基于BP神经网络的语音情感识别系统分析与设计
2022-05-30邬卓恒赵嘉熙时小芳
邬卓恒 赵嘉熙 时小芳







摘要:语音情感识别是人工智能的重要研究领域之一。文章基于神经网络算法分析与设计语音情感识别系统。系统分为前端和后端两个模块:前端部署在移动终端上,实现接收语音,上传语音文件,显示识别结果等功能;后端部署在服务器上,实现语音降噪、特征提取、语音情感模型训练、情感识别、个人语音库创建等功能。
关键词:语音情感识别;BP神经网络;个人语音库
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2022)10-0076-04
通常意义上的语音识别是指机器自动的识别语音的文本信息。语音的文本含义识别技术出现较早,1952年开发出简单的语音识别数字系统,从此正式开启了语音识别的进程。语音情感识别也是语音识别的重要部分。语音情感识别领域是一项综合性的研究领域,包括生物技术、心理认知、脑科学、统计学、计算机科学等学科。情感可以通过孤立的跳跃式、离散的数据描述,也可以采用二维、三维或多维空间的连续值数据描述。本文设计的情感识别系统采用离散描述的情感模型,即将人类的情感分为6类:悲伤(Sa) 、害怕(F) 、惊奇(Su) 、生气(A) 、高兴(J) 和讨厌(D) [1]。语音以波的形式在介质中传播,在计算机处理语音信息要进行采样、连量、编码后存储使用。识别语音中包含人的情感,需要提取声音的特征。声音的提取特征方式较多,本系统采用MFCC[2-3]作为语音情感识别的特征。在语音情感识别技术发展的过程中出现了很多算法,其中传统的机器学习算法、深度学习算法应用较为广泛。系统使用BP神经网络算法训练语音情感模型,刻画语音特征与情感的关系。
1 需求分析
语音情感识别系统包括两个主要功能:识别用户上传的语音的情感、建立并不断优化情感识别模型。用户和管理员是语音识别系统的两类参与者。用户使用的核心功能是通过移动终端的客户端发送语音,等待系统反馈,系统识别说话人声音中包含的情感状态。
管理员需要创建并维护公共语音数据库、调用训练算法、建立用户个人语音库、训练用户个人情感识别模型。在系统运行的早期,语音识别系统使用的语音数据特征是从公开数据库中获得,并使用公开语音数据库中的数据训练语音识别模型。系统运行一段时间后,积累一部分用户语音数据,系统将新增加数据与公共数据联合训练模型,提升模型识别的准确率。系统运行较长一段时间后,积累大量的用户语音数据,为用户建立用户个人语音库。系统建立个人语音数据库并训练模型,该模型为该用户服务,能提升用户情感识别的准确度。
2 语音情感识别系统框架
语音情感系统分为两部分如图1语音情感识别系统框架图所示:第一部分为前端,使用App安装在用户的移动终端中。第二部分为后端,以Web的形式部署在服务器上链接公共声音数据库和用户声音个人数据库。两部通过网络进行链接。前端的主要功能是录音、播放、上传、显示情感状态、反馈识别正确程度。后端主要功能有三部分:语音情感模型的训练、语音状态的识别、用户个人语音数据库的构建。
3 语音情感识别系统概要设计
语音情感识别系统结构如图2所示。后端模块中三个模块为语音情感识别模型训练模块、语音情感识别模块、用户个人语音数据库构建模块。其中情感识别模型训练模块、语音情感识别模块是系统的核心内容。这两个模块共同调用预处理模块,语音在产生和传播的过程中会混入噪音,在语音进行降噪后提取语音中的特征。进行模型训练时,将每段语音的特征值作为BP神经网络的输入[X]向量,语音的6种离散情感值作为[Y]值训练模型。在训练模型时,会用到大量语音数据,将语音数据进行批量的预处理,将预处理后的数据存储在数据库中,训练时,可以从数据库中直接读取特征值和标签。语音情感识别模块是从前端接收语音数据后,进行语音预处理得到语音特征,将语音特征带入模型,识别出语音的语音状态,然后将结果发送给用户。用户收到结果后将做出判断,并给出自己认为的情感状态,模块将使用用户的语音信息和结果写入用户个人语音数据库中。
