面向中文菜谱工艺的文本分类研究
2022-05-30孙惠蓝雯飞
孙惠 蓝雯飞


摘 要:针对菜谱工艺标签标注的需求随着网络平台上中文菜谱数量增多而不断增加,使用机器学习搭建了文本分类模型,实现了工艺标签的自动标注。该模型使用TF-IDF、TextRank两种方法进行特征降维,与常见的三种机器学习分类器朴素贝叶斯(NB)、逻辑回归(LR)、支持向量机(SVM)进行组合,组成了6种模型。获取网络上的中文菜谱整理成实验数据集,通过实验验证了所提模型的有效性,为菜谱工艺标签的自动生成提供了可行的解决途径。
关键词:中文菜谱; 机器学习;文本分类; 特征降维;分类器
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)21-0079-03
开放科学(资源服务)标识码(OSID):
随着大数据和计算机性能的不断提升,机器学习已经广泛应用于数据挖掘、搜索引擎、电子商务、自动驾驶、量化投资、自然语言处理、计算机视觉等。若要人工处理互联网海量的信息文本,将会费时费力,且分类结果稳定性差。应用机器学习的方法,实现文本内容的自动化标记分类,是大数据信息时代的必然选择。
如今文本分类已经应用于多个领域,涉及新闻、医疗、司法、林业等各个领域。在新闻文本的分类中,由于数据集的充分,如今的分类效果已经高达0.93的精确率[1];在医疗文本分类中,分类效果达到0.86的精确率[2];在司法文书文本分类中,各项分类预测任务也高达0.77的精确率[3];在林业文本分类中,也实现了0.92准确率[4]。
菜谱文本发源于历史上不同时期各种方式的“菜品”记录,早在《诗经》《尚书》《左传》等先秦元典中已有零散资讯,是中华饮食文化重要的承载者[5]。目前,在食谱菜谱文本领域的文本分类研究尚不如其他领域充分。近年来,随着中国在线食谱网站及应用的不断发展,越来越多来自不同地区的用户将他们制作的食谱分享到线上,为我们研究中文菜谱提供了丰富的数据资源。有的研究者将数据集进行食谱成分多样性分析、食谱特色成分分析、食谱复杂性分析、食谱相似系分析、食谱惯用辅料分析等多种数据分析研究[6]。还有研究者以中国菜品图片作为研究对象,提出了基于双线性模型的菜品识别方法[7]。
随着时代的进步,人们的不同特殊需求也开始显露,人们不再局限于以前传统思想的束缚,越来越多的新型需求开始显现出来,同时,这些新型需求也对当前的文本分类技术提出了挑战[8]。因此,本文针对菜谱工艺的分类需求,以中文菜谱文本为研究对象,使用机器学习的方法构建文本分类模型,以替代人工标注、提高标注效率。
1 相关理论
1.1 文本分类的过程
文本分类是用计算机对文本数据集按照一定的分类器模型进行自动化分类标记。文本分类的总体过程包括预处理、特征提取、分类器、测评等。文本分类实验的总流程如图1所示。
(1)预处理:将原始语料格式化为统一格式,便于后续的统一处理。
(2)特征提取:从文档中抽取出反映文档主题的特征。
(3)分类器:将实验数据放入分类器中进行训练。
(4)测评:分类器的測试结果分析。
1.2评测指标
文本分类采用分类任务常用的F1(F1-score)作为评测指标,对每一个类别的分类结果,正确分入该类的样本数量记作TP,错误分入该类的样本记作FP,本该分入该类却错误地分入其他类的样本数量记为FN。则精确率P(Precision)、召回率R(Recall)和F1(F1-score)值的定义分别如式(1)、式(2)、式(3)所示。
[P=TPTP+FP] (1)
[R=TPTP+FN] , (2)
[F1=21P+1R=2×P×RP+R] , (3)
2 实验环境与数据集
实验软件环境为 Window10(64位)操作系统,编程语言Python 3.6,机器学习框架 scikit-learn 0.21.2; 硬件环境为 Inter Core i7—7500U—2.7 GHz,8.0 GB 内存。
本文基于数据挖掘技术,采集网站上中文菜谱文本数据,通过去重和去噪处理,筛选出 818条中文菜谱文本数据。根据烹饪工艺为分类标签进行人工标注,其中炒339、炖煮213、蒸141、拌67,烤 61,如下图2所示。统计文本中字符的个数,如图3所示,可以看出家常菜制作的文本有短文本(低于50个字符),也有长文本(高于400个字符),大于3/5的文本的字符数在50~200之间。经过文本的预处理后,将文本统一存储在csv文件中。图4为数据的存储格式,图5为某个中文菜谱文本的文本内容的样本。
