融合注意力机制的群组推荐研究
2022-10-26齐浩翔马莉媛
齐浩翔,尹 玲,马莉媛
(上海工程技术大学 电子电气工程学院,上海 201600)
0 引 言
为了解决信息过载问题,推荐系统被广泛应用于电子商务、新闻资讯、社交网络等领域[1]。与此同时,用户也有更多的集体活动,例如成团旅行、团队聚会、拼团购物等[2]。如何快速且精准地为群组推荐合适的项目成为了当下的研究热点。与传统的推荐系统不同,群组推荐系统所面临的对象是一个包含多个用户的群组,通常情况下,用户间有着很大的偏好差异,这就导致传统的推荐方法无法很好地完成群组推荐任务。
群组推荐中单一用户变为群组用户,需要融合群组中用户的偏好。同时,群组的决策往往存在用户间的交互过程,每个用户将为最终的决策做出自己的个人贡献。因此,一个良好的群组推荐系统应该不仅可以融合用户的偏好,还要能够建模群组中用户的交互。现有的群组推荐方法大多采用预定义的固定策略来融合群组用户的偏好,这些静态的方法无法体现群组用户间的交互,难以模拟复杂的群组决策过程,最终导致推荐效果不佳。如何通过学习用户间的交互来降低群组偏好冲突是群组推荐工作中的一项挑战。
相关研究表明,理想的群组推荐模型可以动态融合用户偏好,利用用户间的交互信息来模拟群组的决策过程往往会取得更好的推荐效果。文献[3]将遗传算法应用于群组推荐,该方法考虑到了群组间成员的相互作用,一定程度上提高了成员间的满意度;文献[4]提出了PIT(person impact topic)模型,认为最有影响力的用户应代表群组并对决策过程产生重大影响;文献[5]提出了COM(consensus model)模型,假定用户的影响力视群组的主题而定,相关领域专家将更具影响力,且用户之间的行为相互独立,但是该方法认为用户在不同的群组中遵循群组决策的概率相同;文献[6]提出了一种基于社会影响力的群组推荐SIG(social influence-based group)模型,主要思想是利用社交网络中的数据,以特定的神经网络框架来学习用户的历史信息和社会影响力。
