融合立场检测和主题挖掘的突发公共事件网络舆情演化研究
2022-05-26刘高勇黄靖钊艾丹祥
刘高勇,黄靖钊,艾丹祥
(广东工业大学 管理学院, 广东 广州 510520)
突发公共事件是指突然发生的,造成或可能造成严重社会危害,需采取有效措施进行应急处置的事件,包括自然灾害、事故灾难、公共卫生、社会安全等[1]。突发公共事件中往往存在复杂、富有争议性的因素,容易引起民众的关注和讨论,而互联网信息渠道的便利性和实时性,进一步提升了突发公共事件的扩散速度和社会影响范围。同时,网络自媒体、社交媒体的平民化、普泛化等特点使事件传播过程中的舆情走向难以预测。如果突发公共事件舆情演化过程中缺乏有效的引导和控制,可能会对社会稳定造成危害。因此,充分地探索突发公共事件网络舆情的演化规律,构建科学有效的治理机制是具有重要意义的研究工作。
事实上,在突发公共事件的舆情生命周期中,充斥着形形色色的消息和评论,但不同的内容具有不同的舆情效用:事件报道类信息在首次出现时效用最大,之后的重复转发则会随着内容的传播扩散而逐步降低舆情价值;事件评论类信息的效用与大众的认可度相关,不被大众接受的观点和看法,会随着时间慢慢“褪去”,无法获得舆情中的传播力和影响力;而被大众支持和赞同的观点,将会持续引导事件舆情的传播速度和方向,甚至能够迅速感染其他用户从而导致舆论的爆发。当前的舆情演化分析方法,无论是基于主题抽取还是情感分析,都缺乏对网络数据舆情效用的评估,使用高成本挖掘舆情价值较低的内容,而高价值的内容被海量数据“淹没”,无法获得重视和聚焦。
鉴于此,本文从考虑网络数据舆情效用的视角出发,改进前人的舆情演化分析方法。先构建基于深度学习的文本立场检测模型和主题句挖掘模型,筛选出被大众用户认同或接受的舆情内容,再针对此类高效用价值的舆情信息进行主题挖掘和演化分析,以便更加快速和准确地揭示突发公共事件的舆情演化规律。
1 相关研究
1.1 立场检测
立场检测任务主要是通过自然语言处理技术,检测给定文本针对某特定目标文本的立场倾向是支持、反对还是中立[2]。最初的立场检测研究仅仅侧重于国会辩论或在线论坛的应用分析[3-4],直到2016年,第五届自然语言处理与中文计算会议[5]和International Workshop on Semantic Evaluation[2]分别推出了中文微博和英文推特的立场检测任务,使学者们的关注力转移到了微博和推特的文本立场检测。
常见的立场检测模型是深度学习模型或基于特征工程的机器学习模型。基于特征工程的传统机器学习模型[6-7]常常花费大量的人力和时间添加自定义词典或相关领域知识,以构建特征工程挖掘复杂的、富含领域知识的语义特征。相比之下,深度学习模型拥有更加高效的自特征提取能力,更适用于立场检测任务。Kazuaki等[8]利用Bi-LSTM(Bi-directional Long Short-Term Memory)模型验证了数据集外部的知识对于提升立场检测的准确度有着显著的效果。白静等[9]使用了Bi-LSTM和卷积神经网络(Convolutional Neural Networks, CNN)模型,结合注意力机制,分别获取文本表示向量和局部卷积特征,再在局部卷积特征中加入权重,最后将两种特征融合进行分类,提升了立场检测的分类效果。周艳芳等[10]基于Bi-LSTM和迁移学习,证明了混合字、词特征能够提高立场分类的性能。
