基于残差连接的高帧率Siamese目标跟踪算法
2022-10-25石少华伊力哈木亚尔买买提
石少华,伊力哈木·亚尔买买提
(新疆大学电气工程学院,新疆乌鲁木齐 830047)
0 前言
视频目标跟踪的任务是在视频序列中自动定位指定目标,当前该技术已经被广泛应用于机器人导航、智能汽车、医学诊断和运动分析等多个领域。随着其广泛应用,越来越多的研究者也逐渐投身于该方面的研究。
目标跟踪算法主要分为两类:生成式模型和判别式模型。早期的生成式模型主要有光流法、粒子滤波算法、Mean Shift算法等。判别式模型主要有TLD、支持向量机等。2015年以后,随着深度学习的广泛应用,人们开始尝试将深度学习用于目标跟踪领域,DLT、SiamFC和SiamRPN等一系列目标跟踪算法的相继提出,使得深度学习逐渐成为目标跟踪领域的又一研究热点。
当前目标跟踪算法面临的主要挑战有:目标遮挡、形变、快速运动和相似物干扰等。在SiamFC中,一种新的全连接孪生神经网络被提出,它使用第一帧给出的模板图像训练出一个普适的相似性学习模型,随后用训练好的孪生网络从一个大的搜索图片中选择模板图像,该网络实现了端到端的训练方式,并且在实时性和准确性上都取得了比较理想的效果。在SiamFC中,由于模板图像仅从视频首帧获得,因此其跟踪效果主要依赖于首帧模板图像特征的有效性。然而,SiamFC使用的主干网络是相对较浅的AlexNet,这就导致首帧模板图像的有效信息往往未能被充分利用。为解决这一问题,大多数Siamese跟踪算法是通过引入更复杂、更深层的卷积神经网络提取更高维度的目标特征,该类方法虽然有效,但也使得模型复杂度显著提升,严重影响了跟踪的实时性。另外,在跟踪任务中,大多数Siamese跟踪算法只用到了网络输出的最深层卷积特征,对于网络输出的浅层特征并未利用到,这在一定程度上造成了输出特征信息的丢失,降低了模型的性能。
针对以上问题,本文作者基于SiamFC算法提出一种基于残差连接与深度可分离卷积的Siamese目标跟踪算法。将原有主干网络中的5×5卷积块替换为2个3×3的卷积块,使得在保持感受野大小不变的情况下提高算法对特征的学习能力,并减少其计算量,加快模型推理速度。使用深度可分离卷积代替主干网络中的普通卷积,进一步减少算法计算量,为将算法嵌入到移动端或算力不足的设备中打下一定基础。在深度可分离卷积过程中采用逐层裁剪消除填充操作带来的影响。借鉴ResNet网络中的残差结构,在深度可分离卷积块中引入残差连接,以此将网络中不同层级提取的特征进行有效融合,达到提高特征信息利用率的目的。
1 相关原理
1.1 SiamFC跟踪算法
在目标跟踪中使用孪生网络架构,其目的是将跟踪任务转变为相似度匹配问题 。其公式如(1)所示:
(,)=()*()+·1
(1)
式中:为经过预处理的模板图像,大小为127像素×127像素;为经过处理的待搜索图像,大小为255像素×255像素;*代表互相关操作;(,)为最终得到的相似性响应得分图;为在每个位置取值为的偏置信号,∈。其跟踪过程为:模板图像和搜索图像经过相同的特征提取网络后,分别得到6像素×6像素的模板图像和22像素×22像素的搜索图像的特征图,利用作为卷积核在上进行滑动卷积,最终得到一个17像素×17像素的响应得分图,图中响应值最大的点为目标相对位置,随后对得分最高点进行多尺度变化,从而得到原图中目标的所在位置。
1.2 深度可分离卷积
MobileNetV1为当前比较流行的轻量级网络,它是Google提出的一种网络模型,其主要创新点是用深度可分离卷积代替普通卷积,因此它在计算量和模型大小上都远小于传统卷积神经网络。其中,深度可分离卷积操作主要分为两步,首先是深度卷积,将输入数据的每个通道进行单独卷积;然后是点卷积,对深度卷积后的输出进行1×1的标准卷积,从而得到所需维数的特征图,较大地减少了模型的计算量和复杂度,使它可以被应用到一些算力相对不足的设备中。标准卷积和深度可分离卷积的网络结构分别如图1、图2所示。