将深度学习引入群组推荐更有利于群组中用户的偏好融合,比传统静态方法有更好的推荐效果。基于现有研究的基础,本文利用深度学习相关理论提出了一种基于注意力机制的群组推荐方法,在传统的协同过滤中引入注意力机制来获取群组中每个用户对其他用户的注意力权重,以此来选出群组中的决策者,该过程可以很好地模拟用户之间的交互,最后根据用户的加权偏好来为群组推荐项目。
1 相关工作
1.1 群组推荐
文献[7-8]通过共识分数对群组推荐做出了形式化的定义,从群组的预测评分和群组的分歧度两个方面量化,最终得到群组的共识分数,可以用公式表示为
F(G,v)=ω1×Gp(G,v)+ω2×(1-Dis(G,v))
(1)
(1)式中:Gp(G,v)表示群组对项目v的群组预测评分;Dis(G,v)表示群组用户对项目v评分的分歧度;ω1和ω2分别为对应的权重,且ω1+ω2=1 。群组推荐的目标是找到特定的项目v使共识函数F(G,v)最大化,故项目的群组预测评分越高,其群组分歧度就越低,就越能满足所有群组用户的偏好。
群组推荐大致分为3个步骤:群组形成,群组建模,项目推荐。具体来说,要先识别出与群组用户偏好类似的用户,再汇聚提取群组用户的共同偏好,然后对项目预测评分,最终完成推荐,其过程如图1所示。

图1 群组推荐过程Fig.1 Group recommendation process
在群组形成时一般考虑3个因素[9],包括群组大小、相关程度以及组内凝聚力。在识别群组成员时,多采用相似度计算和聚类这两种方法。
群组推荐系统将群组中每个用户的偏好进行融合,以缓解用户之间的偏好冲突,尽可能使所有用户满意。所以群组建模是整个推荐过程的关键,而在群组建模的过程中运用到的核心技术,是偏好融合策略和偏好融合方法[10]。将不同的偏好融合策略和偏好融合方法相结合,可以组成不同的群组推荐系统。
偏好融合策略大概分为3种:基本融合策略,加权融合策略,动态交互策略。基本融合策略主要包括均值策略(AVG)、最小痛苦值策略(LM)、Borda公平策略等[11-13],都是静态策略,均存在一定的不足。本文所提出的方法是一种加权融合策略,考虑了用户间的差异性,根据用户的特征[14]为其分配不同的权重,更符合逻辑,因此推荐效果更佳。
