基于高光谱数据季相特征的山地草甸植被分类识别
2022-06-06郑奕,王瑶,刘艳*
郑 奕,王 瑶,刘 艳*
1.中国气象局乌鲁木齐沙漠气象研究所,新疆 乌鲁木齐 830002 2.中亚大气科学研究中心,新疆 乌鲁木齐 830002 3.新疆树木年轮生态实验室,新疆 乌鲁木齐 830002
引 言
近年来,由于气候变化及人为干扰强度增加,天山山区草地生态严重失衡,天然草地面积逐渐减少,部分草地类型发生退化。天山北坡山地草甸是全区草地生产力最高的草地类型,也是退化较为严重[1]、草畜矛盾突出的区域。草地退化是一个由量变到质变的发展过程,表现为草地生态系统的物种个体,种群特征、群落组成等发生着不同程度的演变。因此,对草地植被进行分类识别,监测草地生态系统本底状况,可以快速、准确、有效的评价草地退化动态与程度,是进行生态重建的关键。传统的草地资源实地考察的监测方法难以实现对偏远地区监测及快速资源调查评估的需要;多光谱遥感监测精度较低,无法对植被种类进行识别,难以获取草地持续退化过程中优势种和群落组成变化的精细信息,对于部分毒杂草丛生或“逆向”演替的退化草地类型具有明显的局限性。因此,寻求一种适用的草地植被分类识别方法具有十分重要的意义。
高光谱遥感技术的发展,为草地监测提供了前所未有的数据源。高光谱遥感数据具有光谱分辨率高、信息量大的特点,能够更为全面、细致的获取地物光谱特征及其差异性,从而大幅度提高地物分类的类别精细度和准确度[2]。目前国内的相关分类识别研究主要集中在利用地面实测高光谱数据,通过波段选择和特征提取,结合支持向量机(support vector machine,SVM)[3]、决策树[4]、逻辑回归[5]及极限学习机(extreme learning machine,ELM)[6]等分类器对植被进行分类识别,取得了较好的分类效果。如林川等分析和对比了不同植物生态类型的光谱特征,选定用于识别植物生态类型的光谱特征变量,最后应用非线性的反向传播人工神经网络(BP-ANN)与线性判别分析(FLDA)的类型识别方法,对湿地植物生态类型进行了识别[7]。肖波等采集了6个草地早熟禾品种新鲜叶片的高光谱图像,提取了叶片的光谱信息,运用逐步判别分析法选择特征波段,采用Fisher线性判别法,构建草地早熟禾品种的判别分析模型, 为快速识别草地早熟禾品种提供了一种新的方法[8]。但是,高光谱遥感精细分类中仍存在“维数灾难”(Hughes现象)及椒盐噪声严重影响分类结果的应用[2]。有效降低高光谱数据的维数、选择特征波段以及提高光谱图像的信噪比和质量仍是高光谱数据处理和应用中亟待解决的关键问题[9]。另外,由于草地植被的光谱曲线特征差异性不大,存在“同物异谱”和“异物同谱”现象,加上植被在生长发育的不同阶段,植被的外部形态特征到内部的叶绿素含量、含水量都会发生变化,其光谱特征也会随之变化,都会影响分类识别的精度。现阶段的研究大多采取植被成熟时期的光谱数据进行植被识别,而缺少时间过程的多时相地物光谱数据综合分析、目标识别研究。如何使植被类型间的差异加大,增强植被的可分性,提高分类精度还有待更多的研究实例进行验证。
