的下降,从而增加了代码维护工作量,开发人员也能对其关键性进行准确评估.
Shotgun Surgery是对某类进行修改时需要一并修改其他类,开发人员可根据触发其他类修改的数量来评估此种代码异味的强度.
以上4种代码异味已被证明在研究软件项目中大范围分布,其存在会对软件系统的可维护性、可理解性、可测试性造成严重的负面影响,且由于异味检测工具的限制,需在针对Java语言编写的程序中进行异味研究.综上所述,本文聚焦以上4种类级别的代码异味,对这4种代码异味进行分析研究也有助于更好地解决软件开发中的潜在问题.
2.2 代码异味强度
根据异味严重性数值划分不同等级得到代码异味强度,其可用于衡量异味的严重程度.准确地对代码异味强度进行预测可使高危险性的代码问题得到优先处理,从而在极大程度上减少软件项目的维护开销.本文考虑基于开发者感知的代码异味严重性Criticality,该指标是开发者对代码异味严重程度的直接评价,并按程度不同分为1~5,1为最轻微,5为最严重.代码异味强度相应地分为3个不同等级:NON-SEVERE(轻微)、MEDIUM(中度)、SEVERE(严重),以表征代码异味的严重程度,如表2所示.

表2 代码异味强度等级划分
轻微等级代表代码中存在较弱的代码异味强度,危害较弱且不易被察觉.中度等级代表代码中已有较明显的异味,通常可被开发者直接感知.严重等级代表代码中已存在危害性较高的代码异味,需要开发者尽快处理,防止后续发展为更严重的代码问题.
2.3 LightGBM算法
LightGBM,全称为Light Gradient Boosting Machine,该算法基于梯度增强的机器学习框架,利用了决策树算法.LightGBM与其他树类算法不同,不逐行增长树,而按叶增长树,其选择它认为将产生最大损失减少的叶子.LightGBM与XGBoost或其他模型所使用基于排序的决策树算法不同,LightGBM实现了一种高度优化的基于直方图的决策树学习算法,这种算法与传统算法相比在效率与内存消耗方面具有巨大优势,LightGBM算法采用两种新技术GOSS(基于梯度的单边采样)与EFB(互斥特征捆绑),使得算法运行速度更快且能保持极高的准确度[18].LightGBM具有许多XGBoost的优点,包括稀疏优化、并行训练等方面.
LightGBM的基于梯度的单边采样方法如算法1所示.
算法1.GOSS(基于梯度的单边采样)
输入:训练数据M、迭代次数I、大梯度数据采样率a、小梯度数据采样率b、损失函数loss、弱学习器L.
输出:训练完成的强学习器
2.topN←len(M)*a/*提取大梯度样本*/;
3.randN←len(M)*b/*从剩余数据随机选取b×100%小梯度样本*/;
4.fori=1 toIdo /*迭代循环直到达到规定迭代次数*/;
5. preds←models.predict(M) /*模型预测得到样本预测值preds*/;
6.k←loss(M,preds),s←{1,1,…} /*由preds计算loss,再计算得样本梯度,样本初始权重s均为1*/;
7. sorted←SortedData(abs(k)) /*由梯度绝对值降序排序得到样本索引数组sorted*/;
8. topSet←sorted[1:topN] /*在大梯度样本中选择topN数据得到索引数组topset*/;
9. randSet←RandPick(sorted[topN:len(M)],randN) /*从剩余数据中随机选取b*100%的数据,生成小梯度样本randSet*/;
10. usedSet←topset+randSet /*大梯度样本与小梯度样本进行合并*/;
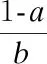
12. newmodel←L(M[usedSet],-k[usedSet],s[used Set]) /*由usedSet中的样本M、梯度k与权重s得到新的弱学习器*/;
13. models.append(newModel) /*将新的弱学习器加入模型*/;
LightGBM中的互斥特征捆绑方法(EFB)包括两项内容:特征捆绑和互斥特征合并,如算法2与算法3所示.