偏好融合方法大致分为偏好模型融合和推荐结果融合两大类。偏好模型融合是指在推荐生成前进行偏好融合;推荐结果融合是指在推荐生成后进行偏好融合。图2为偏好模型融合与推荐结果融合示意图。具体来说,偏好模型融合是在获取群组内每个用户的偏好后,再使用融合策略生成群组偏好,最后生成群组推荐结果;而推荐结果融合就是对每个用户的个性化推荐列表进行融合,与偏好模型融合相比,该方法能够动态地调整推荐列表,让更多的群组用户满意,但其计算过程更为复杂。
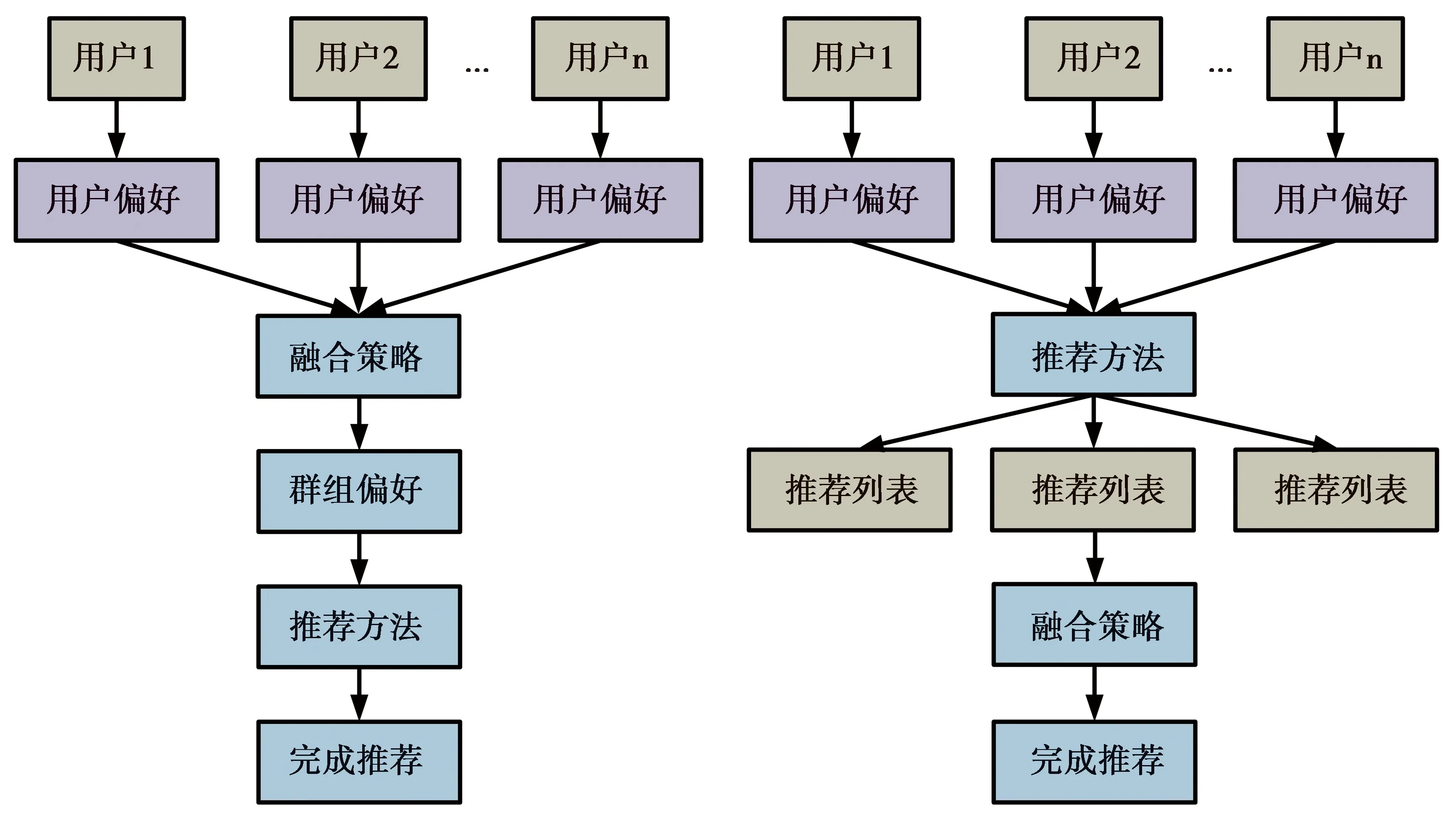
图2 偏好模型融合与推荐结果融合示意图Fig.2 Sketch map of preference model fusion and recommendation result fusion
1.2 注意力机制
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局信息[15],获得需要重点关注的目标信息,对重点信息投入更多注意力资源,以获取更多的细节信息,同时抑制其他无用信息。
注意力机制最开始广泛应用于视觉图像领域,后来又常用于自然语言处理的机器翻译任务,已经应用于各个领域。
机器翻译主要通过传统编码器-解码器模型传递信息,编码器-解码器框架如图3所示。

图3 编码器-解码器框架Fig.3 Encoder-Decoder framework
输出序列的所有元素都由同一个上下文向量进行解码。在这种序列到序列的任务中,如果文本过长,就很容易丢失文本的相关信息。针对这种状况,文献[16]提出在编码器-解码器模型中引入注意力机制,使每个输出元素都有上下文向量Cj,可以表示为
(2)
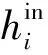
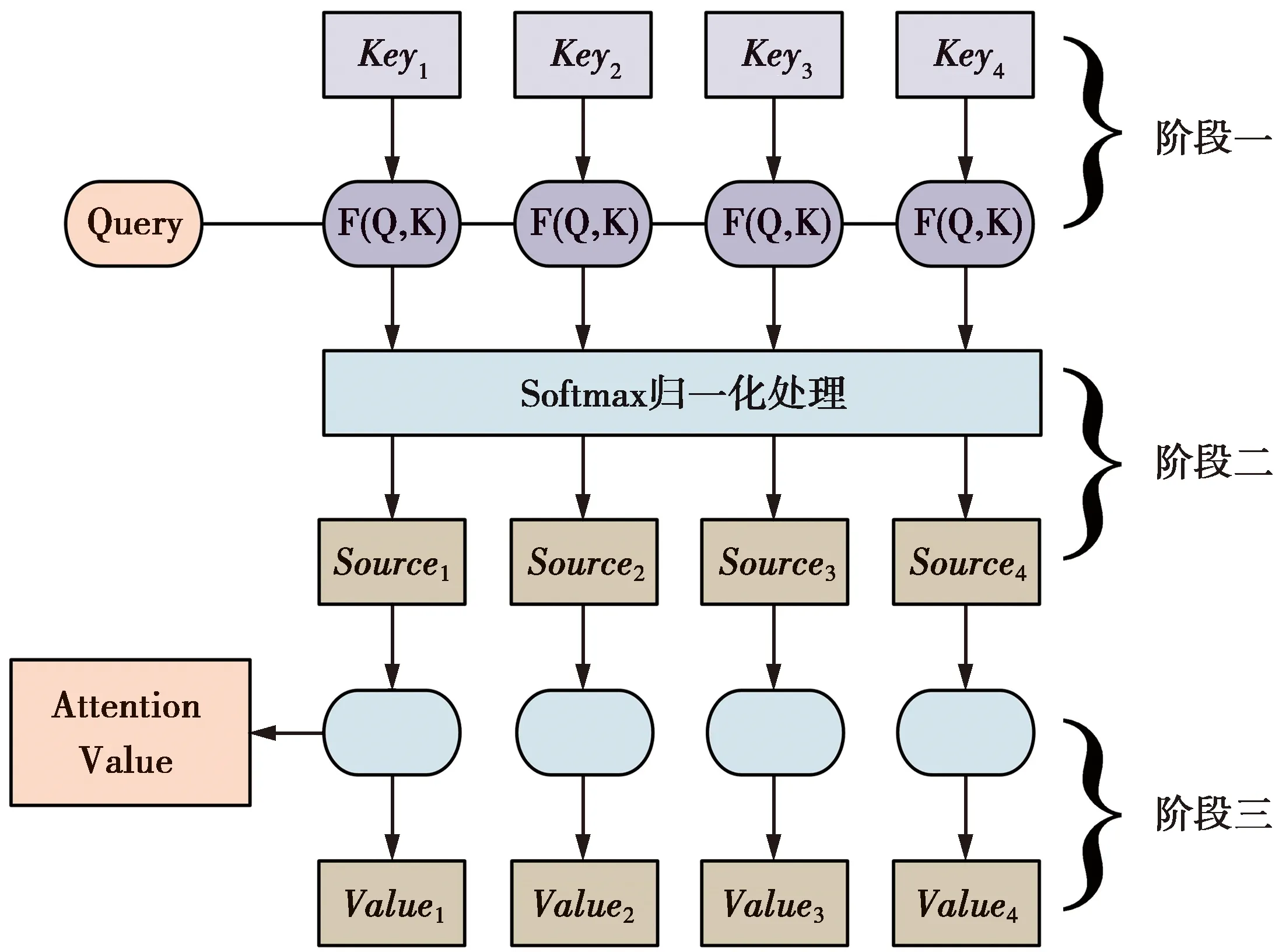
图4 注意力权重的计算过程Fig.4 Calculation process of attention weight
注意力机制的主要作用就是将Source中的构成元素Key、Value类比成一一对应的键值对
2 基于注意力机制的群组推荐方法
群组推荐旨在为一组用户推荐项目,良好的模型可以很好地模拟群组决策过程。用户可能只关注小组的领导者或专家等少数用户的决策。
