大规模MIMO 系统分级预编码及基于人工免疫的功率分配算法*
2022-10-16魏唯
魏唯,李 月
(黑龙江大学,黑龙江 哈尔滨 150080)
0 引言
随着移动通信在5G 技术的支持下持续快速发展,连接的设备终端、数据流量将以指数形式迅速增长。大规模多输入多输出(Multiple Input Multiple Output,MIMO)技术作为5G 的核心技术之一[1],采用的方法是在基站端配置百根左右甚至更高数量级的天线,并通过空间复用[2]技术为大量用户提供服务,在很大程度上提升了系统的频谱效率。但大量的天线增加了接收信号检测[3]的复杂度,而通过预编码技术[4]对发射信号进行预处理,可增强接收端的信号检测性能。文献[5]、文献[6]和文献[7]回顾了大规模MIMO 预编码算法,介绍了它们的性能与复杂性。按照预编码技术的实现原理可将其划分为线性和非线性两类预编码方案,并以此为基础还提出了许多改进的优化预编码方案。
通信技术的发展过程中,大规模MIMO 中的功率分配问题[8]一直是一个重要的问题。在基站端对发射功率的合理分配对提升通信系统的性能具有非凡的意义,然而最优功率解很难获得。文献[9]旨在提供一种控制功率分配问题的解决方案,以最大化能量效率(Energy Efficiency,EE),给出了基于牛顿方法的最佳功率分配和基于拉格朗日分解的联合用户关联方法,导出了最优功率分配的闭合解。该算法具有良好的性能和效果,然而其计算复杂度仍然过高。文献[10]研究了在多小区大规模MIMO 下行链路系统中联合功率分配和用户关联的问题,制定了最大化最差用户频谱效率的最大最小公平目标函数,并证明了它可以作为一个拟线性规划来求解。还有研究证明传统的方法可以解决以目标函数为优化目标的功率分配问题[11],但需要以提高计算复杂度为代价。通常构造的目标函数有最大总和频率效率、最大化最小频谱效率,但这是两种过于极端的情况。最大总和频谱效率(Spectral Efficiency,SE)[12]完全忽略了用户间的公平性,且其优化问题是非凸的,计算复杂度高。最大化最小频谱效率[13]则通过提高信道质量差的用户的频谱效率,使得各个用户的频谱效率趋近于相同,虽提供了完全的公平,但必然使得信道质量好的用户性能受到损失。此外,以最大化最小频谱效率为目标函数,普遍的求解方法是使用二分算法[14],其高度依赖迭代,因此计算复杂度高。
鉴于此,本文在进行功率分配的同时,为了消除小区内多用户间干扰(Multi-user Interference,MUI)和小区间干扰(Inter-cell Interference,ICI),基于分组消除干扰的思想提出分级预编码方案。首先在小区内依据用户的位置信息对用户进行分组,以消除MUI;其次在小区间基于信漏噪比[15]的思想设计预编码方案,以消除ICI 以及残存MUI;最后,引入人工免疫算法[16]完成功率分配。人工免疫算法是根据生物的免疫机制构造出的一种优化算法,对于求解全局寻优、非线性等复杂问题具有自身特有的益处,同时具有自适应性、全局收敛性等优点。人工免疫算法可以通过调整亲和度函数实现功率分配。这里为了兼顾用户个体和系统整体的性能,提出将每小区用户最小频谱效率与平均频谱效率的乘积作为亲和度函数完成功率分配。实验结果表明,相较于传统的二分算法,人工免疫算法可以有效提升用户的频谱效率,使得用户个体和系统整体的性能均得到提升。
1 多小区多用户大规模MIMO 系统
1.1 大规模MIMO 系统模型
本文考虑的大规模MIMO 系统工作在时分双工(Time Division Duplexing,TDD)模式下,定义其由L个六边形小区构建而成。在每小区l中心位置的基站处配置M根天线服务于K个随机分布在小区内的单天线用户,如图1 所示。
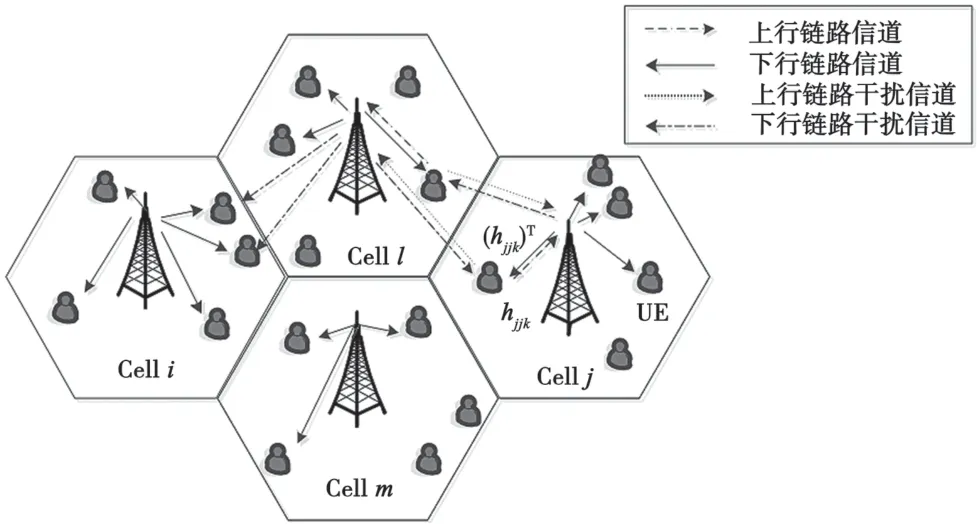
图1 大规模MIMO 系统模型
第j个小区中的第k个用户到小区i基站的上行链路信道矩阵可以表示为:

式中:hijk=(hijk1,hijk2,…,hijkM)T∈CM×1为一个列向量;gijk=(gijk1,gijk2,…,gijkM)T∈CM×1为小尺度衰落矢量,其分布满足gijk~CN(0,IM);βijk为一个标量,代表大尺度衰落系数,可表示为:
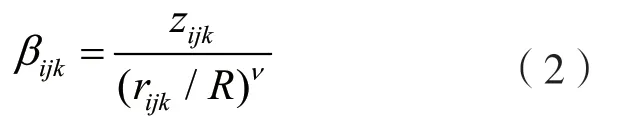
式中:zijk为阴影衰落因子;rijk为第j个小区中的第k个用户到小区i基站的距离;R为小区半径;v为路径损耗指数。搭建的系统工作在TDD 模式下,因此下行链路信道是上行链路信道的转置,故下行链路信道为hijkT。
1.2 大规模MIMO 信道估计
在大规模MIMO 系统中,通常对信道进行估计使用的方法为最小二乘(Least Square,LS)法或者是最小均方误差(Minimum Mean Square Error,MMSE)法。这里为了消除小区内干扰,系统对于同一小区内的用户使用相互正交的导频,同时为了提高频谱效率,对小区之间采用全复用导频方案。本文系统使用的导频序列表示为:

式中:τp为系统分配给每个终端的导频信号所占的长度。
因此第i个基站接收到的导频信号可以表示为:

2 分级预编码及功率分配算法
在基站端对发送信号进行预编码处理目的在于抵消信道中的干扰,进而消除用户间的干扰,降低用户终端的计算复杂度。第j个小区的基站发送给当前小区内K个用户的信号为:

式中:ρjk为小区j内用户k分配的功率;sjk为归一化的发射信号,即E{|sjk|2}=1;wjk为小区j用户k的预编码向量。
在基站端,根据发送的导频信息获得对信道的估计,计算得到预编码矩阵。对发射信号进行预处理,可以很好地消除用户之间的干扰。但是在实际的通信环境之中,受到地理因素等影响,用户的分布在一些区域较为稠密,而在另外一些区域则较为稀疏。在用户稠密的区域中,由于用户数量多且用户之间距离近,用户端会明显地感受到不论是打电话还是上网都会变得非常困难,用户间的干扰难以很好地消除;因此设计基于分组的消除干扰的方法显得十分必要。
2.1 用户分组
联系到上述实际中的通信情景,受到某些重点区域多用户场景的影响,基站所服务的用户分布呈现稀疏的特性,此时适合采用基于分组干扰消除的思想设计预编码策略。在大规模MIMO 系统中,由于用户的位置信息具有无线信道的本质特征,故依照用户位置对用户进行分组,用户分组伪代码如下:

2.2 分级预编码
2.2.1 组内预编码
通过上述小区内用户分组的步骤得到分组后的结果,在分组内针对MUI,总是希望对于每个用户k能将其他所有用户的干扰项置为零,一般可通过信道矩阵求逆实现,如迫零(Zero-forcing,ZF)预编码算法。小区j中用户k的ZF 预编码算法的表达式为:
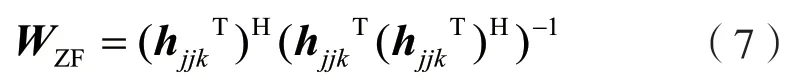
基于这种思想设计预编码可以较好地消除多用户之间的干扰,但没有考虑到噪声的问题,当用户与用户之间位置较近时,会使信道矩阵由于高度相关性成为病态矩阵,这时对信道矩阵求逆会导致噪声放大。而正则化迫零(Regularized Zero-forcing,RZF)预编码算法建立在ZF 预编码算法的基础上,在对hjjkT(hjjkT)H求逆前引入单位矩阵,可有效缓解噪声放大问题,故在分组内采用RZF 预编码。小区j中用户k的RZF 预编码的表达式为:
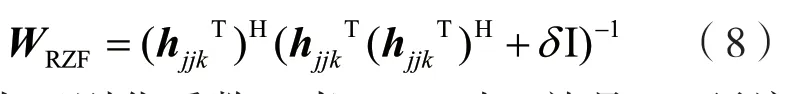
式中:δ为正则化系数,当δ→0 时,就是ZF 预编码;当δ→∞时,就是最大比发射(Maximum Ratio Transmitting,MRT)预编码。
2.2.2 组间预编码
通过上述小区内用户分组的步骤得到分组后的结果,在分组内采用RZF 预编码。但仍需判断小区内是否存在未被分组的单独用户,若不存在,则相当于已经完成小区内多用户间干扰消除;若存在,下一步考虑消除单独用户与分组间的干扰。块对角化(Block Diagonalization,BD)预编码实质上是基于ZF 预编码的一种演进,其通过引入零空间矩阵可以很好地消除其他用户的干扰。这里将划分为一组的用户视为一个等效用户,其等效信道矩阵用组内所有用户的平均信道矩阵替代,没有被分组的用户则仍然是一个单独的用户,采用BD 预编码的思想,求得零空间矩阵用于消除等效用户和独立用户之间的干扰。假设当前小区j中K个用户被划分为C组,即等效对应于C个独立用户,剩余c个未被分组的单独用户。对于任一未被分组的用户cs,其他所有用户的联合等效信道定义为:

2.2.3 小区间预编码
最后提出小区间预编码,解决ICI 以及残存MUI 的问题。小区间干扰主要考虑当前小区用户的信号带给其他小区用户的干扰。通常情况下,预编码优化的目标往往是提高用户的信干噪比(Signal to Interference plus Noise Ratio,SINR)。由j小区中用户k接收到的信号为:

由式(10)可以计算得到小区j中用户k的SINR为:

由SINR表达式可以得出,如果以最大化SINR作为优化目标,计算用户k的预编码向量会涉及其他所有用户的预编码向量,变量之间相互耦合,无法计算获得精确的解。而如果将优化目标设定为最大化信漏噪比(Signal to Leakage and Noise Ratio,SLNR),则完全能够避开这个问题。SLNR希望泄露给其他用户的信号尽可能的小,等价于SINR接收到其他用户的干扰信号尽可能的小,SLNR的计算公式为:
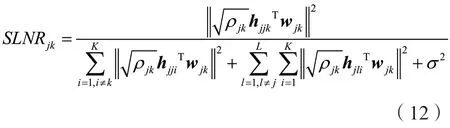
式(12)等效为:
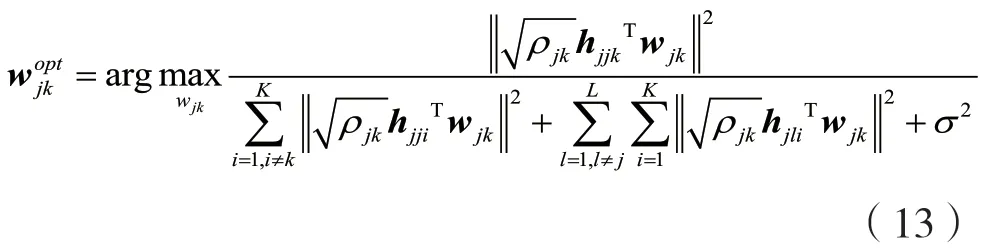
根据参考文献[18]定义:

对上述步骤进行总结:首先经过小区内分组消除干扰预编码,计算得到等效信道矩阵为Hequal=HWgroup-precoding,其中,Wgroup-precoding表示在小区内进行干扰消除的预编码向量组成的矩阵;其次在小区间采用SLNR 预编码进行干扰消除。
2.3 基于人工免疫算法的功率分配
2.3.1 功率分配的优化目标函数
作为智能优化算法之一的人工免疫算法,效仿生物免疫系统,拥有免疫系统的基本特征。该算法通过群体搜索的方式,利用迭代计算得到问题的最优解。与其他智能优化算法对比,其在种群多样性、自适应性、全局收敛性等各方面存在显著的优势。
基于免疫算法对多小区大规模MIMO 系统进行功率分配时,最主要的问题在于构建亲和度函数,一般以功率分配的优化目标函数作为亲和度函数。在传统的计算方法中构建的优化目标函数往往只能够关注到某一个方面,而不能兼顾整体,必然会造成系统性能的损失。因此,为兼顾用户个体和系统整体性能,本文将亲和度函数设计为最大化每小区的频谱效率均值与每小区用户最小频谱效率的乘积,则计算过程可表示为:

其中,小区j中用户k的下行链路频谱效率的计算公式为:

2.3.2 基于人工免疫算法的功率分配求解
基于人工免疫算法的功率分配,将免疫系统中的抗原对应于相应的功率分配问题,所产生的抗体种群对应于功率分配问题对应的可行解,每个抗体在抗体种群之中占据的比重代表浓度,亲和度函数衡量每个抗体与抗原之间的吻合度,将其定义为求解功率分配待优化的目标函数。通过计算每个抗体的亲和度函数值,将选择浓度低、亲和度大的抗体进行免疫操作。免疫操作包括克隆、变异和克隆抑制以及边界条件的判定,其余的抗体将会被更新。
基于人工免疫算法求解功率分配问题的步骤如下:
(1)将功率分配问题对应于抗原,构建如上所述亲和度函数aff。
(2)产生大小为Nk的抗体种群即对应Nk种可行解,且其取值在规定的功率约束条件内。接着对抗体进行定义,每个抗体用K×L维的矩阵表示,矩阵中的任一元素(k,l)即代表为小区l中用户k分配的功率,并计算每个抗体的亲和度函数值。
(3)计算每个抗体浓度,需要先计算抗体之间的相似度为:

式中:abm,abn分别为抗体m和抗体n;θ为相似度阈值。抗体m的浓度的计算方式为:

(4)依据亲和度函数值和浓度值计算抗体激励度,其计算公式为:

式中:α和β均为激励度系数。选择浓度低、亲和度函数值大的抗体进行免疫操作。
(5)对每个抗体基于激励度依照降序进行排序,选择激励度排在前Nk/2 的抗体进行克隆、变异以及克隆抑制,从而得到免疫种群。克隆、变异以及克隆抑制的具体方法如下:
①克隆:对所选择的抗体进行复制,克隆的个数η越多,局部搜索的能力和全局搜索的能力均越强,但如果克隆个数过多,计算量也会随之增加。
②变异:针对复制得到的抗体进行变异操作,使得其亲和度函数值发生突变。这里首先需要设置一个突变的概率pro,进行变异操作时,使用rand()函数先随机产生一个概率。如果rand<pro,则将复制得到的抗体进行变异操作,并且需要进行边界条件处理,使得功率分配的结果满足功率限制边界条件。
③克隆抑制:对经过变异的抗体进行二次选择,选取亲和度函数值高的克隆抗体保存。
(6)随机生成Nk/2 个新的抗体种群,并将其与免疫种群合并,计算新种群中每个抗体的浓度、亲和度函数值和激励度,依照每个抗体的激励度进行排序,重复上述步骤(3)~(6)直至迭代完成。
3 仿真结果分析
3.1 仿真参数设置
在本文所搭建的大规模MIMO 系统中,设置L=4;在每个小区内产生位置随机分布的K=20 个单天线用户,并且与基站的距离r的取值范围为rmin≤r≤rmax,其中,rmin=100 m,rmax=1 000 m。蒙特卡洛仿真103次。仿真参数设置总结如表1 所示。
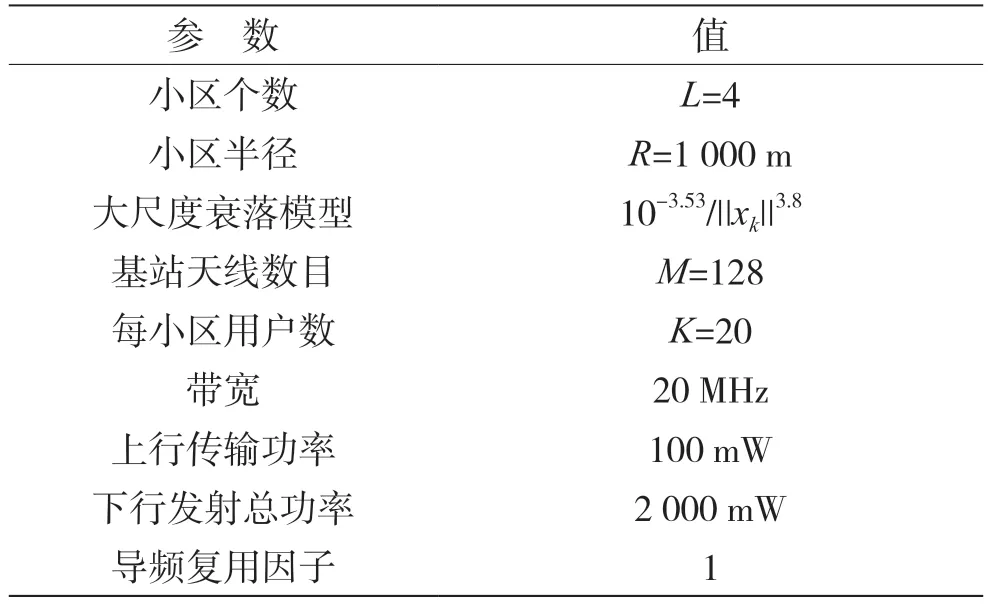
表1 仿真参数