系统的核心业务流程有两个:第一是语音情感识别模型创建,语音情感识别模型是系統的核心基础,系统识别的准确率取决于情感识别模型,语音情感模型创建的流程如图3所示。第二是用户情感识别,情感识别是系统的重要应用。用户语音情感识别流程如图4所示。
语音情感模型创建,首先选取公共语音数据库,选取公共数据库要注意两点:第一根据软件使用的用户人群,确定语种。要选取同语种的公共数据库。也可根据软件使用的区域不同,选择不同的公共数据库。第二,情感模型可以是连续描述也可以是离散描述。每种描述又有多种类型。要根据系统情感模型选择合适的数据库。本系统采用离散情感标注的中文语音公共数据作为模型训练源。
从数据库中提取数据进行一系列处理后得到每段语音数据的特征和标签。将这些特征和标签存入数据库。将所有语音特征划分成两部分,一部分语音的特征训练模型,另外一部分语音的特征测试模型。数据集的划分方法根据你数据量的大小来确定。若有海量语音数据,取2000~10000条数据作为测试集即可,每个数据集中不同标签的样本要均等出现。若数据量较少,可以采用7∶3的比例划分或采用交叉方法选择[4]。
确定初始参数后,启动神经网络算法。经过多次迭代算法收敛或大于最大迭代次数后,得到初步的情感识别模型。将测试集的语音特征和标签数据带入情感识别模型验证准确率。假设训练集的准确率为[p1],测试集的准确率为[p2]。此时会出现两种情况需要调整参数,第一若[p1]大于标准且[p1>p2],表明模型过度地刻画了语音特征和情感之间的关系,该模型实际应用能力较差。第二若[p1]不达标准,该模型识别情感状态能力较弱,为欠拟合现象。可以根据不同的现象调整参数再次训练模型。直到满足准确率的要求,将模型存储到数据库,供用户情感数据识别使用。
若在实际应用中模型效果较好,可以用该模型支持系统运行,直到更新大量语音数据。若应用效果较差,可以调整训练集和优化模型训练算法再次训练模型。
用户通过智能终端的App提交语音,在服务器上识别语音状态,将结果通过网络传输到App。用户收到结果后,可以为此次判断评价。若识别正确,则点击确定,若识别错误,用户提交情感状态。
用户上传的数据是在非绝对安静情况下的录音,所以语音的降噪处理十分重要。降噪处理后,提取语音特征。将特征作为输入项带入情感识别,得到识别结果。系统将此条语音数据和其包含的状态存入用户个人语音库,以待以后使用。当用户个人语音库积累到一定数量后就可以训练语音情感识别模型,此模型将用于该用户的语音情感识别。
4 语音情感识别系统详细设计
4.1 语音预处理
语音数据预处理是系统的重要模块,该模块会被语音情感识别模型训练模块和用户语音情感识别模块调用。它很大程度上影响系统情感识别的准确性。在本系统中该模块有两部分:语音降噪和特征处理。
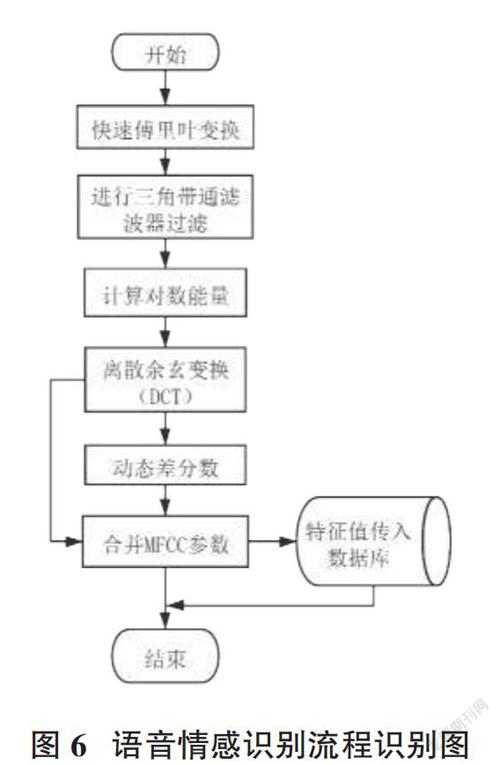
系统语音降噪过程如图5所示。该部分包括四步,原始的语音信号通过这四步的处理后才能准确地提取语音特征。语音数据以.wav文件输入,从文件中读出数据按照图6的顺序执行,最后得到一个[N×M]二维数组,其中[N]为帧的个数,[M]为每个帧的采点的个数,该数组可以作为下一步特征提取的输入。
人的声音并不是在录音的开始的0时刻出现的,人说话也不是连续不断的,中间会有停顿。端点检测的主要目的是识别一段语音中,人声的出现和结束位置。可以根据端点检测出来的开始点和结束点截取语音,提升声音特征提取的准确性,可以采用基于阈值的方法检测端点,低于阈值是没有声音,高于阈值是有声音。
声音产生后,在传输的过程中经过人的口腔和嘴唇,这两部分对声音产生辐射阻抗。通过预加重,降低人体这两部分对语音信号的影响[5-6]。预加重,就是对声音信号进行滤波处理。滤波器的传递函数为[H(z)=1-μz-1],其中[μ∈0.9,1.0]。声音经过滤波后的公式为:[ft=x(t)-μ(t-1)]其中[μ]是經验值,取0.98。