图1 标准卷积

图2 深度可分离卷积
图1、图2中:为输入图像的大小;为卷积核大小;和分别为输入和输出的维数。
进行一次标准卷积操作的计算量如公式(2)所示:
·····
(2)
进行一次深度可分离卷积操作的计算量如公式(3)所示:
····+···
(3)
所以一次标准卷积操作与一次深度可分离卷积操作的计算量比例如公式(4)所示:


(4)
文中使用的深度可分离卷积网络中为3,因此理论上一次深度可分离卷积的运算量大概是普通卷积的1/9倍,所以在一些算力相对较弱的设备中,文中算法更适合。
2 文中算法
文中算法在SiamFC基础上将原网络中的5×5普通卷积替换为2个3×3普通卷积,并使用深度可分离卷积代替原网络中的普通卷积,这样不仅大大减少了网络计算量,还增加了网络中的非线性操作,进而提高模型对特征的学习能力。另外,为充分利用提取到的特征信息,在所提算法中通过残差块融合网络提取到的不同层特征。文中算法的整体网络框架如图3所示,其中为模板图像,为搜索图像。

图3 文中算法框图
2.1 改进后的卷积块
在算法整体网络框架图中,Conv2、Conv3是两个3×3的卷积块,其作用是代替AlexNet原网络中的5×5卷积块,另外在所提网络模型中用h-swish激活函数替代ReLU激活函数。具体结构对比如图4所示。可以看出:在保证输出特征尺寸大小不变的情况下,图(b)中的非线性操作比图(a)多,这在一定程度上增强了模型对于特征的学习能力,从而使得决策函数更加具有判别性。
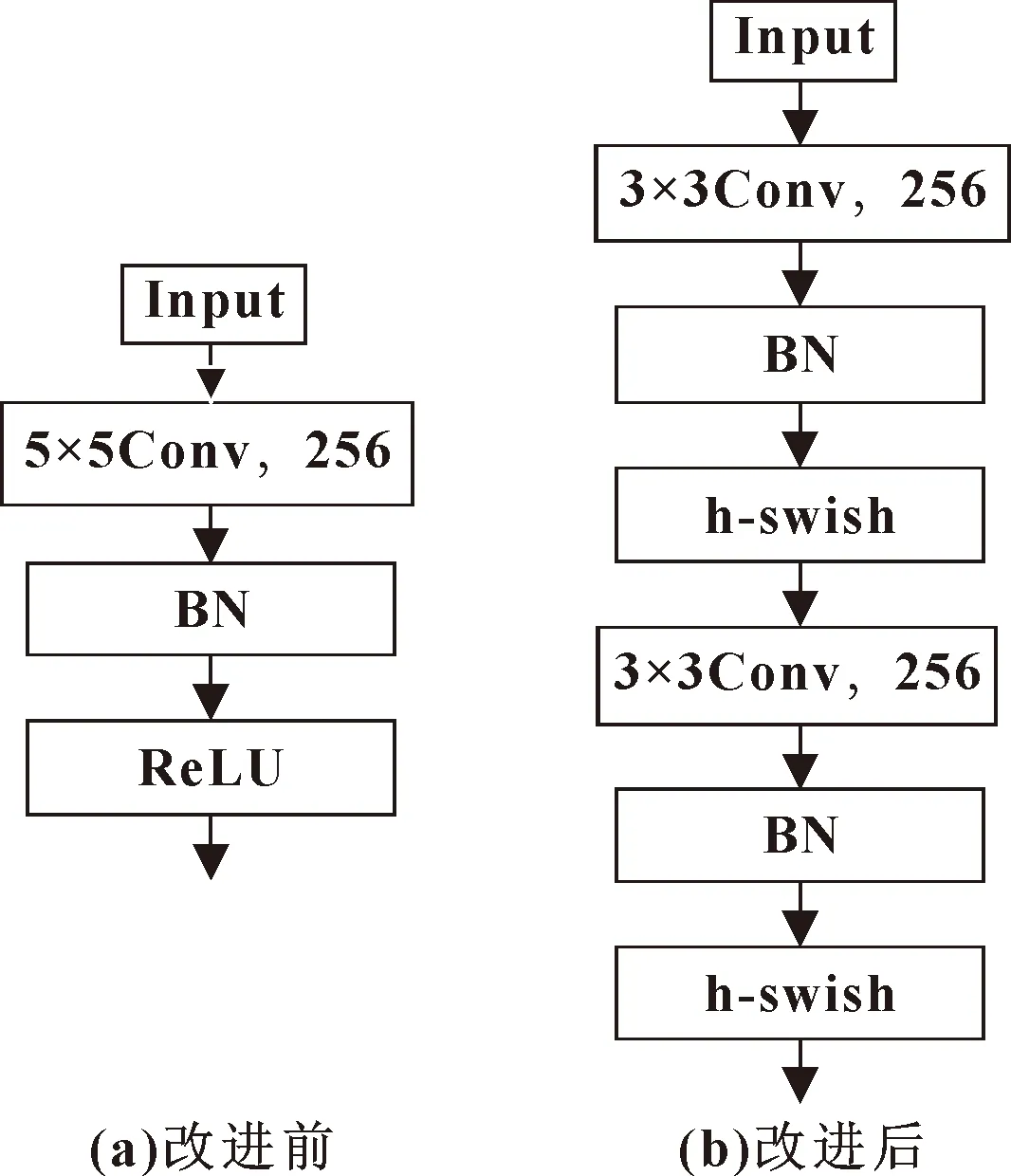
图4 卷积结构改进前后对比
另外,在输入大小为×且输入输出通道数相同的情况下,图4(a)中的计算量如公式(5)所示:
5×5××××=25××××
(5)
图4(b)的计算量如公式(6)所示:
3×3×2××××=18××××
(6)
从式(5)(6)可知改进后模块的计算量与改进前模块相比大概节约了39%。
在激活函数的选择上,文中选择h-swish激活函数,它在准确率上与swish激活函数基本一致,是swish激活函数的近似版本。另外,与swish激活函数相比它有如下几个好处:(1)它没有使用Sigmoid函数,计算量得到了极大的减少;(2)ReLU6适用于大多数软硬件平台的部署;(3)在内存访问上,由于它使用的是逐点操作,大大降低了延迟,提高了系统的实时性。与ReLU激活函数相比,h-swish具有无上界有下界、平滑、非单调的特性,在模型效果上也要优于ReLU。其数学表达如公式(7)所示:

(7)
2.2 Residual Block特征融合结构
在卷积神经网络的前向传播过程中,不同卷积层对所要表征目标的信息侧重点往往是不同的。深层网络有利于提取目标语义特征,语义特征中具有丰富的语义信息,利于目标和背景的判别,因此常采用网络提取的最后一层的特征来表征目标。然而,语义特征的分辨率低,不能很好地捕捉到空间位置等细节信息,但这些细节信息却是目标准确定位的关键。浅层特征更有利于保留目标的位置、轮廓、尺度、边缘等结构特征,对于目标的定位更为有利。
在大多数Siamese跟踪算法中,只是用到了卷积网络终层输出的深层卷积特征,并没有利用到浅层特征,这在一定程度上造成了特征信息的丢失。文中利用深度可分离卷积和残差连接组成Residual Block结构,用以融合卷积神经网络不同层的输出特征,减少特征信息的丢失。另外,SiamFC使用AlexNet网络作为主干网络,它是没有填充的全卷积网络,使用深度可分离卷积替换原网络中的普通卷积,这虽然增加了网络深度,但也不可避免地引入了填充操作。对于一个含有填充操作的网络来说,目标图像的特征可能是从原始图像加上额外零填充区域中提取的。对于搜索图像的特征,有些特征可能只从图像本身提取,而有些特征则是图像本身加上额外零填充的区域。本文作者在主干网中的Residual Block结构后添加剪裁操作,用以消除填充对跟踪结果产生的负面影响。Residual Block结构如图5所示。
图5中主干分支为深度可分离卷积操作,其主要操作分为以下两步,首先对输入特征矩阵进行深度卷积处理,即对输入特征矩阵的每一个通道单独使用一个卷积核进行处理;然后是点卷积,对深度卷积后的输出进行1×1的标准卷积,目的是得到所需维数的特征图。
图5中捷径分支的设计是为了融合网络提取的不同层特征,其具体作用:将捷径分支与主分支的输出特征矩阵进行相加融合。值得注意的是,在特征融合时捷径分支与主分支的输出特征矩阵必须具有相同的shape。其次,由于深度可分离卷积并不改变输入特征矩阵的大小,因此只需在捷径分支中通过一个1×1的标准卷积来调整其输出特征矩阵的深度,使它与主分支中的输出特征矩阵深度相等即可。