基于此,选择新疆天山北坡中段山地草甸典型植被作为研究对象,采集了多季相(4个关键生育期)植被原始反射光谱数据,然后通过多项式卷积平滑(Savitzky-Golay,S-G)对实测高光谱数据进行平滑除噪,再利用最小噪声分离(minimum noise fraction,MNF)变换进行降维处理,构建多种分类模型进行植物识别;一方面研究了不同季相草地植被的辨识精度,另一方面通过选用不同的分类识别算法,探索适用于新疆山地草甸植被的高光谱分类识别方法。
1 研究方法
1.1 研究区概况
研究区位于天山北麓中段白杨沟的中天山草地生态气象监测野外基地,海拔2 050.0 m,年平均气温2.4 ℃,年平均总日照时数2 429 h,年降水量468 mm,年平均蒸发量1 194 mm,土壤为栗钙土。该基地草场类型属山地草甸,建群种主要有禾本科牧草(老芒麦ElymussibiricusL.、草地早熟禾PoapratensisL.等)、豆科牧草(黄芪AstragaluspenduliflorusLam.等)及典型的退化指示种(草原糙苏Phlomispratensiskar.et Kir.、草原老鹳草GeraniumpratenseL.、绿草莓FragariaviridisDuch.、委陵菜PotentillachinensisSer.、火绒草Leontopodiumleontopodioides(Willd.)Beauv.)等,局部地段生长有中生灌木,其气候特点和自然植被类型具有较好的代表性。
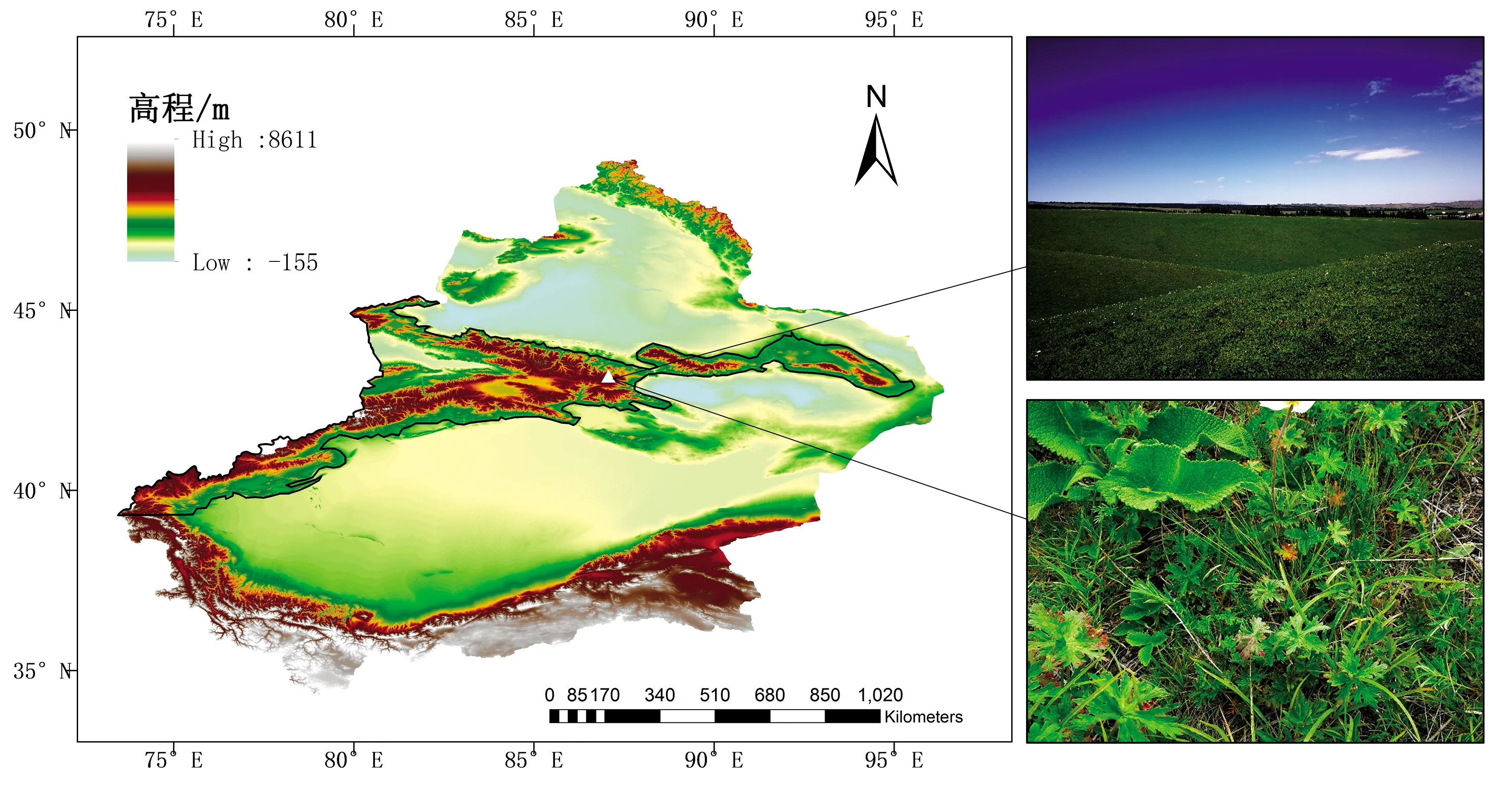
图1 研究区地理位置及典型植被组成图(图中黑框区域为天山山区)
1.2 高光谱数据的采集
植物光谱观测采用美国的高光谱成像光谱仪(SOC710VP),波长范围是400~1 000 nm,光谱分辨率为4.7 nm,波段数为128个,所获取的高光谱图像具有图谱合一的特点,图像上每一个像元点都包含着丰富的光谱信息,构成光谱数据立方体。选择晴朗、无云、光照条件较好的天气进行测量,时间为12:00—14:00。测定植被冠层光谱时,应保证测定区域内植被类型具有代表性。观测时传感器方向垂直向下,高度0.6 m,同时记录观测时间、天气状况、样地经纬度、植被类型情况。测量的时点包含山地草甸典型植被的返青期(4月)、分蘖(枝)期(5月)、花期(6月—7月)及黄枯期(9月)。采用定点观测,每个测点采集5景高光谱图像,一个测点整个生长季共采集了20景高光谱图像,选取其中质量最好的4景作为实验样本,优势植物主要为老芒麦、草原糙苏、草原老鹳草和绿草莓。