语音是随时间变化的连续量,但是在短时间内(毫秒级) 语音的特征不会改变。为了后面的处理方便,将语音按照15ms为单元进行分割,15ms内这一段称为一个帧。为了让声音更平滑,帧与帧之间要重叠一部,这部分被称之为帧移。假设有一段语音它时间为[T=50ms],每帧的时间间隔为[t=15ms],帧移大小[l=5ms]该段语音将会被分为5份。
将每帧数据分别进行处理时,由于帧时截取的进行傅里叶变换时会出现大量空白,造成能量泄露。通过加窗处理可以改善这种缺点,窗的种类很多,选择不同窗也带来不同处理的结果。最常使用的就是汉明窗[6-7],其公式如下:
[w(n)=0.54-0.46cos2πn/N-1,0≤n≤N0,其他] (1)
将一段语音进行降噪处理,获得[N×M]二维数组后,将此二维数组为基础进行语音特征的提取,具体过程如图6所示,若此段语音不是用户识别语音,需要将得到的二维特征数组存入数据库,以备语音情感识别模型训练算法的使用。此部分用到的方法都是库函数,按照流程图的顺序进行调用。
4.2 语音情感识别模型训练与应用
本系统选用BP神经网络[8-10]作为模型训练算法,它通过训练集和测试集数据训练模型,在算法收敛后,固定各个神经元之间的权值即可得到语音情感识别模型。要输入的一段语音的特征值与标签用[(X,Y)]二元组表示,其中[X]是一个[N×M]的二维数组,[N]表示这段语音的帧的个数,[M]表示特征个数,该神经网络的输入层节点个数为[N×M]。例如一段语音特征值提取为[125×39]的二维数组,那么需要4875个输入节点。通常而言,语音的特征值是一个很大的二维数组,所以输入节点个数较多。
隐藏层的节点个数通过参数确定。系统选用六个离散数值描述情感,选用[{0,1,2,3,4,5}]表示6种情感状态,所以该神经网络输出层需要6个节点。
训练流程如图7所示。首先从数据库中提取语音特征值与标签。将其分成两部分:训练集、测试集,六种情感的语音特征数据要等比例存在每个数据集中。然后配置神经网络的初始参数,参数包括训练的最大迭代次数、隐藏节点数、最低准确率、两个学习率。初始参数根据算法应用的领域及数据集的特点确定,是经验数值。当算法收敛到一个正确率或超过最大迭代次数时我们终止训练,得到初始的语音情感识别模型。如果模型在训练集和测试集的识别正确率低于要求数值,调节参数继续训练。如果模型识别正确率符合要求,就将该模型保存在数据库中,以备识别使用。
用户的语音情感识别过程是模型训练过程的简化版本。用户上传语音文件后进行标准化和降噪处理,然后提出特征值得到一个[N×M]的二维数组,该二维数组是语音情感识别模型的输入值。从数据库中取出该模型各个节点的权重值,运行模型将特征值输入语音情感识别模型即可得到该段语音中包含的情感状态,然后显示到用户的App上。
4.3 个人语音库
个人语音库是系统拓展模块,主要收集用户的个人语音数据。语音情感识别应用领域问题之一是模型训练数据和模型使用的数据不一致。语音和情感是极具个人特色和地域特色,识别语音中包含的情感也极具个人和地域特色。系统识别的每段语音都是训练数据集的积累。系统早期使用公共数据库训练模型,系统后期可根据用户的个人语音库训练模型。也可以根据用户的地域不同将个人语音数据库合并成地域语音库,使用该数据库训练的模型应用到该地域用户的初始情感识别。
语音库的建立过程:系统将用户长传的语音识别出来后显示给用户。用户可以根据识别出的状态做出自己的判断,若正确就点击确定,若错误就从6个情感状态中选择一个点击确定。系统根据用户的反馈,系统可以评价模型在现实应用中的识别正确率,然后将用户的语音数据和标签传入用户专属的语音库中,以备以后使用。
5 总结与展望