2.1 问题制定
从U={u1,u2,u3,…,un}表示n个用户;V={v1,v2,v3,…,vm}表示m个项目;G={g1,g2,g3,…,gs}表示s个组。假设目标组t为gt,Ugt表示t组的成员,模型的目标是为该组生成一个推荐列表。具体来说,模型的输入为用户、项目、历史日志,输出为群组的项目预测分数。
2.2 本文模型
图5为基于注意力机制的群组推荐模型,主要包括3个层面:嵌入层、融合层、预测层。嵌入层将输入的用户和项目转化为稠密向量;融合层由一个神经网络构成,其主要作用是学习用户在群组中从其他用户那里获得的权重。在融合层的框架下,每个群组、项目以及用户都是一个嵌入向量,通过融合层得到一个群组向量的表示,作为预测层的输入;将向量输入到预测层,最后获得群组的预测分数。
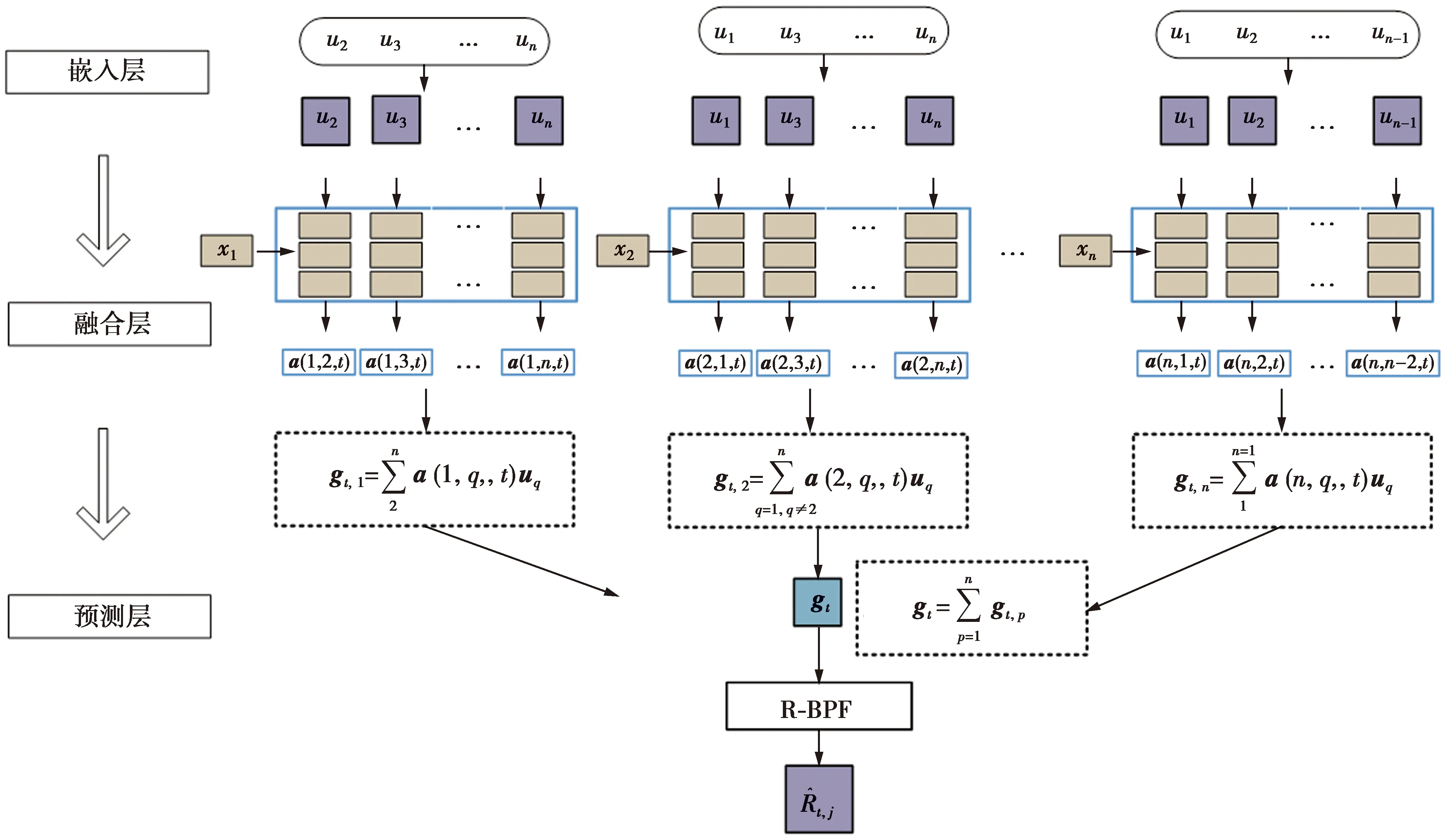
图5 基于注意力机制的群组推荐模型Fig.5 Group recommendation model based on attention mechanism
2.2.1 嵌入层
设un和vm分别是用户un和项目vm的嵌入向量,这些向量是模型中的基本表示元素。本文的目标是为每个群组获得一个嵌入向量,以估计其对群组偏好的表示。在把用户和项目转化为向量时,要对其进行one-hot编码,其在引发向量稀疏问题的同时也会导致计算的复杂度上升。为了避免这一问题,本文将one-hot编码后的向量转化为低维稠密向量,具体而言,第n用户和第m项目可以表示为un、vm。
2.2.2 融合层
群组间在进行推荐时一定会有类似小组讨论的用户交互。融合层可以很好地模拟该交互过程。整个过程分为两步:①在群组的决策中,每个用户先选出群组中的某些用户为该群组的决策者;②由这些被选出的用户为该组选择一个项目。注意力机制的主要作用是帮助每个用户学习其他用户的注意力权重。群组中重要的用户能够从其他用户那里获得较高的注意力权重。图6是本文方法针对单个用户决策过程的例子。图6中,x表示用户潜在向量,α表示注意权重,最终返回该用户的加权平均数值y。