在小区内对用户进行分组时,通过仿真寻优设定阈值ε=10。利用人工免疫算法求最优功率分配的解。本文设定数目Nk=20 个免疫抗体,初代抗体随机产生后,后一代抗体在前一代抗体的基础之上经过选择以及更新获得,且其取值上限Nmax=Pmax,取值下限Nmin=0。免疫代数Gen=300,变异概率pro=0.7,激励度系数分别为α=2 和β=1,邻域范围初值为Ne=0.05×Nmax,相似度阈值θ=5,克隆个数η=10。
3.2 结果分析
3.2.1 系统谱效率分析
采用表1 中的仿真参数,比较了在多小区多用户大规模MIMO 系统中,分别采用MRT、RZF、MMSE、BD、SLNR 和本文所提出的预编码方案,以最大化最小SE 为目标函数,使用二分算法进行功率分配时,各个用户的累积分布函数(Cumulative Distribution Function,CDF)曲线,结果如图2 所示。CDF 曲线描述的是小区中各用户因位置差异导致的不同用户频谱效率取值的变化。选择对比50%的中断概率点(图2 中所示纵坐标0.5 处的横轴虚线),可以直观地看出,采取本文所提出的预编码方案(位于最右侧),可以使得给定任意位置的用户以较大的概率获得更高的频谱效率,其相较于频谱效率最差的MRT 预编码性能大约提升了3.5 倍。而由图2可知,BD、RZF、MMSE 可提供的频谱效率大致相同,除去本文所提预编码方案,SLNR 预编码方案相对较优,其性能相较于MMSE 大约提升了36%,而本文所提算法的性能大概比SLNR 增加了约64%。
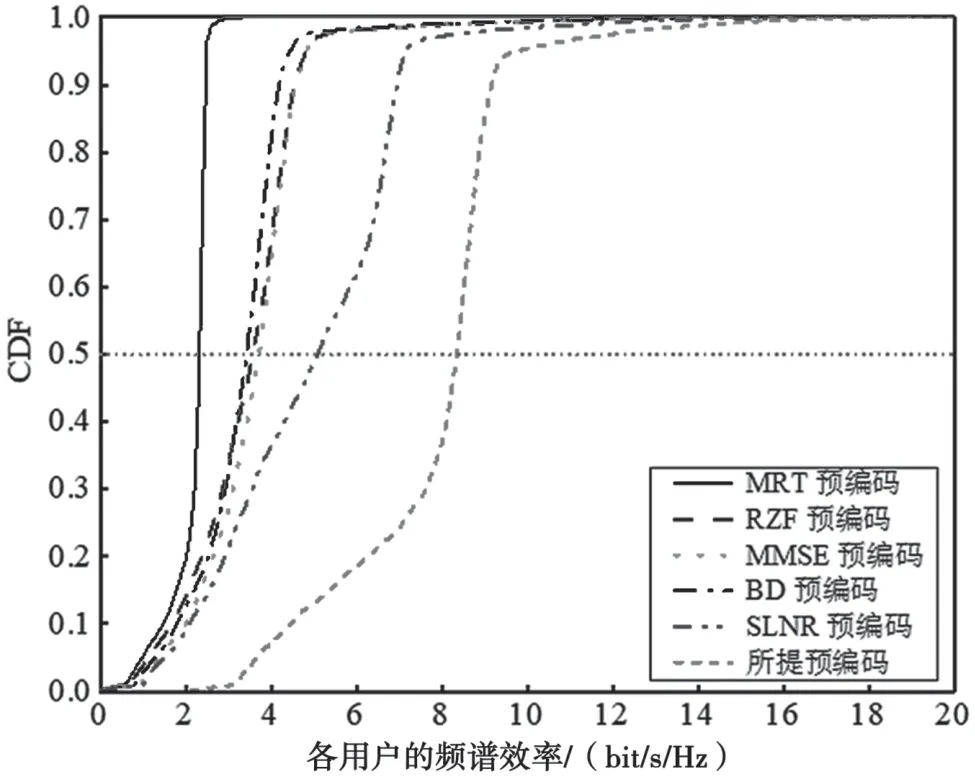
图2 不同预编码方案各个用户的CDF 曲线对比
图3 为基于人工免疫的功率分配算法亲和度进化曲线,其中,横轴代表迭代的次数,纵轴代表目标函数值。由图3 可知,人工免疫算法迭代50 次左右时,功率分配算法基本达到收敛,这表明该算法有较好的收敛性。