图2 植被不同时期高光谱图像
1.3 高光谱数据处理方法
高光谱数据采集后,剔除数据有明显异常的波段,截取的波段范围为406~997 nm,共计115个波段,先利用SRAnal710软件进行高光谱数据标定及反射率转换处理,再用ENVI5.3软件进行数据分析。
1.3.1 平滑去噪处理
采用多项式卷积平滑(S-G)对高光谱数据进行平滑去噪,它是一种在时域内基于局部多项式最小二乘拟合的滤波方法,该方法的最大优点在于滤波噪声的同时可以确保信号的形状和宽度不变,较好地保留了图像细节。由于该算法不受图像数据本身限制,因而提高了平滑去噪的适用性。其计算公式如式(1)
(1)
1.3.2 降维处理
由于高光谱数据波段数较多,有些波段质量不佳,将其直接作为模型输入将会导致数据过大,影响速度和精度。同时为了克服Hughes现象,选用最小噪声分离(MNF)变换对高光谱数据进行降维和波段优选以提高建模速度、减少计算量。MNF是针对一组多元随机变量构造线性变换,得到一组相互正交的结果变量,变换的目标是使结果变量的信噪比最大化[9]。其本质上是两次叠置的主成分变换,第一次变换(基于估计的噪声协方差矩阵)用于分离和重新调节数据中的噪声,这步操作使变换后的噪声数据只有最小的方差且没有波段间的相关;第二步是对噪声白化数据(noise-whitened)进行主成分变换,具体相关推导公式见文献[9]。
1.4 分类识别方法
分别利用支持向量机分类(support vector machine,SVM)、人工神经网络分类(artificial neural network,ANN)及波谱角填图(spectral angle mapper,SAM)这三种常用的高光谱数据分类方法对研究区植被进行分类识别,并对分类精度进行综合评价与比较分析。
1.4.1 支持向量机
近期的研究表明SVM的方法在高光谱遥感数据监督分类方面具有相当大的潜力,能获得比神经网络、决策树和最大似然等概率分类方法更高的精度,其分类原理及具体公式见文献。在SVM中需要指定一个重要参数为惩罚系数C(表示对误差的宽容度),C越大,说明越不能容忍出现误差,容易过拟合,即训练集准确率可能很高而测试集准确率不高;C越小,容易欠拟合[10]。另外,SVM中的核函数及其参数的选择也很重要,直接影响到SVM的分类效果,常用的核函数有线性核(linear)、多项式核(polynomial)、Sigmoid核与径向基核(radial basis function)4种。其公式如下:
(1)线性核(linear)
k(xi,xj)=xixj
(2)
(2)多项式核(polynomial)
k(xi,xj)=(xixj+c)d
(3)
(3)Sigmoid核
k(xi,xj)=tanh[μ(xixj)+ν]
