基于深度学习的吸烟检测研究
2022-09-28李祥祥李晓华
李祥祥,李晓华,石 刚
(新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
吸烟有害身体健康,在公共场所吸烟会对他人的身体健康造成危害.吸烟会引发肺癌、喉癌、功能丧失等疾病,全球每年因烟草致死人数高达800万人.在加油站、飞机场、办公室、化工厂、森林等地吸烟极易引起火灾,造成重大经济损失和人员伤亡.为了他人生命和财产健康着想,禁止在公共场所吸烟已经成为所有人的道德规范和行为准则,国家也已采取很多措施严禁公共场所吸烟.
传统的吸烟检测方案主要包含3种:烟雾传感器、红外成像仪、可穿戴设备.但这3种方案都有局限性,烟草的烟雾稀薄且极容易逸散,在通风场所和占地很大的室内场所中烟雾浓度低,很难达到烟雾传感器的检测阈值;红外成像仪通过感知物体的温度进行吸烟检测,但公共场所环境复杂、人员众多,容易造成误检情况;可穿戴设备通过各种传感器检测佩戴人员在吸烟时的运动和生理特征进行吸烟检测,该方案需要被检测人员佩戴可穿戴设备,难以普及.
除了使用各种设备,研究人员还研究了针对监控视频的吸烟检测方案.传统图像处理算法可以很好的应用于吸烟检测任务,该方案的检测过程共分4步:(1)图像预处理.在目标检测算法中,图像质量的好坏直接影响检测的精度.通过几何变换、灰度化、图像增强等方法的处理,修正图像的角度、减少噪声、突出重要特征.(2)候选框的提取.候选框主要用于待检测目标的定位.通过设定不同大小和步长的滑动窗口,由左至右、由上至下滑动提取候选框.(3)特征提取.在候选框中提取预先设定的特征.方向梯度直方图[1](Histogram of Oriented Gradient,HOG)通过将图像分为多个小块(如8×8像素),计算每个小块的梯度分布直方图,每4个小块得到一个特征向量.Haar通过积分图获取图像的边缘特征、线性特征和点特征.尺度不变特征变换[2](Scale-invariant feature transform,SIFT)提取检测目标的关键点,通过关键点计算特征方向和特征向量.(4)分类.通过Adaboost[3]、支持向量机[4](SVM)、决策树(Decision Tree)等分类器,对滑动窗口中提取的特征进行进一步处理和分类.
传统图像处理算法存在一定的缺陷.随着硬件设备计算性能的提高和深度学习神经网络各种算法的不断完善,使用神经网络算法完成目标检测任务开始成为主流.特别是在2012年ILSVRC大赛中,AlexNet[5]取得第一名的好成绩,力压一众传统目标检测算法.其后神经网络算法不断发展,并凭借超高的检测精度和分类性能在各个领域不断取得突破,如人脸识别、目标检测、手势识别、车辆识别、人体姿态识别等.
本文采用神经网络算法,检测吸烟者的人脸和烟支,对比两者的位置关系判定是否存在吸烟行为.为了达到实时检测的目的,参考单阶段目标检测算法,利用改进后残差结构[6](Residual Block)、跨阶段局部网络[7](CSPNet)、注意力机制(Attention)构造主干网络,将更多小目标的特征传入更深的卷积层,解决特征丢失问题;对主干网络输出的多层次特征图进行特征融合,提高各特征图信息的丰富程度,增强了小目标的检测精度;改进了激活函数、损失函数、归一化方法、融合图像的上下文信息,提高了模型的鲁棒性.
1 难点及解决方案
1.1 实时检测
深度学习神经网络算法进行图像处理和目标检测任务时,通常卷积网络的层数会堆叠几十乃至上百层.主要是因为深度学习目标检测任务十分复杂,训练图像数量极大、背景复杂、检测目标尺寸不一,为了提高对检测目标的表征能力和泛化能力,通过加深卷积网络的层数的方式提高模型的学习能力,让复杂的目标检测任务成为可能.
1.1.1 单阶段目标检测算法
深度学习目标检测算法发展多年,目前主要有两种检测思路:双阶段目标检测算法和单阶段目标检测算法.
双阶段目标检测算法采用目标定位(候选框提取)和目标分类分离的策略,主要算法包含RCNN[8]、Faster R-CNN、Mask R-CNN[9]、Cascade RCNN[10]等.其目标定位算法是在传统目标检测算法的基础上发展而来的,早期的算法还是采用滑动窗口方式,之后为了提高模型的检测速度,提出了选择性搜索(Selective Search)和区域建议网络(Region Proposal Network,RPN)的方案.选择性搜索的实现思路是首先将图像分割成很多的小块,然后使用贪心策略计算每两个相邻区域的相似度,合并最相似的两块,直到最终只剩下一块完整的图片.在合并的过程中,首先合并最小的图像,将合并的图像块保存起来并设置权重,得到图像的分层表示.区域建议网络的实现思路是首先预设9个大小不一的候选窗口,这些候选窗口也叫锚(anchors),在输入图像上设置若干锚点,每个锚点设置9个锚,让锚与真实框进行对比后进行平移和缩放,在经过Softmax排序和非极大值抑制(Non-Maximum Suppression,NMS)后得到最有可能的候选框.