目前,较多的学者在进行立场检测任务时,直接对给定文本进行立场分类,忽略了目标文本的信息,没有较好地判断给定文本和目标文本的语义信息关系。为了充分融合给定文本和目标文本的语义信息进行立场分类,本文基于Word2Vec模型[11],结合Bi-LSTM和CNN两种深度学习模型,构建新的立场检测模型。
1.2 主题挖掘
最早的主题挖掘是由美国的Luhn[12]提出的基于词频统计的主题挖掘。近年来,主题挖掘更是受到了不少学者的关注,其中最受瞩目的是基于词语级别的主题挖掘。Wei等[13]提出了一种基于条件共现度的主题词发现方法;安璐等[14]基于 Word2Vec模型,使用K-mean算法分别提取了突发事件舆情生命周期各阶段的微博博文主题词;李跃鹏等[15]使用K-mean算法对基于Word2Vec模型向量化后的词语进行聚类,并计算词语间的相似度,最后将每个类别中与聚类中心相似度最高的词语作为关键词。然而,在分析网络舆情文本数据时,缺少关联性的主题词语很难明确地反映其蕴含的语义,必须要经过人工了解事件舆情,对主题词扩充描述后才能确定主题的内容。人工扩充描述存在描述困难的问题,容易出现描述偏差,导致研究结果过于主观。
句子级别的主题能避免人工描述过度主观的问题。为了弥补词语级别主题的缺点,学者们开始聚焦句子级别的主题挖掘。孔胜等[16]提出了基于句子相似度的文本主题句提取算法;唐晓波等[17]基于句子相似矩阵进行主题聚类,再利用改进的LexRank算法找出重要度较高的句子生成主题摘要;万国等[18]选取位置特征和标题句子重合度与关联度的特征,对句子进行得分排名,提取出主题句。
与词语级别的主题相比,句子级别的主题在后续的网络舆情演化分析应用中具有一定的优越性。因此,本文参考前人的研究,基于Word2Vec模型和K-means算法对高效用价值的舆情内容进行句子级别的主题挖掘,抽取出主题句,生成主题摘要。
1.3 舆情演化周期
突发公共事件的演化具有特定的生命周期,但不同学者的研究角度不同,生命周期划分模式也就不同,常见的模式有三阶段划分模式、四阶段划分模式、五阶段划分模式等。杜洪涛等[19]将突发事件的演化周期划分为形成(扩散)阶段、高潮阶段、消退阶段;Fink[20]从医学角度提出了经典的四阶段划分模式,把突发事件划分为潜伏期、爆发期、延续期和痊愈期;贾亚敏等[21]将城市突发事件网络舆情的传播演化周期划分为起始阶段、爆发阶段、衰退阶段与平息阶段;王曰芬等[22]结合生命周期理论与舆情变化数将事件舆情划分为五个阶段:爆发期一、衰退期一、爆发期二、爆发期三和衰退期二及平缓期。这些研究多是以生命周期理论为指导,按照事件发生序列,对突发事件的舆情演化模式进行细致分析,深入挖掘事件舆情演化的有效信息。在前人的研究基础上,本文结合突发公共事件的特点划分事件舆情演化的生命周期阶段。
2 研究框架和方法
2.1 研究框架
本文以特定的突发公共事件为例,基于立场检测和主题挖掘,提出了新的突发公共事件舆情演化研究框架,如图1所示,包括数据采集和预处理、划分舆情演化生命周期、筛选高效用舆情内容、主题挖掘。具体步骤为:(1) 利用采集器获取特定突发公共事件的微博数据集,包括博文文本语料、评论文本语料等,并对相关数据进一步预处理;(2) 根据生命周期理论,结合突发公共事件热度在时间序列上的变化,划分舆情演化生命周期阶段;(3) 构建新的立场检测模型,识别评论针对博文的立场信息,挖掘出被大众用户支持、认同的博文,以筛选出高效用的舆情内容;(4) 基于Word2Vec模型和K-means算法,分别对每个阶段的高效用的舆情内容进行主题挖掘。