图5 Residual Block结构示意
3 实验结果分析
3.1 实验平台及参数设置
文中算法实验环境是在Windows系统下进行的,采用Python编程语言和PyTorch 1.4.0 框架。实验所用CPU为Intel(R) Xeon(R) W-2223 3.60GHZ,GPU处理器为NVIDIA RTX2080Ti,显存11 GB。
训练集选用GOT-10K,它包含了超过10 000条视频,分为560多个类别,且主角都是现实世界里移动的物体,手动标注的目标框超过150万。训练过程中,采用随机梯度下降法,训练时的学习率从指数0.01衰减到1×10,mini-batches设置为8,训练50个epoch,互相关操作中的偏置为0,动量因子(momentum)为0.9。
文中算法的损失函数定义为公式(8),∈{-1,+1},代表该点的真值标签;表示score map中每个点的实际得分。
(,)=ln[1+exp(-)]
(8)
不同的候选位置有着不同的得分,所有的候选位置构成总得分响应图,代表得分响应图的所有位置。训练时采用所有候选位置的平均逻辑损失表示损失函数,如公式(9)所示:

(9)
3.2 基于OTB数据集的实验
文中选择目标跟踪中常见的公开数据集OTB50和OTB2015作为验证集,分别包含50、100个完全注释的视频序列。文中的评价标准为一次通过评估(One-Pass Evaluation,OPE),评价指标为精确度(Prec)和成功率(AUC)。精确度为算法预测出的跟踪框中心与数据集标注中心的欧氏距离小于一定阈值的成功帧数占总帧数的百分比。成功率用预测跟踪框与标注跟踪框的重合率得分OS(Overlap Score)进行评估,其表达式如公式(10)所示:

(10)
式中:为预测跟踪框;为标注跟踪框;其中|·|为交并集区域像素数。当OS大于设定的某一阈值时,表示该帧跟踪成功,总成功帧数和总帧数比率即为成功率,此实验成功率取值范围为0~1。
3.2.1 总体性能分析
该实验将文中算法与当前7种常见跟踪算法进行比较,分别是SiamFC、CFNet、Staple、SRDCF、MUSTer、fDSST、STRUCK。
它们在OTB50数据集上的表现如表1所示。可知:文中算法的精确度为0.823、成功率为0.609,SiamFC的精确度为0.728、成功率为0.541。与SiamFC相比,文中算法在精确度上提升了13.0%,在成功率上提升了12.6%,在速度提升了21.2%。

表1 各跟踪算法在OTB50上的表现对比
在OTB2015数据集上的表现如表2所示。可以看出:在OTB2015数据集上,文中算法无论是在精确度还是在成功率上与其他7个跟踪算法相比均处于最佳水平,并且在GPU上的运行速度高达105 帧/s。与原算法SiamFC相比,精确度提升了5.4%、成功率提升了3.1%、速度提升了22.1%。与跟踪器SRDCF相比,精确度提升了3.3%、成功率提升了1.3%。

表2 各跟踪算法在OTB2015上的表现对比
文中算法之所以在各数据集中处于领先地位,主要有以下几点因素:
与深度学习类算法(SiamFC、CFNet)相比,文中算法使用了更深的网络层数,目标模板经过卷积神经网络后,得到了对目标表征能力更强的深层语义特征,而传统的深度学习类算法只使用了卷积网络输出的深层语义特征。文中算法通过加入残差连接将网络提取的不同层特征进行自适应融合,通过一系列操作,网络提取到的深浅层特征得到了充分利用,从而增强了跟踪算法在尺度变化、遮挡和光照变化等挑战中的鲁棒性。
与传统的相关滤波算法(Staple、SRDCF、MUSTer、fDSST、STRUCK)相比,相关滤波算法采用在线训练和实时更新,使得其跟踪速度大打折扣,很难满足跟踪实时性的要求。文中算法采用离线训练的方式,并且在模型的大多数卷积层的使用中选择了计算量相对较小的深度可分离卷积,因此,在跟踪速度上文中算法与相关滤波算法相比有较大提升,约是Staple和fDSST的1倍多。另外,文中使用的深度特征是通过大量训练样本学习出来的特征,比相关滤波手工设计的特征更具有鉴别性,所以在跟踪精度和成功率上,文中算法也优于SRDCF。
3.2.2 基于OTB2015数据集的不同属性的实验分析
为进一步对比文中算法和其他算法在不同挑战下的表现,分别绘出了OTB2015数据集中11个不同属性下的精确度和成功率的对比图,如图6、7所示。