算法2.特征捆绑
输入:特征F、最大冲突数C、图G;
输出:特征捆绑集合bundles;
1.searchOrder←G.sortByDegree() /*构造具有加权边的图G,图的顶点为特征,将不互斥的特征顶点相连,边的权值对应特征同时不为0的样本数,按照顶点的度按降序排序特征*/;
2.bundles←{},bundlesConflict←{}
3.foriin searchOrder do
4. needNew←True
5. forj=1 tolen(bundles) do /*对有序表中每个特征,在特征捆绑簇中进行遍历*/;
6. cnt←ConflictCnt(bundles[j],F[i])
7. ifcnt+bundlesConflict[i] ≤Cthen /*C为设置的最大冲突阈值,若该特征加入特征簇中后冲突数不超过C,则加入该特征到这个簇中*/;
8. bundles[j].add(F[i]),needNew←False /*将特征分配给具有小冲突的现有bundle*/;
9. break
10. ifneedNewthen
11. AddF[i] as a new bundle tobundles/*否则创建新特征簇,并将该特征加入*/;
算法3.合并互斥特征
输入:数据数量numData、一个互斥特征簇F;
输出:newBin、binRanges;
1.binRanges←{0},totalBin←0 /*LightGBM中直方图算法对特征值进行了分桶(bin)*/;
2.forfinFdo /*binRanges为偏移常数数组*/;
3. totalBin += f.numBin
4. binRanges.append(totalBin)
5.newBin←new Bin(numData)
6.fori=1 tonumDatado
7. newBin[i]←0
8. forj=1 tolen(F) do
9. ifF[j].bin[i]≠ 0 then
10. newBin[i]←F[j].bin[i] + binRanges[j]
2.4 CFS
基于相关性的特征选择(Correlation-based feature selection,CFS).从源代码中提取到的代码度量部分可能与异味强度无关,即特征与异味强度之间的相关性较小,直接使用原始数据集中高维的数据特征通常会导致算法模型运算速度变慢,还可能降低识别精度.因此提出CFS根据相关性分析对代码度量指标进行筛选,计算各度量指标与基于开发者感知的代码异味严重性数值间的相关系数,衡量其之间的相关关系.采取过滤的方法,将相关性较低的度量指标滤去,保留高相关度量指标来作为后续代码异味强度预测模型的输入,如图1所示.

图1 代码度量指标CFS过程
3 代码异味强度预测模型
实际情况下代码之中存在的异味问题按危害程度有轻重之分,而现有的异味检测方法仍存在较大的局限性,或只依靠手动设置代码的单一结构度量阈值检测指标,如设置行数阈值范围来检测长方法,但缺点首先是指标的选取较为灵活,缺乏开发经验的人员往往不能准确定位某种代码异味的外在度量指标,其次是单一某种或简单几种综合的代码度量指标并不能充分反映代码质量.
基于此,本文考虑基于LightGBM融合CFS模型进行代码异味强度预测,先进行数据筛选过程,再提取相应代码度量指标并通过CFS进行特征选择,最后运用LightGBM进行预测并对预测效果及模型进行评价,如图2所示.
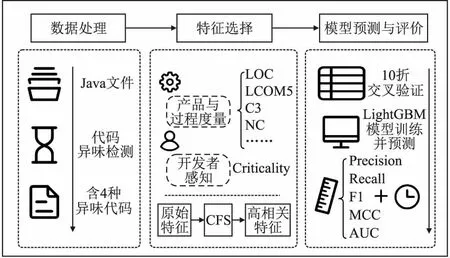
图2 基于LightGBM融合CFS的代码异味强度预测模型
3.1 数据统计
本文考虑所研究的4种类级别代码异味,挖掘Apache与Eclipse系统中9个开源项目中存在异味的代码,使用Décor[2]和HIST[21]进行异味检测,提取分别包含4种异味的代码.数据集中包含的代码异味数量情况如表3所示.