图1 基于立场检测和主题挖掘的突发公共事件舆情演化研究框架Fig.1 Research framework of public opinion evolution of public emergencies based on stance detection and topic mining
2.2 基于深度学习的立场检测模型筛选高效用舆情内容
本文基于深度学习构建新的立场检测模型,如图2所示,检测评论针对其对应博文的立场,再计算每条博文获得的大众认同度,以挖掘出大众用户接受、认同的博文,识别出效用价值较高的舆论信息,提高突发公共事件舆情演化的分析效率。筛选高效用舆情内容的具体步骤为

图2 立场检测模型Fig.2 Stance detection model
1) 搭建立场检测模型
立场检测模型由CNN模型、Bi-LSTM模型和预训练的Word2Vec模型构成,共包括3层。
(1) Embedding层:Embedding层以预训练的Word2Vec模型为基础,能将一个句子转换为m×n的向量矩阵,例如:将已分词的博文(如:这是、疑案、不是、灵异 ······)和评论(如:同感、大概率、已经、遇害······)输入Embedding层,分别获得m×n的博文和评论词向量矩阵,其中m为句子的词语数量,n为词向量的维数。
(2) Bi-LSTM层:Bi-LSTM的基础构件是循环神经网络(Recurrent Neural Network,RNN)的变体LSTM,如图3所示。LSTM每个隐藏层包括了遗忘门ft,输入门it, 输出门ot, 其中遗忘门ft负责控制模型遗忘上一层信息的比例,输入门it决定当前层的输入信息比例,输出门ot决定当前层输出信息比例。详细公式为

图3 LSTM结构图Fig.3 LSTM structure diagram

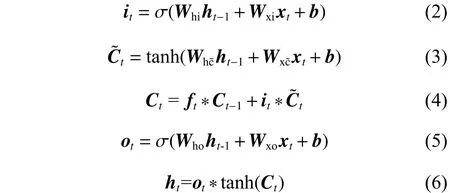
式中:ht-1是 上一阶段的隐藏层的状态;xt是当前阶段的隐藏层输入,即由Word2Vec模型预训练获得的词向量;是当前阶段的临时细胞状态;Ct-1、Ct表示上一阶段和当前的细胞状态;ht是现阶段当前的隐藏层状态;Whf、Wxf、Whi、Wxi、Whc~、Wxc~、Who、Wxo是相应控制门的模型权重;b是偏置向量;σ 是sigmoid激活函数;tanh为双曲正切函数;* 是向量逐点相乘运算。
基于门控RNN的LSTM解决了传统RNN中长期依赖和梯度消失的问题,但是LSTM仅从前往后编码句子,只能获取到从前向后的上下文语义信息,不能获取从后向前的上下文语义信息。Bi-LSTM将前向和后向的两层LSTM结合起来,能更好地从两个方向获取上下文语义信息,如图4所示,其中,αn和 βn分别代表了前向和后向的LSTM。前向和后向的两层LSTM各自输出结果进行拼接得到,作为Bi-LSTM的输出hn。

图4 Bi-LSTM结构图Fig.4 Bi-LSTM structure diagram
该层以2个Bi-LSTM模型为基础,分别用于学习博文和评论的上下文语义信息。首先,将博文和评论的词向量矩阵输入Bi-LSTM模型,分别输出博文、评论上下文语义信息矩阵;然后,将博文上下文语义信息矩阵和评论上下文语义信息矩阵进行矩阵相乘,融合博文和评论的语义信息,获得博文-评论混合语义信息矩阵。
(3) CNN层:CNN层是基于CNN模型的分类层,用于对博文-评论混合语义信息矩阵进行特征提取,并实现评论立场分类,网络结构的搭建见图5。

图5 CNN结构图Fig.5 CNN structure diagram
输入层:输入的是博文-评论的语义混合矩阵X。
卷积层:卷积层是CNN的核心,含有多个卷积核,通过对输入矩阵X卷积运算获得更高级的特征表示。每个卷积核滑动局部窗口对输入矩阵进行卷积操作,获得特征向量,并通过非线性激活函数处理,从而获得本层输出的特征,公式为

式中:X为输入的特征矩阵;Wc为卷积核;b为偏置向量;g表示非线性激活函数,而本文应用ReLU函数,能够降低学习周期;cq为该卷积核在位置q的卷积特征。
池化层:池化层的作用是将卷积层得到的特征进行特征采样。池化层分为最大池化和平均池化,而本文使用的是最大值池化,即选取最大特征值进行拼接。
分类层:该层是将池化后的特征进行重新拟合,再实现最终的评论立场分类(支持不支持)。在CNN模型的基础上添加全连接层,最后通过Sigmoid分类器进行分类。公式为

式中:y为分类标签; σ为sigmoid函数;W为权重向量;v为得到的文本的高层特征向量;b为偏置向量。
2) 训练立场检测模型
为了训练立场检测模型,本文从事件数据集中抽取并人工标注一定量的样本作为训练模型的样本集,具体的标注规则为:随机抽取一条评论,与对应博文配对作为一条样本,若评论表示支持或者认同博文,则标注为1;若评论表示不认同、不接受博文,或对博文的观点持中立态度,或与博文完全不相关,则标注样本为0。采用三人标注策略,即先由其中两人分别对样本进行标注,若两人意见不一致,则第三人参与标注讨论,最后投票决定该样本的标注类别,标注示例如表1所示。将人工标注的样本集分为训练集、验证集与测试集,并应用于训练模型。