选择性搜索方案主要应用于R-CNN、Fast R-CNN等,区域建议网络主要应用于Faster R-CNN、Mask R-CNN等.综合上述方案提出的候选框和主干网络输出的特征图,经过ROI池化后生成候选特征图,最后经过全连接层的处理,完成目标检测算法的定位和分类任务.单阶段目标检测算法将定位和分类问题转换为回归问题,利用锚的思想,在主干网络提取的特征图上选出多个锚框,针对每个锚框进行回归定位和分类,最后使用非极大值抑制得到最优预测结果.单阶段目标检测算法主要包含SSD[11]、YOLO、CornerNet[12]、CenterNet等.双阶段方案拥有更高的检测精度,但检测速度较慢;单阶段方案检测精度稍低,但检测速度很快.为了达到实时检测的目标,本文采用单阶段方案.
1.1.2 深度可分离卷积
卷积神经网络(Convolutional Neural Networks,CNN)是深度学习视觉领域的代表算法,卷积层是卷积神经网络的主要构成部分,减少卷积层的权重参数和计算量就可以在很大程度上提高目标检测速度.
大多数卷积神经网络采用常规卷积,如图1(a)所示,卷积核(Kernel Filters)的通道数与输入特征图(Feature Maps)的通道数(Channels)保持一致,卷积核的宽(width)和高(height)一般为3×3 (一些卷积层中可能使用5×5、7×7,甚至更大),卷积核的个数与输出特征图的通道数保持一致.常规卷积所涉及的权重参数量大,耗费计算资源多.为了提高检测速度,本文使用深度可分离卷积作为本文模型的基础卷积,大量实验证明深度可分离卷积的检测精度与常规卷积类似但检测速度有所提高.深度可分离卷积[13](Depthwise separable Convolution)由深度卷积(Depthwise Convolution,DW)和逐点卷积(Pointwise Convolution,PW)组成.深度卷积如图1(b)所示,卷积核的通道数固定为1,卷积核的个数与输入特征图的通道数一致.为了输出需要的特征图,使用逐点卷积进一步操作.逐点卷积如图1(c)所示,卷积核的通道数与输入特征保持一致,卷积核的宽和高固定为1,卷积核的个数与输出特征图的通道数保持一致.
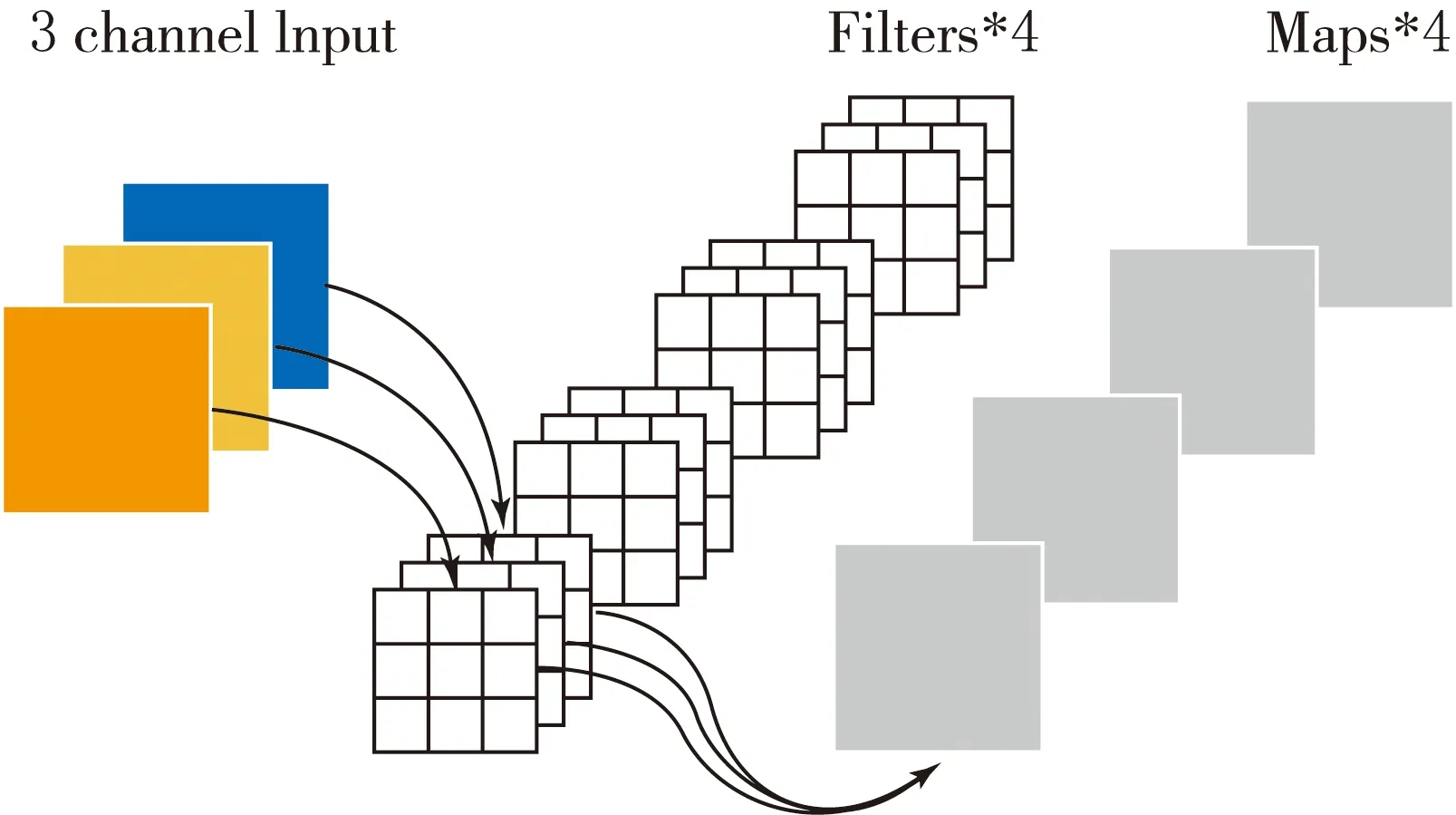
(a)常规卷积
这里引入浮点运算数(Floating Point Operations,FLOPs)和参数量(Params)的概念来衡量模型的复杂度.设输入特征图的尺度为(Hin,Win,Cin),卷积层处理后的输出特征图的尺度为(Hout,Wout,Cout).其中H代表特征图的高,W代表特征图的宽,C代表特征图的通道数.卷积核的高和宽总是一样大小,设为K.浮点运算数可以用来衡量模型的计算量,其计算公式为
FLOPs=(Cin×2×K×K)×
Hout×Wout×Cout.