表3 代码异味数量统计
3.2 代码度量指标
选取产品度量、过程度量结合开发者度量,综合构建代码异味强度预测模型.本文研究所考虑的度量指标如表4所示.
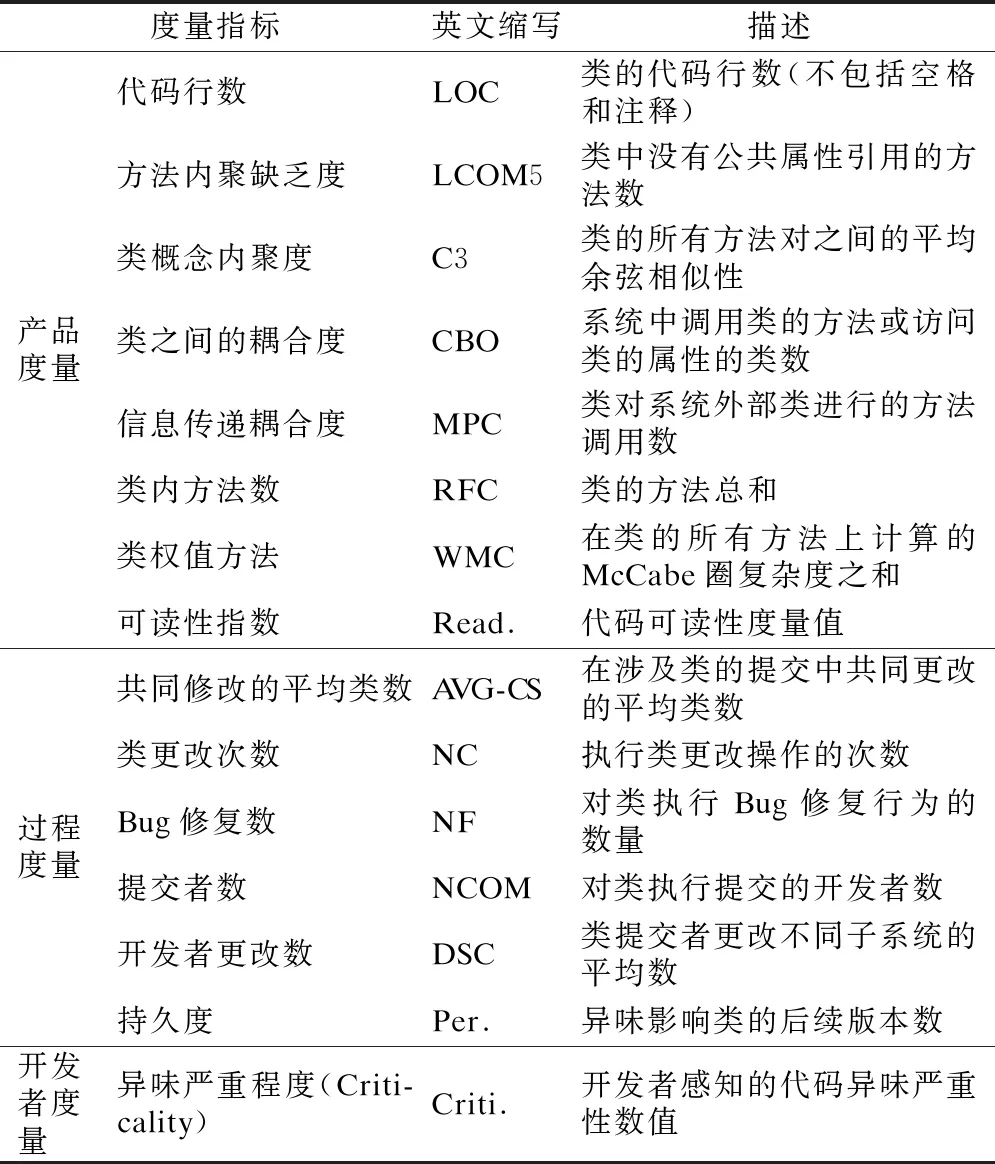
表4 代码度量指标
3.3 模型预测与评价
本文采用基于LightGBM融合CFS模型,运用10折交叉验证方式对数据集中代码的异味强度进行预测,如图3所示,依次将每折数据作为测试集,其余数据作为训练集,合并每折预测结果从而得到全体样本的代码异味强度预测结果.共选取6个评价指标对实验进行评估,其中,基于实例的评价指标共5个,包括Precision,Recall,F1,MCC,AUC.基于模型效率的评价指标1个,分析基于LightGBM融合CFS模型的性能表现,并与Pecorelli[15]等人提出的RF模型方法进行对比.