(4)
(4)径向基核(radial basis function)
(5)
其中,c,d,μ,ν和σ2均为参数。
1.4.2 人工神经网络
ANN指用计算机模拟人脑的结构,用许多小的处理单元模拟生物的神经元,用算法实现人脑的识别、记忆、思考过程。其中误差反向传播算法(back propagation,BP)应用最为广泛,它通常指多层前向神经网络,含有输入层、输出层以及处于输入输出层之间的隐含层,如果进行非线性分类,输入的区域并非线性分类或需要两个超平面才能区分类别的时候,隐含层数设置为大于或等于一。隐含层的状态影响输入与输出之间的关系,改变隐含层的权系数,可以改变整个多层神经网络的性能,本文使用的是算法较成熟的前馈三层BP网络模型(BP-ANN),有关模型的算法详见文献[7, 10]。
1.4.3 波谱角填图
SAM是高光谱图像分类中较常用的方法,该方法从考虑光谱维的信息出发,强调了光谱的形状特征,通过计算待测光谱与参考光谱之间的“角度”来确定两者之间的相似性。每个光谱都看成n维空间的一个向量,第i个向量和第j个向量之间存在一个夹角θij,夹角的余弦值称为相似系数,如式(6)
(6)
式(6)中,i和j均为n维空间向量,X为向量对应的值。光谱角值越小,其余弦值越接近1,待测光谱与参考光谱就越相似,地物特征信息也就越相似,归为一类的可能性就越高[11]。
1.5 精度评价
衡量分类算法性能的2个指标分别为总体分类精度、Kappa系数,值域范围均为[0,1],2个指标的值越接近1,说明算法的性能越好。总体分类精度为所有正确识别的样本数与总验证样本数的比值,其公式如式(7)[12]
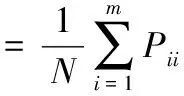
(7)
式(7)中,N为样本总数,m为地物类型数,Pii为混淆矩阵第i行第i列的像元数(即地物i被正确识别的样本量)。
Kappa系数是另一种衡量图像整体分类精度的指标,既考虑了对角线上被正确分类的像元,又考虑了不在对角线上的各种漏分和错分误差,其值越大,分类结果与真实地物类型的一致性越好,其公式如式(8)
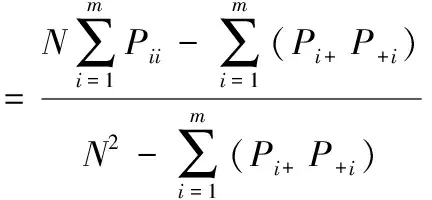
(8)
式(8)中,Pi+和P+i分别为混淆矩阵第i行和第i列的像元总数。
2 结果与讨论
2.1 原始光谱曲线经Savitzky-Golay滤波后效果
图3为几种优势植物不同季相光谱曲线平滑去噪处理前后对比,可以看出,草地植被未经平滑去噪处理的原始光谱,其锯齿状的波动不利于光谱特征的判断和提取,经过Savitzky-Golay滤波算法处理后,对比原始曲线,大部分噪音得以去除,且滤波后的曲线平滑度较高。平滑处理在剔除干扰值的同时,保持了原始曲线的基本特征,并突出刻画了波峰与波谷相交替的状态,较好的体现了植物生长的变化特征。