(1)
参数量的计算公式为
Params=(Cin×K×K+1)×Cout.
(2)
当输入特征图的通道数为3,卷积核的宽和高均为3,输出特征图尺寸为64×64×4时,常规卷积和深度可分离卷积的计算量和权重参数量如表1所示,深度可分离卷积的参数量和计算量对比常规卷积均有所降低.

表1 两种卷积的参数量和计算量
1.2 小目标检测
吸烟检测属于小目标检测任务.小目标物体有两种定义方式,一种是待检测目标的长宽占原图像的10% (相对尺寸),另一种是待检测目标小于32×32像素(绝对尺寸).小目标检测任务一直是深度学习卷积网络模型的一个难题,小目标物体分辨率低、容易受到抖动的干扰,而且图像模糊,又因为小目标本身所占图像像素低,携带信息很少,没有明显的特征.且小目标物体容易受到噪声、遮挡等因素的干扰,图像增强、去噪声的方法也很难恢复原本特征.
1.2.1 主干网络设计
目前的目标检测模型的主干(backbone)网络部分通常会进行多次下采样处理,导致小目标在特征图中的尺寸基本上只有个位数的像素大小,且小目标特征在传入更深的网络层时特征丢失严重,因此目标分类器对小目标的分类效果极差.本文设计的主干网络在力求降低网络的参数量和计算量的同时,将更多的小目标特征送入更深的网络层.
目标检测模型通常由3个部分组成:主干网络(backbone)、颈部(neck)和检测头(head).主干网络是目标检测模型网络层数最多,特征提取能力最强的结构,主干网络提取的目标特征直接影响到模型的检测效果.神经网络的检测效果和神经网络的层数有着很大的关系,通常层数越多检测精度就越高,相应的训练难度也就越高.并且当网络层数达到一定程度后,网络会达到饱和状态,即达到了检测的最好效果.再增加网络层数,检测效果会下降,训练损失值开始增加,这一现象被称为退化(degradation).为解决退化问题,He等[6]提出残差网络.残差网络由一系列可重复利用的残差块(见图2a)组成,残差块分为两个部分,直接映射(左分支)和残差部分(右分支).直接映射分支不做任何处理.残差部分一般由2~3个卷积操作、批处理和激活函数组成.之后残差部分和直接映射相加合并,再经过一次ReLU激活函数的处理得到输出结果.实验表明,残差网络很好地解决了深度神经网络的退化问题,在同等层数的网络中,残差网络收敛速度更快,且在去除个别网络层后,残差网络的性能表现不会有大的变化.
本文对残差块进行了改进(见图2b).左分支的直接映射保持不变.将右分支原本的常规卷积用深度可分离卷积替换(深度卷积+逐点卷积),达到减少模型的参数量和计算量的目的.激活函数由ReLU函数替换为Mish函数,Mish函数也属于ReLU 系列,只是在正负值交界处增加了一个平滑的过渡曲线以保证模型拥有更好的泛化能力.每个深度可分离卷积输出的特征图均使用批归一化处理,以约束特征权重的数值范围,避免梯度消失、梯度爆炸、过拟合等问题.本文称改进后的残差块为可分离残差块,可分离残差块是可复用结构,可以添加到主干网络的任意位置.本文利用多个可分离残差块组成残差模块(Residual module).如图3(a)所示,采用CSPNet(Cross Stage Partial Network,跨阶段局部网络)的思想,将输入特征拆分成两部分,每部分拥有输入特征的一半通道数.左分支的特征不做处理,右分支的特征经过多个可分离残差块的处理(可根据需要调节数目),最后对2个分支的特征进行拼接,得到输出特征.