用α(p,q,t)表示组t中用户up对用户uq的投票系数。根据以往的经验,用户更倾向于投票给相关领域专家的人。因此,如果uq用户在组t中属于领域专家,那他将获得该组其他用户较高的投票,获得相应的α(*,q,t)就更高。如果在另一个组r中,uq用户不再是该组的领域专家,他从其他用户那里获得的投票将会减少,那么他获得的α(*,q,r)将会减少。
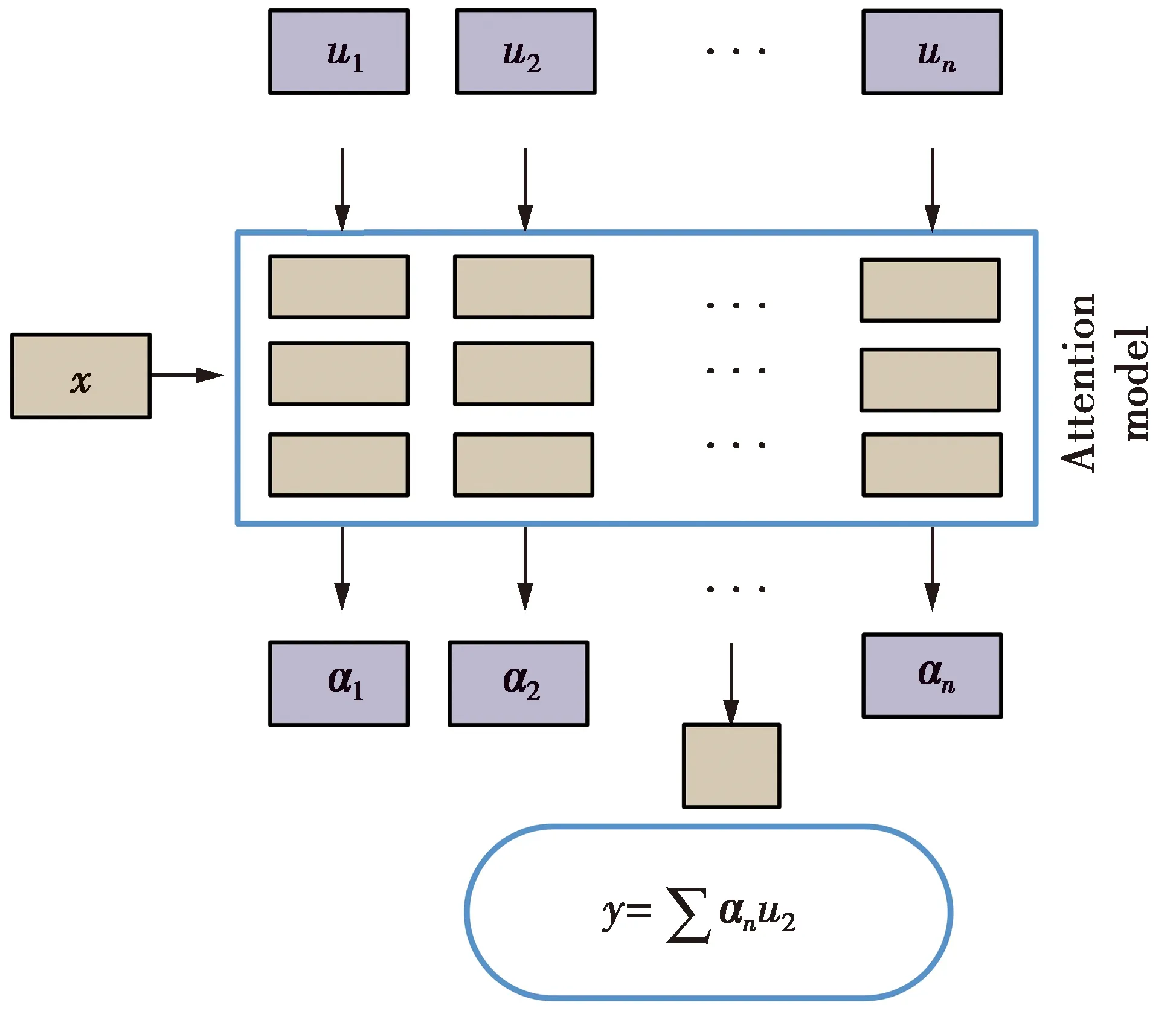
图6 单个用户决策过程Fig.6 Individual user decision-making process
由图5可以看出,本文所提出的方法本质上就是每个用户投票给其他用户,可以看成是同时进行的n个子过程。
对于给定目标组t,本文使用n个注意力子网络。每个注意力子网络都输入用户上下文向量,以及该用户的潜在向量,然后输出每个用户的注意力权重,最后将每个注意力子网络的输出加权求和。本文将目标组t分成n个子组,每个子组gt,p包含除去用户up之外的所有用户。每个组都是一个注意力子网络,每个注意力子网络的输出为
(3)
最终对所有用户的投票进行加权平均后得到
(4)
2.2.3 预测层
每个注意力子网络模拟该成员与群组其他成员之间的交互,以得到其对群组内其他成员的偏好参数,本文使用两层注意力网络来计算,最终得到该成员的注意力评分为
a(p,q,t)=wTφ(Wccp+Wuuq,q≠p+b)+c
(5)
(5)式中:矩阵Wc、Wu和偏置b是第1层参数;矢量w和偏置c是第2层参数。利用ReLU函数使φ(x)=max(0,x),再用Softmax函数对a(p,q,t)进行归一化处理,得到最终的注意力权重为
(6)
然后,得到目标组t的预测得分为
(7)
(7)式中,vj是j项的潜在向量。接下来对最终的推荐列表进行排序,从排序的角度来处理推荐任务。本文选择使用成对学习的方法来优化模型,假设已经观察到的项必须优先于未观察到的项。基于回归的成对损失(R-BPL)[17]是一种常用的成对学习方法,可用于解决个性化排序,同理也适用于优化群组推荐。最终的目标函数为
(8)
(8)式中,R表示训练集,包含群组的所有成对正负项。每个子集都是包含一个组和两个项目的3元组,表示与正项有所交互,与负项没有交互;有交互的为1,没有交互的为0。