图3 人工免疫算法的亲和度进化曲线
图4 为采用人工免疫算法与传统的二分算法时,各个用户的CDF 曲线对比。其中,传统二分算法以最大化最小频谱效率为目标函数,人工免疫算法以调整后的目标函数作为亲和度函数。由图可知,在0~5 bit/s/Hz 区间时,两种方法的差异不明显,这说明用人工免疫算法构建的亲和度函数能够确保最大化最小用户的频谱效率。而在10~ 15 bit/s/Hz区间范围内,因为使用人工免疫算法时对亲和度函数进行了调整,用户明显以较大的概率分布在较高的频谱效率范围内。
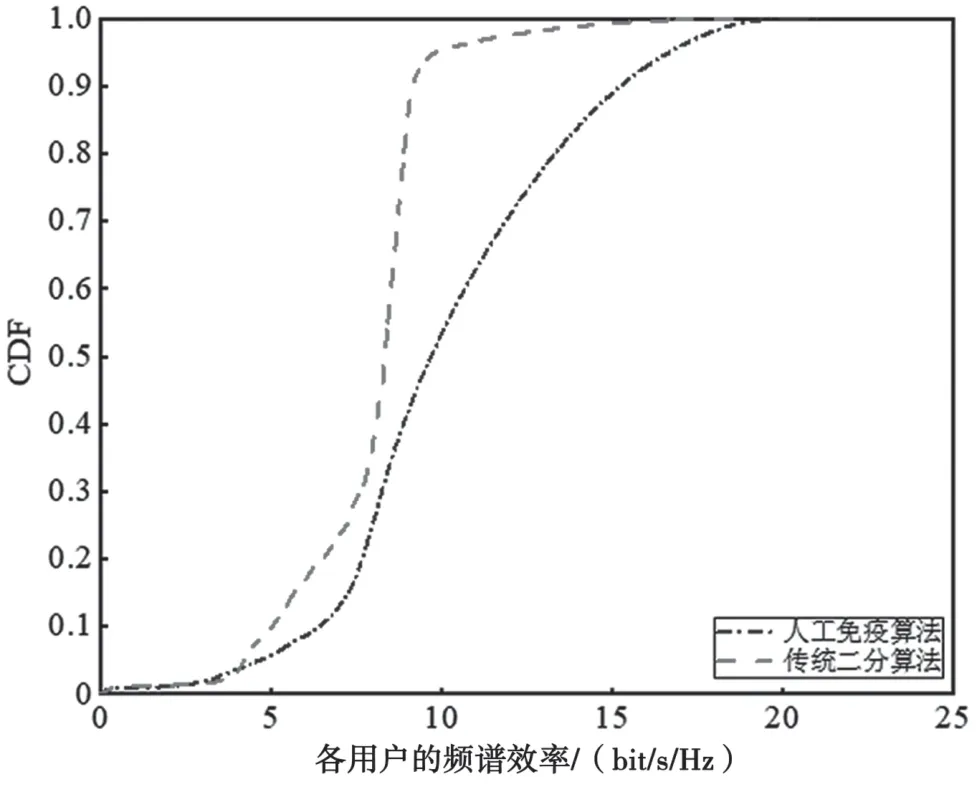
图4 人工免疫算法与二分算法各个用户的CDF 曲线对比
图5 为采用人工免疫算法与传统的二分算法时,用户的平均频谱效率CDF 曲线对比。可以看出,由于对目标函数进行了调整,在构建亲和度函数时考虑到了平均频谱效率,使得用户的平均频谱效率得到提升。