图6 OTB2015不同属性下的跟踪精度对比结果

图7 OTB2015不同属性下的跟踪成功率对比结果
从图6、7可以看出:文中算法的跟踪精度在10个不同属性下都位列第1,在复杂背景下文中算法的精确度为0.76,排名第2,第1为MUSTer,它的精确度为0.77,两者差距很小,但在跟踪速度方面MUSTer约为4帧/s,文中算法远高于它。在跟踪成功率方面,文中算法在9个不同属性的挑战上都保持最佳性能,只有在复杂背景和光照变化的挑战中位于第2和第3。
另外,为更直观地展示出文中算法和其他算法的跟踪效果,从OTB2015的100个视频序列中选择6组具有代表性的视频序列进行可视化展示,分别是Basketball、Bolt2、Car4、David3、Girl2、MotorRolling,其可视化结果如图8所示。文中仅画出了AUC排名前5名的算法跟踪框,实验中,在同一帧图像上利用不同类型的跟踪框来展示文中算法与其他主流算法的跟踪效果。在所选的这些视频帧中包含了光照变化、旋转、目标遮挡、背景复杂和尺度变化等绝大多数目标跟踪所面临的挑战。

图8 6组视频序列可视化跟踪结果对比实验
在Basketball视频序列中,其主要难点包括遮挡、背景复杂及光照变化。从第24帧可以看出在发生轻微遮挡时,各算法均能进行有效跟踪,但从跟踪效果上看,文中算法和Staple比较出色;第419和694帧分别是运动员经过几次交叉移位、遮挡后各跟踪算法的跟踪效果,从跟踪框来看,文中所提算法均为最佳,其中在第694帧时,SRDCF和Staple均已丢失跟踪目标。
在Bolt2视频序列中,其跟踪难点主要是形变、背景复杂。在短跑比赛中,由于运动员一般都会在起跑后进行不断加速,其肢体动作往往会发生很大变化,这在一定程度上增加了跟踪难度。从可视化图中可以看出,在运动员刚起跑后,SiamFC就丢失了目标,并且在整个跟踪过程中均跟踪失败;在第183和205帧中,目标与其他背景物发生重叠后,SRDCF也出现了跟踪丢失的情况;与其他算法相比,文中算法更优秀。
在Car4视频序列中,跟踪难点主要有尺度变化和光照变化。3幅图中目标物体分别处于不同光照变化的场景中,并且在尺度上也发生了一定变化。从整体跟踪效果来看,所有算法均跟踪到了目标物体,但从标出的跟踪框可以看出,在跟踪精度上,文中所提算法更准确。
在David3视频序列中,跟踪难点主要是遮挡、形变和平面外旋转。通过可视化结果可以看出,当视频中目标与背景发生重叠时,除SRDCF外,其余算法均都较为准确地跟踪到了目标,但在跟踪精度上,文中算法更优秀。
在Girl2视频序列中,其跟踪难点主要是遮挡、平面外旋转和尺度变化。在第59帧中,小女孩虽然与背景物发生了严重重叠,但各算法都准确跟踪到了小女孩;在178帧中,小女孩在首次经过路人的完全遮挡和重现后,只有文中算法重新找回小女孩且成功跟踪;在1487帧中,小女孩在经过不同场景变化后,身体背对摄像头,并且受到了轻微遮挡,这时只有文中算法和SRDCF成功跟踪到了目标。
在MotorRolling视频序列中,其跟踪难点主要是快速运动、平面内旋转和运动模糊。在跟踪开始阶段,赛车手与摩托发生旋转,这时所有算法都能较好地跟踪到目标物,然而在第63和161帧中,随着目标大小尺度和跟踪场景的变化,只有文中算法依旧表现良好。
综上所述,文中算法在11种不同属性的挑战中,除了在背景复杂和光照变化场景中表现稍差于排名第一的跟踪算法,在其余9个挑战上都保持了领先地位,由此可以看出文中算法适用于不同场景的跟踪任务。
4 结束语
为了保证目标跟踪算法在复杂场景下的高速率和高精度,提出基于残差连接与深度可分离卷积的孪生网络跟踪算法。以SiamFC算法为基础,利用深度可分离卷积和残差连接对其原网络进行改进,使得模型可以提取更深层的语义特征,并且残差连接的加入使得模型可以将不同层卷积网络提取到的特征进行融合,从而达到充分利用所提取特征信息的目的。对网络模型中卷积块大小的调整和使用参数量更少的深度可分离卷积代替普通卷积,使得网络的总体参数量相比于原网络较少,因此所提算法在算力较小的设备上更具竞争力。