3 实 验
3.1 准备工作
本文实验在Windows10操作系统下进行,实验数据集分别采用了CAMRa2011和MovieLens 1M。CAMRa2011是一个包含个人及家庭对电影评分的真实数据集,鉴于大多数用户缺乏群组的相关信息,实验过滤掉了个人用户,只保留加入群组的用户,最终该数据集包含602个用户、290个群组、7 710个项目。MovieLens 1M数据集,则在原有的基础上,经过处理,随机分配生成了一个包含1 082个用户、410个群组、1 422个项目的数据集。本文将数据集以训练集、测试集按8∶2的比例随机分配。
3.2 评价指标
根据推荐任务的不同,群组推荐的评价指标可分为预测评分评估和项目集合评估。因为本文模型本质上是用来解决Top-N推荐任务的,从命中率(hit rate,HR)以及归一化折扣累计增益(normalized discounted cwmulative gain,NDCG)[18-19]两个方面对提出的方法进行评估,对项目进行更加细化的区分,而不是仅分为相关和不相关,所以更适用于Top-N推荐任务。HR数值越大,效果越好,具体公式为
(9)
(9)式中:NoH表示点积数量,TN表示测试项目集合。
NDCG用来衡量列表的排序质量。其计算式为
(10)
(8)式中:ZK是一个系数,目的是使NDCG@K的值介于0~1;ri表示推荐结果的相关性,若命中,ri=1,否则ri=0;K是指Top-K(K=5,10),表示推荐生成列表的项目个数。
3.3 实验结果
为了体现本文方法的性能,选择4种模型进行对比实验,其中包括两种固定策略的传统静态模型:NCF均值策略模型(NCF+AVG)、NCF最大满意度策略模型(NCF+LM),以及目前群组推荐中较为先进的非固定策略的模型:共识模型(COM)和SIG模型。
1)NCF+AVG模型。通过NCF模型预测用户的偏好分数,再使用均值策略融合用户的偏好以获得群组偏好分数。最终将群组中个体用户的偏好得分的平均值作为群组偏好得分。
2)NCF+LM模型。与NCF+AVG模型类似,该模型通过NCF模型结合最小痛苦策略向群组推荐项目。最小化群组成员的偏好得分,将个体得分的最小值作为群组得分。
