基于YOLOv5深度学习模型的动态靶标识别跟踪方法
2022-09-20李福禄段修生
李福禄, 吉 喆, 段修生
(1.石家庄铁道大学 机械工程学院,河北 石家庄 050043;2.河北交通职业技术学院 电气与信息工程系,河北 石家庄 050035)
0 引言
身管靶标位置识别与跟踪作为身管位姿解算的先决条件,其识别效果和动态跟踪精度决定了身管位姿解算的最终精度。实际情况中,为了保证身管靶标的识别效果和跟踪精度,往往选取棋盘标志物、圆形标志物等形状规则的物体作为身管靶标。近些年有诸多学者对此开展了一系列研究,苏建东等[1]提出一种基于单目视觉的平面靶标姿态测量模型,但动态跟踪识别效果不理想,存在一定的局限性。齐寰宇等[2]提出火炮身管指向测量方法,但由于靶标识别算法采用霍夫变换检测原理,在靶标识别精度满足的同时,动态跟踪相对滞后。另外还有一些学者采用CCD、经纬仪、全站仪、激光跟踪仪等方法,方法相对繁琐且动态跟踪精度不高[3-8]。
随着近些年基于深度学习的图像处理与目标识别技术的发展,越来越多的领域将深度学习技术与计算机视觉技术进行融合,从而达到更好的机器识别效果。尹靖涵等[8]提出了一种基于深度学习的交通标志识别模型[9],将计算机视觉与深度学习算法进行融合,有效地解决了雾霾、雨雪等恶劣天气下小型交通标志识别精度低、漏检严重的问题。其与实际靶标图像提取时情况相近,需通过单目摄像机采集不同姿态下动态身管靶标数据,因靶标相对较小,且单目视觉系统采集精度受目标动态变化影响较大[9-10]。受其启发,提出一种基于YOLOv5深度学习算法的动态身管靶标识别跟踪方法。经过实验验证,基于该方法的身管靶标实时识别跟踪效果良好。
1 YOLOv5网络模型搭建
如图1所示,YOLOv5包括:Input(输入端)、Backbone(主干网络)、Neck(颈部网络)基本模块。

图1 YOLOv5网络架构与组件图
(1)Input模块。Input端包括Mosaic数据增强、自适应锚框计算、图片尺寸处理3部分。Mosaic数据增强:通过对4张样本图像进行随机缩放、随机裁剪、随机排布的方式进行拼接,丰富了样本图像的细节数据。自适应锚框计算:在YOLOv5模型训练前,需要预先设定初始锚框,然后根据初始锚框预测输出锚框,通过计算对比输出锚框与真实锚框的差值来更新模型网络参数。通过增加自适应锚框计算代码改善了以往锚框值单独计算存在训练结果不优的情况,对样本图片进行尺寸处理,保证所有样本的输入尺寸统一。