图5 人工免疫算法与二分算法平均频谱效率CDF 曲线对比
3.2.2 计算复杂度分析
进行预编码处理涉及矩阵的运算,不同的预编码方案对应的计算量不同,因此本文通过比较不同方案之间的计算量可实现对不同预编码方案计算复杂度的分析。表2 给出了不同预编码方案的计算复杂度。
由表2 可知,本文所提分级预编码方案的计算复杂度为RZF、BD、SLNR 3 种预编码方案计算复杂度的线性组合,相较于采用单一的预编码方案,计算复杂度略有提升。

表2 不同预编码方案的计算复杂度
3.2.3 运行时间分析
表3 给出了在采用分级预编码方案的前提下,分别基于传统二分算法与人工免疫算法对搭建的模型进行仿真后,得到的算法运行时间。仿真参数:处理器为AMD Ryzen 5 3500U with Radeon Vega Mobile Gfx 主频2.10 GHz,64 位操作系统,内存8.00 GB;软件环境为MATLAB R2019a。得到的运算时间如表3 所示。
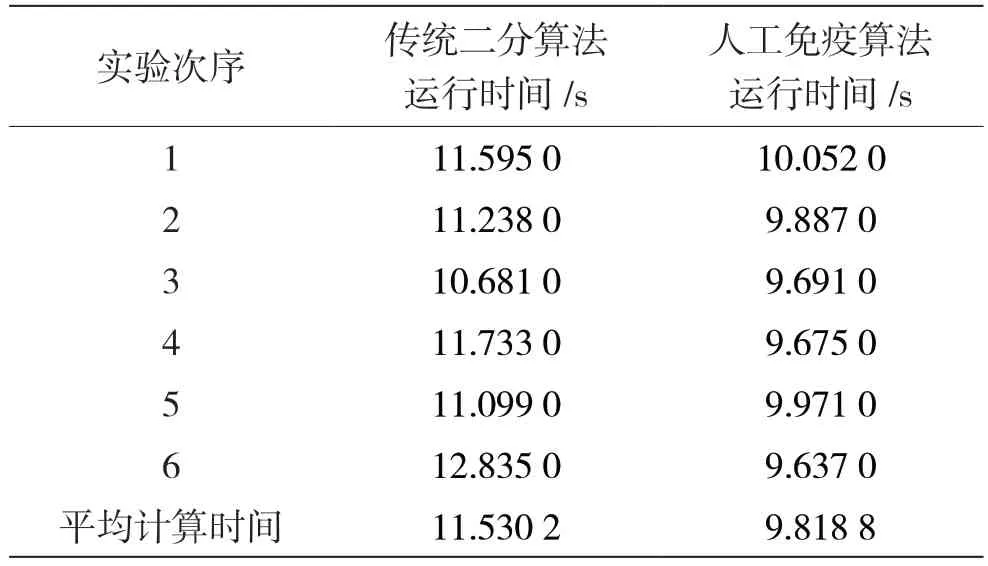
表3 传统二分算法与人工免疫算法运行时间
由表3 可知,人工免疫算法的运行时间低于传统二分算法,传统二分算法的平均计算时间约为11.530 2s,而人工免疫算法的平均计算时间约为9.818 8 s。在算法平均运行时间上,人工免疫算法大约比传统二分算法降低了17%。
4 结语
本文针对多小区大规模MIMO 系统功率分配的问题进行了研究,提出了分级预编码方案和基于人工免疫算法的功率分配方法。大规模MIMO 系统由于其在基站端布置的天线数量大幅度增加,并且同时服务于很多用户,因此不可避免地存在严重的干扰。为了消除这种干扰的影响,在进行功率分配的同时,本文首先提出了分级预编码方案。该方法将小区内用户依据位置信息进行分组;再根据分组结果,对组内用户采取RZF 预编码;然后对分组内所有用户的信道矩阵求均值,将其视为一个独立的用户,在组间与未被分组的独立用户间利用BD 预编码的方法消除干扰;最后基于SLNR 预编码进一步消除小区间ICI 干扰以及残存MUI 干扰。其次,利用人工免疫算法并行处理和强大的全局搜索能力,本文提出了基于人工免疫算法的功率分配方法,为兼顾用户个体和系统整体性能,将亲和度函数设计为最大化每小区的频谱效率均值与每小区用户最小频谱效率的乘积。实验结果表明,采取分级预编码方案,再利用人工免疫算法去求解功率分配,能够使得用户个体和系统整体的频谱效率均得到提升。