3)COM模型。该模型假设用户的影响力与所处的群组相关,通过概率模型对群租决策过程进行建模。
4)SIG模型。该模型利用社交网络中的数据,以统一的框架来学习用户的历史信息和社会影响力,再利用神经网络对用户和项目的交互进行建模。
不同K值下各方法在CAMRa2011数据集上的HR如图7所示,NDCG如图8所示。
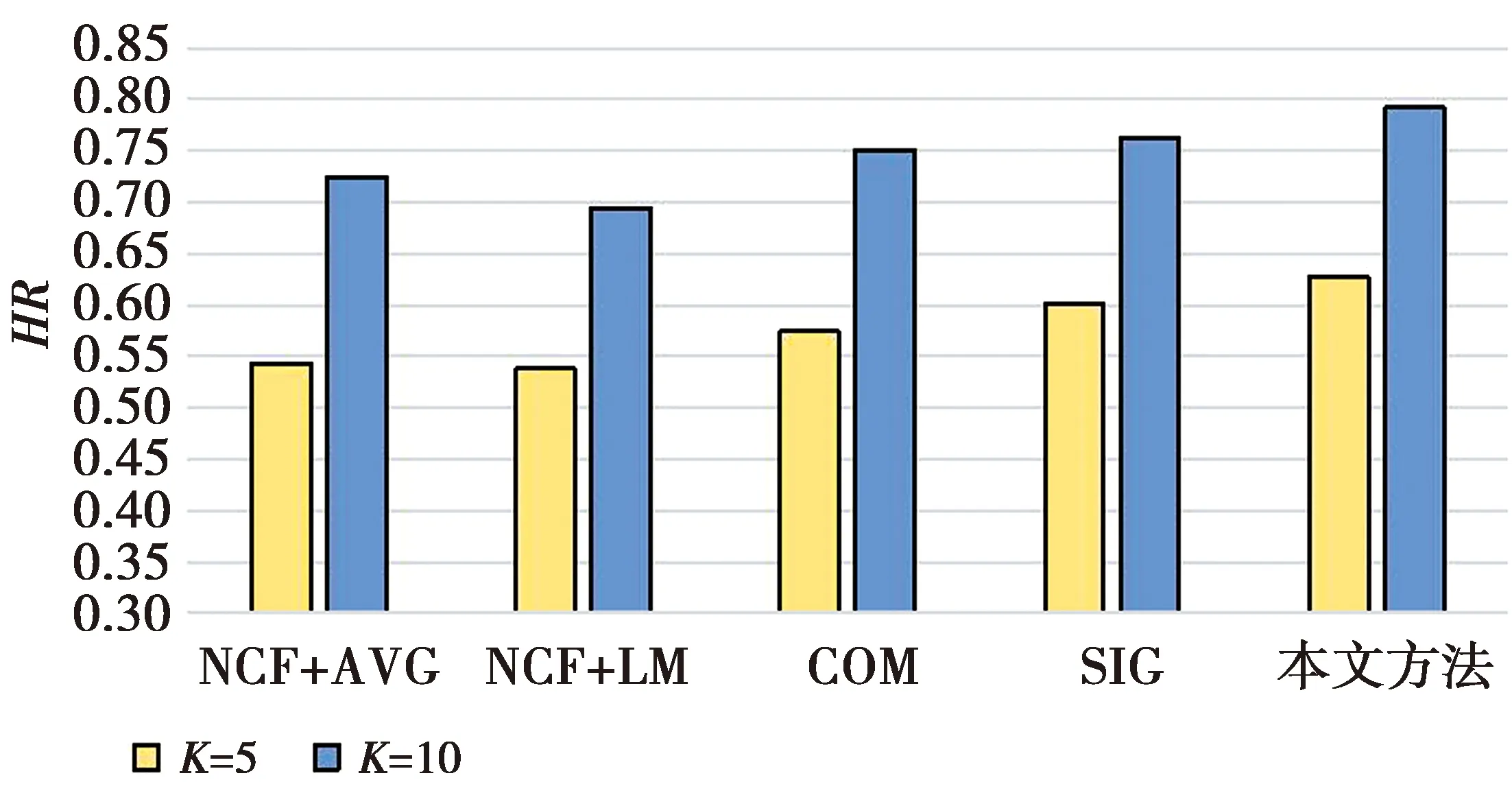
图7 不同K值下各方法在CAMRa2011数据集上的HRFig.7 HR of each method on the CAMRa2011 data set under different K values
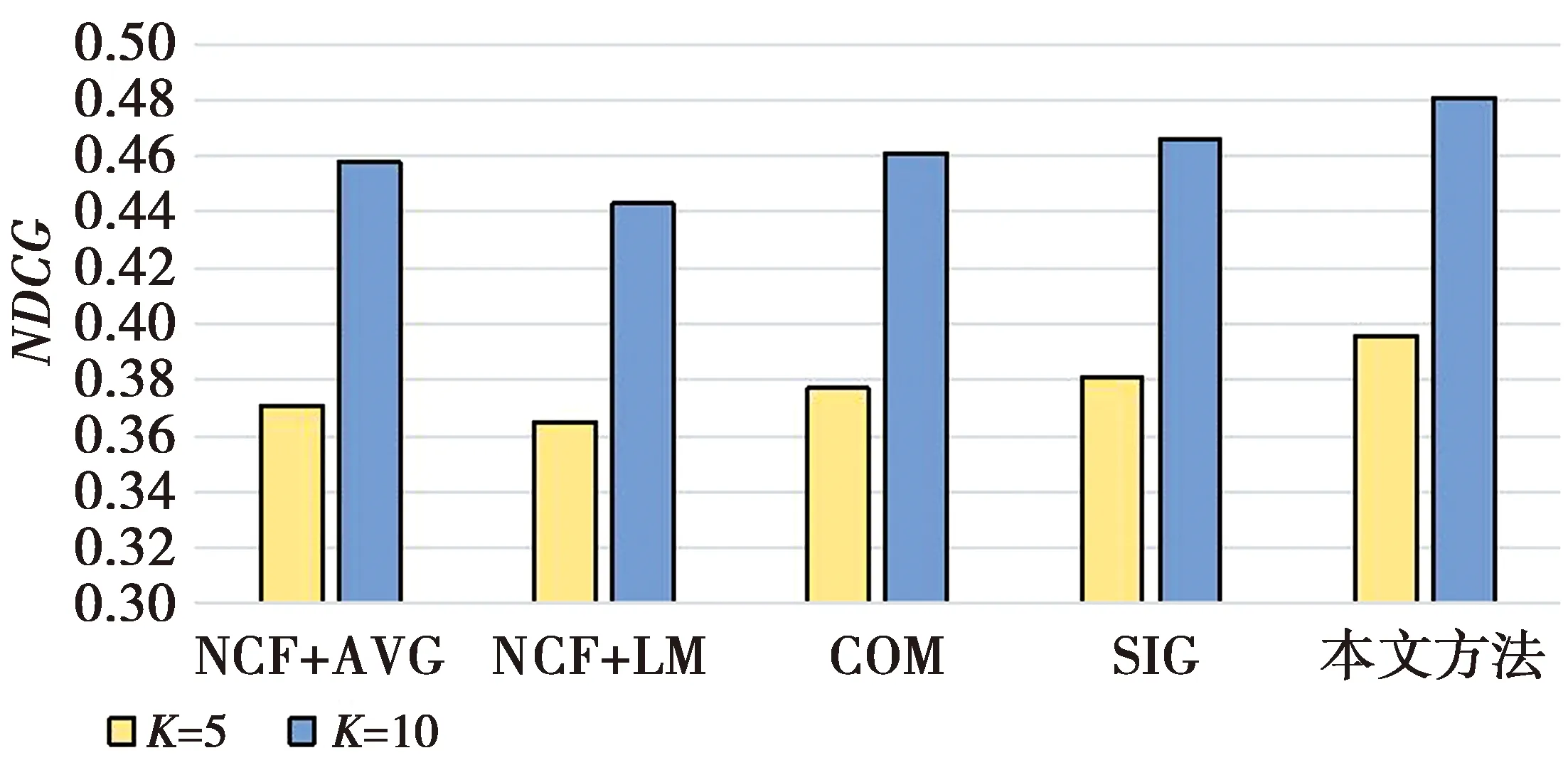
图8 不同K值下各方法在CAMRa2011 数据集上的NDCGFig.8 NDCG of each method on the CAMRa2011 data set under different K values
由图7—图8可见,在推荐项目个数K=5,K=10时,本文所提出的方法在数据集上均取得最优表现。在与效果最好的基准模型SIG方法相比较时,也具有明显的优势,说明了本文方法的有效性。K=5时,本文HR和NDCG分别比SIG方法提高4.21%和3.80%;K=10时,分别提高3.94%和3.22%。
不同K值下各方法在CAMRa2011数据集上的HR和NDCG如表1所示,在MovieLens 1M数据集上如表2所示。
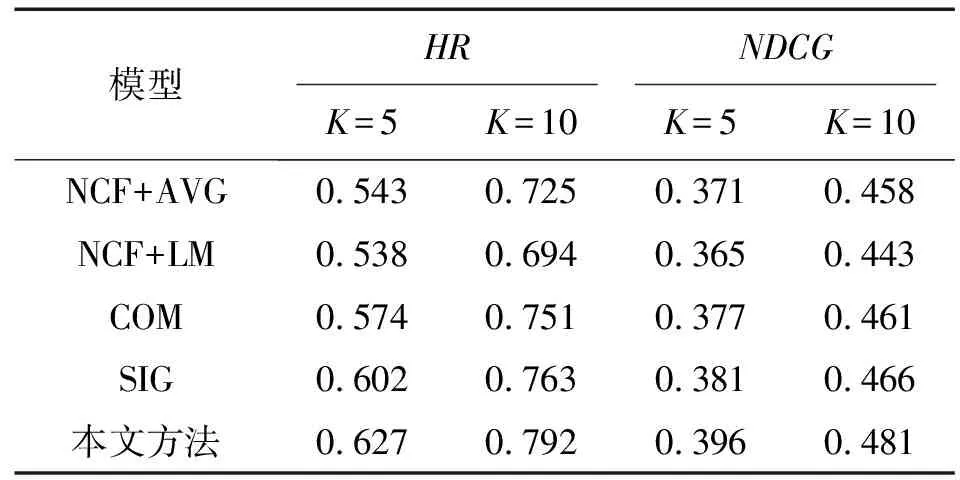
表1 不同K值下各方法在CAMRa2011数据集上的HR和NDCGTab.1 HR and NDCG of each method on the CAMRa2011 data set under different K values

表2 不同K值下各方法在MovieLens 1M数据集上的HR和NDCGTab.2 HR and NDCG of each method on the MovieLens 1M data set under different K values