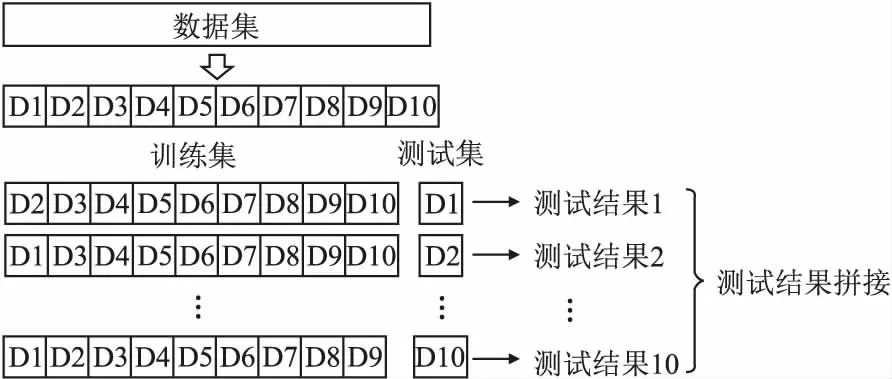
图3 10折交叉验证示意图
4 实验研究
本文设计3个实验,主要寻求解决以下3个问题:
Q1:代码相关度量指标是否和基于开发者感知的代码异味强度间存在相关关系?
Q2:本文所提出的基于LightGBM融合CFS模型与文献[15]的RF模型相比精度表现如何,是否有了提升?
Q3:本文所提出的基于LightGBM融合CFS模型是否比文献[15]的RF模型速度更快,效率更高?
4.1 实验环境和数据集
本文实验环境如下:操作系统为Windows 10,处理器为Intel(R) Core i5-6300HQ CPU @ 2.30GHz,内存12GB,所用软件为SPSS和PyCharm,开发语言为Python.
为了评估本文模型的性能,实验使用基于开发者感知的代码异味数据集,该数据集由开发者对代码气味实例进行评价得出,其中包含了开发者对感知到的代码异味严重程度的度量值.
数据集包含9个开源Java项目,它们属于两个软件生态系统,分别为Apache与Eclipse.数据集中项目在代码量、作用领域等方面各不相同,具有一定的代表性.所选项目的类数都超过了500个,变更历史超过5年,提交次数大于1000次,参与开发者数量都超过20人,可提供相应代码异味的实例以供研究.表5总结了所选项目的基本信息与统计数据.
