基于SMOTE+ENN的个人信用评估方法
2022-06-29邢进生
吕 颖,邢进生
(山西师范大学 数学与计算机科学学院,山西 临汾 041004)
0 引 言
随着大数据时代的到来,互联网金融得到了快速的发展,个人信用在金融领域越来越重要。银行根据个人信用报告所记录的内容,对个人信用进行评估,不仅有助于帮助客户树立正确的信用观念,而且有利于提高银行的授信效率,扩大消费信贷的发放[1]。
传统的信用评估方法主要以BP(back propagation,BP)神经网络、支持向量机(support vector machine,SVM)[2]、逻辑回归(logistics regression,LR)[3]、决策树(decision tree,DT)[4]等理论为基础。Chen Jie等人[5]基于BP神经网络,建立绿色供应链合作信用评价模型,从而更好地学习和评估不同层次的绿色供应链信用。姜凤茹[6]利用支持向量机建立了个人信用评估模型,并引入遗传算法进行参数优化,实验证明遗传算法-支持向量机(genetic algorithm-support vector machine,GA-SVM)模型有效解决了P2P(peer to peer lending,P2P)网贷平台的个人信用评估问题。李太勇等人[7]充分利用稀疏贝叶斯学习(sparse Bayesian learning,SBL)的优势,使得特征权重尽量稀疏,以此实现了个人信用评估和特征选择。但随着金融数据量的增加和数据不平衡问题的出现,这些传统机器学习算法已不能更好地满足市场模型评估的需求[8]。
近年来,随着深度学习[9]相关理论以及信用评估方法[10]的深入发展,国内外众多学者在数据处理及模型构建方面进行了相应研究,取得了良好的成绩。赵雪峰等人[11]利用银行个人信贷数据,构建了基于卷积神经网络的信用贷款评估模型,提高了信用贷款模型的鲁棒性。Shen Feng等人[12]提出了一种改进的合成少数类过采样技术(synthetic minority oversampling technique,SMOTE)[13]用于不平衡数据处理,并将长短时记忆网络(long short-term memory network,LSTM)和自适应提升(adaptive boosting,AdaBoost)算法整合到集成框架中,解决了不平衡信用风险评估问题。Jie Sun等人[14]提出一种基于SMOTE和引导聚集(bootstrap aggregating,Bagging)集成学习[15]算法,为不平衡的企业信用评估建立有效的决策树集成模型。Lean Yu等人[16]提出一种基于深度信念网络(deep belief nets,DBN)的重采样支持向量机集成学习范例,以解决信用分类中的不平衡数据问题。在现有数据不均衡的条件下,分类器集成俨然成为信用评估建模的发展趋势[17]。
鉴于目前个人信用评估方法的研究现状,提出了基于SMOTE+ENN算法与集成学习的个人信用评估模型。该方法在解决样本数据不均衡的基础上,采用网格搜索[18]算法对多种分类器模型进行超参数优化,并利用集成学习技术把最优模型结果集成,从而构建出最优的个人信用评估模型。为了验证算法的有效性,采用公开数据集Give Me Some Credit对该算法进行测试。与传统单一分类器模型预测结果相比,该模型不仅良好地解决了数据不均衡的问题,而且提高了信用评估的精度。
1 相关理论
1.1 SMOTE算法
SMOTE算法是一种合成少数类的过采样技术,广泛应用于处理数据不平衡的问题。其基本思想是基于对现有少数样本的分析,人工生成额外少量样本,并添加到原始数据集中,形成样本数量均衡的新数据集,从而有效改善了样本数据不均衡问题。SMOTE算法具体步骤如下:
(1)对于每个少数类中样本xa,以欧氏距离为标准,找到该样本最近的k个样本。
(2)从k个近邻样本中随机选择一个样本xb。
(3)在xa和xb两个样本点之间随机插入一个新的样本xc,合成新样本的数学公式如式(1):
xc=xa+rand(0,1)×|xa-xb|
(1)
式中,rand(0,1)表示区间(0,1)内的任何一个数。
1.2 网格搜索
网格搜索通过遍历所有超参数组合,寻找一组合适的超参数配置,从而达到优化模型的目的。假设总共有n个超参数,第n个超参数可以取mn个值,即总共的配置组合数量为m1×m2×…×mn。网格搜索根据这些超参数的不同组合分别训练一个模型,通过循环遍历进行测试,从中选择一组性能最好的参数。网格搜索优化参数的基本原理如下:
(1)在初始状态下,网格搜索法依据经验先设置好待搜索的超参数区域,为防止关键参数被遗漏,设置较广的待搜索超参数区域范围。
(2)设置参数搜索步长,从起始点出发,沿着参数不同增长方向以单位步长运动,将所到区域以网格形式表示出来,网格中的交叉点就是所要搜索的参数。
(3)在搜索区域内选取网格的节点,通过交叉验证,测试该参数下模型性能,选取表现最优的参数。
1.3 集成学习
集成学习作为当前比较流行的机器学习算法之一,主要通过某种策略将多个弱监督模型集成,并利用群体决策来提高决策准确率,得到一个更好更全面的强监督模型。即便其中某个弱分类器预测错误,其他的弱分类器也可以及时纠正,从而获得比个体学习器更好的泛化性能。集成学习首先构建一组个体学习器,然后通过某种结合策略将其集成构建成一个强学习器,如图1所示。目前,集成学习常用的结合策略主要有以下几类:

图1 集成学习示意图
1.3.1 平均法
对于数值输出问题,平均法是最常用的集成学习结合策略。
(1)简单算术平均的集成模型可由式(2)表达:
(2)
式中,f(x)为个体学习器预测结果,M为模型数量。
(2)加权算术平均的集成模型可由式(3)表达:
(3)

1.3.2 投票法
对于分类问题,最常用的集成学习策略就是投票法,投票法主要分为硬投票和软投票两种。
(1)硬投票。
根据少数服从多数的原则,选择所有个体分类器中输出最多的标签作为最终预测结果,如图2所示。

图2 集成学习硬投票机制
(2)软投票。
将预测结果为某一类别的所有分类器的预测概率平均,平均概率最高的类别为最终预测结果。
1.3.3 学习法
学习法的代表方法是Stacking,它是一种分层模型集成框架。首先采用原始数据集训练出多个不同个体学习器,然后再用训练好的个体学习器的输出作为新训练集的输入,进而训练出一个新模型,得到最终输出结果。
2 个人信用评估模型的构建
2.1 数据不平衡处理
GiveMe Some Credit数据集一共包含15万条样本数据,其中违约数据10 026条,占比6.68%,无违约数据139 974条,占比93.32%,样本数据严重不平衡,因而需要进行样本数据的平衡处理。但经典SMOTE算法随机选取少数类样本合成新样本,忽略了周边样本情况,容易导致新合成的少数类样本与周围多数类样本产生重叠,形成较多噪音。数据清洗技术ENN广泛应用于重叠样本数据的处理,因而可以将SMOTE算法与ENN结合起来形成一个pipeline,即先过采样再进行数据清洗,以改善SMOTE算法处理数据的不足。该文采用SMOTE+ENN算法对少数类样本进行合成处理,以提高分类器优化性能。
SMOTE+ENN算法主要是在SMOTE过采样的基础上,通过ENN算法清洗重叠数据,达到均衡样本数据的目的。具体步骤如下:首先使用SMOTE算法生成新的少数类样本,得到扩充数据集。然后对新数据集中的每一个样本使用KNN(一般取K=5)方法进行预测,若预测结果和实际结果差异较大,则剔除该样本。
2.2 多分类器集成学习
选取给定数据集的75%作为训练集,剩余数据集作为测试集,并使用训练集分别建立逻辑回归LR、K最近邻(K-nearest neighbor,KNN)、决策树DT、随机森林分类器(random forest classifier,RFC)、引导聚集Bagging、随机梯度下降(stochastic gradient descent,SGD)、极端梯度提升(extreme gradient boosting,XGB)和集成学习(由KNN、Bagging、和XGB模型集成)8种模型。LR是一种概率模型,通过使用Logistic函数将实数值映射到[0,1]之间,以逼近真实标记的对数概率;KNN通过计算样本点与其近邻的5个样本数据距离,从而达到分类的目的;DT通过递归选择最优特征对训练数据进行分割,使得各子数据集达到一个最好分类。RFC是一种基于决策分类树的Bagging集成学习方法,其输出结果由包含的各决策树输出类别的众数决定。Bagging方法通常是独立并行学习多个弱学习器,并按照某种确定性的平均过程将它们组合。SGD每次随机选择一个样本,不断更新模型参数,从而使得目标函数达到极小值点。XGB是一种极限提升树模型,将许多树模型集成在一起,从而形成一个很强的分类。
该文采用基于投票法的集成学习结合策略进行预测分类,该方法主要是先并行学习几个弱分类器,根据输出预测结果从中选取3个最优个体分类器作为基分类器,并通过硬投票法将基分类器结果集成,输出最终的预测结果。算法流程如图3所示。
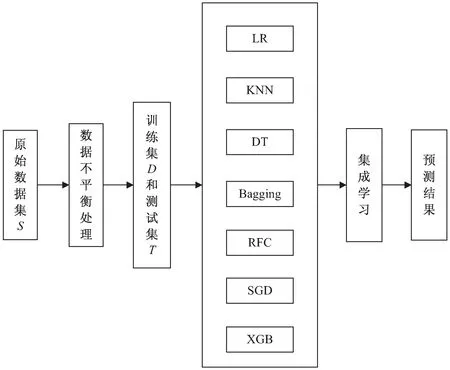
图3 集成学习方法流程
(1)将Give Me Some Credit数据集S划分为训练集D(75%)和测试集T(25%)。
(2)将训练集D按照五折交叉验证的方法随机均等划分为D1、D2、D3、D4和D5五个子集,依次选取各子集Di(i=1,2,3,4,5)作为测试子集,剩下的4份作为训练子集。
(3)网格搜索算法分别对LR、KNN、DT、RFC、Bagging、SGD、XGB模型自动交叉验证、训练,通过调节每一个模型超参数来跟踪评分结果,获取最优超参数。
(4)利用测试集T,对所有最优超参数的个体分类器模型进行预测,将预测结果AUC评分可视化,结果如图4所示。