由表1—表2可以看出,在数据集MovieLens1M中,各方法的表现都明显不如CAMRa2011数据集。这与MovieLens1M数据集中项目个数略少,历史数据不足有关。
图9所示为本文模型在CAMRa2011上迭代时评价指标的变化趋势。从图9可以看出,本文模型在CAMRa2011数据集上收敛很快,迭代到第5次时基本收敛,到第20次时趋于稳定,到第30次时完成迭代达到最优。
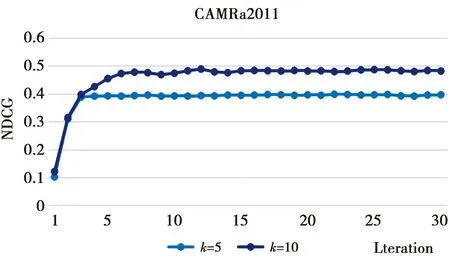
图9 本文模型在CAMRa2011上的迭代表现Fig.9 Iterative performance of our method on CAMRa2011
为了应对不同规模的群组,本文还探究了各推荐方法在不同规模群组上的表现。由于各方法在CAMRa2011上的表现更加优越,因此选择在CAMRa2011上进行了不同规模群组的实验。将群组分为3人组、5人组、10人组和15人组进行试验,不同规模下各方法的NDCG结果如图10所示。

图10 不同规模下各方法的NDCGFig.10 NDCG of various methods at different scales
从图10可以发现,本文方法在面对不同规模的群组时一直保持着较高的推荐质量,在面临10人以上的大规模群组时也有着良好的表现;COM与SIG模型也能够在大规模群组中取得较好的效果,但COM模型在小规模群组中的表现不佳;两种传统的固定策略,在面对10人以上的大型群组时性能反而受到影响,尤其是NCF+LM算法,并不能很好地应对大型的群组推荐任务。因此,在面对不同规模的群组时应该对现有的群组推荐算法有所取舍;在面临更大型群组时,应该采取怎样的推荐算法也是一个值得研究的问题。
4 结束语
为了解决现有群组推荐中预定义策略导致推荐效果不佳的问题,本文提出了一种基于注意力机制的群组推荐方法。该方法使用注意力机制来获取群组中每个用户对其他用户的注意力权重,为群组选出一个决策者,以此来模拟群组中用户的交互,并根据用户的加权偏好来为群组推荐项目。考虑到用户在不同群组中发挥的作用不同,该方法可以动态调整不同用户在不同群组中的注意力权重,能够很好地模拟群组决策过程。
