局部特征重叠的行人属性识别方法①
2022-05-10陈伟航刘志刚谢东军
陈伟航,刘志刚,黄 朝,谢东军
(东北石油大学 计算机与信息技术学院,大庆 163318)
行人重识别是指在多个不重叠摄像头中检索出目标行人的技术,可以广泛应用于智慧城市、图像管理等领域.但是,由于使用不同摄像头所拍摄的行人图像存在光照、视角、遮挡以及摄像头分辨率等问题,使得行人重识别技术目前仍面临着很大的困难.随着深度学习的发展,深度学习方法在行人重识别上也得到了很好的应用.实验结果也表明使用深度学习的方法相较于传统方法能够学习到更深层次的图像特征,从而更好地实现行人重识别.但现有的使用深度学习的行人重识别方法大多采用加深神经网络层数的方法,会导致神经网络参数急剧增多,从而使神经网络训练的难度增大,耗费大量的计算资源也难以提取到比较高层的行人语义信息.因此一些学者提出通过利用标注好的行人属性信息来提高对行人的特征提取能力从而提高行人重识别效果.如:Zhu 等[1]提出使用多标签的卷积神经网络(multi-label CNN,MLCNN)模型,将行人图像划分为多个可重叠的部分,并对每个部分都进行相应的属性预测.Fabbri 等[2]同样是将行人分为头、肩、上身、下身几个部分来分别进行属性预测.Liu 等[3]提出多方向注意力网络(hydraplus-net:attentive deep features for pedestrian analysis,HP-Net),将多层注意力特征图多向映射到不同的特征层中,从而能够挖掘到不同尺度的注意力特征,充实行人特征表示.Li等[4,5]提出深度多属性识别(deep learning based multiple attributes recognition,DeepMAR)和深度单属性识别(deep learning based single attribute recognition,DeepSAR)两个网络模型,Deep SAR 能独立识别每个属性,而Deep MAR 则是利用属性之间的关系进行属性识别,最后将两个模型联合共同进行识别.但这些网络都没有考虑局部特征对整体网络识别的影响,也没有关注到行人属性不均衡所导致的网络训练效果不佳的情况.
针对上述问题,本文提出了一种结合行人属性标签的方法,通过对多个有重叠的行人局部特征进行属性识别作为行人全局特征的补充信息来提高识别的准确率.其次,使用Focal loss[6]损失函数来解决属性识别任务中的正负样本不平衡和难易样本不平衡问题.
1 相关理论
1.1 Focal loss
Focal loss 损失函数是在标准交叉熵损失[7]的基础上修改得到的,它通过引入参数γ来降低易分类样本的权重从而使模型更专注于难分类样本的训练,同时还加入了平衡因子α用来平衡正负样本比例不均,从而也有效解决属性样本不平衡的问题.二分类交叉熵损失函数为:

其中,y为真实值,y′为预测值.当y=1 时,预测值越接近真实标签1,损失函数越小,预测值越接近真实标签0,损失越大.y=0 时,预测值越接近真实值0,损失越小,预测值越接近真实值1,损失越大.此时的损失函数就可能在大量简单样本的迭代中训练缓慢且很难达到最优的训练效果.Focal loss 的引入主要是为解决训练过程中难易样本和正负样本不平衡的问题,它从交叉熵函数改进而来,其函数为:
首先在原有的交叉熵函数基础上加入了两个参数γ和α.加入参数γ>0 是用来降低易分类样本的损失,使得网络更关注困难的、容易被错分的样本.此外,加入了平衡因子α,用来平衡正负样本本身的比例不均.γ调节简单样本权重降低的速率,当γ为0 时就变成了传统的交叉熵损失函数,当γ增加时调制系数也在增加,对网络的影响也越大.
1.2 行人属性识别网络
行人属性识别网络(attribute-person recognition network,APR)[8]是将行人属性识别当作一个多任务学习的方式,其结构如图1所示.在损失计算前有m+1 个全连接层(fully connected layer,FC),其中有一个身份分类损失和m个属性分类损失.m+1 个FC 层分别表示为FC,FC1,…,FCm,其中FC 用于ID 分类,FC1,…,FCm用于属性识别,预训练模型使用ResNet50[9].对于属性预测,使用M个Softmax loss 来进行计算.通过用一个多属性分类损失函数和一个id 分类损失函数,训练APR 网络来预测属性和id 标签,最后的损失函数定义如下:

图1 行人属性识别APR 网络模型图

其中,LID和Latt分别表示行人的ID 分类和属性分类的交叉熵损失,参数 λ用于衡量这两个损失函数在Loss的权重.
2 局部特征重叠的行人属性识别方法
2.1 ALFO 网络
本文提出的局部特征重叠的行人属性网络(attributelocal feature overlap network,ALFO)主要由3 部分组成,其结构如图2所示.首先是特征提取部分,利用ResNet50 作为基础网络,其次是进行属性识别任务的局部分支部分,最后是进行行人ID 预测的全局分支部分.
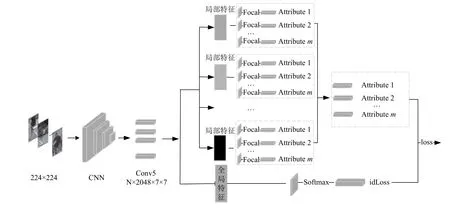
图2 局部特征重叠的行人属性识别模型图
本文基准网络采用的是Resnet50 网络,并去掉网络最后两层使其输出大小为7×7 的2048 维图像.在局部分支中首先将通过基准网络得到的特征图像切分为多个大小相同且有重叠的行人局部特征图,实验发现将特征图切分为6 块得到的最终训练效果最好.再将每块局部特征都分别进行多任务属性学习,并利用m个全连接层来同时预测行人的属性,其中m是标注的属性种类数量.然后对每块局部特征计算出的属性损失通过投票得出每个属性所对应的最优损失.在全局分支中使用全连接层来预测行人的身份标签并计算ID 损失,最终网络的总损失为行人的ID 损失与投票选出的属性损失之和.
2.2 损失函数
该网络的总损失包括使用行人身份标签预测的ID 损失和使用行人属性标签预测的损失.在行人属性数据集中,由于行人包含有多种不同种类的属性会导致出现属性样本不平衡问题,包括类内样本不平衡和类间样本不平衡.其中类内样本不平衡是指在某一类别属性下,如在下身衣服颜色的属性下,不同颜色下身衣服的样本数量不平衡.类间样本不平衡表示不同属性类别间的样本数量不平衡:如帽子和上衣属性样本数量不平衡.属性样本不均衡会导致网络训练效果差或者训练效率低下等问题,一般可以使用三元组损失(triplet loss)[10]或者四元组损失(quadruplet loss)[11]等度量学习的方式或者使用数据预处理的方式对解决样本不平衡问题有一定效果.本文通过改进损失函数,在局部分支进行属性识别时使用Focal loss 计算损失,能够解决在训练中属性样本不平衡的问题.
2.3 行人局部特征属性识别
前期基于深度学习的行人重识别研究中,虽然是基于神经网络自动提取特征,但是较少有方法能够提取到行人高层语义信息.随着行人重识别研究的不断深入以及标注行人属性的大规模数据集的提出,研究者们越来越关注通过行人属性特征来提取行人的高层语义信息从而提高行人重识别的准确率.另外,考虑到行人重识别问题经常面临视角变化、遮挡等情况,而之前的行人重识别方法大多只学习了行人的全局特征没有考虑人体的整体空间结构导致学习困难,因此在全局特征上强调局部差异是非常重要的.本文将行人特征图像切分为大小相同且有重叠的行人局部特征图,然后对每块局部特征分别计算属性损失,最后再通过投票得到识别效果最好的属性损失,这样网络模型同时学习到了行人的局部特征和全局特征从而提高行人重识别的准确率.
3 实验
3.1 数据集
本文实验使用了两个行人属性数据集:Market-1501_attribute[8],DukeMTMC-attribute[8].这两个行人属性数据集,分别在Market-1501 和DukeMTMC 这两个行人重识别数据集的基础上进行行人属性信息标注得到的.Market-1501 数据集在清华大学校园中采集,拍摄于夏季.它是由6 个摄像头在不同区域所拍摄到的1501 个行人组成,且每个行人至少由2 个摄像头所捕获到.共包含训练集751 人,由12 936 张图像组成,测试集由750 个行人的共19 732 张图像组成.Market-1501_attribute 为每一个行人标注包括性别、年龄、上衣颜色、下身颜色等27 个属性.DukeMTMC 数据集拍摄于冬天的杜克大学,它由8 个高清摄像头拍摄,包含来自702 个人的16,522 张训练图片和来自另外702 个人的2 228 张查询图片.DukeMTMC-attribute 数据集为每一个行人标注了包括性别、上衣长度、上衣颜色、下身衣服颜色等23 个属性.通过使用标注了行人属性信息的数据集,使得网络能通过对相应部位的属性进行学习来更好地关注到不同部位的细节,从而提取更有代表性的特征.
3.2 实验结果及分析
本文基线方法采用属性识别网络,因为Market-1501_attribute 和DukeMTMC-attribute 两个数据集是Lin 等人[8]标注并公开的,且APR 网络与本文方法相似,都是同时学习了行人身份和属性信息.同时本文也加入了局部分支的方法,与行人重识别PCB(partbased convolutional baseline)[12]方法有一定相似之处,因此本文与APR 和PCB 网络分别比较,可以验证本文方法的有效性.
本文采用了两种对照实验,分别是通过消融实验证实使用局部分支以及使用Focal loss 的有效性以及与主流行人重识别算法效果的对比,具体如下.
实验1.分别只使用全局分支、只使用局部分支以及不使用Focal loss 方法与本文算法进行对比来验证使用全局和局部特征相结合的方法比只使用局部或者全局行人特征的效果更好,同时也验证了Focal loss 函数的有效性.
实验2.将本文算法与PCB,APR,DeepMar 等主流行人重识别算法在Market-1501 和DukeMTMC 数据集上进行对比实验以验证本文算法相比以往一些主流的行人重识别算法效果有所提升.
实验结果表明:由表1 可知,在 Market-1501 和DukeMTMC 数据集上分别进行测试,结果表明,相比于只使用全局分支的网络,只用局部分支的网络其Rank-1 和mAP 都更高,说明只有局部信息没有行人ID 信息不能很好的识别行人身份,而本文算法相比于只用全局分支和只用局部分支以及不使用Focal loss函数的模型,Rank-1 和mAP 都有较大提升.说明使用提取全局分支和局部分支相结合的方法有一定效果.