图4 单一分类器可视化AUC评分结果
(5)根据AUC评分结果,选择KNN、Bagging和XGB为基模型,并通过基于硬投票法的集成学习结合策略将基分类器结果集成新预测分类模型。用训练集D重新训练,测试集T验证模型效果。
3 实验设计
3.1 实验环境设置
所有实验运行环境均为:Windows 10操作系统,Intel(R) Xeon(R) W - 2123 CPU@ 3.6 GHz中央处理器,NVIDIA GeForce GTX1080显卡,显存大小为8 GB、Python 3.6版本、Anaconda 3.6集成开发环境。
3.2 数据采集与分析
实验数据集来自Kaggle数据算法比赛中的Give Me Some Credit开源数据集,该数据集包含12个变量,15万条的样本数据。为了方便特征描述,将变量SeriousDlqin2yrs设置为Y,Y中的数据1表示违约,0表示没有违约。其他特征变量按顺序依次设置为X1~X10。Give Me Some Credit数据集相关特征变量信息如表1所示。

表1 个人信用特征及其对应解释
3.3 数据预处理
实验所采用的数据集是非结构化数据,因而包含多种噪声,需要对数据进行预处理操作。实验数据预处理主要包括缺失值处理、异常值处理、数据归一化操作。
经统计分析发现,特征变量X5、X10存在数据缺失,变量X1、X2、X4、X5、X6、X8存在不同程度的数据异常。本次实验为了处理噪声数据的干扰,采用前一个非缺失值去填充该缺失值,并将异常值视为缺失值,按照缺失值处理方法来进行处理,以保证原数据的均值和标准差不发生大的改动。
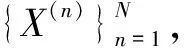
(4)
式中,min(X)和max(X)分别是特征X在所有样本上的最小值和最大值。
3.4 超参数优化
为了确保实验有效进行,需要为每个分类器仔细设置超参数,如表2所示。网格搜索法作为一种自动参数寻优算法,根据给定模型自动进行交叉验证,通过调节每一个参数跟踪评分结果,由于其参数寻优性能的稳定可靠,被广泛应用于多个领域。