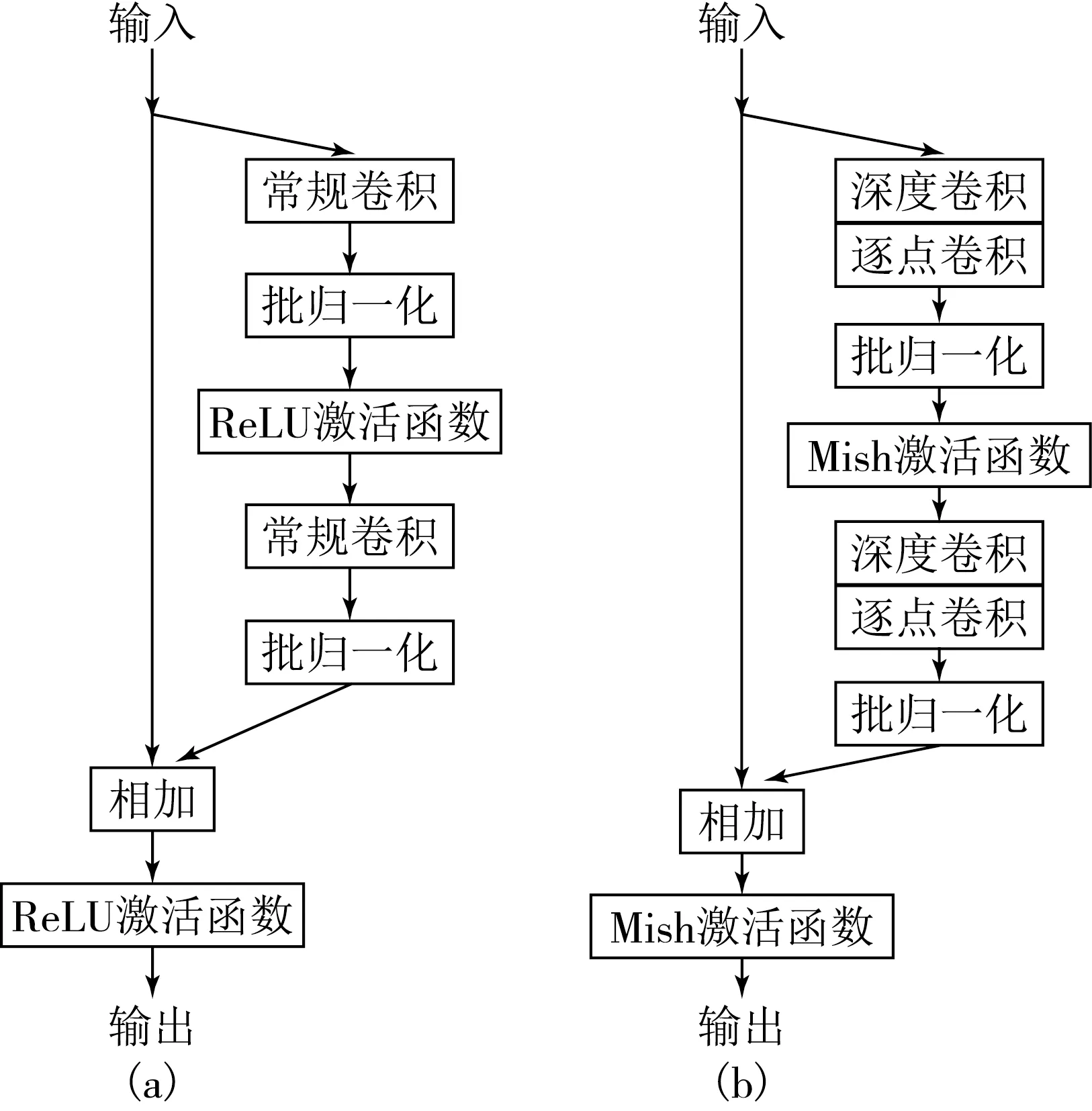
图2 残差块(a)和改进的可分离残差块(b)框图
本文设计的可分离残差块和残差模块都遵循一个原则:将浅层的特征图尽可能传递到更深的卷积层中.这样做有很多优点,首先是避免了退化问题.要想获得更好的目标检测效果,模型的卷积层数必须很深.当卷积层数超过饱和层数之后,特征学习能力直线下降.可分离残差块和残差模块中的CSP结构将浅层的优秀特征直接传递到深层,优化了深层的特征学习情况.更加重要的优点是避免了小目标物体特征在进入更深的卷积层时的特征丢失问题,能有效提高小目标物体的检测精度.
卷积网络经过一系列的卷积和池化操作得到各种尺度的特征图,但特征图中的数据对于检测效果的贡献程度不同.为了强化贡献度高的特征数据削弱贡献度低的特征数据,引入注意力机制,根据贡献度为特征图加权.注意力机制最先在机器翻译领域取得了不错的效果,而后在视觉领域也开始发力.2017年,SENet[14](squeeze and excitation networks)设计了一种可重用通道注意力模块,对输入特征图进行压缩(squeeze)和激发(excitation)操作获得每个通道权重参数,并将加权后的特征图作为输出.该注意力模块能有效提高模型的检测性能.2018年,CBAM[15](Convolutional Block Attention Module)注意力模块结合特征图的通道和空间注意力特征,进一步提高了模型检测性能.