图3 不同季相优势植物光谱曲线平滑去噪处理前后对比
2.2 不同季相优势植物光谱特征变化
图4反映了草原糙苏、绿草莓、草原老鹳草、老芒麦等4种山地草甸优势植物在不同季相的光谱曲线响应变化,在可见光波段400~420 nm处的吸收谷,称为“蓝谷”,反映了植物光合作用色素(叶绿素、类胡萝卜素)对蓝光的吸收特征。
在可见光波段550 nm附近是叶绿素的绿色强反射区,形成一个反射峰,即“绿峰”,返青期的“绿峰”幅值最高,说明这个时期植被叶绿素含量较高。在植物分蘖(枝)期及花期,“绿峰”均不同程度向蓝光方向偏移,这是因为随着植被的生长,叶绿素浓度增加,植物光合作用增强。黄枯期这几种植物的叶片开始黄化,生物量减少,叶绿素缺乏使植物在叶绿素吸收带上的吸收减少,“绿峰”又向红光方向偏移。如绿草莓、草原老鹳草黄枯期的“绿峰”位置偏移到640 nm左右。表现最为明显的是草原糙苏,黄枯期地上部分大多凋落或枯黄,绿色叶片大量减少,光谱曲线无明显“绿峰”和植物光谱特征,已呈现出土壤的光谱反射特征,只是反射率要高于土壤,这是由于草原糙苏枯叶表面比较光滑,在测量光谱过程中,入射光照射到枯叶表面会有一部分产生反射,使其反射率比土壤的反射率要大,这和已有的一些研究结论相同[13]。
在可见光波段670~700 nm处的吸收谷,称为“红谷”,是植物光合作用吸收最强的波段范围。随着植被的生长,有“红谷”蓝移现象。由图4还可以看出,分蘖(枝)期(5月)为植被生长旺期,叶绿素含量较高,几种植物对红光的吸收较强,“红谷”幅值基本都是全生长季最小。

图4 优势植物在4个关键生育期的光谱曲线对比图
在近红外波段700~750nm区域,植被叶面反射率急剧增大,出现反射“陡坡”,称为“红边”。“红边”斜率主要与植被覆盖度或叶面积指数有关,覆盖度越高,叶绿素含量越高,红边的斜率越大。另外,植被生长旺盛时期,植被生物量、色素含量高,红边位置会向红光方向偏移,到黄枯期,又向蓝光方向偏移。
近红外波段750~950 nm是一个相对平坦、反射率较高的区域,它主要由植被叶片内部结构决定。在这个范围内,不同植被在不同季节,其光谱反射率是不同的。几种植物返青期草地光谱反射率值均不同程度高于其他时期的草地反射率值,主要是因为返青期草地生长状况良好,叶面积指数较大,叶绿素含量较高。黄枯期则因植被地上部分大多凋落或枯黄,绿色叶片大量减少,反射率受到土壤光谱干扰而呈现数值偏高的现象。
通过以上分析,可以看出几种植物虽然具有相同的反射率变化特征,即波峰、波谷等特征出现的位置基本一致。但在生长的不同阶段,由于叶绿素含量差异影响到植物光合作用效率,叶绿素含量越低,蓝、红波段吸收减弱,可见光波段反射率升高,近红外反射率减弱,反之叶绿素含量越多,蓝、红波段吸收增强,可见光波段反射率降低,近红外反射率增强,导致光谱特征存在细微差别,主要体现在“绿峰”、“红谷”及“红边”等参数差异较大,其位置会根据植被健康状况、成熟状态等发生偏移,因此可以通过不同季相光谱曲线的细小差别实现对植被的精细分类。