表2 不同算法下网格搜索参数设置
3.5 评价指标
为了衡量一个机器学习模型的好坏,通常采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F值(F1-Score)对分类模型预测效果进行评估,各个指标的具体描述如公式(5)~公式(8)所示。
(5)
(6)
(7)
(8)
式中,TP表示预测正确的正样本数量;FP表示预测错误的负样本数量;FN表示预测错误的正样本数量;TN表示预测正确的负样本数量。
3.6 实验测试与结果分析
3.6.1 SMOTE+ENN算法数据不平衡处理
SMOTE+ENN算法通过选择性地产出少数类样本,生成了质量相对较高的新样本集合,增强了分类算法性能。对比实验结果如图5所示。
从图5可以看出,与经典SMOTE算法相比,SMOTE+ENN算法生成的新样本中,离群点数目明显减少,生成的新样本分布更加均匀。SMOTE+undersampling作为欠采样与过采样结合的简单算法,其生成的新样本离群点数目较多,样本数据存在欠拟合。与之相比,SMOTE+ENN算法生成的新样本拟合度更高,样本数据分布更佳。
经SMOTE、SMOTE+undersampling、SMOTE+ENN三种不同的数据不平衡算法处理,样本数据结果如表3所示。
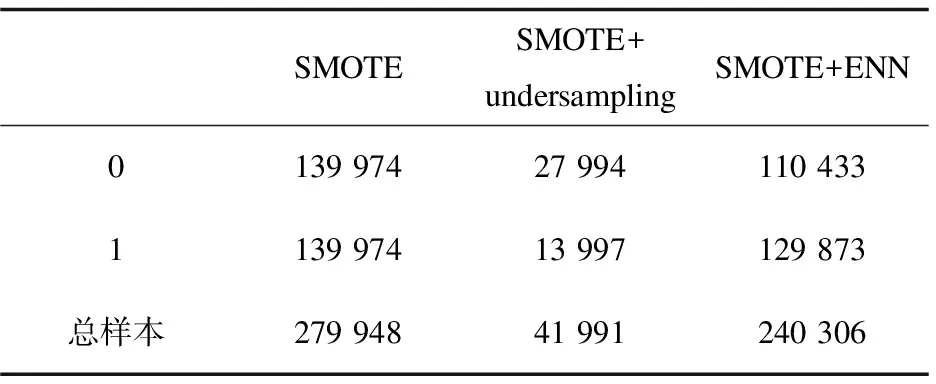
表3 不同算法下样本数据的数量分布
SMOTE算法只是单纯重复了违约样本,会过分强调已有的违约样本,如果部分样本点标记错误或者是噪音,那么SMOTE算法处理后的数据错误也会被成倍放大,造成违约样本过拟合。SMOTE+undersampling算法抛弃了大部分正常样本数据,从而弱化了中间部分正常样本的影响,但样本数据的大量遗弃,可能会形成偏差很大的模型。SMOTE+ENN算法与SMOTE、SMOTE+undersampling两种算法有着明显的不同,不仅是单纯地重复违约样本,而且在局部区域通过KNN生成了新的违约样本数据,降低了数据过拟合的风险。

图5 SMOTE+ENN算法生成新样本分布对比
3.6.2 实验结果分析
针对SMOTE、SMOTE+undersamping、SMOTE+ENN三种不同的数据预处理算法,分别使用简单5折交叉验证、网格搜索和集成学习的算法预测模型分类准确率,具体实验结果如表4~表7所示。

表4 不同算法下简单交叉验证的准确率

表5 不同算法下网格搜索优化模型的准确率

表6 不同算法下集成学习的准确率

表7 集成学习评估结果
从表4、表5的实验结果可以看出,在两种不同的信用评估方法下,SMOTE+ENN算法相较于SMOTE和SMOTE+undersamping两种算法,个体分类器模型的预测准确率最高。在简单交叉验证的条件下,SMOTE+ENN算法预测分类准确率最高,但由于简单交叉验证无任何参数优化,且产生的训练集数据分布和原始数据集有所不同,预测结果偏差较大,可信度低;网格搜索通过优化超参数,获取最优个体分类器模型,SMOTE+ENN算法预测分类准确率相较于简单交叉验证虽有所降低,但可信度增加。
根据表4~表7的评估结果,可以看出在不同算法下,集成学习模型的准确率远远高于个体分类器模型。该文提出的SMOTE+ENN算法对数据不平衡处理后,相较于SMOTE和SMOTE+undersamping数据不平衡处理方法,无论是在个体分类器还是集成学习模型上,预测准确率均有大幅度提升。在基于网格搜索和集成学习的情况下,所提出的SMOTE+ENN算法能够在一定程度上改善了SMOTE算法的不足,预测精度提升了2%,同时实验结果表明集成学习模型相较于个体分类模型而言,预测效果更好。
4 结束语
首先介绍了常用的信用评估方法,在相关研究的基础上,提出了一种应用于不平衡数据集样本处理的算法,即SMOTE+ENN算法。通过设计多种分类器、超参数优化以及集成学习,实现最优评估模型的构建,从而完成对个人信用的评估。为了验证该算法的可行性,针对SMOTE和SMOTE+undersamping两种算法进行实验对比分析,结果表明了基于SMOTE+ENN与集成学习方法的信用评估模型的稳健性。