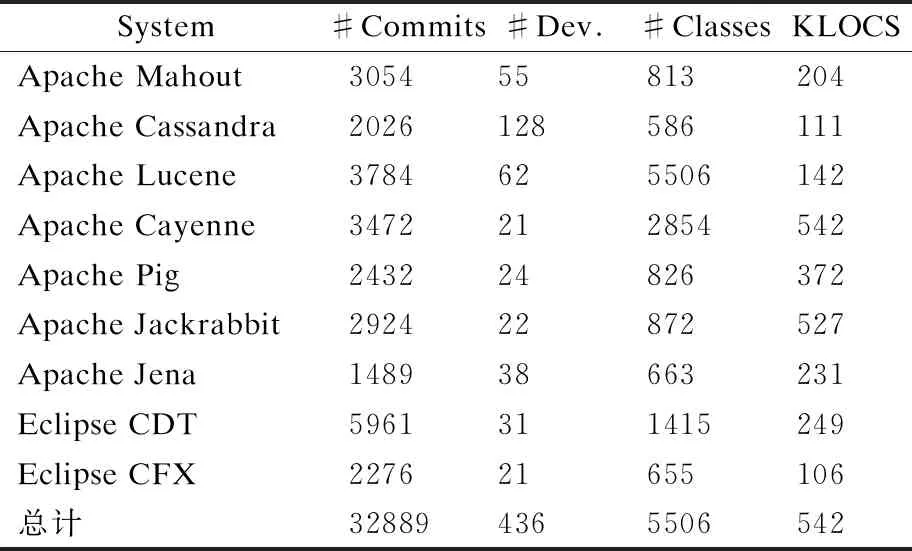
表5 实验所涉项目
4.2 代码异味检测方法
数据集中包含从实验项目中筛选出的含4种代码异味的代码实例,其中DÉCOR[2]用来检测项目存在的Blob Class、Complex Class和Spaghetti Code异味,HIST[21]用来检测Shotgun Surgery异味.这两种工具已被代码异味研究学者广泛使用,能准确地识别出代码中的代码异味.使用这两种工具进行检测从而避免了重新构造检测工具而带来的结果有效性威胁.从备选实验项目中提取的含4种异味的数据集,均经过了以上两种方法的检验,并证实了各自所含的代码异味的存在.用于实验的数据集中异味强度分布情况如表6所示.
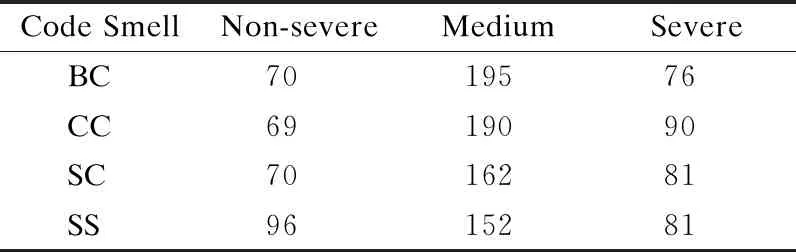
表6 数据集代码异味强度分布
4.3 相关性分析
从实验项目中选取代码度量指标,分别验证其是否与代码异味严重程度存在相关关系.用SPSS统计软件进行实验.这里引入Spearman相关系数.
(1)
其中ρ代表Spearman相关系数,它是衡量两个变量的依赖性的非参数指标,表明了x(独立变量)与y(依赖变量)的相关方向,这里x表示所考虑的各项代码度量指标,y表示代码异味严重性.Spearman相关系数取值范围为-1~1,0代表变量间无相关性,即该代码度量指标和代码异味严重性不存在相关关系,Spearman相关系数绝对值越接近1代表相关性越强,即该代码度量指标和代码异味严重性存在程度较强的相关关系,负值代表负相关,正值代表正相关.