(2)Backbone。Backbone主要由Focus、Bottleneck CSP模块构成。Focus负责把数据切分为4份,每份数据都是相当于2倍下采样得到的,然后在channel维度进行拼接,最后进行卷积操作。Bottleneck CSP通过对基础层的特征映射图进行复制、dense block处理等操作,将基础层特征图进行分离,在很大程度上解决了梯度消失带来的影响,并且能够实现特征的传播和复用,降低了网络模型的参数冗余,提高了模型计算速度和识别准确率。
(3)Neck。YOLOv5的Neck模块应用了Path-Aggregation Network路径聚合网络(Pannet),如图2所示,在从上到下的金字塔网络中(FPN),通过上采样操作处理信息传递过程得到预测特征图。

图2 路径聚合网络Path-Aggregation Network
Pannet是基于Mask R-CNN和FPN搭建的,增强了信息传递效能。通过优化Pannet特征提取器的FPN结构,改善了特征层自上而下的传递方式。在每个路径中,都以前一级的特征映射作为当前路径的输入,并采用卷积的方式进行处理。然后将特征输出送入FPN结构的特征图中,给下层结构提供输入。同时,以自适应特征池化(adaptive feature pooling)方法,重现特征层和候选区的中断信息,并将其合并以防分配混乱。
2 损失函数对比优化
损失函数包括:分类损失(classification loss)用来预测模型分类误差,定位损失(localization loss)用来预测边界框与GT之间的误差,置信度损失(confidence loss),用来预测锚框的目标性[11]。为了选择合适的损失函数,对YOLO常用的集中损失函数进行了对比分析。
图3为基于IOU、GIOU、DIOU识别精度对比,使用3种损失函数下的区别,尤其是当目标锚框包括预测框时,DIOU可以更好地区分不同情况的差异。