表1 样本标注示例Table 1 Sample annotation example
利用准确率A、精确率P、召回率R和F1值4种标准评价获得的模型。4种标准的公式为

式中:TP指真实值为正,预测值为正的样本数;FP指真实值为负,预测值为正的样本数;FN指真实值为正,预测值为负的样本数;TN指真实值为负,预测值为负的样本数。
3) 检测评论立场信息并筛选高效用舆情内容
应用完成训练并通过测试的立场检测模型预测评论针对博文的立场信息,统计每一则博文获得的大众认同度,认同度计算公式为

式中:In为第n则博文的认同度,Sn为对博文n表示支持的评论数,Tn为博文n的总评论数。如果某一博文的In值大于50%,则认为该博文获得了大众的认同,可作为高效用舆情内容保留,参与下一阶段的主题挖掘;否则判定该博文没有被大众接受,将其剔除。
2.3 采用句子级别的主题挖掘对高效用舆情内容进行主题聚类
本文采用句子级别的主题挖掘方法,对高效用舆情内容进行主题聚类,然后从每个簇的句子集中选取与聚类中心余弦相似度最高的3个句子作为主题句,并组成主题摘要,具体方法如下。
(1) 根据标点符号(如“。”“?”“!”“······”)将博文文本切分为数个以单个句子为单位的文本。由于网友的表达具有一定的随意性,本文也将英文格式的标点符号作为切分依据。
(2) 句子向量化。首先应用预训练的Word2Vec模型将博文句子文本的词语向量化;然后将每个词向量相加,获得句子向量。
(3) K-means主题聚类。借助手肘法和数据分布图确定聚类类别数,再应用K-means算法对博文句子集进行聚类,将语义相似的句子向量聚合成为一个主题类。其中,手肘法是确定K-means聚类类别数k的常用方法,先绘制不同类别数k的聚类偏差图,再选取聚类偏差骤变的类别数k作为最终的聚类类别数。
(4) 句子重要性计算。针对上一步形成的每个主题类,计算其中每个句子向量与聚类中心的余弦相似度,用以评估句子的重要性。与聚类中心相似度值越高的句子,其重要性越高。余弦相似度ε 的公式为

式中:δi和 γi分别是句子向量和聚类中心向量的元素。
(5) 主题抽取。选取每个主题类中重要性最高的3个句子,作为该主题的代表,并组成主题摘要。
3 实验设计和分析
3.1 实验数据和预处理
2020年7月,新闻媒体报道了一起社会安全类事件:“杭州江干区一女子在小区离奇失踪”,很快便引发了广泛关注。大量网民通过新浪微博平台积极参与该事件的讨论,相关话题频频登上热搜榜。本文将以该事件作为案例,以新浪微博平台作为网络舆情数据来源,并进行舆情演化的实证分析。结合百度指数,可以确定大众网民对“杭州女子失踪案”的相关搜索规模和关注周期,事件的舆情热度趋势图如图6所示。本文综合考虑爬虫程序的工作效率和新浪微博平台的搜索特点,使用后羿采集器,以“杭州失踪”为搜索关键词,抓取2020年7月14日~2020年8月4日的微博数据。获取微博博文、评论等信息后,经过删除信息缺失的微博博文和评论、去除@、#、URL链接等预处理步骤,最终保留了2 656条博文、287 778条评论。