本文在CBAM的基础上略作改进设计注意力模块,如图3(b)所示.输入特征在注意力模块中分成2个支路,一个支路使用通道注意力处理得到通道权重,另一个支路不做处理,2个支路结果相乘得到通道加权特征图;通道加权特征图又分为2个支路,一个支路使用空间注意力处理得到空间权重,另一个支路不做处理,2个支路结果相乘得到空间加权特征图并输出.设特征图的尺寸为H(特征图的高)×W(特征图的宽)×C(特征图的通道数),通道注意力分别使用全局最大池化和全局平均池化得到2个1×1×C的特征,之后为了更好地拟合通道间复杂的相关性,使用共享多层网络(全连接层+Mish激活函数+全连接层)进行处理得到2个1×1×C的特征,相加并进行Sigmoid激活后得到一个1×1×C的通道权重特征,与H×W×C的输入特征图相乘后得到通道加权特征图.空间注意力分别使用最大池化和平均池化得到2个H×W×1的特征,按照通道拼接为一个H×W×2的特征,经过卷积和Sigmoid函数激活后得到一个H×W×1的空间权重特征,与H×W×C的输入特征图相乘后得到空间加权特征图.本文改进的注意力机制可以在通道和空间2个尺度衡量特征图的贡献程度,能有效加强小目标特征的学习能力,提高检测精度.
(a)残差模块 (b)注意力模块 (c)主干网络
主干网络的结构如图3(c)所示,输入图像首先使用2个卷积层进行预处理,减少特征图的宽高,增加了通道数.之后使用4组残差模块和注意力模块的组合,提取不同层次的特征图.残差模块中卷积层数多,用于提取待检测目标的特征信息.注意力模块评价残差模块输出特征图的贡献度,输出加权特征图.该主干网络在降低参数量和计算量基础上,能够提取更多的小目标特征,保证了小目标实时检测的需求.
1.2.2 特征融合策略
感受野(receptive field)用来表示网络内部不同卷积层的输出特征图中每个元素在输入图像上的映射区域大小.感受野越小则能接触到的原始图像越小,特征图更趋向于表达目标的局部细节特征,包括纹理、边缘、颜色、形状等,可以很好地表达小目标物体的特征;而感受野越大则能接触到的原始图像越大,会将小目标周围的背景纳入学习范围,特征图更趋向于表达更加抽象的全局特征,丧失了小目标的特征,适用于更大物体的目标检测.
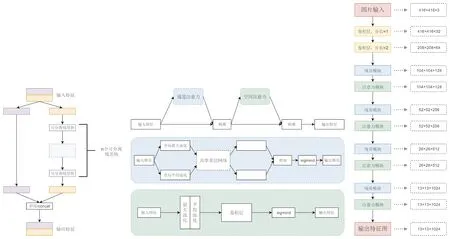
本文目标检测模型的整体结构如图4所示,主干网络在注意力模块处理后输出3个层次的特征,较浅层输出的特征图拥有较小的感受野,适合小目标检测;层数越深其感受野越大,更加适合大目标检测.为了进一步提高小目标的检测精度,引入PAN[16]网络(如图4的颈部所示),融合主干网络多层次的输出特征,结合浅层的细节信息和深层的语义信息,提高小目标的定位和分类效果.特征融合对于各个尺度的目标特征都有一定程度的增强,之后从大中小3个尺度对图像进行目标检测.
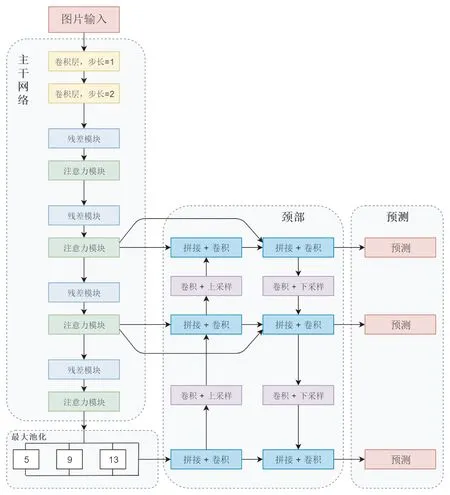
图4 目标检测模型整体结构
本文构建的目标检测模型使用深度可分离卷积代替常规卷积,如表2所示.深度可分离卷积方案在模型大小、参数量和计算量3个尺度都有明显优化.

表2 不同卷积组成模型对比
2 模型优化策略
神经网络模型除了卷积层和池化层的特征提取部分,还包括了一些仅增加少量推理成本的结构,可以起到修正特征数据、提高模型学习能力的作用.首先是图像增强技术,不对模型进行改动,只对训练图像进行裁剪、缩放、旋转、模拟遮挡等操作,提高图像环境的复杂度和图像数量,使模型可以适应更加复杂的环境,提高泛化能力.
激活函数通过激活特征图中符合条件的特征数据,使模型拥有了非线性建模的能力,可以更好地拟合复杂的检测任务.但sigmoid和tanh 函数在反向传导的过程中会导致梯度消失问题.ReLU 函数保留了正值的梯度,将负值转化为0,解决了梯度消失问题,且模型能够更快收敛.但是也导致了“死亡神经元”问题,输入持续为负的神经元激活值总为0.批归一化将每个卷积层的输出特征数据归一化为均值为0、方差为1的数据,并根据训练得到平移因子和尺度因子对数据进行一定的处理.批归一化解决了梯度消失、梯度爆炸的问题;能有效提高收敛速度;拥有正则化的特点,减少过拟合.本文构建的目标检测模型主要使用Mish激活函数,公式为
Mish=x·tanh(ln(1+ex)).