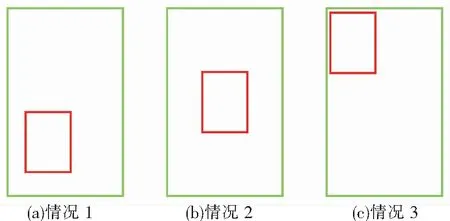
图3 目标锚框包括预测框的3种情况
从表1可以看出,基于IOU和GIOU的损失函数,模型无法区分3种情况,基于DIOU损失函数的网络模型可以区分出。图4、图5为基于以上3种损失函数模型收敛速度对比,可以看出,相对于GIOU作为损失函数,DIOU有着更加优秀的收敛速度。

表1 3种情况下损失函数指数
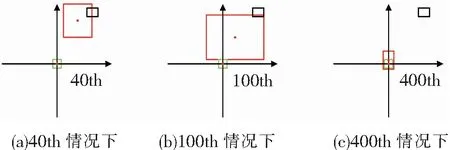
图4 以GIOU作为损失函数的收敛情况

图5 以DIOU作为损失函数的收敛情况
YOLOv5采用二元交叉熵损失函数计算类别概率和目标置信度得分的损失,并且使用CIOU_Loss作为bounding box回归的损失。CIOU在DIOU的基础上增加了2个参数
(1)
式中,v为锚框宽度和高度的比例混合度。
(2)
(3)
如果进一步对CIOU进行优化,需要进行以下操作
(4)
(5)
式中,w、h属于[0,1],为了避免梯度爆炸造成计算量大幅增加的情况,一般令h/w2+h2=1。
对IOU、GIOU、CIOU作为损失函数的回归情况进行对比,如图6所示。
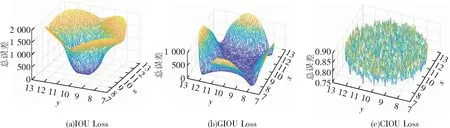
图6 回归情况对比
DIOU Loss虽然比GIOU Loss和CIOU Loss具有更快的收敛速度,但CIOU Loss考虑的因素更多,能够更充分地描述锚框的回归。
3 模型训练
3.1 制作数据集
选取MAKE SENSE环境制作数据集,首先将需要的样本数据集导入MAKE SENSE环境,并精准框选出线性靶标各个标识圆的位置,最终得到带有标识圆位置信息的labels文件。
在labels文件中从左到右,每一列分别代表目标类别,x_center、y_center、宽度和高度[12],由于实际情况中只专注于身管靶标的跟踪识别,所以只需设置一类记为0。图7所示的靶标位置示意了YOLOv5的labels标注文件所需要的目标位置信息,其中图像的宽度记为width,高度记为height,目标的左上角坐标记为(xmin,ymin),目标右下角坐标记为(xmax,ymax),目标中心坐标记为(x_center,y_center)。由于锚框坐标必须采用规范化的xywh格式(从0到1),所以需要通过公式的计算才能得到labels标注文件的数据,计算公式为