表1 使用单独分支实验对比表(%)
实验结果表明:由表2 可以看出,使用本文方法与有代表性的APR、PCB、DeepMar 以及TriHard 和PAR 等基准网络相比,在Market-1501 数据集上mAP分别提升了11.24%、7.43%、4.11%.在DukeMTMC数据集上mAP 分别提升了15.38%、8.02%、1.42%.说明使用局部特征重叠的行人属性识别方法后相比APR、PCB 等主流行人重识别算法在性能上得到了进一步提升,证明本文所提方法有效.

表2 与其他主流行人重识别算法实验对比表(%)
4 结论
行人重识别领域一直存在着许多挑战,现有的方法是直接使用卷积神经网络来提取行人特征,但没有充分利用行人的属性信息.在实际场景中,行人不对齐、行人属性数据集样本不平衡等问题一直很难得到有效解决.本文提出了一种将局部特征重叠与行人属性识别相结合的网络结构,能够同时学习图像的全局特征和局部特征,从而能一定程度上解决行人不对齐和特征表达能力不足的问题,使性能指标得到提升.同时,对于行人属性样本不平衡问题,使用Focal loss 代替原来的交叉熵损失,能够一定程度上解决属性样本不平衡问题所带来的训练效果差或训练效率低下问题,从而提高算法精度.