2.3 多种方法分类结果与精度评价
基于同一样地采样数据,在对原始数据进行降维除噪后,分别采用SVM,BP-ANN和SAM三种方法进行分类。采用ENVI5.3软件提取高光谱图像的感兴趣区域(region of interest,ROI),为了保证精度验证的准确性,建模样本与验证样本必须彼此独立,重新选取ROI作为验证样本来计算混淆矩阵。不同季相不同植物建模样本和验证样本的比例大致为2∶1。
2.3.1 SVM分类器的构建与评价
筛选出Polynomial核函数和RBF核函数构建SVM分类器,径向基核函数除了受惩罚系数C影响,还受核函数宽度参数σ2影响,σ2间接地决定了数据映射到新特征空间后的分布状况,值越大,支持向量越少,可能会造成过拟合;值越小,支持向量越多,可能出现大的平滑效应,无法在训练集上得到特别高的准确率,影响最终测试集的分类准确率。因此,C与σ2的选择需要维持一种动态平衡,不仅要有较高的测试集分类准确率,而且还要保证分类器的通用性、泛化性等性能。SVM模型的分类及检验结果如表1所示。

表1 高光谱数据支持向量机建模结果
结果表明,不管是采用多项式核函数还是采用高斯径向基核函数,利用SVM对山地草甸植被高光谱数据进行分类均取得了较理想的效果。尤其在返青期和分蘖(枝)期分类精度较高,总体分类精度均超过了95%,Kappa系数也超过了0.94,其中分蘖(枝)期Polynomial-SVM分类精度达到97.86%,Kappa系数为0.97。利用SVM方法进行分类时,在植物生长旺盛期(4月—5月)Polynomial核函数分类精度较高,植物成熟期(6月—9月)径向基核(RBF)函数分类精度较高。
2.3.2 其他分类方法的比较
为了验证SVM对高光谱数据分类的优势,又利用BP-ANN及SAM分类方法进行了比较分析,具体分类结果见表2。
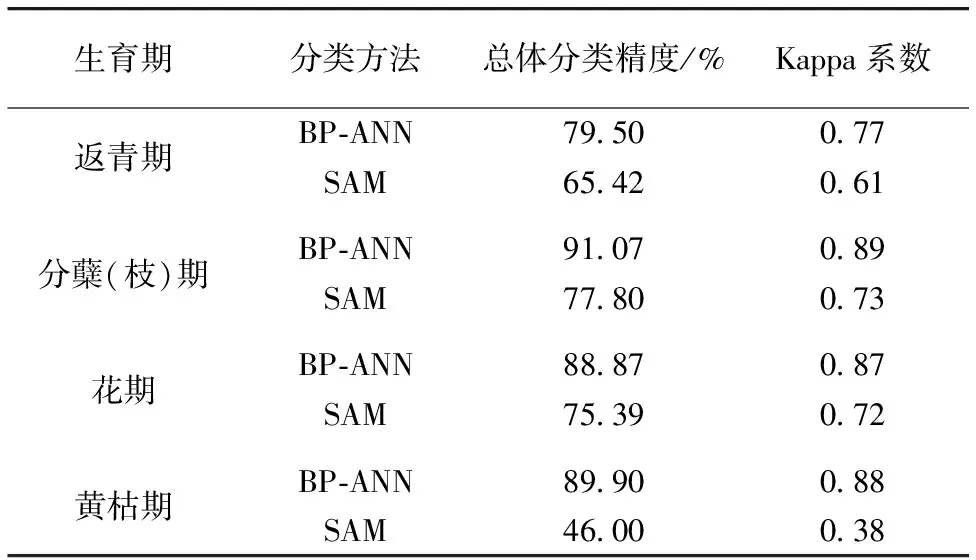
表2 多种方法分类结果与评价
在常用的高光谱数据分类方法中,BP-ANN为学习型机制,通过误差逆传播算法不断训练模型实现分类,但是针对高光谱数据的不确定性、高维数等分类效果不够理想。由表2可以看出,除了分蘖(枝)期分类精度较高,总体分类精度为91.07%,Kappa系数为0.89,其他时期分类效果一般。另外,在样本数量较大时,BP-ANN模型训练较为耗时,分类效率较低,虽然在MNF变换降维后能极大的缩短数据处理时间,但分类时间还是较其他两种分类方法都长。该方法在黄枯期的分类精度略高于SVM和SAM分类方法,总体分类精度为89.90%,Kappa系数为0.88。