图7 样本标注格式示意图
(6)
(7)
(8)
(9)
3.2 目标框的回归策略
Anchor给出了目标宽高的初始值,需要回归的是目标真实宽高与初始宽高的偏移量,即预测框中心点相对于对应网格(gridcell)左上角位置的相对偏移值。为了将边界框中心点约束在当前网格中,采用sigmoid函数处理偏移值,使预测偏移值在(0,1)范围内,目标框回归示意图如图8所示。

图8 目标框回归示意图
由于原始的框方程式宽度和高度完全不受限制,所以可能导致失控的梯度、不稳定、NaN损失并最终完全失去训练[13]。通过sigmoid所有模型输出来修补此错误,同时还要确保中心点保持不变。通过设置当前的方程式,将锚点的倍数从最小0限制为最大4,并将锚框-目标匹配更新为基于宽度-高度的倍数,设置标称上限阈值超参数为4.0。采用跨邻域网格的匹配策略,从而得到更多的正样本,通过从当前网格的上、下、左、右的4个网格中找到离目标中心点最近的2个网格,再加上当前网格共3个网格进行匹配,从而加速收敛。
3.3 训练结果
身管靶标模型训练环境为:Windows10操作系统、NVIDA GeForce GTX 3050 Ti GPU、AMD Ryzen 75800H@3.2 Hz CPU、16 GB RAM、软件环境Pytorch1.10、实验语言Python3.10、运行环境Pycharm2021.3。经过300轮次的训练得到了靶标识别跟踪模型,不同姿态下模型的动态识别跟踪效果如图9所示。

图9 训练后模型对线性身管靶标样本的检测效果
4 实验数据可视化分析
为了更好地对实验结果进行分析,采用YOLOv5模型的数据可视化模块对靶标训练模型进行可视化分析,包括对训练模型的置信度和F1分数的关系、识别精准率与召回率关系、识别准确率和置信度关系、以及锚框跟踪损失进行可视化处理。对所涉及参数指标及关系进行介绍并对实验结果展开分析。