本系统采用离散数据描述情感,使用MFCC特征简化语音信息,并使用BP神经网络训练情感识别模型,建立个人语音库。语音包含文本信息和情感信息,情感是一个很复杂的感念,现在可以通过离散的数据或连续的数据描述情感。但是人是一个复杂的情感载体,一段语音中情感可能是多种情感状态叠加的,单纯地做离散描述不能真实地反映人的感受,若使用离散描述,可以在一段语音中划分出主次情感。连续的描述方式更能体现情感的变化的规律,但是现在并没有一套实用的连续描述规则。
本系统采用了一个经典算法,做成独立模块。系统更新算法时,可以直接替代該模块。情感在哪些语音特征中被表征出来并没有正确的理论认识,现在特征的选取主要依赖于经验。情感和特征的关系是情感识别研究领域一个重要的方向。
语音情感识别没有语音文本识别发展迅速,但是语音情感识别是人工智能发展中不可替代的一环,其应用领域也十分广泛,比如居家养老、情感陪护、机器人语音交互、娱乐、刑侦、医疗等。
参考文献:
[1] Grimm M, Kroschel K. Evaluation of natural emotions using self assessment manikins. In: Proc. of the 2005 ASRU. Cancun, 2005: 381−385.
[2] Barpanda S S,Majhi B,Sa P K,et al.Iris feature extraction through wavelet mel-frequency cepstrum coefficients[J].Optics & Laser Technology,2019,110:13-23.
[3] 韩文静,李海峰,阮华斌,等.语音情感识别研究进展综述[J].软件学报,2014,25(1):37-50.
[4] 朱龙珠,盛妍,刘鲲鹏.基于深度学习的海量语音数据识别及分类方法研究[J].电子设计工程,2021,29(9):116-120.
[5] 孙晓虎,李洪均.语音情感识别综述[J].计算机工程与应用,2020,56(11):1-9.
[6] 詹永照,曹鹏.语音情感特征提取和识别的研究与实现[J].江苏大学学报(自然科学版),2005,26(1):72-75.
[7] 高庆吉,赵志华,徐达,等.语音情感识别研究综述[J].智能系统学报,2020,15(1):1-13.
[8] 陈闯,Ryad Chellali,邢尹.改进遗传算法优化BP神经网络的语音情感识别[J].计算机应用研究,2019,36(2):344-346,361.
[9] Sadeghi B H M.A BP-neural network predictor model for plastic injection molding process[J].Journal of Materials Processing Technology,2000,103(3):411-416.
[10] 余华,黄程韦,金赟,等.基于粒子群优化神经网络的语音情感识别[J].数据采集与处理,2011,26(1):57-62.
【通联编辑:梁书】
收稿日期:2021-12-19
基金项目:本篇文章受项目支持,广东理工学院科技项目:项目名称:基于深度学习的语音情感识别技术研究(项目编号2019GKJZK017) ;广东理工学院教育教学改革 ,应用型本科高校混合式教学模式探索——以“Java 程序设计”为例(项目编号:JXGG202056)
作者简介:邬卓恒(1993—) ,男,山东曹县人,计算机应用技术硕士,广东理工学院讲师,CCF专业会员,会员编号62368M,研究方向为机器学习、数据安全;赵嘉熙(2001—) ,男,本科生,CCF学生会员NO.I7960G,研究方向为信息安全,图像识别,深度学习;时小芳(1991—) ,硕士研究生,河南濮阳人,广东理工学院讲师,主要研究方向软件测试、大数据、商务智能等。