图6 “杭州女子失踪案”舆情热度趋势图Fig.6 "A Hangzhou Woman Missing Case" public opinion heat trend chart
本文采用广泛应用于中文分词的Python编程语言的第三方库Jieba分词器,对预处理后的博文、评论文本数据进行分词。初步分词后发现,Jieba分词器的默认词典没有收录“杭州女子失踪案”的相关词汇、法律词汇和网络流行新词,整体的分词效果欠佳。因此,本文决定参考文献[14]的方法提升分词效果,结合搜狗输入法的法律词汇大全词库、日常用语词库、网络流行新词库和图悦生成的“杭州女子失踪案”高频的150词,共65 725个词汇,制作自定义用户词典并融入分词器。另外,本文借助哈尔滨工业大学停用词表删除文本数据的停用词。
在众多的词语向量化模型中,Word2Vec模型具有通用性强、生成的向量维度低、效果好、训练速度快等优点。本文决定采用Word2Vec模型进行词语向量化,使用P y t h o n 编程语言的G e n s i m 模块、Word2Vec工具的Skip-gram框架,设定词向量为300维,以约1.3 G的Wiki百科中文语料和抓取的19 MB“杭州女子失踪案”微博文本语料为模型训练语料。
3.2 数据结果
从图6可以看出,在舆情初期阶段相关搜索量较少,首次搜索出现在2020年7月16日,第一次极值出现在2020年7月21日,整个舆情生命周期的热度峰值出现在2020年7月24日,2020年7月27日后事件热度迅速大幅度下降并慢慢趋于平缓。这一系列的演化过程符合网络舆情传播三阶段模型。为了便于研究,本文借鉴杜洪涛等[19]的方法将“杭州女子失踪案”的舆情演化过程划分为形成(扩散)、高潮和消散三个阶段,其中,形成(扩散)阶段为2020年7月16日~2020年7月22日;高潮阶段为2020年7月23日~2020年7月26日;消散阶段为2020年7月27日~2020年8月4日。划分阶段后,将每个阶段内容相同的博文进行合并,将博文的评论数相加并合并评论数据集。为了排除偶然性的影响,删除合并后评论数低于10的博文,最终剩下2 076条博文。
在识别每阶段的高效用舆情内容前,需要训练立场检测模型,检测所有评论针对其博文的立场信息。为此,本文共标注了约4 300条样本,并以7:1:2的比例划分为训练集、验证集与测试集。使用Python编程语言的Keras框架搭建立场检测模型,最终模型的准确率为83.12%,查准率为83.15%,召回率为83.12%,F1值为83.11%,达到较满意的效果,可用于当前任务。将训练完毕的立场检测模型应用于检测评论的立场信息,并计算博文大众认同度。将每个阶段的大众认同度大于等于50%的博文看作是高效用舆情内容,留作下一阶段主题挖掘的数据,其中,形成(扩散)阶段302条,高潮阶段635条,消散阶段69条。
然后,应用本文2.3提出的方法挖掘“杭州女子失踪案”的舆情生命周期各阶段的高效用主题。根据标点符号分别对高效用博文进行句子分割,获得形成(扩散)阶段1 226个句子;高潮阶段1 583个句子;消退阶段330个句子。使用python的matplotlib工具包画出每个阶段的聚类偏差图,根据手肘法初步确定每个阶段的类别数,再对比不同类别的数据分布图可以最终确定形成(扩散)阶段类别数为3类、高潮阶段类别数为3类、消退阶段类别数为2类。基于Word2Vec模型将每个阶段的句子向量化后,使用python的sklearn工具包的K-means聚类分别进行主题聚类,选取与聚类中心余弦相似度最高的3个句子作为主题句,并组成主题摘要,结果如表2所示。

表2 主题挖掘结果(高潮阶段示例)Table 2 Topic mining results (example of climax stage)
3.3 实验结果对比分析
基于立场检测和主题挖掘的突发公共事件网络舆情演化研究方法有2个创新点,一是从舆情效用的角度出发,挖掘出大众网民接受、认同的舆情内容;二是引进主题句分析以解决传统词语级别主题分析在舆情演化研究中的描述扩充难、主观性强等问题。为了验证本文方法的有效性,以“杭州女子失踪案”舆情的高潮阶段数据为例,将本文方法(方法①)、基于K-means和Term Frequency算法的主题词模型(方法②)和直接进行主题句挖掘的方法(方法③)3种舆情演化研究方法的实验结果进行对比分析,如表3所示。