由表7的统计结果表明,绝大多数考虑的度量指标和异味严重程度均有较强的相关性,Criti.为基于开发者感知的代码异味强度值,Sig意为显著性,在这里Sig代表判断异味严重程度和所考虑的代码度量指标之间具有相关关系的犯错几率,一般地在统计学中,若Sig<0.05则说明所考虑变量间存在显著相关关系.(回答Q1)
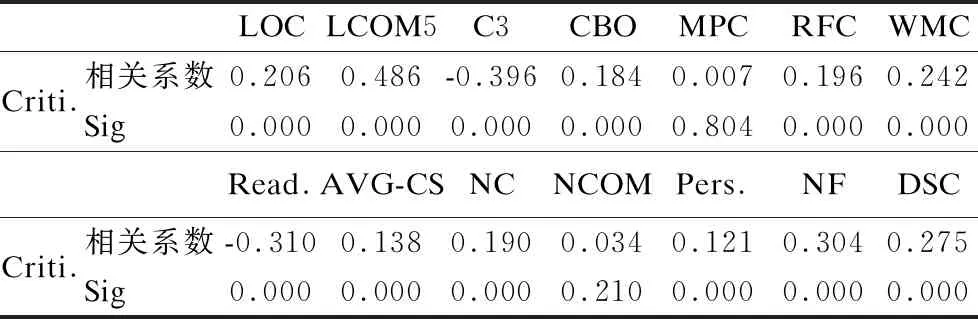
表7 Criti.与代码度量指标的相关性分析
值得注意的是,由表7可观察到涉及表示代码变更的指标(如NC、NF)均与开发者感知的代码异味严重性数值有着较强的相关性,且对代码修改的越频繁,代码异味严重程度也随之增加,呈明显正相关关系.(回答Q1)
另外,MPC的Sig值为0.804,即判断MPC与Criti.相关的犯错概率高达80.4%,且Spearman相关系数接近0,说明MPC与Criti.无明显相关关系,故根据CFS的特征过滤方法,应将其删去.本文所构建的异味强度预测模型具有一定通用性,若待测数据集中未提供Criticality值,通过本文CFS分析已筛选出与异味强度高度相关的代码度量指标,且高相关性的代码度量指标的选择一般不受不同代码数据集的影响,故只需采集待测数据集中相应代码度量指标代入模型即可进行代码异味强度的预测.
4.4 实验模型
4.4.1 RF模型构建
在Pecorelli等人[15]的代码异味严重性预测实现上,其方法是在比较了多种经典机器学习算法包括随机森林、逻辑回归、空间向量机、朴素贝叶斯和多层感知器后,选择了效果最优的随机森林作为最后的预测模型.
随机森林是一种基于集成学习的监督式机器学习算法[22],用随机方式建立一个森林模型,该森林结合了多个相同类型的算法,由许多决策树组成.决策树之间相互独立无关联,输入新样本时,该样本的取值为所有决策树共同决策得出.
随机森林随机性主要体现在了两方面,样本抽样随机性和特征抽样随机性.在训练集中随机地抽取一定数量的样本,作为树的根节点样本建立每棵子树.这两点随机性使得随机森林不容易陷入过拟合.
由于随机森林引入了两个随机性,也使得其具有了良好的抗噪能力.基于树模型的树状结构与其他线性模型的区别,数值缩放不影响分裂点位置,因而无需对数据集进行标准化处理.
4.4.2 LightGBM模型构建
LightGBM是基于GBDT算法的一个具体实现框架,GBDT(Gradient Boosting Decision Tree)为了使模型的效果达到最优化,利用弱分类器(决策树)进行迭代训练,GBDT广泛应用于多分类任务和点击率预估问题(CTR)的解决[23].
LightGBM采用基于Histogram的决策树算法,特点是引入了单边梯度采样(GOSS)与互斥特征捆绑(EFB)[18].GOSS的使用能有效降低小梯度数据在数据实例中所占比例,因此在计算信息增益时只利用剩余的高梯度数据即可,大大节省了在时间和空间上的消耗.EFB可将许多互斥的特征进行捆绑,从而有效减少了特征维度.
另外,传统的决策树模型生长采用Depth-wise策略,即是按层进行的[24].而LightGBM决策树采取Leaf-wise生长策略,即是按叶进行的.每次分裂时从目前所有叶子之中寻找分裂增益最大的叶子进行分裂,如此循环.LightGBM采用这种分裂方式的优点是使误差得到了有效的降低,有利于精度的提高,同时为了防止Leaf-wise生长策略带来的过拟合问题,LightGBM在参数设置中引入了max_depth最大深度限制,有效地解决了该问题.
LightGBM算法模型需要对参数进行调整已达到更好的训练与测试效果,LightGBM在所考虑的4种代码异味数据集上表现出良好性能的关键优化参数及含义如表8所示.