(3)
Mish函数属于ReLU系列激活函数,但在正负值的交界处有一个弧度,过渡得更加平滑(见图5中虚线).这使得Mish函数拥有更加平滑的梯度(见图5中实线),泛化能力更好.且Mish对较小的负值进行激活,缓解了部分神经元永远无法激活的问题.
损失函数是衡量目标检测模型检测效果好坏的标准,将模型前向传播的预测结果和真实标签进行对比计算,得到损失值判定检测效果.根据损失反向传播优化学习模型的特征信息.早期损失函数均方误差(MSE)对预测框中心点坐标和宽高信息分别对待,没有考虑到整体的关系.使用交并比(IoU)计算预测框和真实框的重合程度,有效提高了目标检测的效果.本文使用由IoU 发展而来的CIoU损失函数.CIoU比IoU 多考虑了一些影响预测效果的因素,如重叠程度、目标尺寸、惩罚项、预测框和真实框中心点之间的距离.CIoU的计算公式为:
(4)
(5)
其中:ρ2(b,bgt)表示真实框和预测框中心点的欧式距离;c代表预测框和真实框对角线的距离;α和ν是添加的惩罚项,其计算公式如为:
(6)
(7)
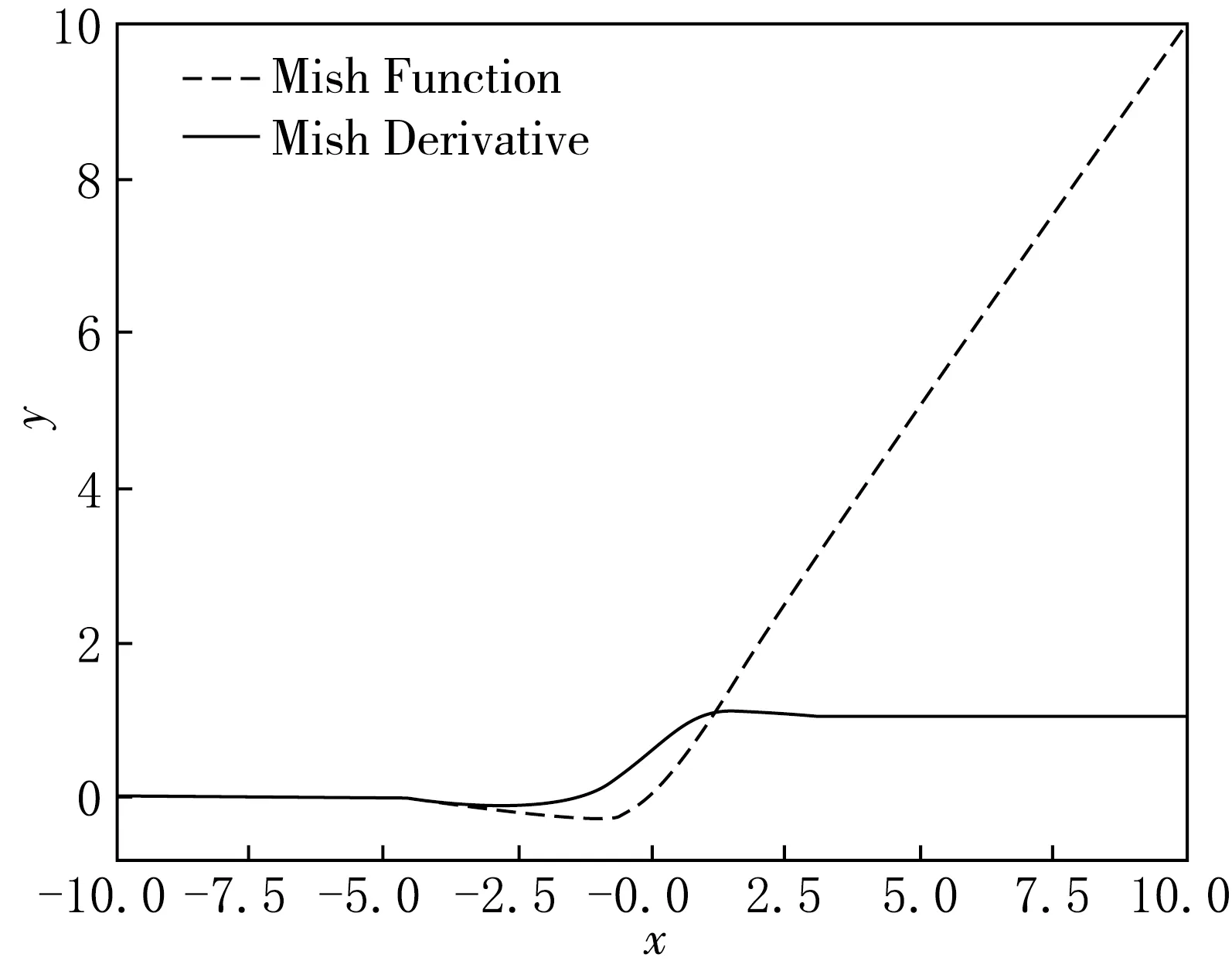
图5 Mish函数及其导数曲线
3 实验结果及分析
本文使用pytorch深度学习框架完成相关代码的编写,使用NVIDIA RTX 2080Ti显卡进行训练,使用NVIDIA GTX 1050Ti完成测试工作,对应操作系统分别为Ubuntu18和Windows10,配置CUDA10和CUDNN7.5工具.