SAM分类也是高光谱分类的常用方法,虽然有训练样本数量少,分类速度快的优点,但是在植被各季相的分类结果精度均不高,最高值为分蘖(枝)期的总体分类精度77.80%,Kappa系数为0.73。这是因为SAM算法把光谱角测度作为一种全局性的训练样本对整个光谱向量集进行相似性测量,当地物类别内部存在一定的差异时,这种方法对局部特征和辐射强度并不敏感,且易受噪声影响,导致分类精度下降[14]。另外,由于所有高光谱的波段都参与影像分类,也容易产生Hughes现象。
比较以上三种分类方法,可以看出,在植被生长旺盛期(4月—5月)的光谱曲线特征比黄枯期的光谱曲线特征更容易区分,因此这个时期比较适合进行草地植被分类,精度较高。三种方法对花期的分类精度都有所降低,可能是因为这个时期部分植物的叶片受叶黄素、花青素等色素影响有变色现象;另外,花期草甸植被植株较其他时期明显增高,受采集时风速的影响,高光谱影像上部分区域出现些许条纹偏移,也是致使花期植被分类精度降低的原因。这几种常用的高光谱分类方法对于植被黄枯期的分类精度均不高,原因大致是因为黄枯期植被大多呈现枯黄状态,地上部分凋落或者萎蔫,叶片叶绿素含量减少,植被稀疏及土壤裸露,植被光谱反射率受到下垫面反射光谱影响造成分类精度降低,因此,植被黄枯期不适合对植被进行分类与识别。
综上所述,SVM算法以数学统计方法和优化技术为基础,分类器结构简单、容易训练、收敛速度快、具有很高的分类精度,与神经网络方法和波谱角填图方法相比具有一定的优势,是一种有效的草地植被分类识别方法,但是在核函数和最优参数组合的选择方面仍然是一个难点。植物生长旺盛期基于Polynomial核函数的SVM分类器精度较高,植物成熟期基于RBF核函数的SVM分类器精度较高。
3 结 论
针对草地植被光谱相似度高、难以分类识别等特点,利用S-G滤波及MNF变换预处理结合不同核函数的SVM分类方法,对比BP-ANN及SAM等几种常用的高光谱数据分类方法,统计分析得出以下结论:
(1)使用S-G滤波及MNF变换预处理方法可以有效的对高光谱数据进行降维除噪,获得较平滑的光谱曲线,减少了数据的冗余程度并缩短了分类时间。
(2)不同季相的植被因结构特征、色素含量和含水量等不同造成光谱曲线差异,“绿峰”、“红谷”及“红边”参数等均存在差异。在植被生长旺盛期(4月—5月)的光谱曲线特征比黄枯期的光谱曲线特征更容易区分,因此这个时期分类精度较高,这也反映出植物的叶绿素含量是进行山地草甸植被分类的主要决定因素,植被黄枯期不适合对植被进行精细化分类与识别。
(3)SVM算法可以实现对山地草甸植被的精细分类,分类结果类别完整,准确度高,误分、错分现象相对较少,相比BP-ANN及SAM等常用的高光谱数据分类方法具有较大的优势。植物生长旺盛期(4月—5月)Polynomial-SVM分类精度较高,植物成熟期(6月—9月)RBF-SVM分类精度较高。