表8 LightGBM模型参数表
4.5 实验结果
根据Pecorelli等人[15]的RF模型与本文模型在4种代码异味数据集上的预测结果,分别构建混淆矩阵进行对比,如表9所示.

表9 本文模型与RF模型的混淆矩阵对比
从表9中可看出,运用本文模型对4种代码异味强度进行预测,在BC、CC、SC、SS所有4种异味上预测效果均优于RF模型,在预测Non-severe、Medium、Severe 3个异味级别中被错误预测的数量明显减少.采用本文模型预测效果可以在RF模型的基础之上再获得较大提升.(回答Q2)
4.6 模型评价
本文选取6个评价指标对实验进行评估,其中,基于实例的评价指标共5个,基于模型效率的评价指标1个.
4.6.1 基于实例的评价指标
基于实例的评价指标是对模型在每种代码异味数据集上进行预测的结果进行评估,以验证模型区分正负样本的能力,相关指标如下:
1)精确率.
真正正确占预测为正确的比例.计算公式如下:
(2)
其中,TP表示实际为正例且被分类器判定为正例的样本数;FP表示实际为负例且被分类器判定为正例的样本数;FN表示实际为正例但被分类器判定为负例的样本数;TN表示实际为负例且被分类器判定为负例的样本数.
2)召回率.
真正正确占所有实际为正的比例.计算公式如下:
(3)
3)F1值.
F-Measure计算公式如下.
(4)
这里β取为1,即为F1值.
(5)
4)MCC值(马修斯相关系数).
MCC的本质描述了预测结果与实际结果间的相关系数.计算公式如下:
(6)
MCC取值范围为[-1,1],MCC值为1表示预测结果与实际结果完全一致,-1表示完全不一致.
5)AUC值.
ROC曲线下方的面积大小,其取值范围为[0,1],该值越大的分类器,表示分类的正确率越高.
以上基于实例的评价指标原是基于二分类问题所讨论的,但都根据本文所研究的多分类问题进行了重新调整,均利用基于Python的Scikit-Learn进行自动化计算.精确率高表示模型要尽量在更有把握的情况下才会将样本预测为正样本,意味着精确率越高,模型对负样本区分能力越强.召回率体现模型对于正样本的区分能力,召回率越高则模型对正样本的区分能力越强.因此,对同一个模型来说,高精确率和高召回率通常不能同时达到,具有较高的精确率的模型往往具有较低的召回率.选取精确率和召回率作为评价指标具有不同的参考意义.
另外,本文选取相应算法模型的程序运行时间作为基于模型效率的评价指标,即计算模型从开始训练到预测完毕的时间,以衡量模型运行效率的高低.
将RF模型与本文模型在4种异味数据集上分别进行实验,将5种基于实例的评价指标进行汇总如表10所示.