3.1 数据集
由于吸烟检测任务没有公开的数据集,本文使用自己构建的吸烟数据集完成吸烟检测任务.从互联网上爬取的有关吸烟的图片和视频,同时自己录制吸烟视频片段.抽取视频中有吸烟行为的关键帧,与网络中吸烟图片结合组成本文数据集.数据集共4 893张图片,使用LabelImg工具进行标注,标注内容包括人的脸部和烟支的位置,其中80%用于训练,20%用于测试.
3.2 实验过程
使用本文构建的模型针对本文构建的数据集进行训练(如图6所示),得到吸烟检测模型.将监控视频作为输入,吸烟检测模型读取视频中每一帧图像,用吸烟检测模型先针对人的脸部进行检测,若图像中不存在人的脸部则判断不存在吸烟行为;若存在则针对烟支进行检测,只有当检测到烟支且烟支位置与人的脸部位置重合,同时烟支面积小于脸部面积1/3 时,认定存在吸烟行为.
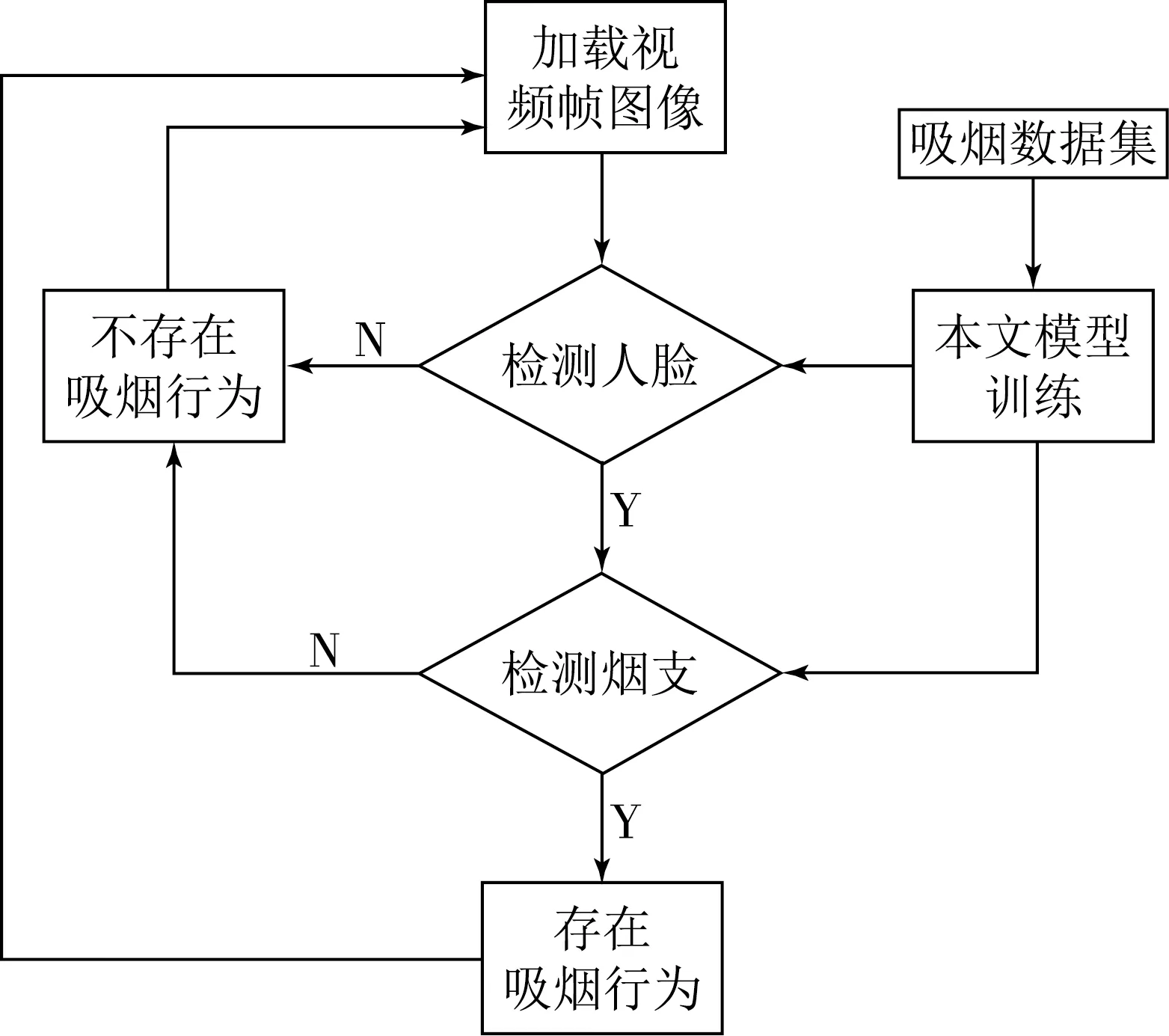
图6 吸烟检测流程
3.3 实验结果
本文模型在Ubuntu18系统上的RTX2080Ti上进行训练,共进行1 000次迭代,每个批次16张图片,使用余弦退火衰减学习率,Adam优化函数加快收敛速度.图7(a)和图7(b) 分别表示模型在训练过程中损失值的变化过程及吸烟检测的mAP面积.