表3 3种方法的挖掘结果Table 3 Mining results of 3 methods
结合K-means和IDF算法的主题模型是常用于舆情演化分析的词语级别的舆情主题挖掘方法,先对舆情文本内容进行分词,再对词语进行K-means聚类,最后计算每个类别词语的Term Frequency值,并选出高Term Frequency值的词语作为舆情主题;直接进行主题句挖掘的方法是指舆情内容没有经过筛选,直接应用K-means算法对舆情句子进行主题聚类。从表格4可以看出,3种方法均能较好地挖掘出“杭州女子失踪案”舆情的主题,但是方法②和方法③在实际的舆情演化分析中具有一定的局限性。方法②挖掘的主题词缺乏关联性,难以明确地反映主题的真实含义和舆情演化的情况,必须人工了解事件舆情,对主题词进行描述扩充后,才能确定主题含义,存在描述困难的问题,而本文应用主题句挖掘,能直接理解主题上下文含义。方法③与本文方法的主题核心内容有一定相似性,但方法③的TopicII-3均是舆情效用价值低的舆情内容,例如:主题句(1)认为失踪女子丈夫是侦察兵,随后被认定为谣言,受到大量网民指责,没有被广泛传播;主题句(2)和(3)均是指责邻居或物业,随后被网民认为是毫无根据的猜测,没有被认可接受。方法③挖掘的主题包括没有被大众网民接受、认同的舆情内容,在短暂的时间内可能会吸引到关注力,但实际上没有对大众造成影响,无法获得舆情传播力和影响力。对比之下,本文挖掘的主题为大众网民认同、接受的舆情内容,容易对大众网民的认知造成冲击,甚至迅速感染其他用户从而导致舆论爆发。因此,本文提出的突发公共事件网络舆情演化研究方法更具有科学性与实用性。
3.4 舆情演化分析
为了进一步验证本文方法在实际案例舆情分析中的实用性和有效性,本文概括每个阶段的主题摘要,如表4所示,并进一步深入分析不同阶段的主题,更加详细地揭示突发公共事件的舆情演化特点。

表4 主题摘要概况Table 4 Topic summary overview
结合主题挖掘的结果和舆情的演化进程可以看出,立场检测模型有效地挖掘了大众接受、认同的消息和观点,较准确地发现了能持续产生影响或能演变出舆情新方向的高效用价值信息,同时也剔除了不被大众网民接受的信息,如“失踪女子丈夫借钱炒股”“丈夫联合儿子绑架其妻子”等谣言,这些消息被较多网民认定为不实消息,并没有引起持续的关注。
对整个周期的主题进行全面的归纳总结,分析舆情演化方向和演化方向的特征。从突发公共事件舆情的整个演化周期来看,舆情演化方向主要集中在:(1) 对“杭州女子失踪案”的案情介绍和跟踪报道,例如:案发小区的监控没有留下任何痕迹、警方在案发小区的化粪池中检测发现疑似人体组织的物质等。(2) 发表观点和看法,例如:分析案件、提供破案思路、认为案件存在疑点和回顾恶性案件统计分析等。(3) 表达情感,例如:谴责凶手、指责网红主播蹭流量、痛斥部分媒体发布未经核实信息和部分网友恶意“顽梗”、表达对婚姻和人性的怀疑等。也可以看出,突发公共事件舆情主要演化方向具有以下特征:(1) 事件发生后,迅速聚焦到热点案件上,并注重持续跟踪。(2) 以敏锐的视角发现事件的新情况和敏感点。(3) 在事件关键节点,以独特的视角,清晰、合理表达观点;(4) 围绕大众最感兴趣、最关心的问题展开讨论。(5) 内容具有正面导向性。(6) 抓住大众的共鸣点,在情感和情绪上影响大众。
4 结论
本文从舆情效用的视角提出了一种基于立场检测和主题挖掘的突发公共事件舆情演化分析的方法,结合舆情生命周期理论,创新性地构建了新的立场检测模型,计算每个阶段的博文的大众认同度,剔除没有被大众用户接受、认同的博文,筛选出高效用的舆情内容,最后基于Word2Vec模型和K-means算法对高效用的舆情内容进行句子级别的主题发掘。以“杭州女子失踪案”微博数据为例,将本文方法与多种方法进行对比分析,验证本文方法的可行性,并进行了突发公共事件网络舆情演化分析,表明本文方法能在实际案例中聚焦关键点,具有一定实用性。目前,鲜有学者将立场检测应用于舆情演化分析。在理论层面,提出了一种较为有效、准确的高效用舆情内容识别和分析方法,也为网络舆情演化的研究提供了新视角。在应用层面,有利于舆情监管部门准确地获取影响大众用户思想的舆情信息,掌握舆情演变的方向,从而提高网络舆情监管水平,做到精准高效地预警和制定对策。
本文也存在一定的局限性:方法应用于其他平台需进一步探讨和研究。因为微博博主有筛选评论的功能和存在某些博主删除博文的情况,这会造成数据少量缺失。使用K-means聚类会出现聚类中心不稳定的情况。立场检测仅仅考虑文本信息,未来还需要应用多模态模型,融入图像、视频等信息。