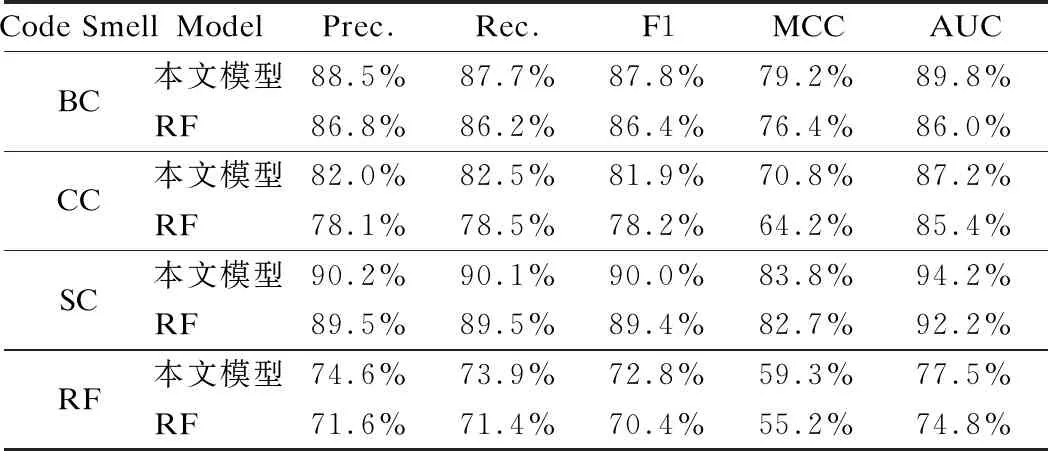
表10 本文模型与RF模型的评价指标对比
由表10可知,Pecorelli等人[15]所使用的RF模型的F1值在70.4%到89.4%之间,而采用本文的代码异味强度预测模型,其精确率、召回率、F1值、MCC和AUC在所有4种代码异味数据集上均较RF模型有了较大提升,其中预测精确率最高达90.2%,相比RF模型最多提升了3.9%;召回率最高达90.1%,最多提升了4.0%;F1值最高达90.0%,最多提升了3.7%;MCC值最高达83.8%,最多提升了6.6%;AUC值最高达94.2%,最多提升了3.8%.实验证明,采用基于LightGBM融合CFS的代码异味强度预测模型较RF模型优化效果明显.(回答Q2)
4.6.2 基于模型效率的评价指标
为了比较两种模型运行效率的差异,运用本文基于LightGBM融合CFS的代码异味强度预测模型与RF模型对4种代码异味数据集进行异味强度预测并统计模型从开始训练至预测完毕的时间,作为衡量模型运行效率的指标.每个模型在每种异味数据集上分别运行3次,记录每次所需时间如表11所示,表中数值单位均为毫秒(MS).
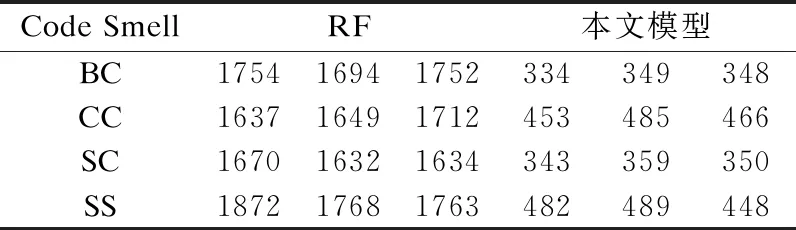
表11 本文模型与RF模型运行时间对比
取两种模型分别在4种异味数据集上进行3次异味强度预测的运行时间平均值作为最终运行时间,得出两种模型的平均耗时对比图如图4所示.
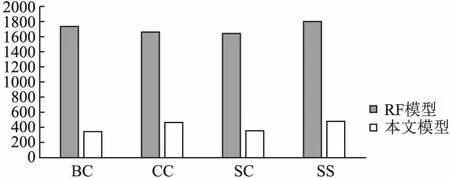
图4 RF模型与本文模型平均耗时对比图
如图4所示,本文所使用的基于LightGBM算法融合CFS模型在4种代码异味数据集上,运行耗时均远低于RF模型,运行时间缩短76.1%.相较于原模型,采用本文模型可使运行效率得到极大提升.(回答Q3)
5 总结与期望
本文提出了一种基于LightGBM融合CFS的开发者感知代码异味强度预测模型,与文献[15]采用的RF预测模型相比,性能在考虑的全部6个评价指标上均得到了较大提升.在提高了异味预测精度的同时加快了预测速度,降低了运行成本.说明本文基于LightGBM融合CFS的开发者感知代码异味强度预测模型能较好地帮助开发者确定代码中存在异味的优先级,以便于优先解决异味严重程度高的代码,有助于降低软件开发与维护成本.
后续的相关工作有两个方向:1)本文所选项目均基于Java语言,后续可以扩展到研究其他编程语言中的异味问题;2)本文只聚焦4种常见的代码异味,且均属类级别,可以扩展到其他种类的代码异味或研究粒度更高的方法级别代码异味问题.