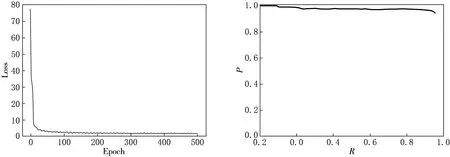
(a)损失曲线 (b)AP
本文算法与Faster RCNN、SSD、YOLOv3、YOLOv4等模型在本文数据集上进行目标检测实验.验证均使用GTX1050Ti显卡,如表3所示,本文算法在检测速度(FPS)和检测精度(mAP)都比其他算法优秀.在实际场景中的吸烟检测效果如图8所示.
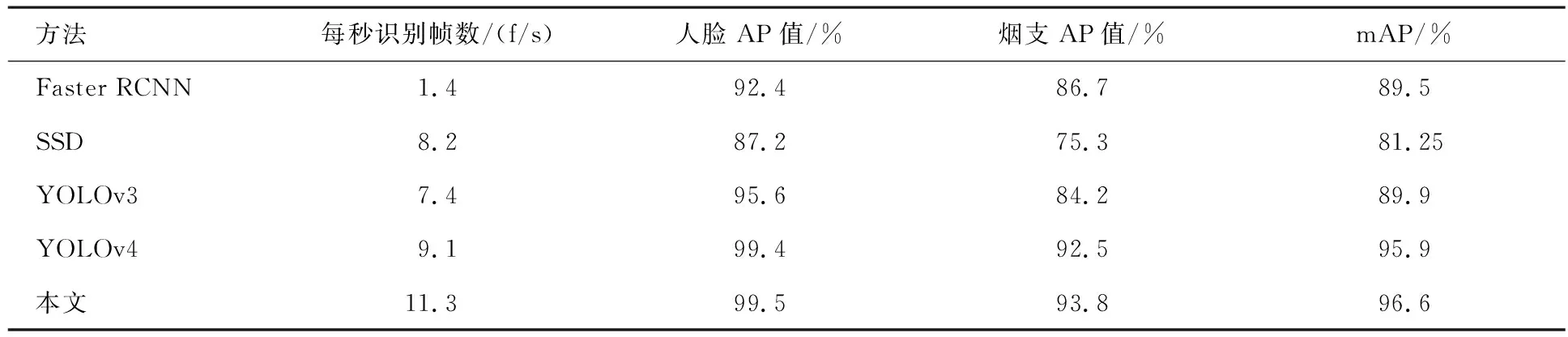
表3 不同算法在本文数据集中的表现

(a)结果1-脸部 (b)结果1-脸部-烟支 (c)结果2-脸部 (d)结果2-脸部-烟支
为了进一步验证所构建的目标检测模型对于小目标的检测能力,本文在公开数据集AU-AIR2019[17]上进行训练和测试.AU-AIR2019数据集是使用无人机针对户外车辆和人员拍摄的视频,经过筛选取出32 823个关键帧图像构成的数据集.共包含汽车(car)、厢式货车(van)、敞篷火车(truck)、人(human)、拖车(trailer)、自行车(bicycle)、公共汽车(bus)、摩托车(motorbike)等8个类别.本文检测结果与基线(YOLOv3-Tiny、MobileNet-SSDLite)的对比如表4所示.本文算法在小目标物体检测任务中具有很好的效果.检测效果如图9所示.

表4 不同算法在AU-AIR数据集中的表现

(a)检测结果1 (b)检测结果2
4 结束语
为配合公共场所禁烟,本文构建小目标检测模型,针对监控图像进行吸烟行为检测.实验表明,针对烟支这种小目标的检测拥有很好的效果.模型主要从检测的实时性和准确性两个方面出发,在保持且略有增加准确性的基础上,有效提高检测速度.为了实现检测的实时性,本文采用单阶段目标检测方案,并提出利用深度可分离卷积代替常规卷积作为本文基础卷积层,减少了模型的参数量和计算量,提高了检测效率.在提高准确性方面,改进残差网络和CSP 网络,将浅层的局部特征传递到更深层,避免了小目标特征丢失的问题,可以使用更深的网络层;融合浅层的局部特征和深层的全局特征,提高小目标检测效果.为了提高模型的泛化能力和鲁棒性,采用Mish激活函数获取更加光滑的梯度,采用CIoU 提高边界框回归的精度,采用批归一化提高模型的泛化能力,采用注意力机制衡量特征图每个尺度的贡献度.在自制吸烟数据集中有很好的表现,但受限于自制数据集图像数量较少和背景环境单一,在实际应用环境中效果较弱,需要后期收集更多、环境因素更复杂的吸烟数据集,增加模型对复杂环境的泛化能力.