使用Jieba分词在主要食材字段数据集中分析出各种食材词汇的出现频率,使用WorldCloud库绘制词云如图6所示。在图6中,食材词汇越大,代表频率越高,不难看出鸡蛋、胡萝卜、土豆、豆腐等频率很高,是家常菜中的普遍使用的食材,与现实生活中人们生活需要相符。
3 分类模型
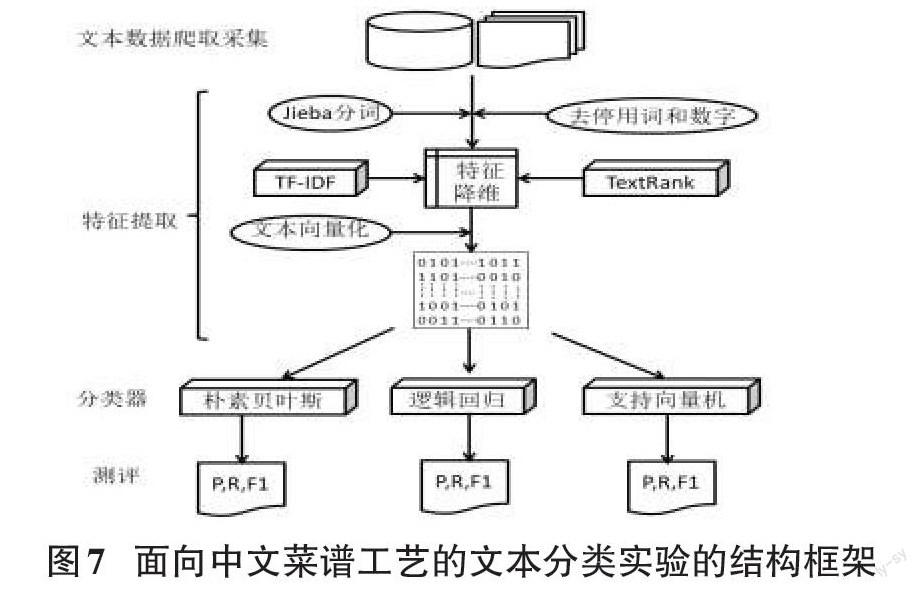
本研究使用两种特征提取方法和三种分类器进行6种模型的分类实验,实验结构框架如图7所示。主要包含4个步骤:文本数据的爬取采集、特征提取、分类器、测评。
(1)首先是文本数据采集及筛选,使用爬虫技术采集网页中的文本数据,经过文本的预处理后,将文本统一存储在CSV文件中。
(2)在特征提取中,用到中文分词技术、去停用词及关键词抽取的方法,最后将词语转化成数值矩阵。在分词方法不同,与关键词数不同时,特征提取的结果也会不同。图8展示的文本样本分别用Jieba库经行分词处理以及去停用词的效果图。在文本关键词提取中,本实验采取了TF-IDF 和TextRank的两种方法进行实验,以降低数据的纬度,以图5所示样本为例,图9、图10分别为两种算法以关键词为20,提取名词和动词的效果图。
(3)将词语转化为特征向量。以关键词为20个名词和动词为例,每一个文本转换为一个空间向量。如图11所示,将文本词语转化为空间向量。
(4)通过两种不同的特征提取方法产生的数据都放入NA、LB、SVM三种中常见的机器学习分类算法中进行训练,统计每个模型的Precision、Recall、F1-score对比观察实验结果。
3 实验结果
为了验证不同算法在文本分类方面的性能,将中文菜谱文本数据集划分为 10 份,任意 9 份作为训练集,剩余任意的 1 份作为测试集。对不同算法进行10 次训练与测试,以实验结果的均值作为参考评估的依据。TF-IDF关键词处理后的各算法性能如表1所示,TextRank關键词抽取后的算法性能如表2所示。
实验结果表明:6种模型都基本实现了中文菜谱文本的工艺分类的任务,TextRank+NA模型的分类效果在对比试验中表现最佳。TextRank算法在关键词抽取上更优于TF-IDF算法,在3种分类器中,朴素贝叶斯分类器(NA)的分类效果最好。
4 结束语
基于机器学习的中文菜谱工艺文本分类模型,让菜谱工艺标签实现自动化分类标注,提高了分类标注的效率,适应时代需求。在机器学习框架下,针对菜谱工艺的文本分类任务,TextRank+NA组合的模型的效果相对最理想。随着网络的菜谱文本不断增加,中国菜谱文本的价值不容忽视,以文本分类模型代替人工标注,有效推动了饮食领域的现代化发展。
本文仅使用了3种典型的分类器,存在一定的局限性,后续可以用其他机器学习分类器或者深度学习网络分类器进行实验,更好的分类方法有待在未来提出。文本数据中的字符数量不同、关键词之间的位置以及上下文间的语义对实验也有可能产生影响,后续可以继续深入研究。
参考文献:
[1] 张昱,刘开峰,张全新,等.基于组合-卷积神经网络的中文新闻文本分类[J].电子学报,2021,49(6):1059-1067.
[2] 赵旸,张智雄,刘欢,等.基于BERT模型的中文医学文献分类研究[J].数据分析与知识发现,2020,4(8):41-49.
[3] 王文广,陈运文,蔡华,等.基于混合深度神经网络模型的司法文书智能化处理[J].清华大学学报(自然科学版),2019,59(7):505-511.
[4] 崔晓晖,师栋瑜,陈志泊,等.基于Spark框架XGBoost的林业文本并行分类方法研究[J].农业机械学报,2019,50(6):280-287.
[5] 赵荣光.“中华菜谱学”视阈下的“中国菜”——2018郑州·向世界发布中国菜活动主题演讲[J].楚雄师范学院学报,2020,35(1):1-5.
[6] 刘兆沛.基于中国在线食谱的探索式数据分析[D].天津:天津工业大学,2019.
[7] 段雪梅,朱明,鲍天龙.双线性模型在中国菜分类中的应用[J].小型微型计算机系统,2019,40(5):1050-1053.
[8] 徐萍.基于机器学习的文本分类技术研究进展[J].电脑知识与技术,2021,17(30):109-110.
【通联编辑:唐一东】