如图10所示为训练模型F1分数、精准率(precision)、回归率(recall)、置信度(confidence)等参数[14]之间的关系曲线,由于只针对靶标进行专一性单类目标识别跟踪,仅需分析身管靶标的模型识别参数,因此只需呈现一条数据曲线。F1分数是分类效果的衡量指标,在图10(a)中,0.775是参数节点,在0.775之前随着置信度上调,F1分数逐渐上升,最大值达到0.99的分类精确度,之后开始下降。在图10(b)中,通过设置置信度参数到0.833,分类精准率可达到1,之后分类精准率得到保持。图10(c)的下围面积反映了模型的分类器性能,图10(d)中数据回归率达到了0.993,说明该训练学习器表现良好。综上所述,该训练模型的置信率配置节点于0.80左右可以实现良好的模型训练结果,达到0.993的识别效果。
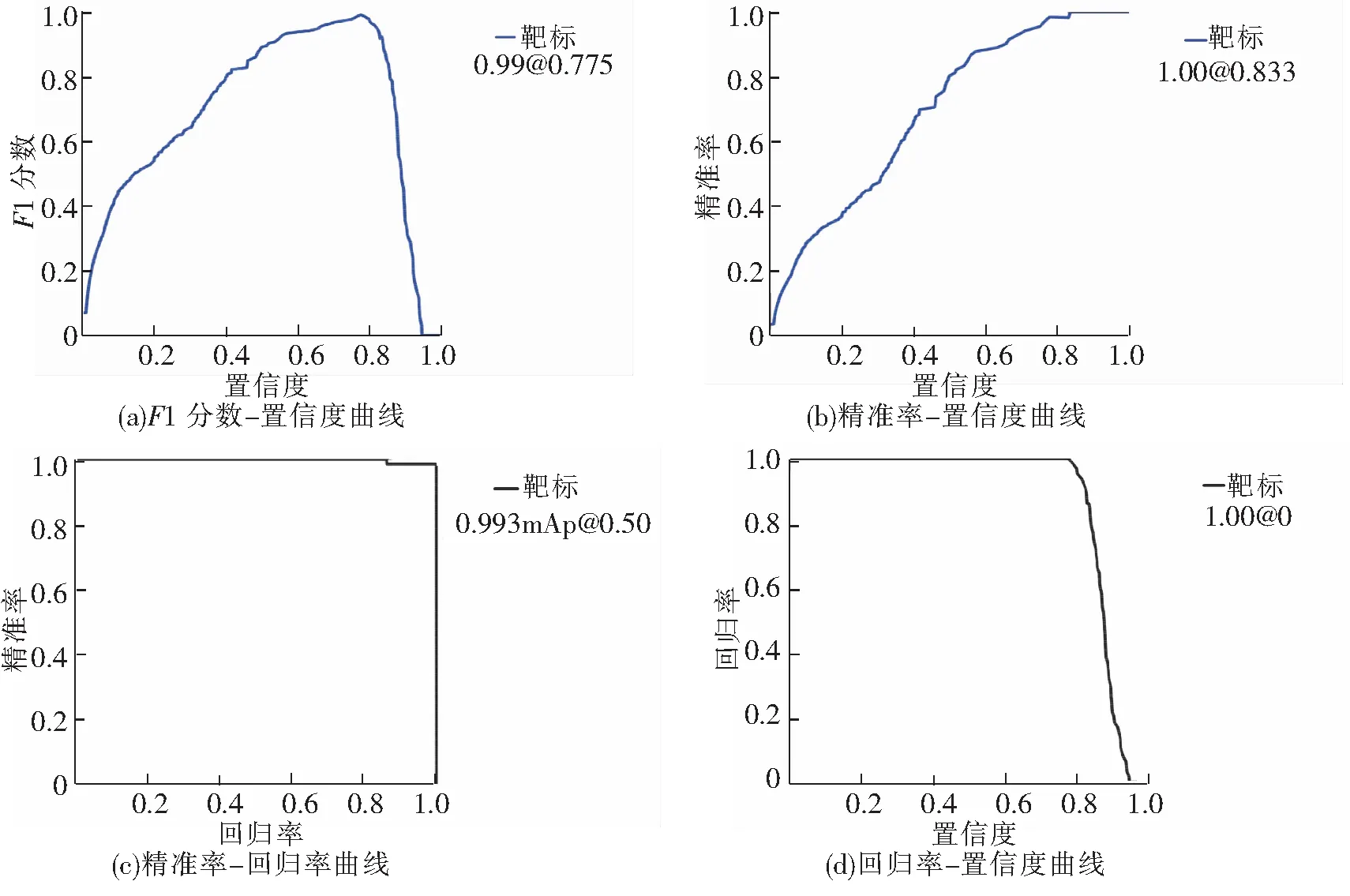
图10 模型参数特征曲线
将靶标跟踪模型数据导出,对数据进行可视化处理,如图11所示为300轮次训练的靶标回归损失数据。YOLOv5使用GIOU Loss作为bounding box的损失,box推测为GIoU损失函数均值,训练损失率基本在0.04~0.10范围之内,训练模型达到了锚框精准度要求;目标检测Loss均值在0.04~0.08之间;分类Loss均值为0;分类精度在0.9~1之间;回归参数0.9~1之间;mAP基本处于0.9~1.0之间。从结果可以看出,本实验有着良好的回归效果,靶标锚框跟踪精度达到0.95,分类跟踪准确率达到0.993,验证了该方法的有效性和可行性。
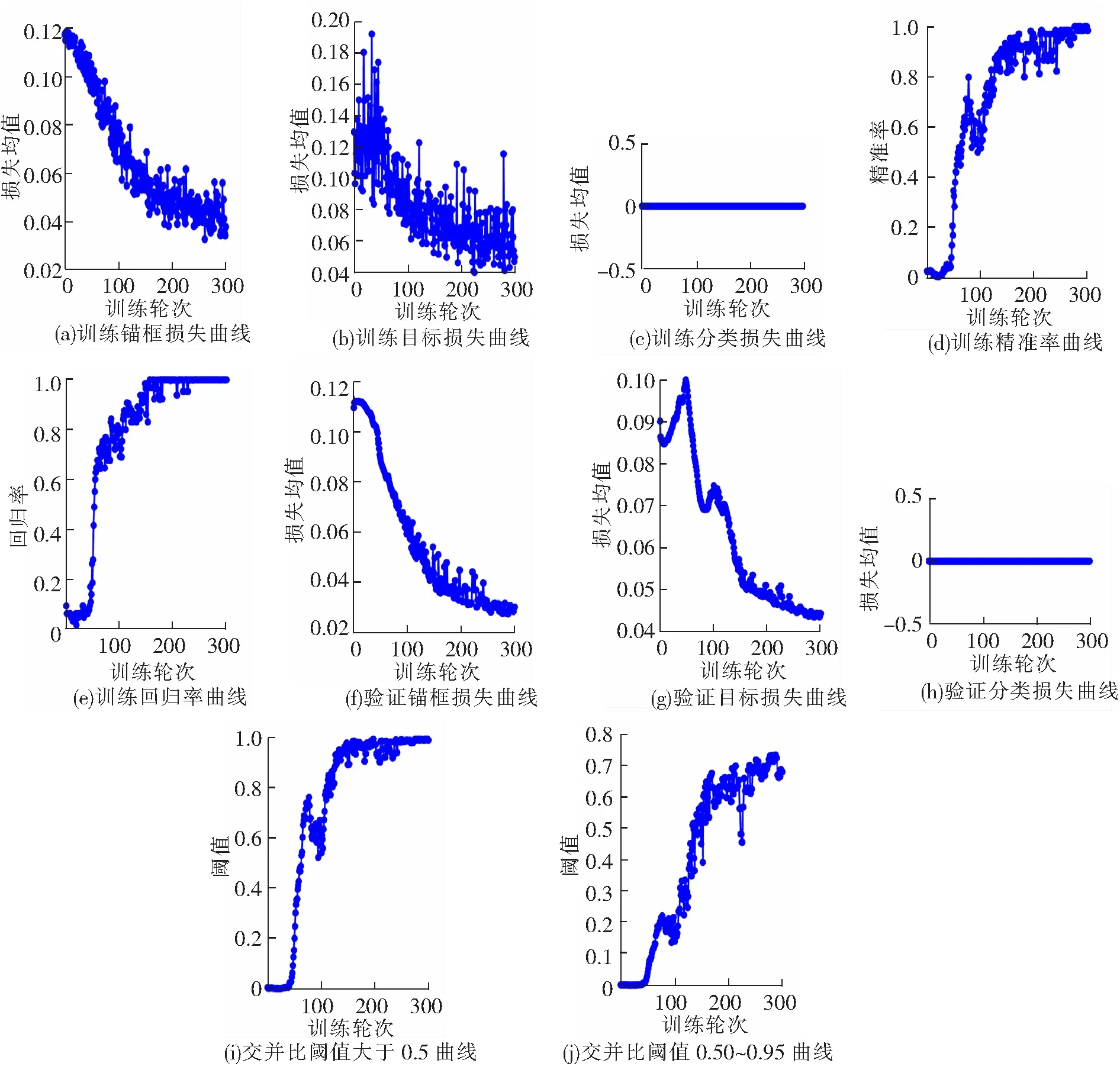
图11 300训练轮次中靶标锚框回归损失
5 结论
为解决身管靶标动态识别跟踪检测问题,融合深度学习相关理论和技术,提出了一种基于YOLOv5的身管靶标检测方法,经过实验,证明该方法切实可行,动态识别跟踪精度达到了实际需求。该方法较现有的身管靶标识别跟踪方法最大的改进在于动态情况下跟踪检测的实时性,以及靶标锚框动态跟踪精度。由于实际情况中身管靶标与摄像机的距离在5~10 m范围,因而不需要考虑遮挡对识别效果的影响。今后仍需要将该方法的原理与身管靶标后续的角点检测、位姿解算相结合,深入研究尺度变换、畸变和数据采集帧率对动态识别跟踪效果的影响,增加方法的普遍适用性。
